
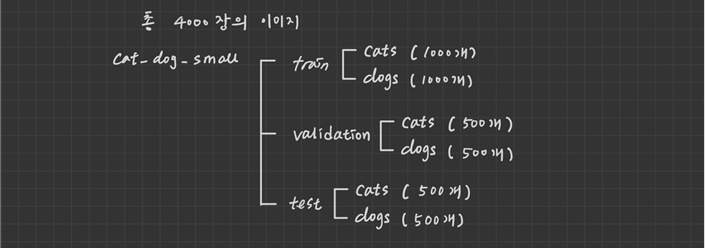
1. 일부 이미지 분리 (총 4000개)
import os, shutil
original_dataset_dir = './data/cat_dog/train'
base_dir = 'data/cat_dog_small'
os.mkdir(base_dir)
train_dir = os.path.join(base_dir,'train')
os.mkdir(train_dir)
validation_dir = os.path.join(base_dir,'validation')
os.mkdir(validation_dir)
test_dir = os.path.join(base_dir,'test')
os.mkdir(test_dir)
train_cats_dir = os.path.join(train_dir,'cats')
os.mkdir(train_cats_dir)
train_dogs_dir = os.path.join(train_dir,'dogs')
os.mkdir(train_dogs_dir)
validation_cats_dir = os.path.join(validation_dir,'cats')
os.mkdir(validation_cats_dir)
validation_dogs_dir = os.path.join(validation_dir,'dogs')
os.mkdir(validation_dogs_dir)
test_cats_dir = os.path.join(test_dir,'cats')
os.mkdir(test_cats_dir)
test_dogs_dir = os.path.join(test_dir,'dogs')
os.mkdir(test_dogs_dir)
fnames = ['cat.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
src = os.path.join(original_dataset_dir,fname)
dst = os.path.join(train_cats_dir, fname)
shutil.copyfile(src,dst)
fnames = ['cat.{}.jpg'.format(i) for i in range(1000,1500)]
for fname in fnames:
src = os.path.join(original_dataset_dir,fname)
dst = os.path.join(validation_cats_dir, fname)
shutil.copyfile(src,dst)
fnames = ['cat.{}.jpg'.format(i) for i in range(1500,2000)]
for fname in fnames:
src = os.path.join(original_dataset_dir,fname)
