📌 이번에 리뷰할 논문은 Xception으로, Inception 구조를 개선한 모델이라고 할 수 있습니다.
특히 1x1 합성곱의 용도가 단순히 파라미터 수를 줄이는 데 그치지 않고, 새로운 해석을 제시하는 데 기여했다는 점에서 매우 인상적입니다.
💡Abstract
우리는 Inception 모듈을 컨볼루션 신경망에서 일반적인 컨볼루션과 depthwise separable convoulution 작업 사이의 중간 단계로 해석할 수 있음을 제시합니다.
Inception 모듈을 depthwise separable convolution으로 교체한 새로운 심층 컨볼루션 신경망 아키텍처인 Xception을 제안합니다. 우리는 이 Xception 아키텍처가 ImageNet 데이터셋에서 Inception V3 보다 약간 뛰어나며, 3억 5천만 이미지와 1만 7천 개 클래스가 포함된 더 큰 이미지 분류 데이터셋에서는 Inception V3를 크게 능가합니다. Xception 아키텍처가 Inception V3와 동일한 수의 파라미터를 갖고 있으므로, 성능 향상은 모델 파라미터의 증가된 용량 때문이 아니라, 모델 파라미터의 더 효율적인 사용 덕분입니다.
기존 Inception V3에서 오직 모델의 구조만 변경하여 성능을 향상 시켰습니다.
💡1. Introduction
최근 몇 년 동안 컨볼루션 신경망은 컴퓨터 비전 분야에서 주요 알고리즘으로 자리잡았으며, 이를 설계하기 위한 방법론 개발이 많은 주목을 받았습니다. 컨볼루션 신경망 설계의 역사는 LeNet 스타일 모델에서 시작되었습니다. 이 모델은 특징 추출을 위한 간단한 컨볼루션 스택과 공간적 하위 샘플링을 위한 최대 풀링 연산으로 구성되었습니다.
2012년에는 이러한 아이디어가 AlexNet 아키텍처로 발전하였고, 여기서는 컨볼루션 연산이 최대 풀링 연산 사이에 반복되면서 네트워크가 모든 공간적 스케일에서 더 풍부한 특징을 학습할 수 있었습니다. 이후, 매년 ILSVRC 대회에 의해 이 스타일의 네트워크를 점점 더 깊게 만드는 추세가 나타났으며, VGG 아키텍처(2014)가 그 예입니다.
이 시점에서 새로운 스타일의 네트워크인 Inception 아키텍처가 등장하였으며,
Inception은 이전의 Network-In-Network 아키텍처에서 영감을 받았습니다.
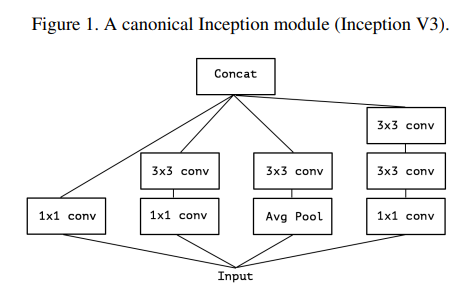
그림 1은 Inception V3 아키텍처에서 Inception 모듈의 표준 형태를 보여줍니다. Inception 모델은 이러한 모듈의 스택으로 이해될 수 있습니다. 이는 간단한 컨볼루션 레이어 스택으로 구성된 이전의 VGG 스타일 네트워크와는 다른 접근 방식입니다.
Inception 모듈은 개념적으로 컨볼루션과 유사하지만, 실험적으로는 더 적은 파라미터로 더 풍부한 표현을 학습할 수 있는 것으로 보입니다.
Inception 모듈은 적은 파라미터로 더 다양한 표현을 학습할 수 있는 구조를 제시하였습니다.
1.1. The Inception hypothesis
컨볼루션 레이어는 2개의 공간 차원(너비와 높이)과 1개의 채널 차원을 가진 3D 공간에서 필터를 학습하려고 합니다. 따라서 하나의 컨볼루션 커널은 채널 간 상관관계와 공간적 상관관계를 동시에 매핑하는 역할을 수행합니다.
