
아래 내용은 개인적으로 공부한 내용을 정리하기 위해 작성하였습니다. 혹시 보완해야할 점이나 잘못된 내용있을 경우 메일이나 댓글로 알려주시면 감사하겠습니다.
ResNet?
ResNet은 2015년 Microsoft에서 발표된 CNN Network이며 깊은 망을 더 쉽게 학습하기 위해 개발된 Network입니다.
많은 수의 layer를 누적하여 깊은 Network를 설계할 때 여러 문제가 발생합니다. ResNet은 shortcut-connection을 활용한 독특한 구조로 이러한 문제점을 해결하였고 1000층이 넘는 layer를 쌓은 네트워크를 성공적으로 학습했습니다.
ResNet구조를 바탕으로 2015년 ILSVRC에서 top-5 error 3.57%의 좋은 성적으로 1위를 차지하였습니다.
아래에서는 ResNet 구조를 발표한 논문인 Deep Residual Learning for Image Recognition을 바탕으로 ResNet의 특징과 실험결과를 정리하였습니다.
특징
DeepLearning에서 네트워크가 깊어질수록 성능이 올라가지만 학습이 어려워집니다.
ResNet은 네트워크의 깊이를 늘리면서도 안정적인 학습을 위해 Residual Learning이라는 개념을 적용했습니다.
Network의 깊이(depth)에 따른 영향
깊은(Deeper) 네트워크의 장점
Convolution연산을 활용한 Deeplearning Network는 영상처리분야 발전에 큰 영향을 주었습니다.
Deeplearning Network는 여러 layer를 거쳐가며 Edge, Corner와 같은 낮은 수준의 특징부터 추상적인 정보와 같은 높은 수준의 특징까지 추출해 나가는데, layer의 숫자가 쌓일수록(Network의 depth가 늘어날수록) 더 많은 정보를 추출하여 활용할 수 있습니다.
ResNet 논문이 발표되던 2015년 당시에도 VGG와 같은 깊은(very deep) 네트워크가 ILSVRC같은 여러 challenge에서 좋은 성능을 보여주고 있었습니다. 따라서 ResNet 개발자들도 망이 깊어질수록 성능이 좋아진다 라는 가정을 합니다.
깊은(Deeper) 네트워크 학습 시 문제점
하지만 많은 layer를 쌓는 경우 여러 문제로 인해 학습이 매우 어려워 집니다.
Network를 학습할 때 현재의 오차값을 줄이는 방향(Gradient)으로 파라미터를 업데이트하는데, layer를 거칠수록 Gradient가 너무 작아지거나 커지면 학습이 매우 느려지거나 멈춰버리는 현상인 Vanishing/Exploding Gradient가 발생 합니다. Vanishing/Exploding Gradient는 네트워크의 깊이가 깊어질수록 쉽게 발생합니다.
또한 네트워크가 깊어지면 학습데이터에 대해 과하게 학습하여 일반화 성능이 떨어지는 overfitting이 발생합니다.
ResNet 논문 저자들은 20-layer와 56-layer 네트워크를 활용해 자체적인 실험을 해본 결과 깊은 망에서 오히려 성능이 떨어지는 것을 확인했습니다.
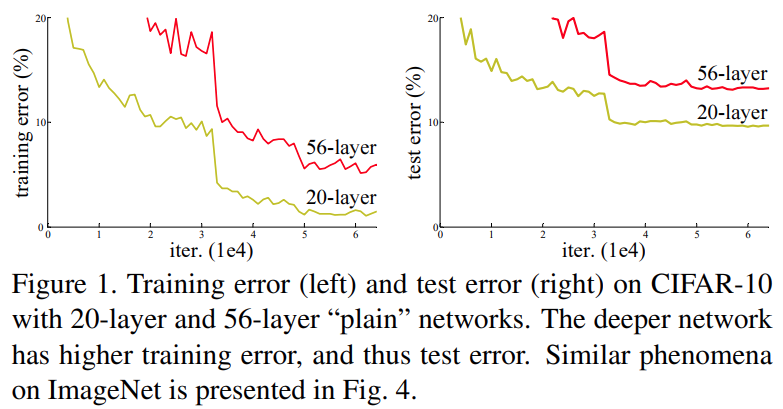
위 그림 오른쪽의 평가 결과를 보면 두 배 이상 깊은 56-layer의 성능이 더 떨어짐을 알 수 있습니다. 특이한 점은 학습시 오차를 나타내는 왼쪽 그래프에서 더 깊은 56-layer가 20-layer보다 error가 더 큰 것을 볼 수 있습니다. ResNet논문에서는 이러한 현상을 Degradation problem이라고 부릅니다.
