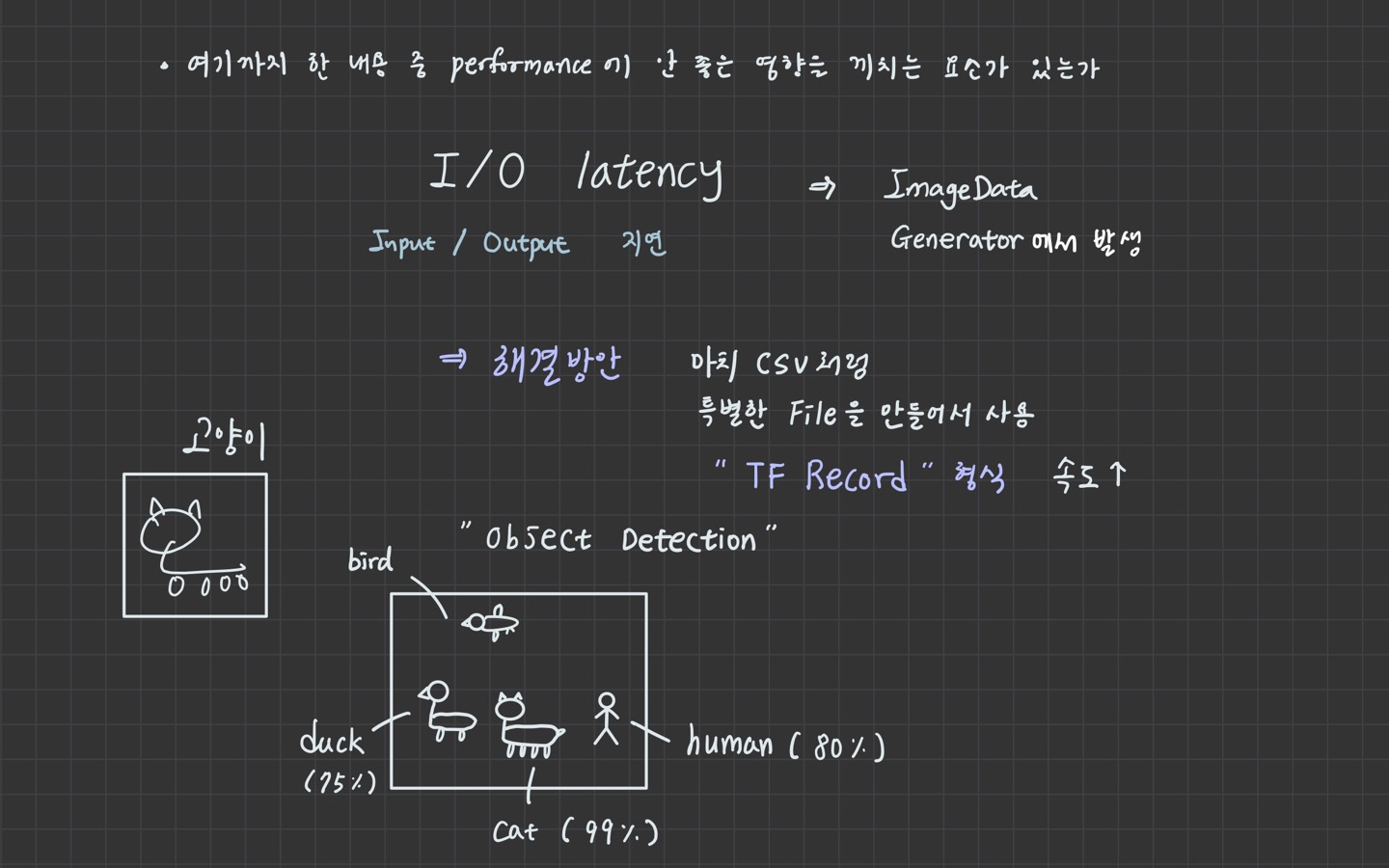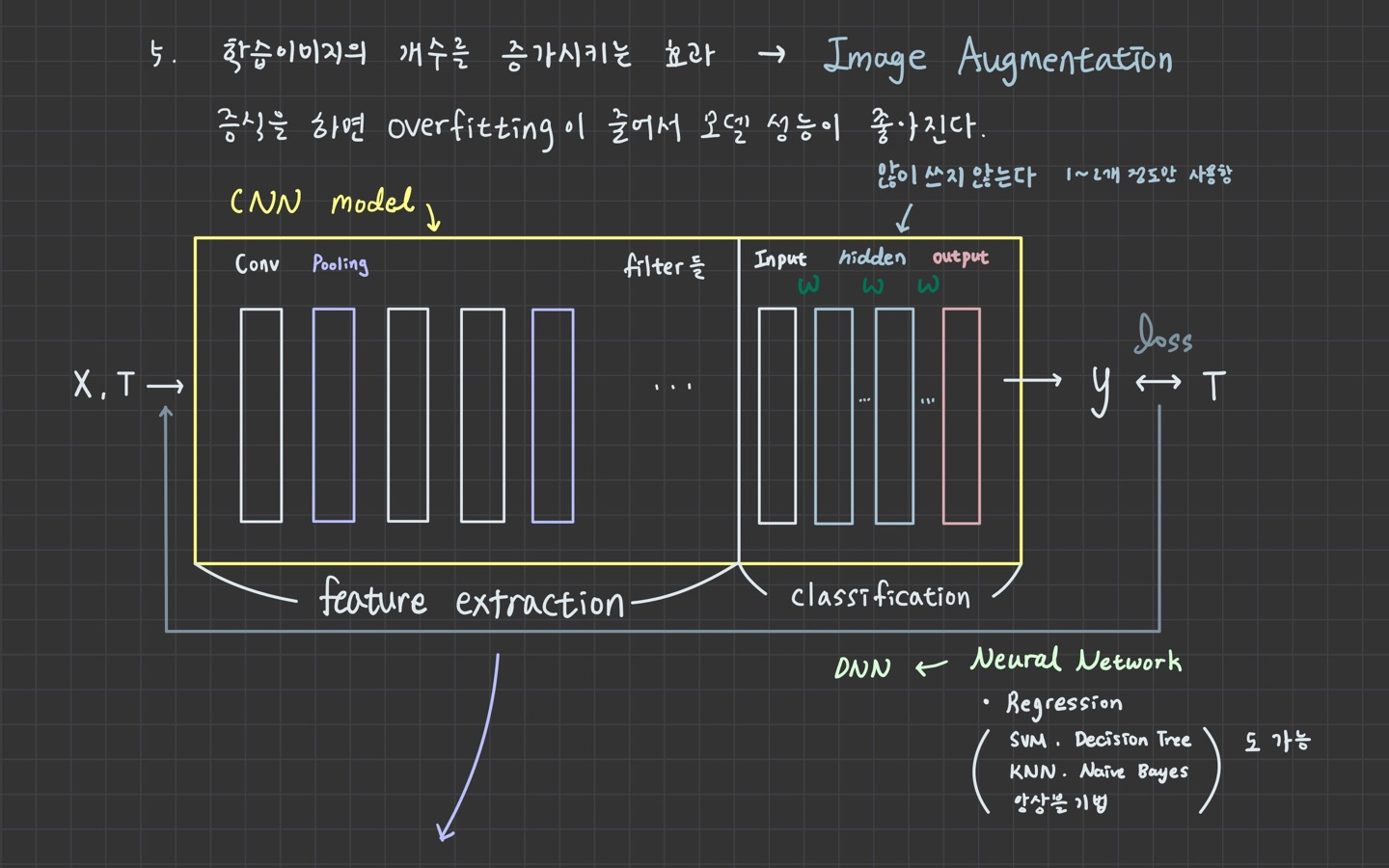
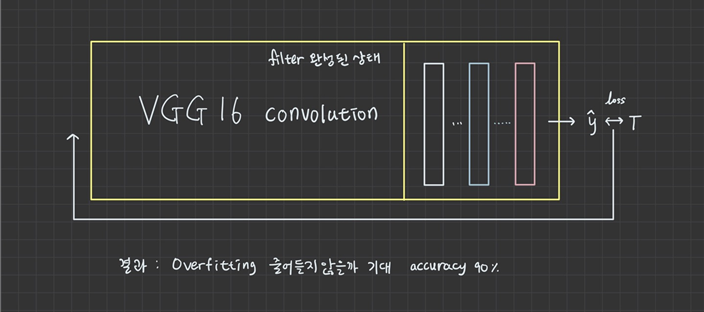
1. Transfer Learning

keras는 전이학습을 위해 VGG16 제공
from tensorflow.keras.applications import VGG16
model_base = VGG16(weights='imagenet',
include_top=False,
input_shape=(150,150,3))
import os
import numpy as np
from tensorflow.keras.preprocessing.image import ImageDataGenerator
base_dir = './data/cat_dog_small'
train_dir = os.path.join(base_dir, 'train')
valid_dir = os.path.join(base_dir, 'validation')
test_dir = os.path.join(base_dir, 'test')
datagen = ImageDataGenerator(rescale=1/255)
def extraction_feature(directory, sample_count):
features = np.zeros(shape=(sample_count,4,4,512))
labels = np.zeros(shape=(sample_count,))
generator = datagen.flow_from_directory(
directory,
classes=['cats', 'dogs'],
target_size=(150,150),
batch_size=20,
class_mode='binary'
)
i = 0
for x_data_batch, t_data_batch in generator:
feature_batch = model_base.predict(x_data_batch)
features[i*20:(i+1)*20] = feature_batch
labels[i*20:(i+1)*20] = t_data_batch
i = i + 1
if i*20 >= sample_count:
break
return features, labels
train_features, train_labels = extraction_feature(train_dir, 2000)
valid_features, valid_labels = extraction_feature(valid_dir, 1000)
test_features, test_labels = extraction_feature(test_dir, 1000)
train_x_data = np.reshape(train_features,(2000,4*4*512))
train_t_data = train_labels
valid_x_data = np.reshape(valid_features,(1000,4*4*512))
valid_t_data = valid_labels
test_x_data = np.reshape(test_features,(1000,4*4*512))
test_t_data = test_labels
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Flatten, Dense, Dropout
from tensorflow.keras.optimizers import Adam
model = Sequential()
model.add(Flatten(input_shape=(4*4*512,)))
model.add(Dense(units=256,
activation='relu'))
model.add(Dropout(rate=0.5))
model.add(Dense(units=1,
activation='sigmoid'))
model.compile(optimizer=Adam(learning_rate=1e-4),
loss='binary_crossentropy',
metrics=['accuracy'])
history = model.fit(train_x_data,
train_t_data,
epochs=30,
batch_size=20,
validation_data=(valid_x_data, valid_t_data))
import matplotlib.pyplot as plt
train_acc = history.history['accuracy']
valid_acc = history.history['val_accuracy']
train_loss = history.history['loss']
valid_loss = history.history['val_loss']
figure = plt.figure()
ax1 = figure.add_subplot(1,2,1)
ax2 = figure.add_subplot(1,2,2)
ax1.plot(train_acc, color='r', label='train accuracy')
ax1.plot(valid_acc, color='b', label='valid accuracy')
ax1.legend()
ax2.plot(train_loss, color='r', label='train loss')
ax2.plot(valid_loss, color='b', label='valid loss')
ax2.legend()
plt.tight_layout()
plt.show()

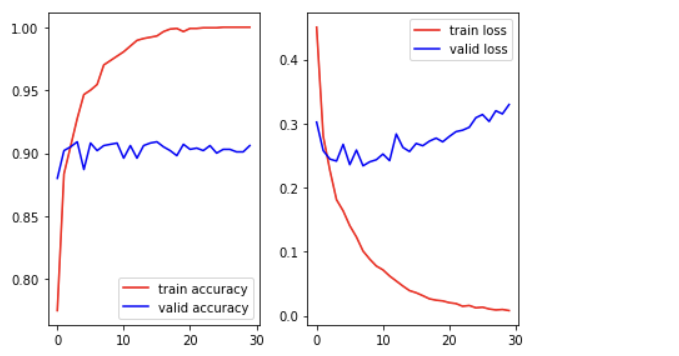
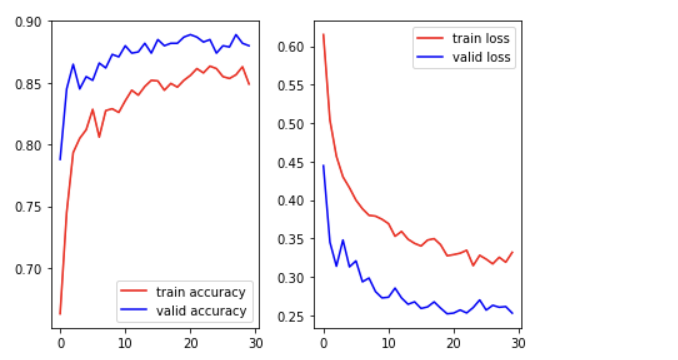
학습이 제대로 이루어졌다고 보기 어렵다.
