

1. 이미지 파일 -> csv 파일로 변환
conda install tqdm
conda install -c conda-forge ipywidgets
pip install opencv_python
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import cv2 as cv
from sklearn import utils
from tqdm.notebook import tqdm
import os
train_dir = 'C:/jupyter_home/data/cat_dog/train'
def labeling(img):
class_name = img.split('.')[0]
if class_name == 'cat':
return 0
if class_name == 'dog':
return 1
x_data = []
t_data = []
for img in tqdm(os.listdir(train_dir),
total=len(os.listdir(train_dir)),
position=0,
leave=True):
label_data = labeling(img)
img_path = os.path.join(train_dir,img)
img_data = cv.resize(cv.imread(img_path, cv.IMREAD_GRAYSCALE), (80,80))
print(img_data.shape)
t_data.append(label_data)
x_data.append(img_data.ravel())

t_data안에 label 정보
x_data안에 픽셀 정보가 들어가 있을 것이다.
t_df = pd.DataFrame({'label' : t_data})
display(t_df.head())

x_df = pd.DataFrame(x_data)
display(x_df.head())
df = pd.merge(t_df, x_df, left_index=True, right_index=True)
display(df.head())
shuffle_df = utils.shuffle(df)
display(shuffle_df.head())
shuffle_df.to_csv('C:/jupyter_home/data/cat_dog/train.csv', index=False)
2. CNN 구현 (colab)
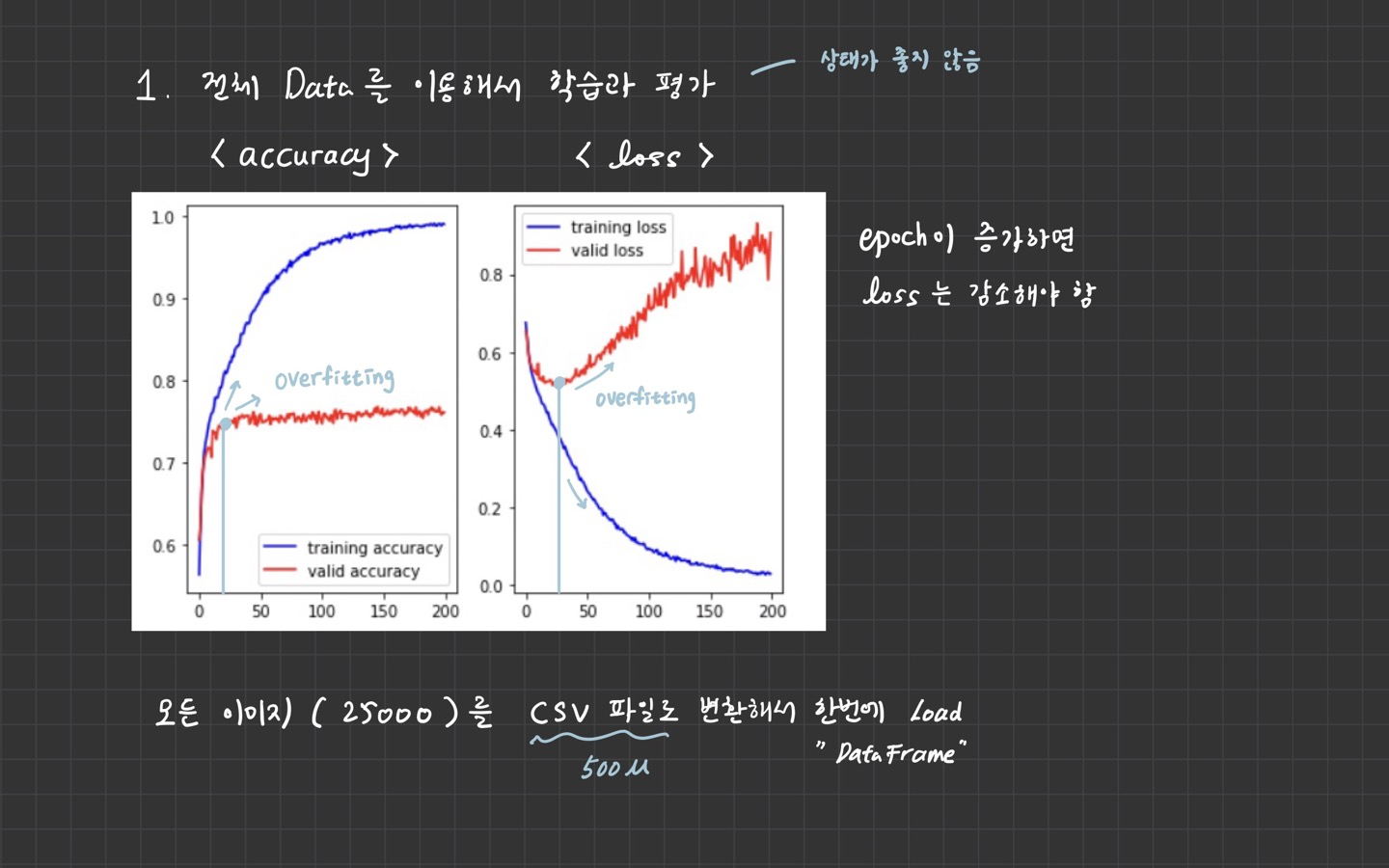
현재 사용하는 데이터의 크기가 약 500M정도이기 때문에
google drive에서 colab으로 파일을 불러올 수 있다.
파일이 더 커지면 못 불러온다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D
from tensorflow.keras.layers import Flatten, Dense, Dropout
from tensorflow.keras.optimizers import Adam
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
Raw Data Loading
df = pd.read_csv('/content/drive/MyDrive/colab/cat_dog/train.csv')
display(df.head())
print(df.shape)
x_data, t_data 분리
x_data = df.drop('label', axis=1, inplace=False).values
t_data = df['label'].values
size 조절
plt.imshow(x_data[152:153].reshape(80,80), cmap='gray')
plt.show()

