기존까지의 GAN의 단점
PGGAN 이전의 GAN은 고해상도의 이미지를 생성 할 수 없었습니다.
→ 해상도가 높아 질 수록 Discriminator가 가짜와 진짜를 구분하기 쉬워집니다.
→ Generated distribution과 Real distribution 사이에 겹치는 구간이 거의 없어지고, Gradient가 무작위로 발산하게 됩니다.
점진적으로 이미지를 UpScaling 하는 학습방법 제안
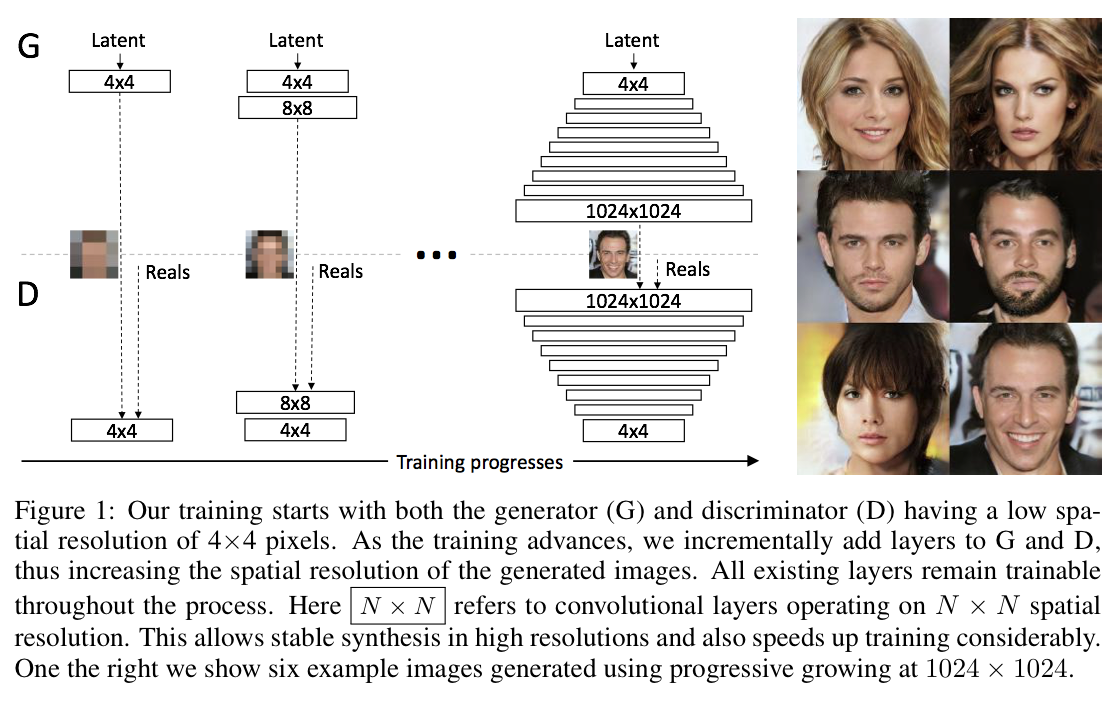
학습 구조
Generator는 4x4 크기의 이미지를 생성하는 Convolutional 신경망으로 구성됩니다.
Discriminator는 4x4 크기의 이미지를 입력으로 받아 진위여부를 판별하는 Convolutional 신경망으로 구성됩니다.
지정된 Epoch만큼을 반복 학습한 뒤,
Generator에는 끝 단에 8x8로 UpSampling 하는 Layer를 추가합니다.
Discriminator에는 가장 처음에 8x8의 이미지를 판별하는 Layer를 추가합니다.
위 단계에서, Generator에 단순히 8x8 크기의 Layer를 추가해서는 안됩니다. 왜냐하면, 4x4 Layer는 학습이 완료되어 진짜에 가까운 이미지를 생성하지만, 그 이미지를 입력으로 받는 8x8 Layer는 아직 학습되지 않은 가중치를 가지고 있기 때문입니다. 그냥 Layer를 추가하고 학습을 진행 할 경우, 오히려 8x8 단계에서 잘못된 이미지를 출력함으로써, Backpropagation 단계에서 잘 학습된 4x4 Layer의 가중치 조차도 잘못되도록 변경 할 수 있기 때문입니다.
따라서 PGGAN에서는 기존의 잘 학습된 4x4Layer가 생성하는 이미지와 새롭게 추가한 8x8 Layer가 생성하는 이미지를 결합하여 출력합니다.
.png)
실제 PGGAN 논문에 첨부된 이미지인데, smooth fadein 방법을 잘 설명하고 있습니다.
Generator를 기준으로 설명합니다.
(a) 16x16 Layer를 학습합니다.
(b) 32x32 Layer를 추가하는데, 16x16의 이미지를 단순하게 32x32로 UpScaling한 이미지 A와 그 이미지를 32x32 Layer에 넣은 이미지 B를 결합하는데, 임의의 변수 alpha를 사용하여, A*(1-alpha) + B*alpha 의 식으로 이미지를 합성하여 출력합니다. alpha는 0부터 1까지 점점 증가합니다.
(c) 충분히 학습이 되면(alpha 가 1이 되면) 더이상 16x16 Layer의 이미지를 생성하지 않고, 32x32 Layer의 이미지만으로 학습을 진행합니다.
.png)
이렇게 4x4 → 8x8 → 16x16 → ... → 512x512 → 1024x1024 까지 진행한다면 아래와 같이 고화질의 얼굴 이미지를 생성 할 수 있습니다.