Inception 모듈의 아이디어는 이 과정을 더 쉽고 효율적으로 만들기 위해 채널 간 상관관계와 공간적 상관관계를 명시적으로 분리된 일련의 연산으로 나누는 것입니다.
일반적인 Inception 모듈은 먼저 1x1 컨볼루션을 통해 채널 간 상관관계를 살펴보고, 입력 데이터를 원래 입력 공간보다 작은 3개 또는 4개의 별도 공간으로 매핑한 다음, 이 작은 3D 공간에서 3x3 또는 5x5 컨볼루션을 통해 모든 상관관계를 매핑합니다. 이 과정은 그림 1에서 설명됩니다.
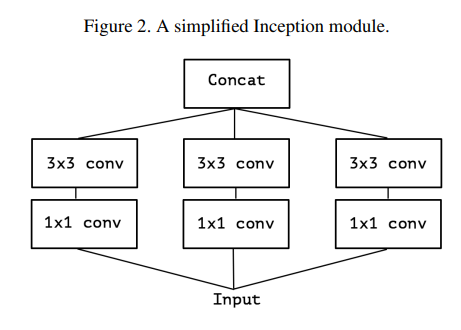
위 그림은 하나의 컨볼루션 크기(예: 3x3)만 사용하고 평균 풀링을 포함하지 않습니다(그림 2). 이 Inception 모듈은 큰 1x1 컨볼루션 뒤에 출력 채널이 겹치지 않는 구간에서 작동하는 공간적 컨볼루션을 적용하는 것으로 재구성될 수 있습니다(그림 3).
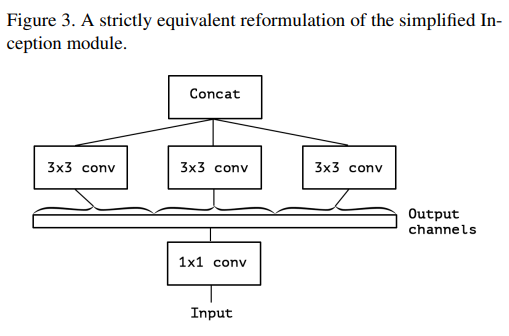
이 과정은 자연스럽게 질문을 제기합니다: 구간의 개수와 크기가 미치는 영향은 무엇일까요? Inception 가설보다 더 강력한 가설을 세워서 채널 간 상관관계와 공간적 상관관계를 완전히 별도로 매핑할 수 있다고 가정하는 것이 합리적일까요?
이 논문에서 가장 중요한 부분이라고 생각합니다.
기존 컨볼루션의 경우 채널간+공간적 상관관계를 한번에 매핑합니다.예) 3채널 7x7 사이즈 이미지 한장을 컨볼루션 한다고 가정해봅시다.
커널의 채널 수와 입력채널 수는 동일해야 합니다. 필터의 수는 5개로 가정합시다.
- 입력 이미지 : 3x7x7
- 커널 : 3x3x3 사이즈의 필터 5개
- 출력 이미지 : 5x5x5
** 입력 이미지의 채널 수와 커널의 채널 수는 동일해야 합니다.
컨볼루션 과정을 직접 그려봤습니다. 첫번째 커널을 보시면, 입력이미지 채널 3개에 커널의 채널 3개가 컨볼루션 됩니다. 이 때 커널의 사이즈가 3x3이죠.
즉 3개의 채널이 컨볼루션을 하는 동시에, 3x3 사이즈로 공간적 컨볼루션도 하는 것이죠.
이를 채널간 상관관계와 공간적 상관관계를 동시에 매핑한다고 말합니다.
1x1 컨볼루션은 한 채널에서 한칸씩만 가져와서 채널끼리 컨볼루션을 합니다. 즉, 한 채널 내에서 공간적 컨볼루션이 없습니다. 오직 채널들 간에 컨볼루션이죠. 1x1 컨볼루션을 한 뒤 3x3 컨볼루션을 하는 것 입니다.