dst = os.path.join(test_cats_dir, fname)
shutil.copyfile(src,dst)
fnames = ['dog.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
src = os.path.join(original_dataset_dir,fname)
dst = os.path.join(train_dogs_dir, fname)
shutil.copyfile(src,dst)
fnames = ['dog.{}.jpg'.format(i) for i in range(1000,1500)]
for fname in fnames:
src = os.path.join(original_dataset_dir,fname)
dst = os.path.join(validation_dogs_dir, fname)
shutil.copyfile(src,dst)
fnames = ['dog.{}.jpg'.format(i) for i in range(1500,2000)]
for fname in fnames:
src = os.path.join(original_dataset_dir,fname)
dst = os.path.join(test_dogs_dir, fname)
shutil.copyfile(src,dst)
2. ImageDataGenerator
import os
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt
train_dir = './data/cat_dog_small/train'
valid_dir = './data/cat_dog_small/validation'
train_datagen = ImageDataGenerator(rescale=1/255)
validation_datagen = ImageDataGenerator(rescale=1/255)
train_generator = train_datagen.flow_from_directory(
train_dir,
classes=['cats', 'dogs'],
target_size=(150,150),
batch_size=20,
class_mode='binary'
)
validation_generator = validation_datagen.flow_from_directory(
valid_dir,
classes=['cats', 'dogs'],
target_size=(150,150),
batch_size=20,
class_mode='binary'
)
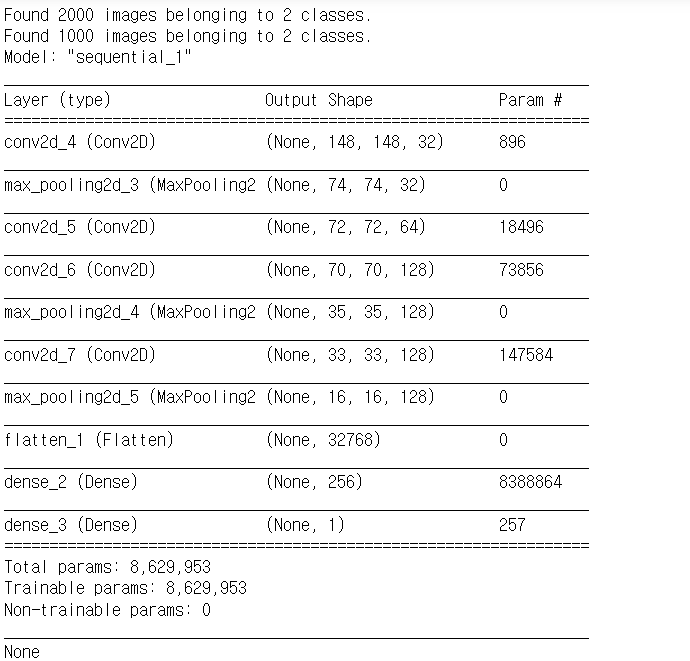
3. 모델 생성
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D
from tensorflow.keras.layers import Flatten, Dense, Dropout
