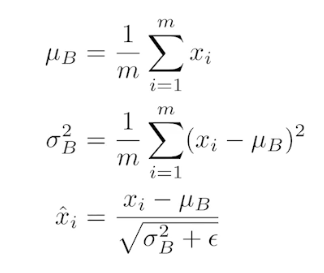
Optimization
- Generaliztion
- Under-fitting vs over-fitting
- Cross validation
- Bias-variance tradeoff
- Bootstrapping
- Bagging and boosting
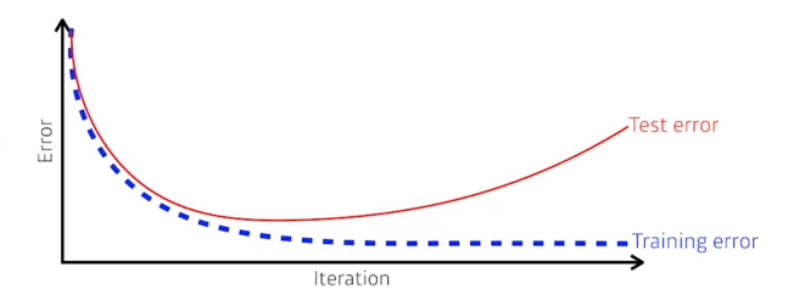
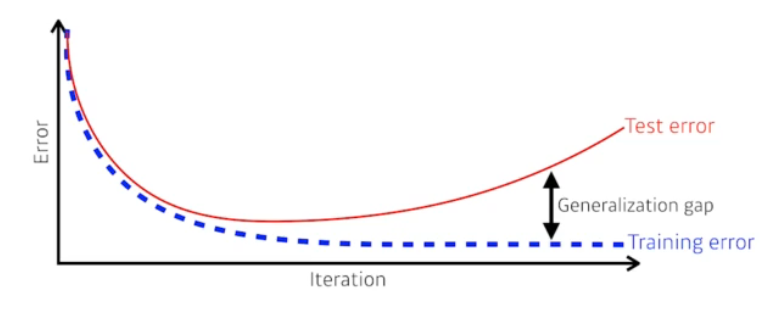
Generaliztion
일반화 성능을 높이기 위한 것
Generaliztion성능은 Test error와 Train error의 차이를 말하는 것
Generaliztion성능이 좋다 : 이 학습데이터와 테스트데이터의 차이가 별로 없다.
학습데이터의 성능이 안 좋으면 Generaliztion성능이 좋다고 해도 테스트 데이터의 성능이 좋다고 할 수 없다.
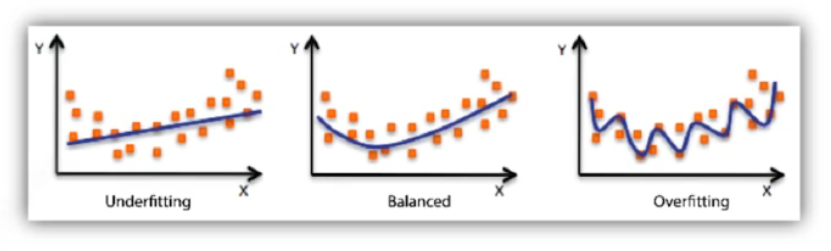
Under-fitting vs over-fitting
Under-fitting : 학습데이터를 제대로 학습하지 못하여, 학습데이터와 테스트데이터 모두에서 성능이 낮은 경우
Overffiting : 학습데이터에 잘 작동하지만, 테스트데이터에 잘 작동하지 않는 것
Cross validation
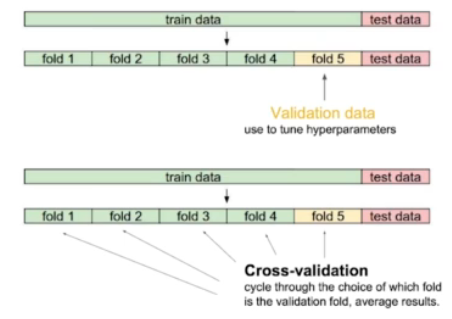
데이터셋을 여러 개의 부분으로 나누어 모델을 여러 번 학습 및 검증하여, 모델의 성능을 안정적으로 평가할 수 있도록 하는 것
k-Fold Cross Validation(k-겹 교차 검증) : 대표적인 교차 검증 방법
Bias-variance tradeoff
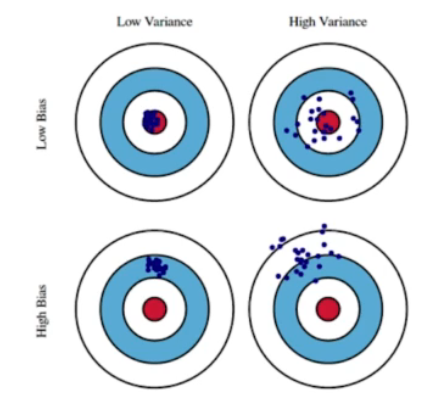
Bias-variance : 출력이 얼마나 일관적으로 나오는지 확인하는 것
Low Bias-High variance: 매우 복잡한 모델로, 훈련 데이터에 과적합되고 새로운 데이터에 대해 일반화 성능이 떨어짐.