이를 채널간 상관관계와 공간적 상관관계를 따로 매핑한다고 말합니다.
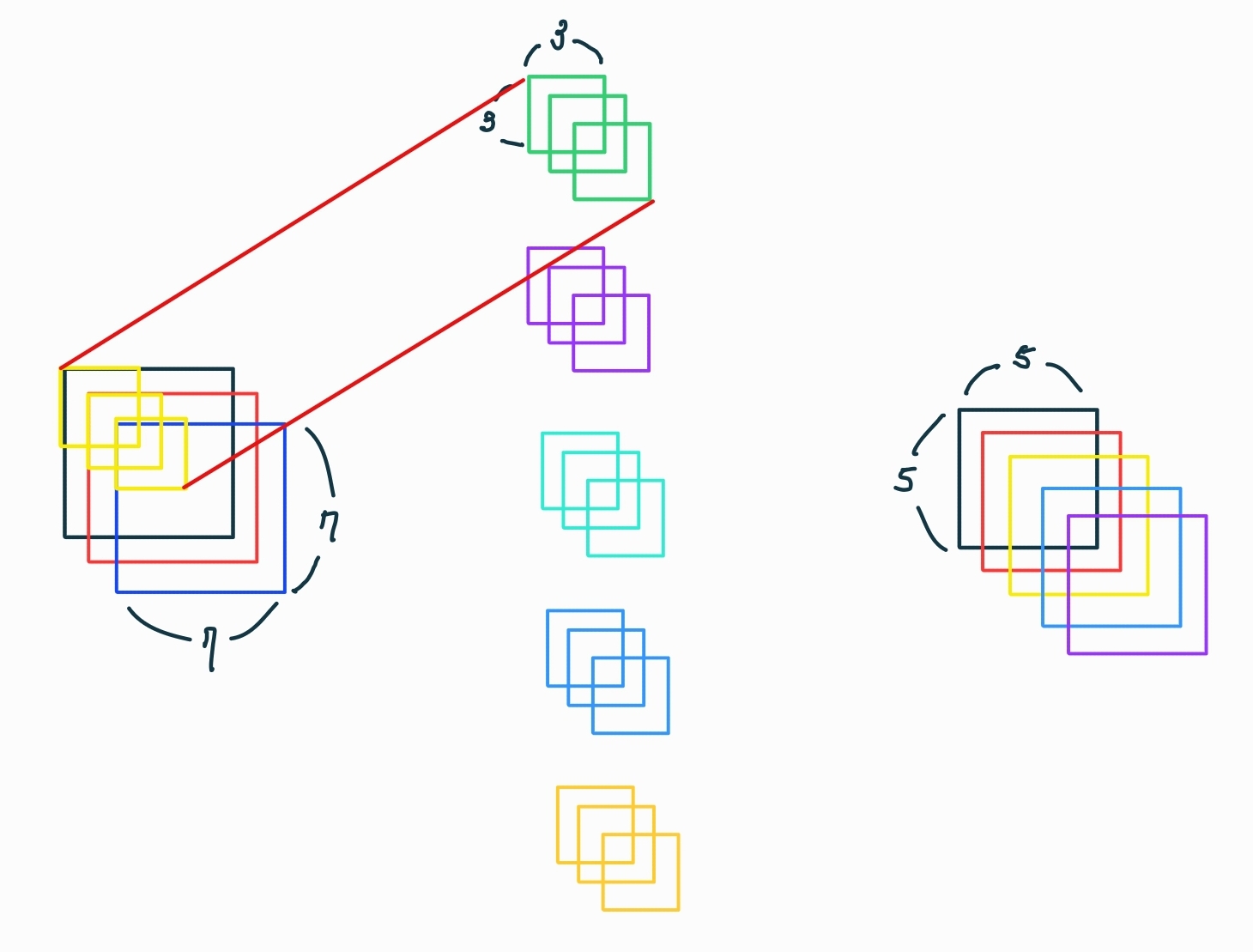
"극단적인" Inception 버전은, 1x1 컨볼루션을 사용하여 채널 간 상관관계를 매핑한 후, 각 출력 채널의 공간적 상관관계를 따로 매핑하는 방식입니다. 이는 그림 4에 나타나 있습니다. 이 극단적인 형태의 Inception 모듈은 사실상 depthwise separable convolution과 거의 동일합니다. 이 방식은 2014년부터 신경망 설계에서 사용되어 왔으며, 2016 TensorFlow 프레임워크에 포함되면서 더 널리 알려졌습니다.