from tensorflow.keras.optimizers import Adam, RMSprop
model = Sequential()
model.add(Conv2D(filters=32,
kernel_size=(3,3),
activation='relu',
input_shape=(150,150,3)))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(filters=64,
kernel_size=(3,3),
activation='relu'))
model.add(Conv2D(filters=128,
kernel_size=(3,3),
activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(filters=128,
kernel_size=(3,3),
activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(units=256,
activation='relu'))
model.add(Dense(units=1,
activation='sigmoid'))
print(model.summary())
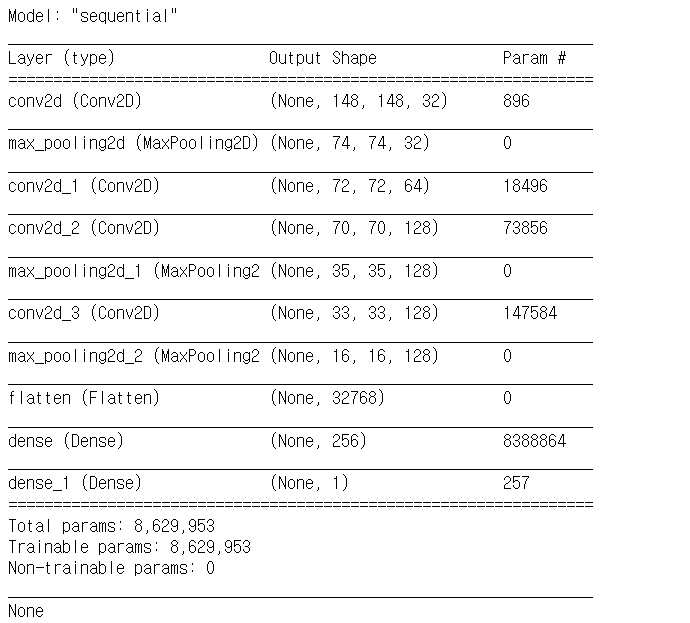
4. 모델 학습 및 저장
model.compile(optimizer=Adam(learning_rate=1e-4),
loss='binary_crossentropy',
metrics=['accuracy'])
history = model.fit(train_generator,
steps_per_epoch=100,
epochs=30,
validation_data=validation_generator,
validation_steps=50)
model.save('./data/cats_dogs_small_cnn_model.h5')

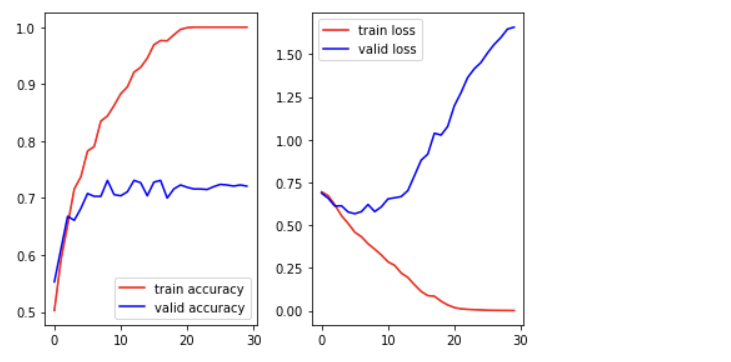
5. 그래프
import matplotlib.pyplot as plt
train_acc = history.history['accuracy']
valid_acc = history.history['val_accuracy']
train_loss = history.history['loss']
valid_loss = history.history['val_loss']
figure = plt.figure()
ax1 = figure.add_subplot(1,2,1)
ax2 = figure.add_subplot(1,2,2)
ax1.plot(train_acc, color='r', label='train accuracy')
ax1.plot(valid_acc, color='b', label='valid accuracy')