학습에 사용되는 이미지가 2000개밖에 안 되므로 증식해야 함
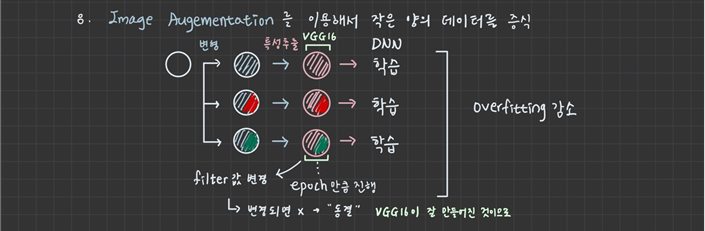
2. 이미지 증식을 이용한 전이학습
import os
import numpy as np
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.applications import VGG16
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Flatten, Dense, Dropout
from tensorflow.keras.optimizers import Adam
import matplotlib.pyplot as plt
train_dir = './data/cat_dog_small/train'
valid_dir = './data/cat_dog_small/validation'
train_datagen = ImageDataGenerator(rescale=1/255,
rotation_range=30,
width_shift_range=0.1,
height_shift_range=0.1,
zoom_range=0.2,
horizontal_flip=True,
vertical_flip=True,
fill_mode='nearest')
valid_datagen = ImageDataGenerator(rescale=1/255)
train_generator = train_datagen.flow_from_directory(train_dir,
classes=['cats', 'dogs'],
target_size=(150,150),
batch_size=20,
class_mode='binary')
valid_generator = valid_datagen.flow_from_directory(valid_dir,
classes=['cats', 'dogs'],
target_size=(150,150),
batch_size=20,
class_mode='binary')
model_base = VGG16(weights='imagenet',
include_top=False,
input_shape=(150,150,3))
model_base.trainable = False
model = Sequential()
model.add(model_base)
model.add(Flatten(input_shape=(4*4*512,)))
model.add(Dense(units=256,
activation='relu'))
model.add(Dropout(rate=0.5))
model.add(Dense(units=1,
activation='sigmoid'))
model.compile(optimizer=Adam(learning_rate=1e-4),
loss='binary_crossentropy',
metrics=['accuracy'])
history = model.fit(train_generator,
steps_per_epoch=100,
epochs=30,
validation_data=valid_generator,
validation_steps=50,
verbose=2)
model.save('./data/cat_dog_small/transfer_learning_cnn_cat_dog_small.h5')