만약 56-layer에서 Overfitting이 발생했다면 training error가 20-layer보다 더 작았을텐데, 실제로는 더 크기 때문에 overfitting이 발생하지 않았다고 판단할 수 있습니다.
논문에서는 특정 조건에서 깊은(deeper) 네트워크가 얕은(shallower) 네트워크보다 좋은 성능을 보여줄 수 있다고 합니다.
조건은 두 가지로, 첫 번째는 얕은 네트워크에서 추가된 layer가 identity mapping이어야 하고 두 번째는 네트워크 앞쪽 layer를 얕은 네트워크에서 학습된 layer를 사용하는 것 입니다.
추가실험을 했을 때 위 조건을 만족하지 않는 환경에서는 조건을 만족하는 상황의 깊은 네트워크보다 좋은 성능을 얻지 못했다고 합니다.
Residual Learning
Deep Residual Learning
ResNet에서는 Degradation 문제를 해결하기 위해 Deep Residual Learning을 제안합니다.
앞에서 깊은 네트워크가 얕은 네트워크보다 좋은 성능을 보여주기위한 조건 중 첫 번째는 얕은 네트워크 뒤에 추가된 layer가 identity mapping(입력값과 출력값이 같은 형태)이 되는것 입니다.
일반적인 딥러닝 네트워크는 쌓여진 layer들을 underlying mapping 하도록 (입력 x가 layer를 통과한 output이 목표값 y에 딱 맞도록) 학습합니다. 하지만 제안된 구조인 Deep Residual Learning은 residual(잔차, 입력과 출력의 차이)를 mapping 하도록 학습합니다.
Resnet 개발자들은 residual mapping이 기존의 underlying mapping보다 최적화하기 쉬울것이며, 따라서 layer들을 쌓은 구조를 학습하여 identity mapping이 되는것 보다 residual(잔차)가 0이 되도록 학습하여 identity mapping이 되도록 하는게 더 쉬울것이라고 가정합니다.
residual이 0이 되도록 학습된 layer를 얕은 네트워크 뒤에 추가한다면 training error가 얕은네트워크보다 작아지게 될 것입니다. (뒤에 추가된 값이 0이므로) 즉, degradation 현상이 없을 것 입니다.
또, 최적화한 layer가 identity mapping에 근접한다면 입력의 작은 변화를 찾아낼 수 있을것입니다.
이 residual mapping을 위해 아래 그림과 같은 shortcut connection이라는 구조를 포함한 block을 설계합니다.
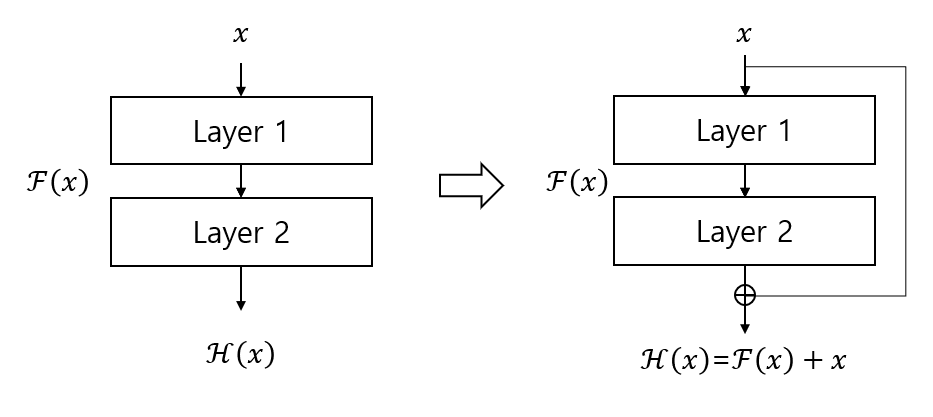
오른쪽의 residual learning block의 구조를 살펴보면 왼쪽의 기존 네트워크 구조에서 하나 이상의 layer를 넘어서 연결하는 shortcut(또는 skip) connection을 추가한것을 볼 수 있습니다.
shortcut connection은 입력값을 layer들을 통과한 출력값에 더하며, 추가적인 파라미터가 없고 연산량 증가가 크지 않은 장점이 있습니다. 또한 end-to-end 학습이 가능합니다.