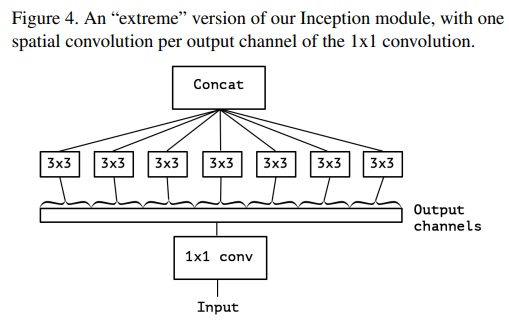
“극단적인” Inception 모듈과 depthwise separable convolution 간의 두 가지 주요 차이점은 다음과 같습니다:
-
연산 순서: Depthwise separable convolutions는 일반적으로 채널별 공간적 컨볼루션을 먼저 수행하고 그 다음 1x1 컨볼루션을 수행합니다 (예: TensorFlow에서의 구현). 반면, Inception 모듈은 1x1 컨볼루션을 먼저 수행합니다.
-
비선형성의 존재 여부: Inception 모듈에서는 두 연산 모두 ReLU 비선형성으로 후처리됩니다. 그러나 depthwise separable convolutions는 대개 비선형성이 적용되지 않습니다.
첫 번째 차이점은 이러한 연산이 스택 형태로 사용되기 때문에 중요하지 않다고 주장합니다. 반면, 두 번째 차이점은 중요할 수 있으며, 실험 섹션에서 (그림 10을 참조) 이에 대해 조사할 것입니다.
또한, 일반적인 Inception 모듈과 depthwise separable convolution 사이에는 중간 형태의 다른 Inception 모듈도 가능하다는 점을 주목해야 합니다. 사실, 정규 컨볼루션과 depthwise separable convolution 사이에는 독립적인 채널 공간 세그먼트의 수에 의해 매개된 이산적인 스펙트럼이 존재합니다. 한 쪽 극단에는 1x1 컨볼루션이 선행된 정규 컨볼루션이 있으며, 이는 단일 세그먼트에 해당합니다. 반대 극단에는 채널당 하나의 세그먼트가 있는 depthwise separable convolution이 있습니다. Inception 모듈은 이 사이에 위치하며, 수백 개의 채널을 3개 또는 4개 세그먼트로 나누어 처리합니다. 이러한 중간 형태의 모듈의 특성은 아직 탐색되지 않은 것으로 보입니다.
이러한 관찰을 바탕으로, Inception 모듈을 depthwise separable convolution으로 대체하여 Inception 계열 아키텍처를 개선할 수 있을 것으로 제안합니다.
💡2. Prior work
-
Convolutional Neural Networks
-
Inception module
-
Depthwise Separable Convolutions
-
Residual Connections
💡3. The Xception architecture
이 아키텍처의 기본 가설은 합성곱 신경망의 피처 맵에서 채널 간 상관관계와 공간적 상관관계를 완전히 분리할 수 있다는 것입니다. 이 가설은 Inception 아키텍처의 기본 가설보다 강한 버전이므로, 우리의 제안된 아키텍처를 "Xception"이라고 명명했습니다. Xception은 "Extreme Inception"의 약자입니다.
네트워크 사양
-
Xception 아키텍처는 36개의 합성곱 계층으로 구성된 피처 추출 기반을 갖추고 있습니다.