ax1.legend()
ax2.plot(train_loss, color='r', label='train loss')
ax2.plot(valid_loss, color='b', label='valid loss')
ax2.legend()
plt.tight_layout()
plt.show()

1. Image Augmentation
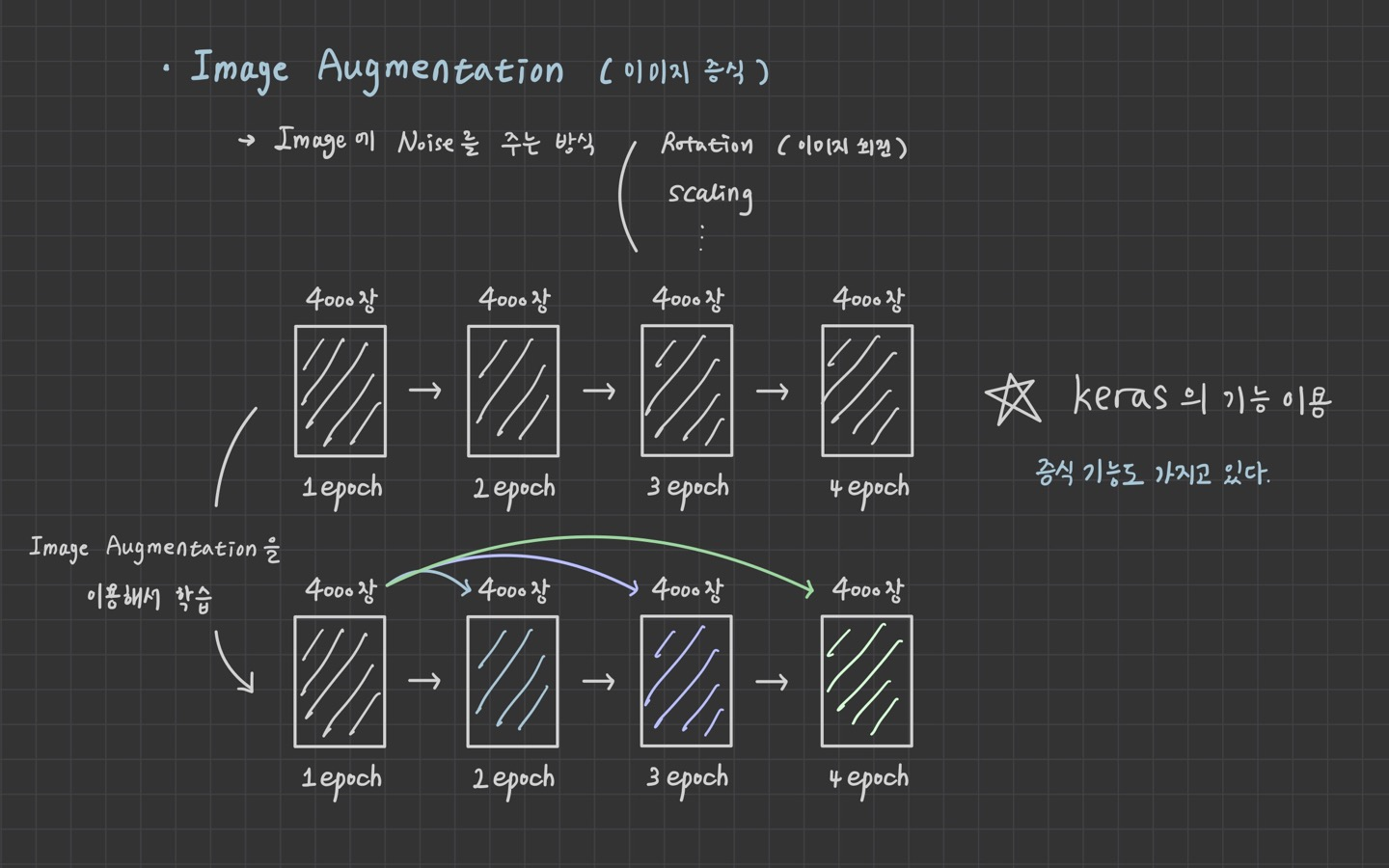
1. 이미지 증식 방법 (이미지 파일 지정)
from tensorflow.keras.preprocessing import image
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt
datagen = ImageDataGenerator(rotation_range=20,
width_sahift_range=0.1,
height_shift_range=0.1,
zoom_range=0.1,
horizontal_flip=True,
vertical_flip=True,
fill_mode='nearest')
img = image.load_img('./data/cat_dog_small/train/cats/cat.3.jpg',
target_size=(150,150))
x = image.img_to_array(img)
print(type(x), x.shape)
x = x.reshape((1,) + x.shape)
print(x.shape)
figure = plt.figure()
ax = []
for i in range(20):
ax.append(figure.add_subplot(4,5,i+1))
idx = 0
for batch in datagen.flow(x, batch_size=1):
ax[idx].imshow(image.array_to_img(batch[0]))
idx += 1
if idx == 20:
break
plt.tight_layout()
plt.show()

2. 이미지 증식을 이용한 CNN
4000개의 이미지 학습
import os
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt
train_dir = './data/cat_dog_small/train'
valid_dir = './data/cat_dog_small/validation'
train_datagen = ImageDataGenerator(rescale=1/255,
rotation_range=30,
width_shift_range=0.1,
height_shift_range=0.1,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
validation_datagen = ImageDataGenerator(rescale=1/255)