실험 및 평가
ResNet논문에서는 성능비교를 위해 두 가지 모델을 비교했습니다. 모델 비교를 위해 ImageNet Dataset을 활용했습니다. 제안하는 구조인 Rresidual Learning의 성능을 확인하기 위해 단순히 3x3 Convolution layer를 쌓은 Plain Network와 Plain Network에 Shortcut connection을 추가한 Residual Network를 학습하며 결과를 비교했습니다. Network는 18-layer와 34-layer를 학습하며 비교했고, shortcut을 추가하고 망을 깊게 했을 때 성능을 확인하기 위해 50, 101, 152 layer까지 학습하며 그 결과를 확인했습니다.
Plain/Residual Network Architecture 설계
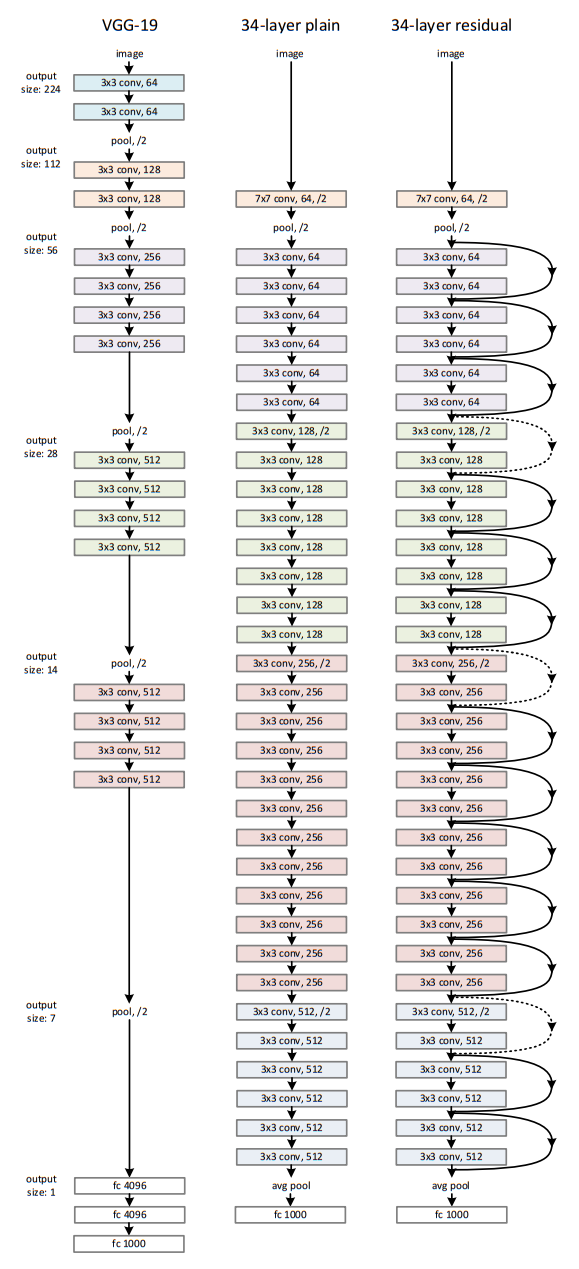
Plain Network
ResNet의 비교군으로 shortcut connection이 없는 Plain Network를 설계했습니다. Plain Network는 VGGNet과 유사한 형태로 3x3 Conv filter로 이루어져 있고 채널 수가 같은경우 같은 feature map size를 유지하며, feature map size가 절반으로 줄어들면 채널 수를 두 배로 늘립니다. feature map을 줄일 때는 Conv filter의 stride를 2로 합니다. 제일 끝에는 Global Average Pooling 후 1000개의 FC Layer가 붙습니다. 가중치가 있는 layer의 개수는 34개 입니다.
Plain Network는 VGGNet보다 필터수가 적고 간단한 구조입니다. 34개의 layer는 36억 Flops로 VGGNet의 18%입니다.
Residual Network
Residual Network는 Plain Network를 바탕으로 Shortcut connection을 추가하는 방식으로 설계 되었습니다.