data split
train_x_data, test_x_data, train_t_data, test_t_data = \
train_test_split(x_data,
t_data,
test_size=0.3,
stratify=t_data)
Normalization(정규화)
scaler = MinMaxScaler()
scaler.fit(train_x_data)
norm_train_x_data = scaler.transform(train_x_data)
norm_test_x_data = scaler.transform(test_x_data)
model 생성
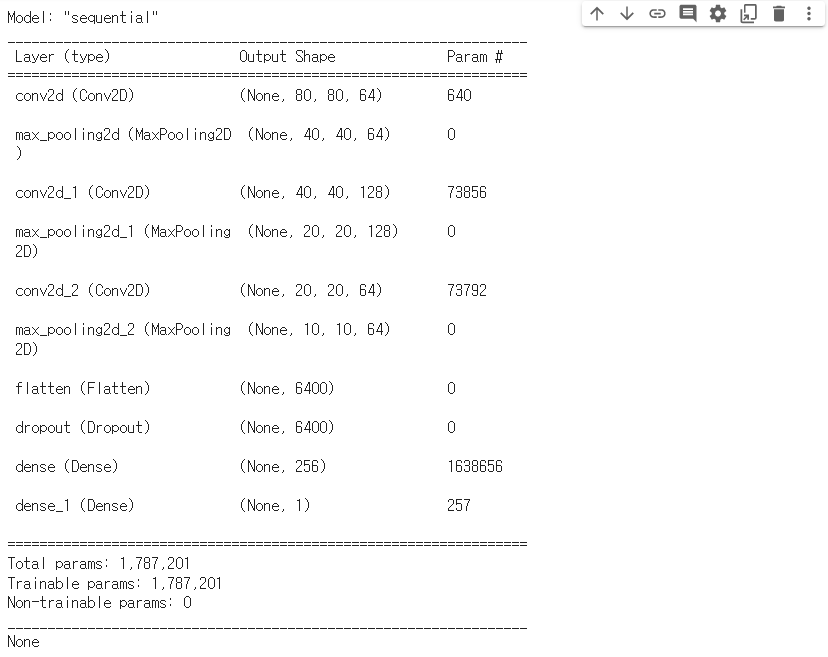
model = Sequential()
model.add(Conv2D(filters=64,
kernel_size=(3,3),
activation='relu',
padding='SAME',
input_shape=(80,80,1)))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(filters=128,
kernel_size=(3,3),
activation='relu',
padding='SAME'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(filters=64,
kernel_size=(3,3),
activation='relu',
padding='SAME'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dropout(rate=0.5))
model.add(Dense(units=256,
activation='relu'))
model.add(Dense(units=1,
activation='sigmoid'))
print(model.summary())
model 실행 옵션
model.compile(optimizer=Adam(learning_rate=1e-4),
loss='binary_crossentropy',
metrics=['accuracy'])
model 학습
history = model.fit(norm_train_x_data.reshape(-1,80,80,1),
train_t_data.reshape(-1,1),
epochs=200,
batch_size=100,
verbose=1,
validation_split=0.3)

result = model.evaluate(norm_test_x_data.reshape(-1,80,80,1),
test_t_data.reshape(-1,1))
print(result)
model 저장
model.save('/content/drive/MyDrive/colab/cat_dog/full_data_model/full_data_model.h5')
history 속성 보기
train_acc = history.history['accuracy']
train_loss = history.history['loss']
valid_acc = history.history['val_accuracy']
valid_loss = history.history['val_loss']
figure = plt.figure()
ax1 = figure.add_subplot(1,2,1)
ax2 = figure.add_subplot(1,2,2)
ax1.plot(train_acc, color='b', label='training accuracy')
ax1.plot(valid_acc, color='r', label='valid accuracy')
ax1.legend()
ax2.plot(train_loss, color='b', label='training loss')
ax2.plot(valid_loss, color='r', label='valid loss')
ax2.legend()
plt.tight_layout()
plt.show()