High Bias-Low Variance: 매우 단순한 모델로, 훈련 데이터와 새로운 데이터 모두에 대해 잘 맞지 않음.
Bias-variance tradeoff : 모델의 복잡도가 증가하면 바이어스는 줄어들지만 분산은 증가하고, 반대로 모델의 복잡도가 감소하면 분산은 줄어들지만 바이어스는 증가한다. 최적의 모델은 바이어스와 분산 간의 균형을 맞추는 것
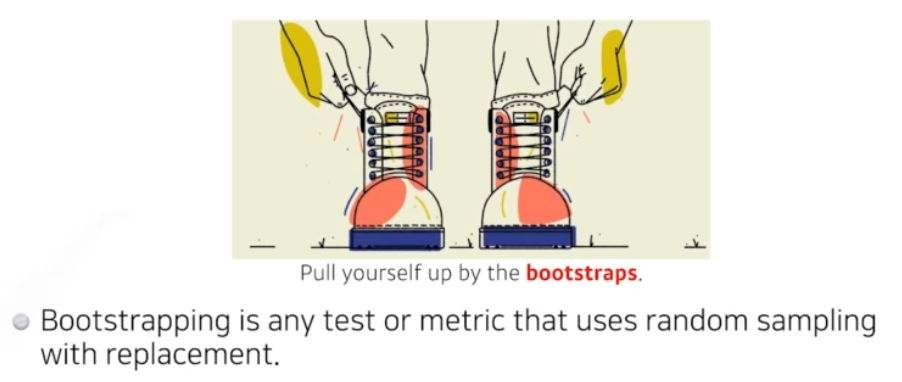
Bootstrapping : 학습데이터에 노이즈가 있다고 할 때
원본 데이터셋에서 여러 번 샘플을 추출하는 방법 각 샘플은 원본 데이터셋과 동일한 크기를 가지지만, 중복된 데이터 포인트를 포함할 수 있다. 이렇게 생성된 여러 부트스트랩 샘플을 사용하여 통계적 추정치를 계산하고, 결과의 변동성을 평가
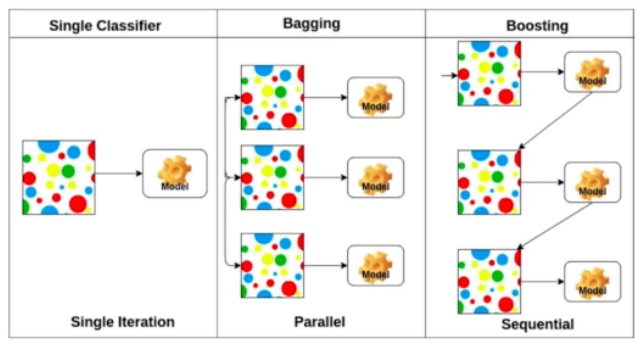
Bagging and Boosting
Bagging : 여러 부트스트랩 샘플을 생성하고 각각에 대해 모델을 학습한 후, 이들의 예측을 결합하여 최종 예측을 도출하는 방법
Boosting : 정확도가 낮은 데이터를 잘 동작하는 모델을 맞춰 합치는 것. 이전 모델의 예측 오류를 줄이는 데 초점을 맞춤
Gradient Descent Methods
- Stochastic Gradient Descent
- Momentum
- Nesterov accelerated gradient
- Adagrad
- Adadelta