ResNet에서 residual block을 설계할 때 입력은 출력과 항상 같아야 합니다. 입력과 출력의 차원(feature map의 크기)가 동일하다면 입력과 출력을 다이렉트로 연결합니다. 만약 입력과 layer를 통과한 출력의 차원이 다르다면 두 가지 방법으로 차원을 조절합니다. 첫 번째는 단순히 zero padding하는것으로 추가적인 파라미터가 없습니다. 두 번째는 projection shortcut하는 방법으로 차원을 맞추기 위해 1x1 Conv Filter를 통과시킵니다.
실험
ResNet논문에서 실험은 Imagenet 2012 classification 데이터셋을 활용해 진행했습니다.
Plain Network vs Residual Network
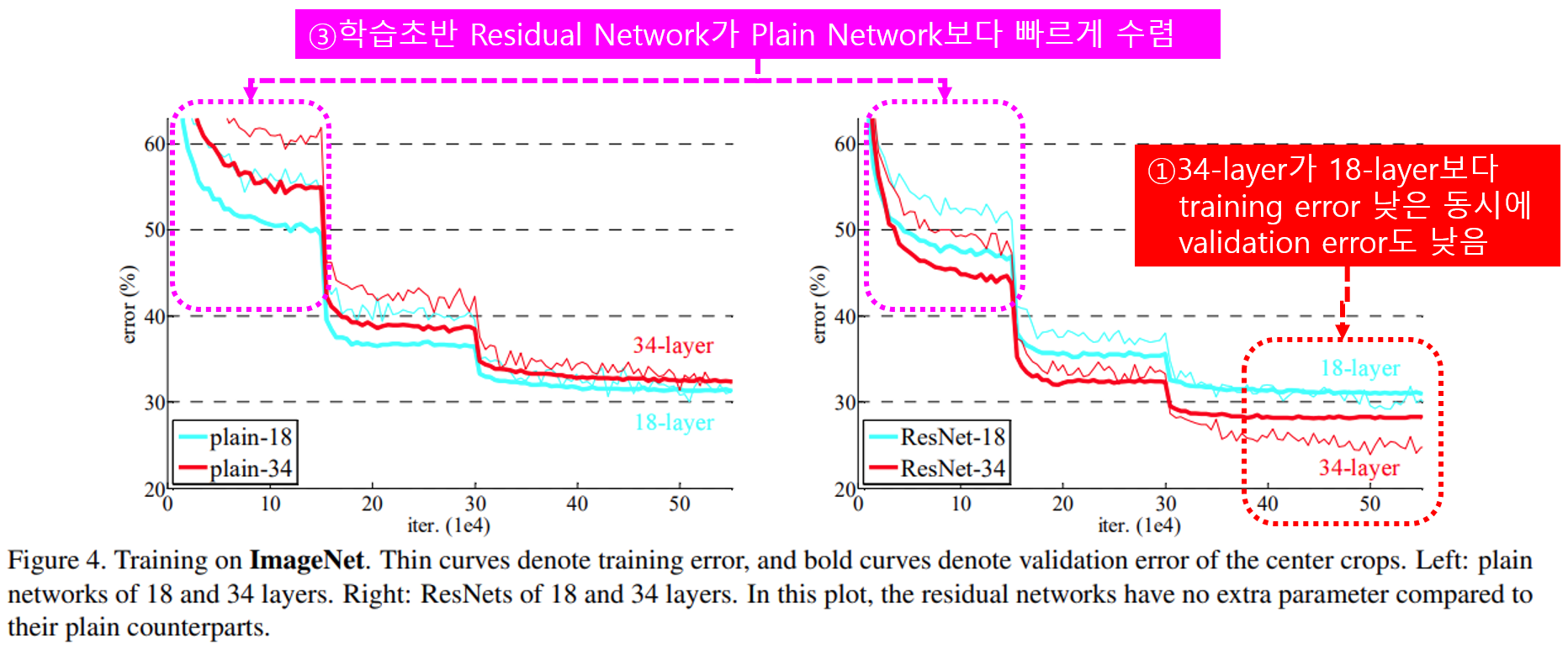
먼저 18-layer와 34-layer의 Plain Network를 학습했을 때 training error와 validation Error를 비교해보니 아래 그래프와 같이 얕은 망인 18-layer보다 더 깊은 망인 34-layer 네트워크에서 더 큰 validation error가 발생합니다.