import matplotlib.pyplot as plt
train_acc = history.history['accuracy']
valid_acc = history.history['val_accuracy']
train_loss = history.history['loss']
valid_loss = history.history['val_loss']
figure = plt.figure()
ax1 = figure.add_subplot(1,2,1)
ax2 = figure.add_subplot(1,2,2)
ax1.plot(train_acc, color='r', label='train accuracy')
ax1.plot(valid_acc, color='b', label='valid accuracy')
ax1.legend()
ax2.plot(train_loss, color='r', label='train loss')
ax2.plot(valid_loss, color='b', label='valid loss')
ax2.legend()
plt.tight_layout()
plt.show()

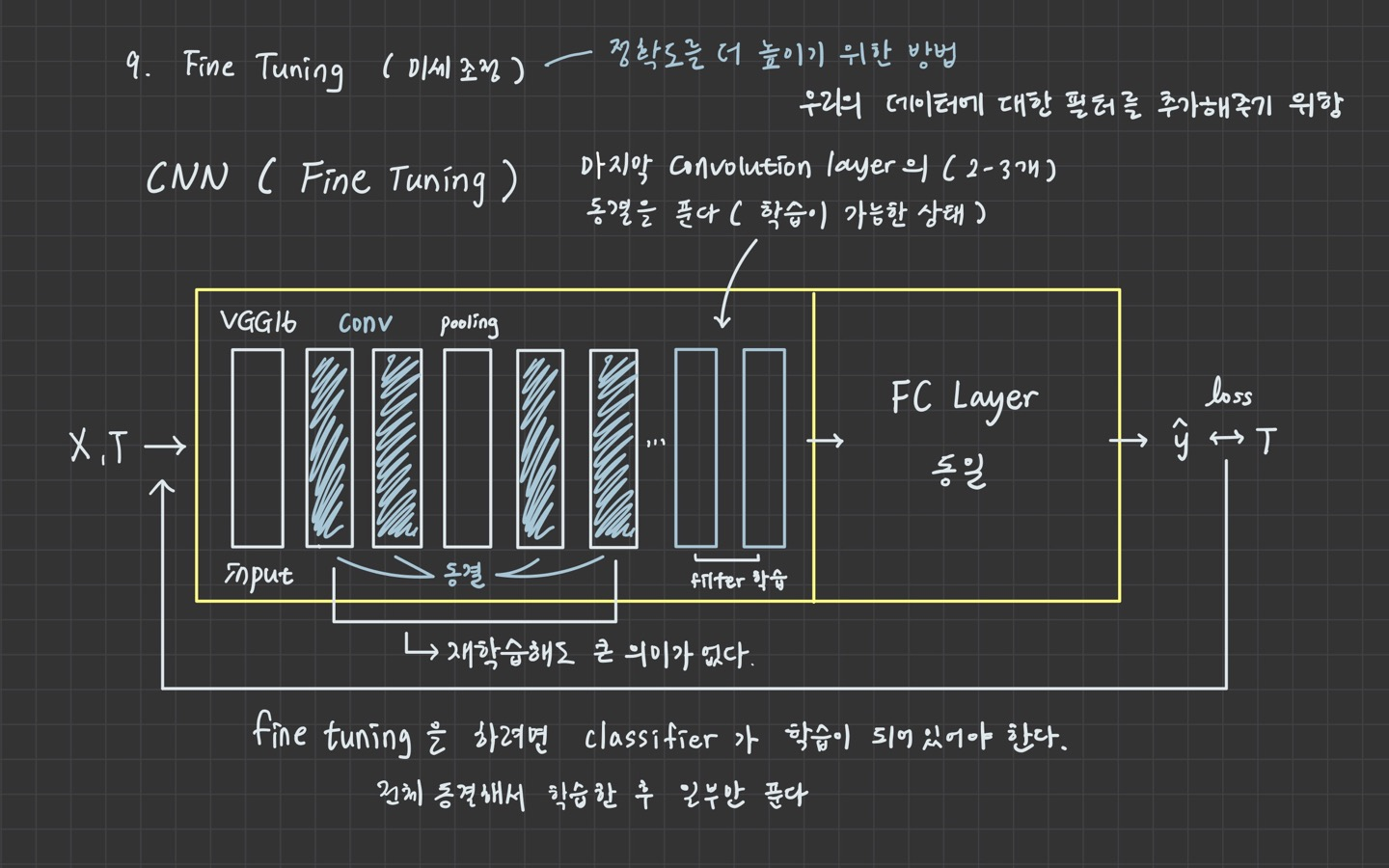
3. 이미지 증식을 이용한 전이학습 (fine tuning)
import os
import numpy as np
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.applications import VGG16
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Flatten, Dense, Dropout
from tensorflow.keras.optimizers import Adam
import matplotlib.pyplot as plt
train_dir = '/content/drive/MyDrive/colab/cat_dog_small/train'
valid_dir = '/content/drive/MyDrive/colab/cat_dog_small/validation'
train_datagen = ImageDataGenerator(rescale=1/255,
rotation_range=30,
width_shift_range=0.1,
height_shift_range=0.1,
zoom_range=0.2,
horizontal_flip=True,
vertical_flip=True,
fill_mode='nearest')
valid_datagen = ImageDataGenerator(rescale=1/255)
train_generator = \
train_datagen.flow_from_directory(train_dir,
classes=['cats', 'dogs'],
target_size=(150,150),
batch_size=20,
class_mode='binary')
valid_generator = \
valid_datagen.flow_from_directory(valid_dir,
classes=['cats', 'dogs'],
target_size=(150,150),
batch_size=20,
class_mode='binary')