train_generator = train_datagen.flow_from_directory(
train_dir,
classes=['cats', 'dogs'],
target_size=(150,150),
batch_size=20,
class_mode='binary'
)
validation_generator = validation_datagen.flow_from_directory(
valid_dir,
classes=['cats', 'dogs'],
target_size=(150,150),
batch_size=20,
class_mode='binary'
)
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D
from tensorflow.keras.layers import Flatten, Dense, Dropout
from tensorflow.keras.optimizers import Adam, RMSprop
model = Sequential()
model.add(Conv2D(filters=32,
kernel_size=(3,3),
activation='relu',
input_shape=(150,150,3)))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(filters=64,
kernel_size=(3,3),
activation='relu'))
model.add(Conv2D(filters=128,
kernel_size=(3,3),
activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(filters=128,
kernel_size=(3,3),
activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(units=256,
activation='relu'))
model.add(Dense(units=1,
activation='sigmoid'))
print(model.summary())
model.compile(optimizer=Adam(learning_rate=1e-4),
loss='binary_crossentropy',
metrics=['accuracy'])
history = model.fit(train_generator,
steps_per_epoch=100,
epochs=30,
validation_data=validation_generator,
validation_steps=50)
model.save('./data/cats_dogs_small_cnn_model_augmentation.h5')
import matplotlib.pyplot as plt
train_acc = history.history['accuracy']