왼쪽 그림인 plain network 학습결과 그래프에서 validation error(굵은 실선)와 training error(얇은 실선) 모두 34-layer가 큰 degradation 문제가 발생하는것을 볼 수 있습니다.
반면 오른쪽의 Residual Network의 경우 34-layer의 validation error와 training error 모두 18-layer보다 작은것을 볼 수 있습니다.
각각의 네트워크의 학습된 결과에 대해 top-1 error를 확인해보면 아래 표와 같습니다.

위 결과에서 중요점 세 가지 확인할 수 있습니다.
첫 번째로 ①ResNet에서 34-layer가 18-layer 성능이 좋으며, 18/34 layer인 plain network와 비교했을 때도 더 낮은 training error를 보여준다는 점 입니다. 이 결과로부터 제안하는 residual learning이 깊은 망에서 training error가 더 큰 degradation 문제를 해결함을 확인할 수 있습니다.
두 번째는 ②resnet이 같은 구조의 plain network과 비교했을 때 training error를 줄이는 동시에 더 작은 top-1 error를 보여주어 residual learning이 깊은 망에서 효율적임을 증명합니다.
마지막으로 세 번째로 ③resnet에서 학습 시 더 빠르게 수렴한다는 것 입니다. 위의 학습그래프에서 학습 초반부를 보면 resnet이 plain network보다 더 가파르게 수렴하는 것을 볼 수 있습니다.
Identity Shortcut vs Projection Shortcut
앞에서 Residual Network를 구성할 때 차원이 다른경우 shortcut을 구현하는 방법을 두 가지 소개했습니다.
첫 번째는 zero-padding하여 차원을 맞추는 것(Identity shortcut)이고, 두 번째는 Linear Projection(1x1 Convolation layer를 통과)를 활용해 차원을 맞추는 것(Projection shortcut) 입니다.
Identity shortcut와 Projection shortcut 의 차이를 확인해보기 위해 ResNet 논문에서는 아래 세 가지 네트워크를 구성합니다.
- (A) : zero-padding(identity) shortcut만 사용
