1. catdog_full_folder생성 (linux)
import os, shutil
original_dataset_dir = './data/cat_dog/train'
base_dir = 'data/cat_dog_full'
os.mkdir(base_dir)
train_dir = os.path.join(base_dir,'train')
os.mkdir(train_dir)
validation_dir = os.path.join(base_dir,'validation')
os.mkdir(validation_dir)
test_dir = os.path.join(base_dir,'test')
os.mkdir(test_dir)
train_cats_dir = os.path.join(train_dir,'cats')
os.mkdir(train_cats_dir)
train_dogs_dir = os.path.join(train_dir,'dogs')
os.mkdir(train_dogs_dir)
validation_cats_dir = os.path.join(validation_dir,'cats')
os.mkdir(validation_cats_dir)
validation_dogs_dir = os.path.join(validation_dir,'dogs')
os.mkdir(validation_dogs_dir)
test_cats_dir = os.path.join(test_dir,'cats')
os.mkdir(test_cats_dir)
test_dogs_dir = os.path.join(test_dir,'dogs')
os.mkdir(test_dogs_dir)
fnames = ['cat.{}.jpg'.format(i) for i in range(7000)]
for fname in fnames:
src = os.path.join(original_dataset_dir,fname)
dst = os.path.join(train_cats_dir, fname)
shutil.copyfile(src,dst)
fnames = ['cat.{}.jpg'.format(i) for i in range(7000,10000)]
for fname in fnames:
src = os.path.join(original_dataset_dir,fname)
dst = os.path.join(validation_cats_dir, fname)
shutil.copyfile(src,dst)
fnames = ['cat.{}.jpg'.format(i) for i in range(10000,12500)]
for fname in fnames:
src = os.path.join(original_dataset_dir,fname)
dst = os.path.join(test_cats_dir, fname)
shutil.copyfile(src,dst)
fnames = ['dog.{}.jpg'.format(i) for i in range(7000)]
for fname in fnames:
src = os.path.join(original_dataset_dir,fname)
dst = os.path.join(train_dogs_dir, fname)
shutil.copyfile(src,dst)
fnames = ['dog.{}.jpg'.format(i) for i in range(7000,10000)]
for fname in fnames:
src = os.path.join(original_dataset_dir,fname)
dst = os.path.join(validation_dogs_dir, fname)
shutil.copyfile(src,dst)
fnames = ['dog.{}.jpg'.format(i) for i in range(10000,12500)]
for fname in fnames:
src = os.path.join(original_dataset_dir,fname)
dst = os.path.join(test_dogs_dir, fname)
shutil.copyfile(src,dst)
2. Keras가 제공하는 ImageDataGenerator 사용
import os
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt
train_dir = './data/cat_dog_full/train'
valid_dir = './data/cat_dog_full/validation'
train_datagen = ImageDataGenerator(rescale=1/255)
validation_datagen = ImageDataGenerator(rescale=1/255)
train_generator = train_datagen.flow_from_directory(
train_dir,
classes=['cats', 'dogs'],
target_size=(150,150),
batch_size=20,
class_mode='binary'
)
validation_generator = validation_datagen.flow_from_directory(
valid_dir,
classes=['cats', 'dogs'],
target_size=(150,150),
batch_size=20,
class_mode='binary'
)
figure = plt.figure()
ax = []
for i in range(20):
ax.append(figure.add_subplot(4,5,i+1))
for x_data, t_data in train_generator:
print(x_data.shape)
print(t_data.shape)
for idx, img_data in enumerate(x_data):
ax[idx].imshow(img_data)
break
plt.tight_layout()
plt.show()

3. 모델 생성
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D
from tensorflow.keras.layers import Flatten, Dense, Dropout
from tensorflow.keras.optimizers import Adam, RMSprop
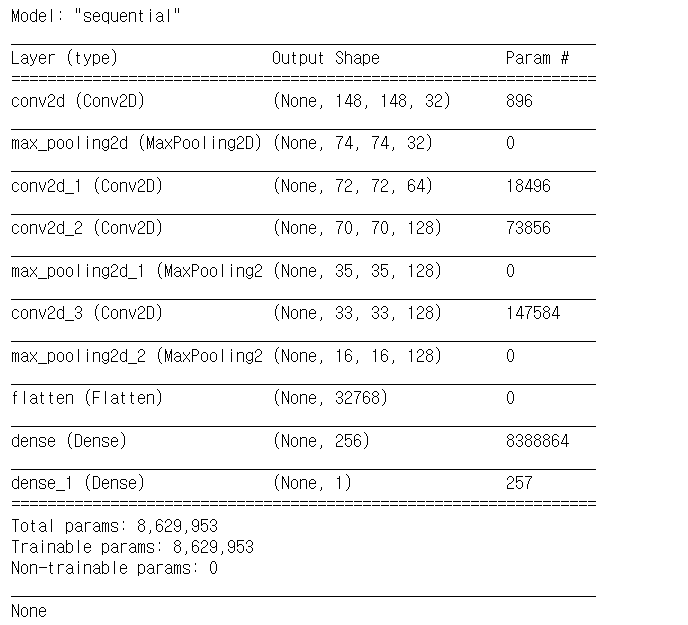
model = Sequential()
model.add(Conv2D(filters=32,
kernel_size=(3,3),
activation='relu',
input_shape=(150,150,3)))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(filters=64,
kernel_size=(3,3),
activation='relu'))
model.add(Conv2D(filters=128,
kernel_size=(3,3),
activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(filters=128,
kernel_size=(3,3),
activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(units=256,
activation='relu'))
model.add(Dense(units=1,
activation='sigmoid'))
print(model.summary())
4. 모델 학습 및 저장
model.compile(optimizer=Adam(learning_rate=1e-4),
loss='binary_crossentropy',
metrics=['accuracy'])
history = model.fit(train_generator,
steps_per_epoch=700,
epochs=30,
validation_data=validation_generator,
validation_steps=300)
model.save('./data/cats_dogs_full_cnn_model.h5')
csv와 image generator의 정확도 차이는 별로 없다.