valid_acc = history.history['val_accuracy']
train_loss = history.history['loss']
valid_loss = history.history['val_loss']
figure = plt.figure()
ax1 = figure.add_subplot(1,2,1)
ax2 = figure.add_subplot(1,2,2)
ax1.plot(train_acc, color='r', label='train accuracy')
ax1.plot(valid_acc, color='b', label='valid accuracy')
ax1.legend()
ax2.plot(train_loss, color='r', label='train loss')
ax2.plot(valid_loss, color='b', label='valid loss')
ax2.legend()
plt.tight_layout()
plt.show()

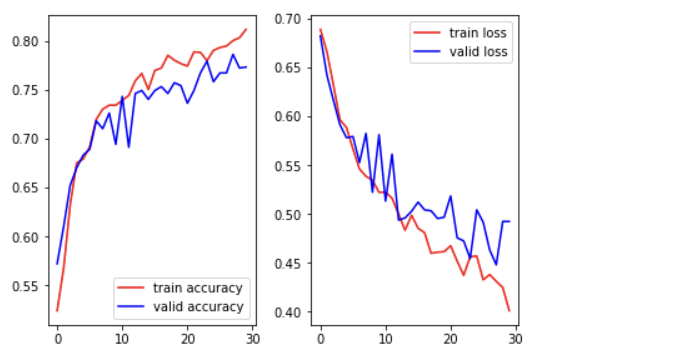
parameter를 조절하고 epoch 수를 늘리면 더 나은 그래프가 나올 것임
2. Transfer Learning (전이학습)
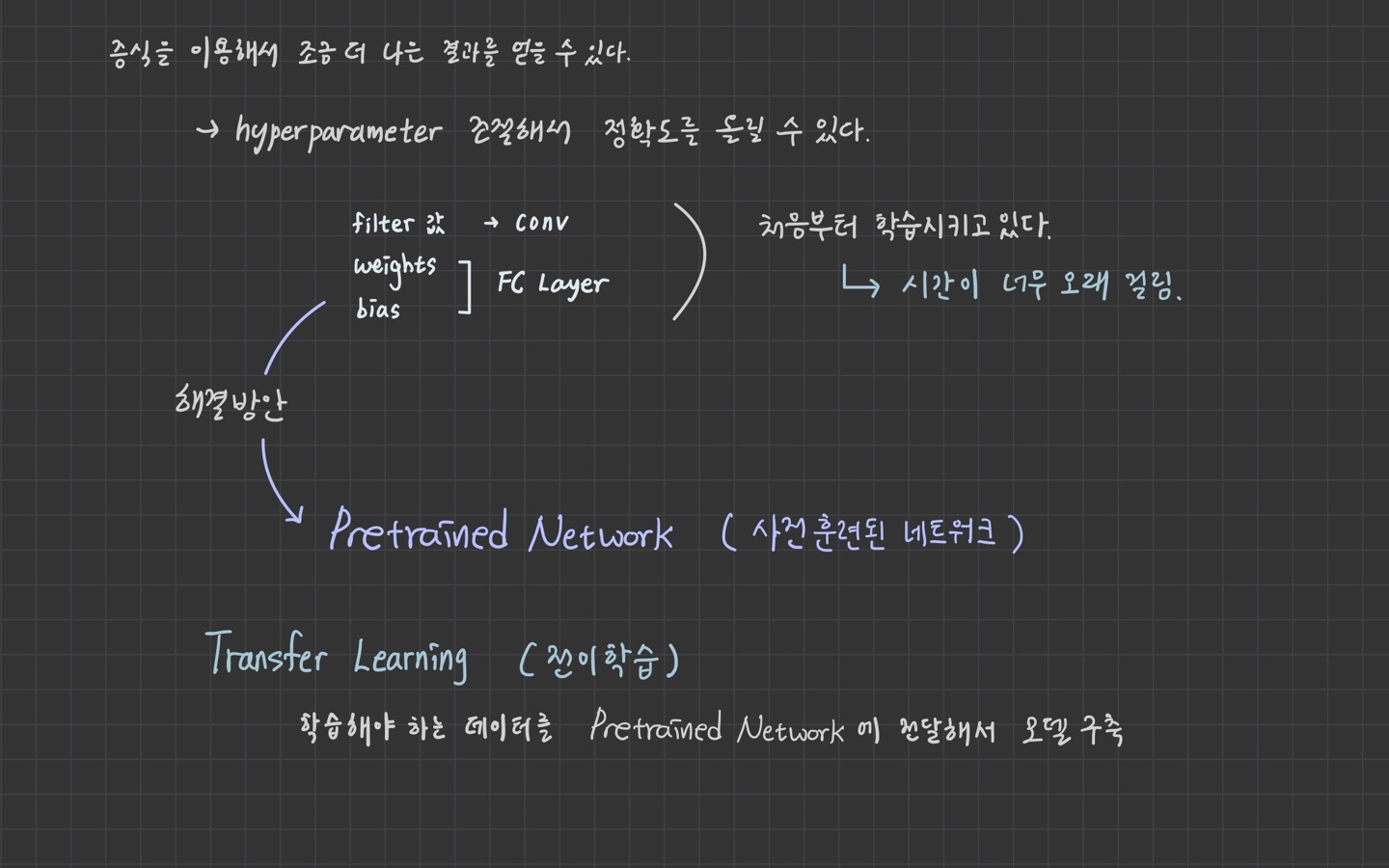
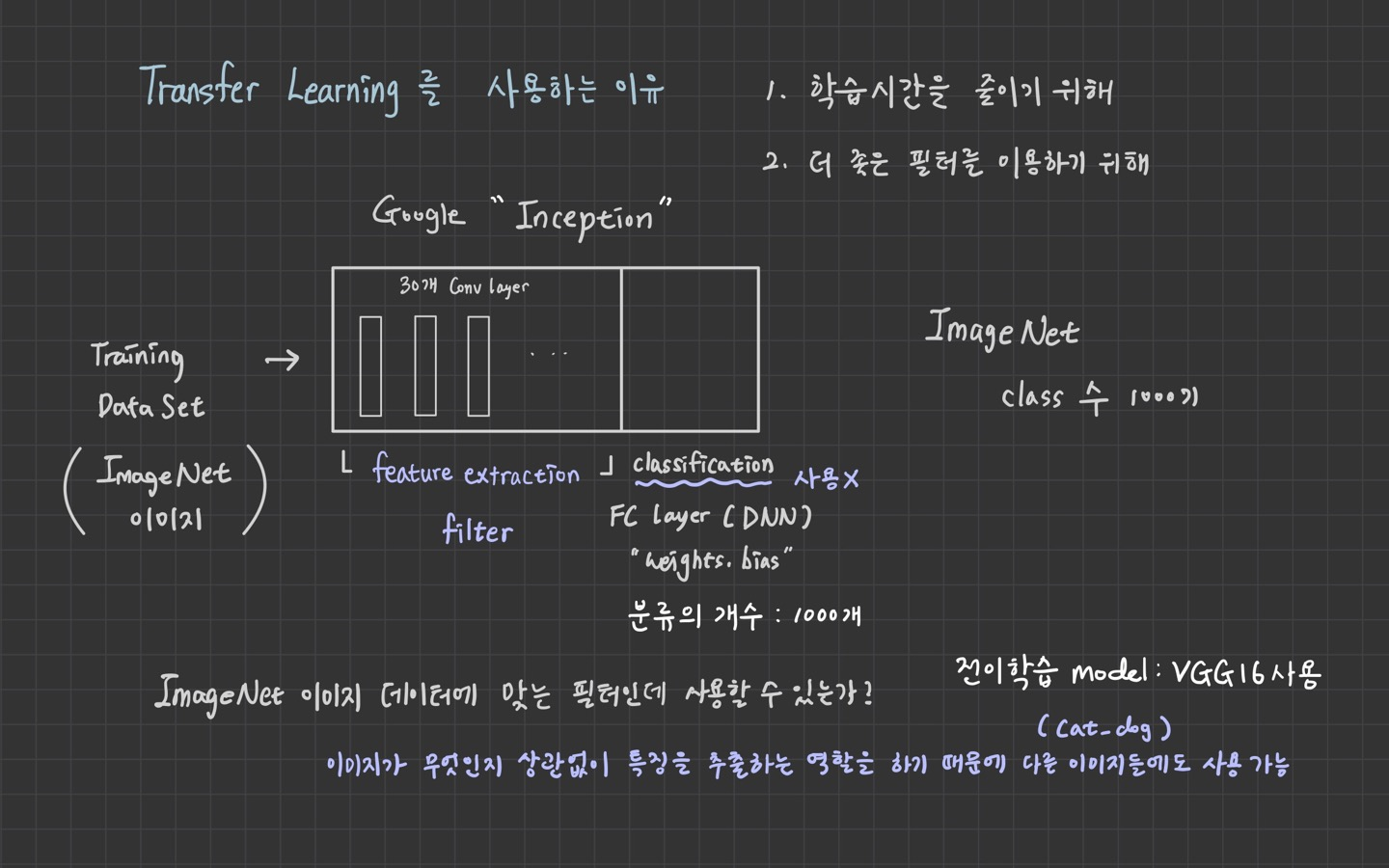

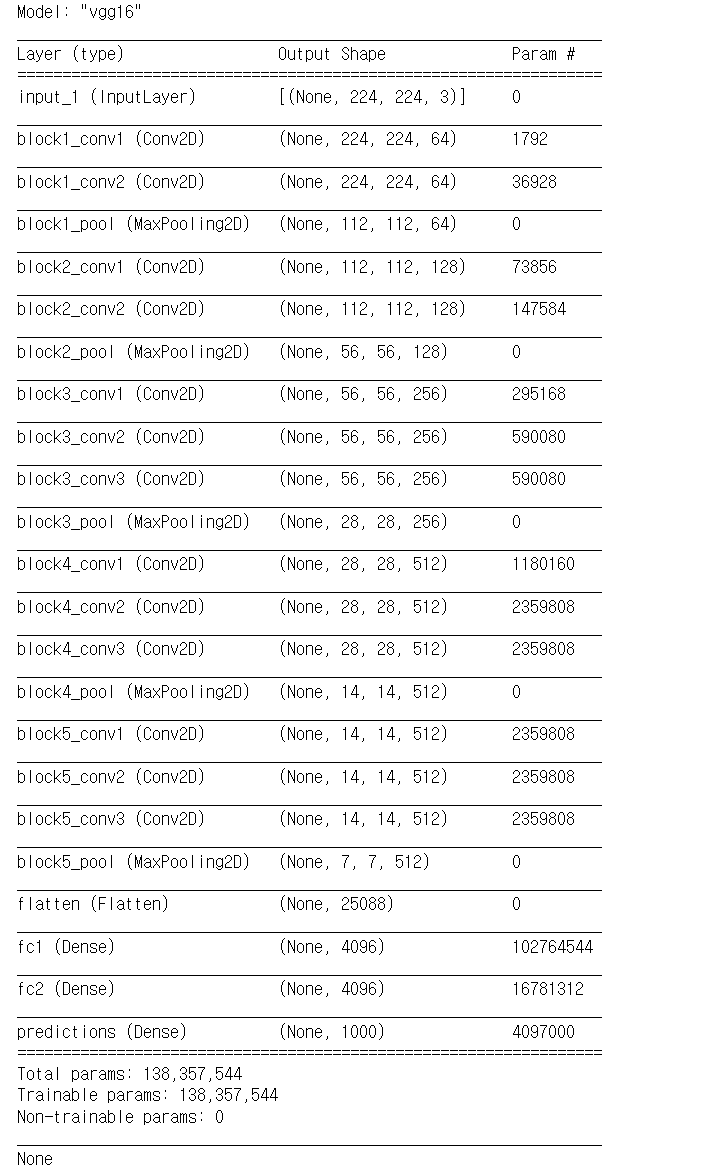
from tensorflow.keras.applications import VGG16
model_base = VGG16(weights='imagenet',
include_top=True,
input_shape=(224,224,3))
print(model_base.summary())
1. activation map 생성
import os
import numpy as np
from tensorflow.keras.preprocessing.image import ImageDataGenerator
base_dir = './data/cat_dog_small'
train_dir = os.path.join(base_dir, 'train')
valid_dir = os.path.join(base_dir, 'validation')
test_dir = os.path.join(base_dir, 'test')
datagen = ImageDataGenerator(rescale=1/255)
def extraction_feature(directory, sample_count):
features = np.zeros(shape=(sample_count,4,4,512))
labels = np.zeros(shape=(sample_count,))
generator = datagen.flow_from_directory(