- (B) : 차원이 같은경우 identity, 차원이 다른경우 projection shortcut 사용
- (C) : projection shortcut만 사용
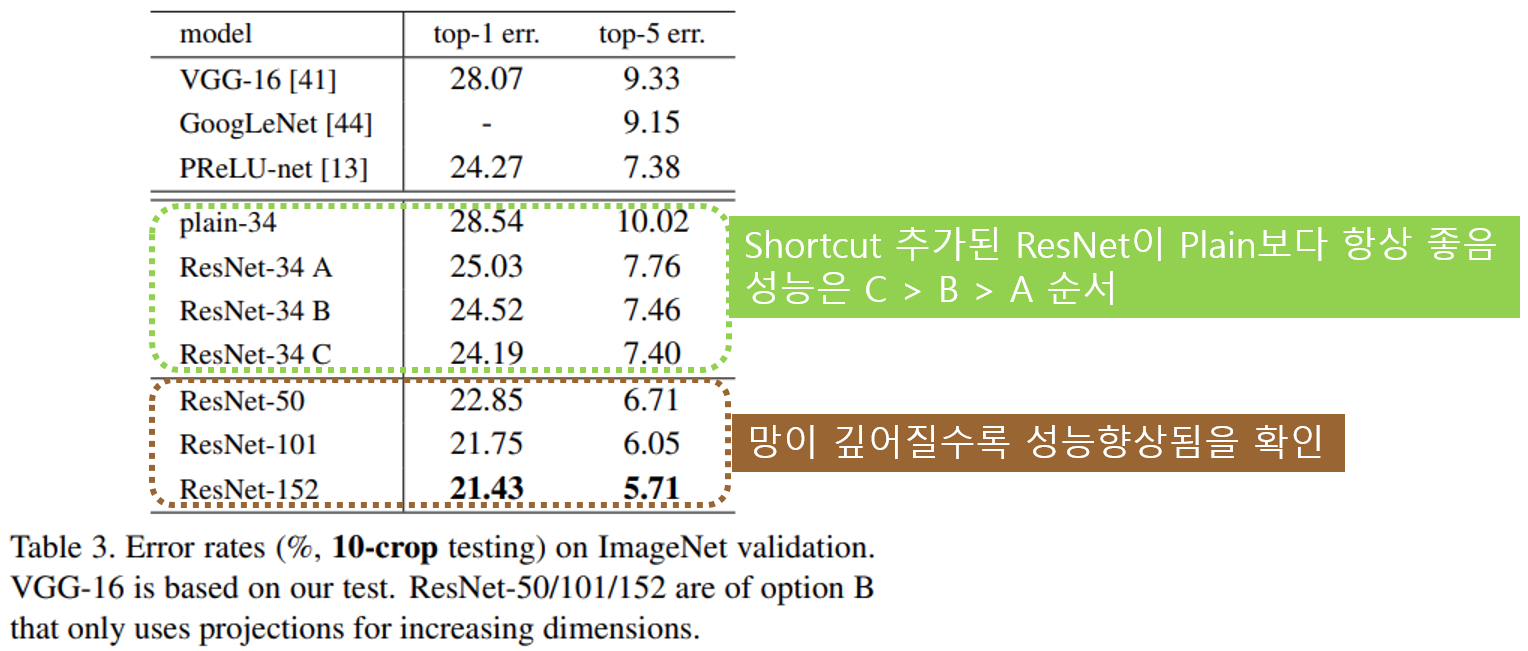
실험 결과에서 A, B, C 모든 경우에서 plain network보다 성능이 좋았습니다. 좀더 상세히 보면, 성능은 projection shortcut을 많이 사용한 C가 가장 좋았으며, B가 그다음, A가 가장 안좋았습니다.
논문에서 identity shortcut의 성능이 떨어지는 이유는 zero-padding한 영역에서는 residual learning이 되지 않았기 때문이라고 추정했습니다. 하지만 A/B/C 의 차이는 작았기 때문에 projection shortcut이 필수는 아니라고 판단 했습니다. 따라서 네트워크의 복잡도와 메모리 사용량을 줄이기 위해 C네트워크는 나머지 실험에서 사용하지 않았습니다.
Bottleneck 구조를 활용한 더 깊은망 설계
논문에서 다음으로 더 깊은 망에서의 성능을 확인하기위해 50/101/152 layer의 네트워크를 설계합니다.
이때 학습시간이 너무 오래걸리는 것을 피하기 위해 Bottleneck구조의 Residual block이 활용됩니다. Bottleneck구조는 아래 그림과 같이 1x1 Convolutional layer를 활용해 네트워크의 차원을 줄였다가 3x3 Conv layer 통과 후 다시 차원을 원래 크기로 늘리는 구조입니다. Bottleneck 구조에서 projection shortcut을 사용하면 모델크기가 두 배가되기 때문에 identity shortcut만 사용합니다.
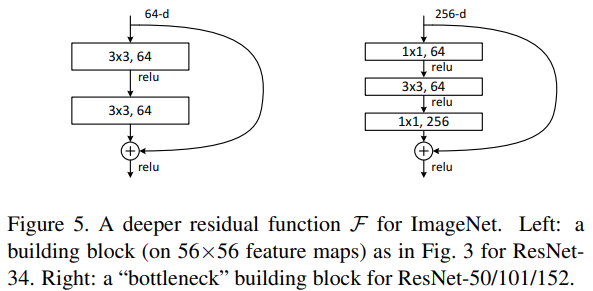
50-layer는 34-layer의 block을 bottleneck 구조로 변경하여 사용합니다. 그 결과 모델의 Flops는 38억이 됩니다. 차원이 바뀌는 순간의 short은 projection shortcut을 사용하는 B구조 입니다.
같은 방식으로 101/152 layer의 ResNet을 구성합니다. 152층이나 쌓이면서 네트워크 크기가 매우 커졌지만(11.3 billion Flops), 여전히 VGG(15.3/19.6 billion Flops)보다 단순하고 가벼운 크기입니다.