- RMSprop
- Adam
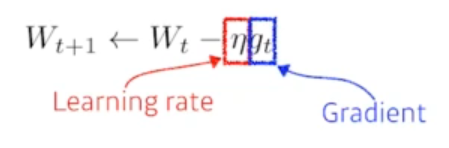
Stochastic Gradient Descent
Learning rate가 크거나 작으면 학습이 불가능함
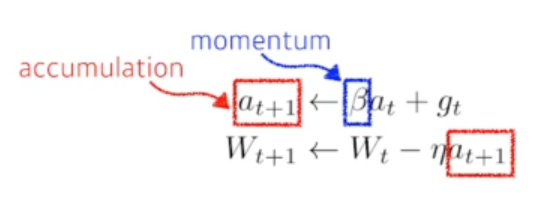
Momentum
Gradient만 활용 학습할 수 있을지, 더 좋은 성능을 만들 수 있지 위한 것
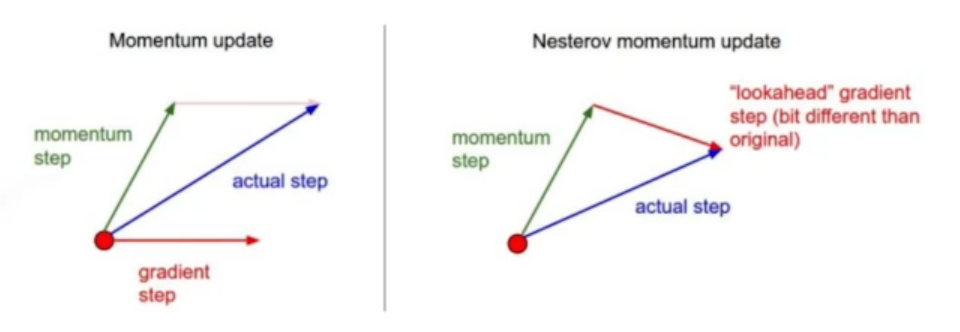
Nesterov accelerated gradient
gradient를 계산할 때 Lookahead gradient로 계산하는 것
한 번 이동하여 a라는 현재 정보가 있으면 한 번 이동하여 gradient를 가져와 계산하는 것
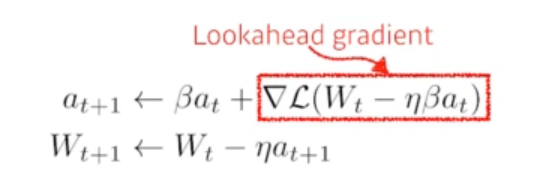
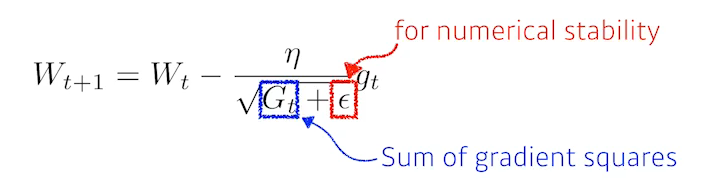
Adagrad
neural network의 파라미터가 많이 변한 조금 변화시키고, 조금 변한 파라미터는 많이 변화시킴
Adadelta
Adagrad의 학습률이 시간이 지나면서 너무 작아지는 문제를 해결하기 위해 제안된 최적화 알고리즘

RMSprop
stepsize를 추가한 것
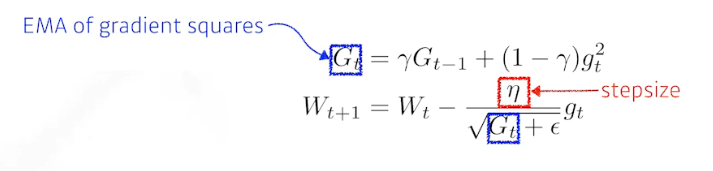
Adam
RMSProp과 모멘텀 최적화 방법을 결합한 것

Regularization
- Early stopping