model_base = VGG16(weights='imagenet',
include_top=False,
input_shape=(150,150,3))
model_base.trainable = False
model = Sequential()
model.add(model_base)
model.add(Flatten(input_shape=(4*4*512,)))
model.add(Dense(units=256,
activation='relu'))
model.add(Dropout(rate=0.5))
model.add(Dense(units=1,
activation='sigmoid'))
model.compile(optimizer=Adam(learning_rate=1e-4),
loss='binary_crossentropy',
metrics=['accuracy'])
history = model.fit(train_generator,
steps_per_epoch=100,
epochs=30,
validation_data=valid_generator,
validation_steps=50,
verbose=1)
model_base.trainable = True
for layer in model_base.layers:
if layer.name in ['block5_conv1', 'block5_conv2', 'block5_conv3']:
layer.trainable = True
else:
layer.trainable = False
model.compile(optimizer=Adam(learning_rate=1e-5),
loss='binary_crossentropy',
metrics=['accuracy'])
history = model.fit(train_generator,
steps_per_epoch=100,
epochs=30,
validation_data=valid_generator,
validation_steps=50,
verbose=1)
import matplotlib.pyplot as plt
train_acc = history.history['accuracy']
valid_acc = history.history['val_accuracy']
train_loss = history.history['loss']
valid_loss = history.history['val_loss']
figure = plt.figure()
ax1 = figure.add_subplot(1,2,1)
ax2 = figure.add_subplot(1,2,2)
ax1.plot(train_acc, color='r', label='train accuracy')
ax1.plot(valid_acc, color='b', label='valid accuracy')
ax1.legend()
ㄴ
ax2.plot(train_loss, color='r', label='train loss')
ax2.plot(valid_loss, color='b', label='valid loss')
ax2.legend()
plt.tight_layout()
plt.show()
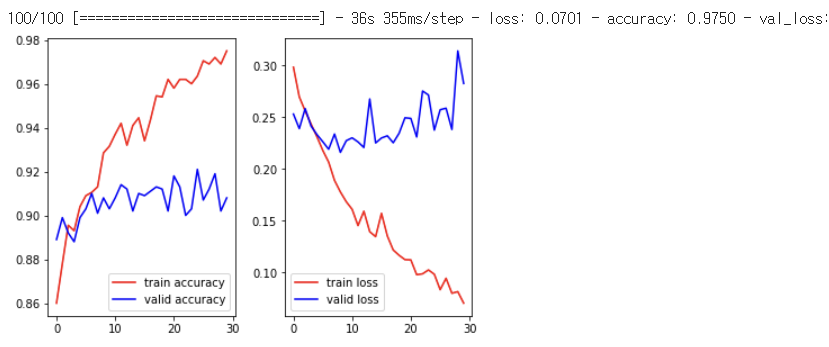
기본적으로 가지고 있는 데이터 사이즈가 작기 때문에overfitting 발생