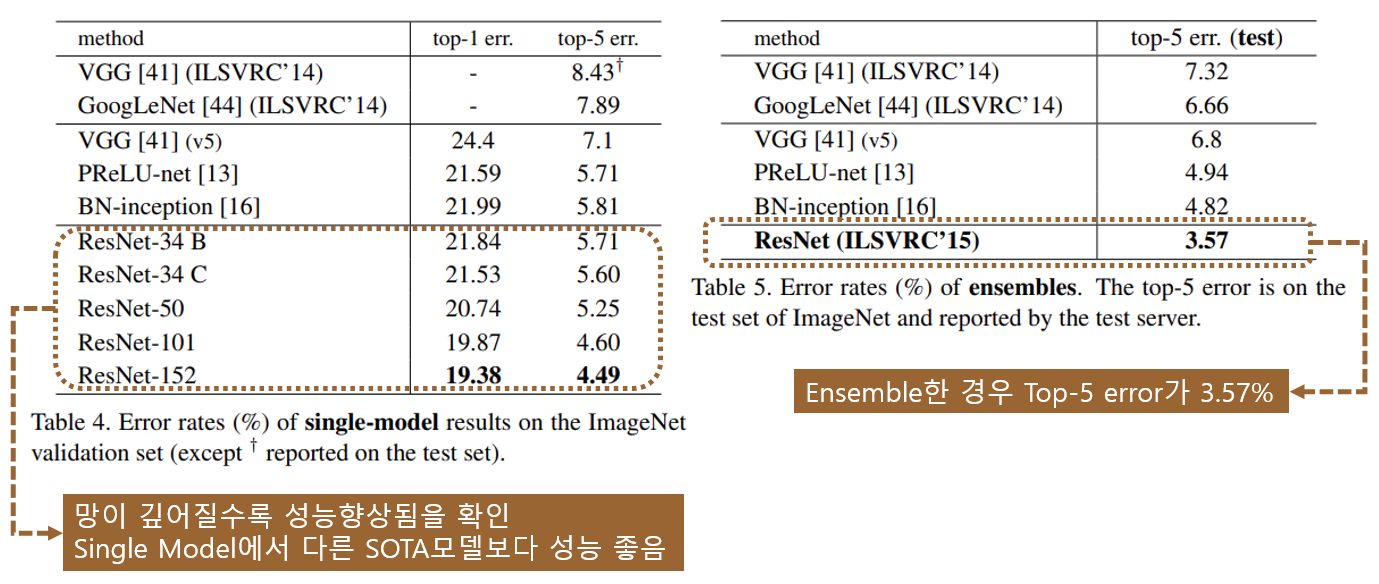
성능은 망이 깊어질수록 성능이 향상되며 degradation 문제는 발생하지 않았습니다.
다른 SOTA 모델들과 비교해서도 성능이 좋으며, Ensemble한 경우 Top-5 error가 3.57%로 ILSVRC 2015에서 가장 좋은 성능을 보여줍니다.
추가실험
1) Cifar-10 데이터셋에서 평가
ResNet은 Cifar-10에서도 테스트됩니다. SOTA달성이 아닌 깊은망에서의 성능을 확인하기 위한 테스트이기 때문에 간단한 네트워크만 사용합니다.
(상세한 학습설정은 논문에 자세히 정리되어 있습니다. 필요하신분은 논문을 참고해주시기 바랍니다.)
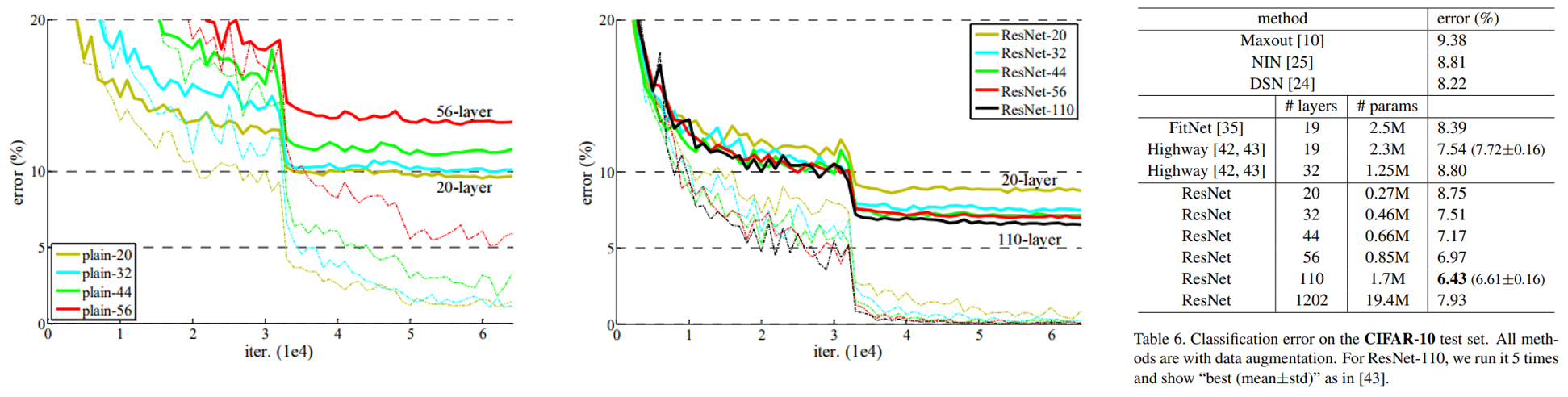
학습 결과는 ImageNet을 학습했을 때와 유사합니다. plain network에서는 degradation 문제가 발생하지만, Resnet에서는 망이 깊어질수록 degradation문제 없이 성능이 좋아지는 것을 볼 수 있습니다. 따라서 ResNet은 깊은 망에서 최적화가 어려웠던 문제를 해결했다고 볼 수 있습니다. 또한 FitNet, Highway 보다 적은 파라미터를 쓰지만 성능은 더 좋은것을 볼 수 있습니다.