3. Keras가 제공하는 ImageDataGenerator 사용
1. cat_dog_full_folder 생성 (windows10)
import os, shutil
original_dataset_dir = '../data/cat_dog/train'
base_dir = '../data/cat_dog_full'
os.mkdir(base_dir)
train_dir = os.path.join(base_dir,'train').replace('\\','/')
os.mkdir(train_dir)
validation_dir = os.path.join(base_dir,'validation').replace('\\','/')
os.mkdir(validation_dir)
test_dir = os.path.join(base_dir,'test').replace('\\','/')
os.mkdir(test_dir)
train_cats_dir = os.path.join(train_dir,'cats').replace('\\','/')
os.mkdir(train_cats_dir)
train_dogs_dir = os.path.join(train_dir,'dogs').replace('\\','/')
os.mkdir(train_dogs_dir)
validation_cats_dir = os.path.join(validation_dir,'cats').replace('\\','/')
os.mkdir(validation_cats_dir)
validation_dogs_dir = os.path.join(validation_dir,'dogs').replace('\\','/')
os.mkdir(validation_dogs_dir)
test_cats_dir = os.path.join(test_dir,'cats').replace('\\','/')
os.mkdir(test_cats_dir)
test_dogs_dir = os.path.join(test_dir,'dogs').replace('\\','/')
os.mkdir(test_dogs_dir)
fnames = ['cat.{}.jpg'.format(i) for i in range(7000)]
for fname in fnames:
src = os.path.join(original_dataset_dir,fname).replace('\\','/')
dst = os.path.join(train_cats_dir, fname).replace('\\','/')
shutil.copyfile(src,dst)
fnames = ['cat.{}.jpg'.format(i) for i in range(7000,10000)]
for fname in fnames:
src = os.path.join(original_dataset_dir,fname).replace('\\','/')
dst = os.path.join(validation_cats_dir, fname).replace('\\','/')
shutil.copyfile(src,dst)
fnames = ['cat.{}.jpg'.format(i) for i in range(10000,12500)]
for fname in fnames:
src = os.path.join(original_dataset_dir,fname).replace('\\','/')
dst = os.path.join(test_cats_dir, fname).replace('\\','/')
shutil.copyfile(src,dst)
fnames = ['dog.{}.jpg'.format(i) for i in range(7000)]
for fname in fnames:
src = os.path.join(original_dataset_dir,fname).replace('\\','/')
dst = os.path.join(train_dogs_dir, fname).replace('\\','/')
shutil.copyfile(src,dst)
fnames = ['dog.{}.jpg'.format(i) for i in range(7000,10000)]
for fname in fnames:
src = os.path.join(original_dataset_dir,fname).replace('\\','/')
dst = os.path.join(validation_dogs_dir, fname).replace('\\','/')
shutil.copyfile(src,dst)
fnames = ['dog.{}.jpg'.format(i) for i in range(10000,12500)]
for fname in fnames:
src = os.path.join(original_dataset_dir,fname).replace('\\','/')
dst = os.path.join(test_dogs_dir, fname).replace('\\','/')
shutil.copyfile(src,dst)
2. ImageDataGenerator 사용
import os
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt
train_dir = '../data/cat_dog_full/train'
valid_dir = '../data/cat_dog_full/validation'
train_datagen = ImageDataGenerator(rescale=1/255)
validation_datagen = ImageDataGenerator(rescale=1/255)
train_generator = train_datagen.flow_from_directory(
train_dir,
classes=['cats', 'dogs'],
target_size=(150,150),
batch_size=20,
class_mode='binary'
)
validation_generator = validation_datagen.flow_from_directory(
valid_dir,
classes=['cats', 'dogs'],
target_size=(150,150),
batch_size=20,
class_mode='binary'
)
for x_data, t_data in train_generator:
print(x_data.shape)
print(t_data.shape)
break
figure = plt.figure()
ax = []
for i in range(20):
ax.append(figure.add_subplot(4,5,i+1))
for x_data, t_data in train_generator:
print(x_data.shape)
print(t_data.shape)
for idx, img_data in enumerate(x_data):
ax[idx].imshow(img_data)
break
plt.tight_layout()
plt.show()