directory,
classes=['cats', 'dogs'],
target_size=(150,150),
batch_size=20,
class_mode='binary'
)
i = 0
for x_data_batch, t_data_batch in generator:
feature_batch = model_base.predict(x_data_batch)
features[i*20:(i+1)*20] = feature_batch
labels[i*20:(i+1)*20] = t_data_batch
i = i + 1
if i*20 >= sample_count:
break
return features, labels
train_features, train_labels = extraction_feature(train_dir, 2000)
valid_features, valid_labels = extraction_feature(valid_dir, 1000)
test_features, test_labels = extraction_feature(test_dir, 1000)
2. activation map을 이용해서 DNN 학습
train_x_data = np.reshape(train_features,(2000,4*4*512))
train_t_data = train_labels
valid_x_data = np.reshape(valid_features,(1000,4*4*512))
valid_t_data = valid_labels
test_x_data = np.reshape(test_features,(1000,4*4*512))
test_t_data = test_labels
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Flatten, Dense, Dropout
from tensorflow.keras.optimizers import Adam
model = Sequential()
model.add(Flatten(input_shape=(4*4*512,)))
model.add(Dense(units=256,
activation='relu'))
model.add(Dropout(rate=0.5))
model.add(Dense(units=1,
activation='sigmoid'))
model.compile(optimizer=Adam(learning_rate=1e-4),
loss='binary_crossentropy',
metrics=['accuracy'])
history = model.fit(train_x_data,
train_t_data,
epochs=30,
batch_size=20,
validation_data=(valid_x_data, valid_t_data))