-
실험 평가에서는 이미지 분류만을 다루며, 따라서 합성곱 기반 뒤에는 로지스틱 회귀 계층이 추가됩니다. 선택적으로 로지스틱 회귀 계층 앞에 완전 연결 계층을 삽입할 수도 있으며, 이는 실험 평가 섹션(특히 그림 7과 8)에서 탐색됩니다.
-
36개의 합성곱 계층은 14개의 모듈로 구성되어 있으며, 모든 모듈에는 선형 잔여 연결이 적용됩니다. 단, 첫 번째와 마지막 모듈은 제외됩니다.
💡4. Experimental evaluation
우리는 Xception을 Inception V3 아키텍처와 비교하기로 결정했습니다.
그 이유는 두 아키텍처가 규모 면에서 유사하기 때문입니다. Xception과 Inception V3는 거의 동일한 수의 파라미터를 가지고 있어(표 3 참조), 성능 차이가 네트워크 용량의 차이 때문이라고 볼 수 없습니다.
비교는 두 가지 이미지 분류 작업에서 수행됩니다:
- ImageNet 데이터셋을 사용한 1000개 클래스 단일 레이블 분류 작업
- JFT 데이터셋을 사용한 17,000개 클래스 다중 레이블 분류 작업
이 두 작업을 통해 Xception과 Inception V3의 성능을 평가할 계획입니다.
4.2 Optimization configuration

두 데이터셋 모두 Xception과 Inception V3에 대해 같은 최적화 구성이 사용되었습니다. 이 구성은 Inception V3의 성능을 최적화하기 위해 조정된 것으로, Xception에 대해 최적화 하이퍼파라미터를 조정하지 않았습니다. 네트워크들이 서로 다른 학습 프로파일을 가지고 있기 때문에(그림 6 참조), 특히 ImageNet 데이터셋에서는 이 최적화 구성이 최적이 아닐 수 있습니다. ImageNet 데이터셋의 경우, Inception V3에 맞추어 신중하게 조정된 최적화 구성을 사용했기 때문입니다.
또한, 모든 모델은 Polyak 평균화 (Polyak Averaging) [13]을 사용하여 추론 시 평가되었습니다.
4.4. Training infrastructure
결과
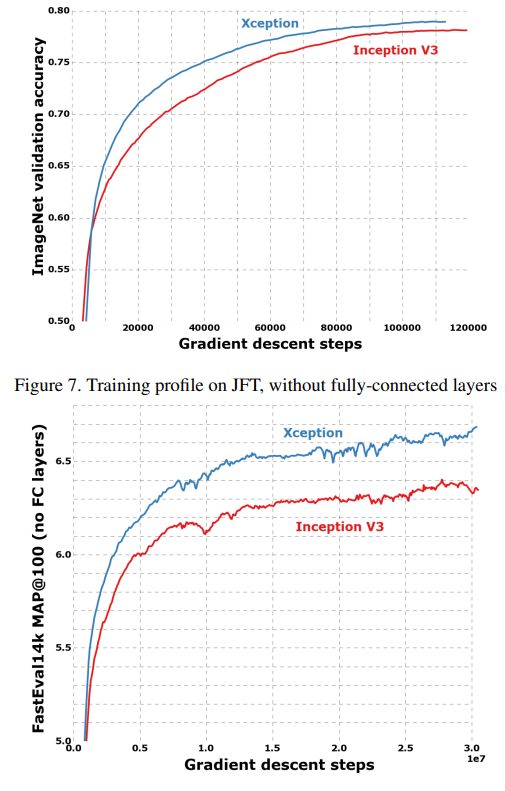
ImageNet에서 Xception은 Inception V3보다 약간 더 나은 성능을 보였습니다.
JFT에서 Xception은 4.3%의 상대적 개선을 보여주었습니다.
또한, Xception은 He et al.이 보고한 ResNet-50 및 ResNet-101과 152의 ImageNet 결과를 능가합니다.