- Parameter norm penalty
- Data augmentation
- Noise robustness
- Label smoothing
- Dropout
- Batch normalization
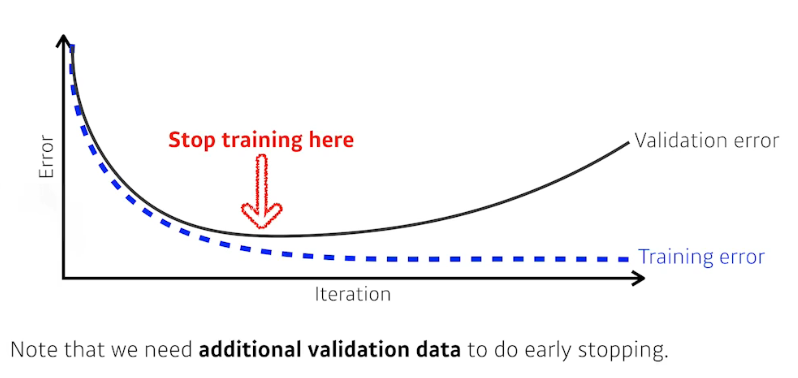
Early stopping
error가 증가할 때 조기 종료
Parameter norm penalty
neural network의 파라미터가 커지지 않게 하는 것
neural network의 파라미터의 제곱의 합을 줄이는 것
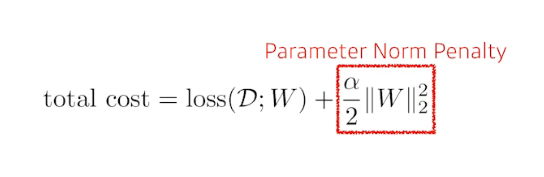
Data augmentation
데이터의 양에 성능이 크게 바뀌기 때문에 데이터를 증강하는 것
한정적인 데이터를 늘리는 것

Noise robustness
데이터에 노이즈를 적용하는 것

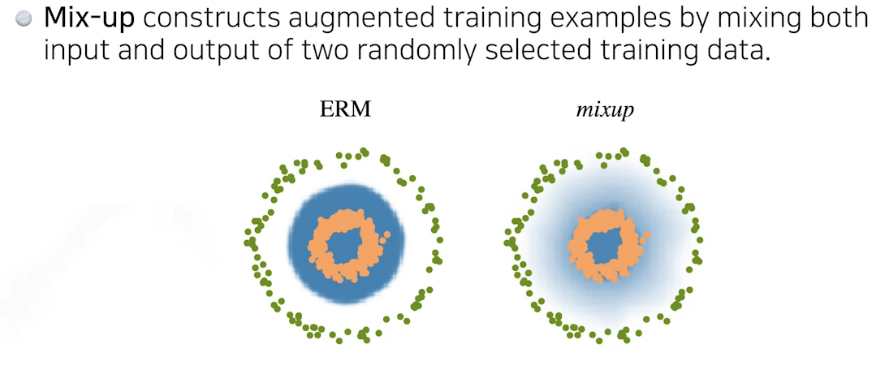
Label smoothing
데이터 두개를 섞는 것
성능이 향상 안 되면 시도해 보라하심 크게 향상될 수 있다함.

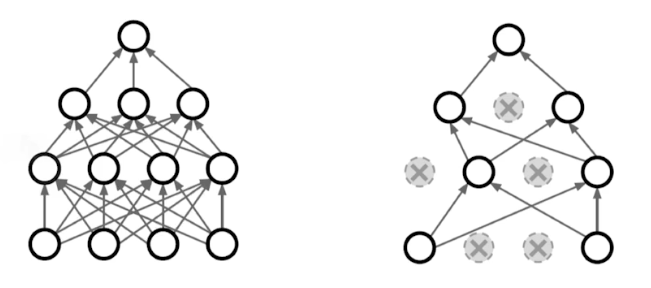
Dropout
학습 과정 중에 랜덤하게 선택된 일부 뉴런을 제외하고 학습
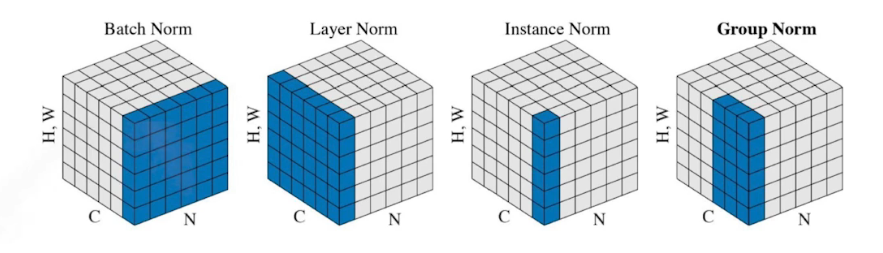
Batch normalization
배치 정규화는 각 미니배치의 입력 데이터를 정규화하여 학습 과정을 안정화하고, 효율적인 학습을 가능하게 한다.