4.5. Comparison with Inception V3
4.7. Effect of an intermediate activation after pointwise convolutions
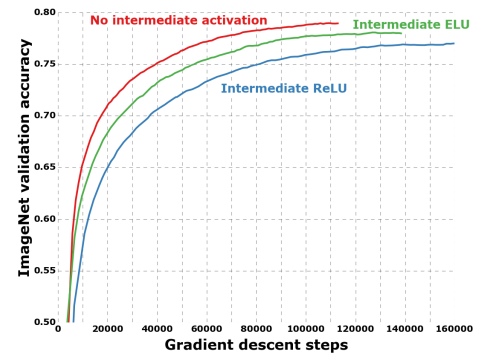
비선형성을 포함하지 않는 경우가 더 빠른 수렴과 더 나은 최종 성능을 보였습니다.
이 결과는 주목할 만합니다. Szegedy et al. [21]은 Inception 모듈의 경우 정반대의 결과를 보고했기 때문입니다. 비선형성이 유용성에 영향을 미치는 것은 중간 피처 공간의 깊이에 따라 달라질 수 있습니다.
깊은 피처 공간(예: Inception 모듈에서 발견되는 경우)에서는 비선형성이 도움이 되지만, 얕은 피처 공간(예: depth wise convolution의 1채널 깊은 피처 공간)에서는 정보 손실로 인해 비선형성이 해로울 수 있습니다.
대부분의 모델에서 활성화 함수를 사용함으로써 정확도가 더 상승하게 되는데, Xception에서는 반대로 활성화 함수를 사용하지 않을 때가 높은 정확도가 나옵니다.
이는 Inception과 동작 방식이 다르기 때문입니다.
Xception의 경우 1x1 컨볼루션으로 채널간 매핑을 해준 뒤, 공간적으로 3x3 컨볼루션을 합니다.
이 때 주의할 점이 있습니다.
3x3 컨볼루션 과정에서 모든 채널을 한번에 매핑한다면, 제가 그림으로 그려서 설명했던 것 처럼 채널+공간을 한번에 매핑하게 됩니다. 즉, 채널+(채널+공간) 맵핑이 되는 것이죠.
이를 방지하기 위해서, 3x3 컨볼루션을 할 때, 채널을 하나하나 따로 매핑해주게 됩니다.
그렇기에 채널 하나를 컨볼루션하는데 활성화 함수를 사용한다면 정보손실이 크다고 논문의 저자는 말합니다.
💡 6. Conclusions
우리는 합성곱과 깊이별 분리 합성곱이 이산 스펙트럼의 양 끝에 위치하며, Inception 모듈이 그 중간 지점에 해당한다는 것을 보여주었습니다. 이러한 관찰을 바탕으로 우리는 Inception 모듈을 깊이별 분리 합성곱으로 대체하는 제안서를 발표했습니다. 이 아이디어를 기반으로 하는 새로운 아키텍처, Xception을 제시했으며, Inception V3와 비슷한 파라미터 수를 가지고 있습니다.
Xception과 Inception V3의 성능 비교
ImageNet 데이터셋에서는 Xception이 Inception V3보다 소폭의 성능 향상을 보였습니다.
JFT 데이터셋에서는 Xception이 큰 성능 향상을 나타냈습니다.
우리는 깊이별 분리 합성곱이 미래의 합성곱 신경망 아키텍처 디자인의 핵심 요소가 될 것으로 기대합니다. 이들은 Inception 모듈과 유사한 특성을 제공하면서도 일반 합성곱 계층만큼 사용하기 쉬운 장점을 가지고 있습니다.
📌 finish
항상 논문리뷰를 하다보면 궁금증이 듭니다. 논문 저자는 왜 이런구조를 사용했을까? 이 활성화함수를 사용한 이유는 뭐지? 굳이 이 사이즈의 컨볼루션을 사용한 이유는 뭘까?
어떤 논문에서는 제대로된 설명이 없을 때도 있으며, 어떤 논문에서는 그 이유를 실험적으로 증명 해줍니다.
그런점에서 이 논문은 인상 깊었습니다. 저는 그저 1x1 컨볼루션을 파라미터 수를 줄이기 위해 사용한다고 알고 있었는데, 제대로된 용도와 사용법을 제시해주었습니다.