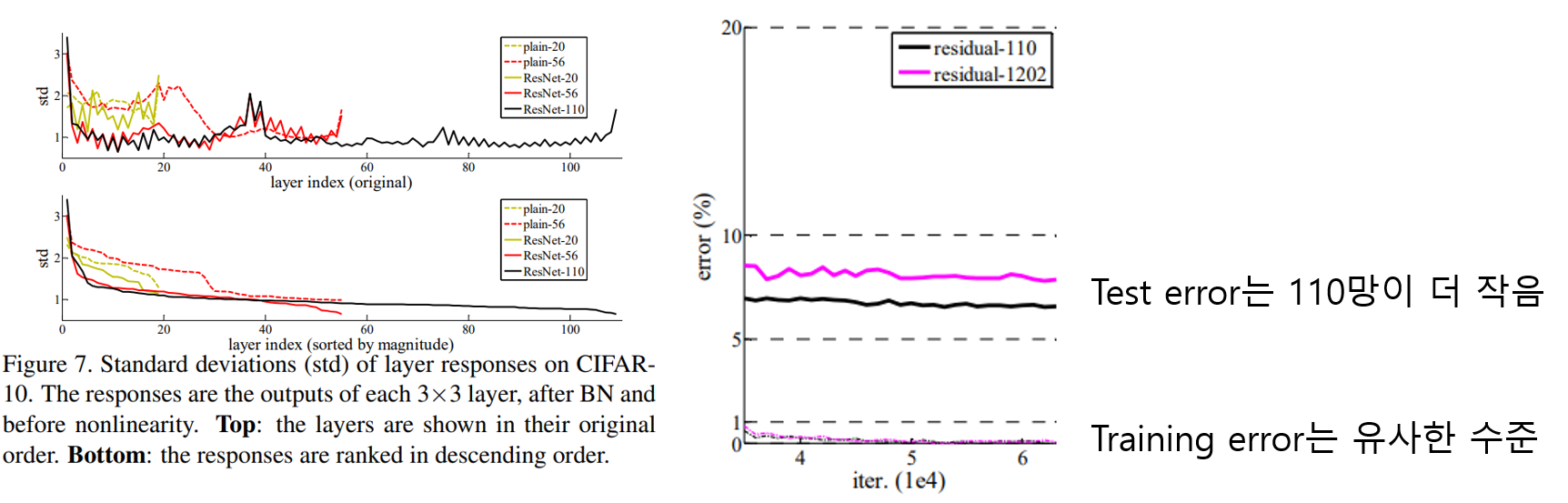
2) layer response
다음으로 Convolution과 Batch Normalization을 통과한 신호의 세기에 대해 표준편차를 확인했습니다. 아래쪽 그래프 결과를 살펴보면 전체적으로 resnet이 같은 깊이의 plain network보다 신호가 더 작은 것을 볼 수 있습니다. 또한 깊은 망일수록 신호가 작은것을 볼 수 있습니다.
이러한 결과는 처음 의도했던대로 각 layer가 0이 되도록, 즉 residual block이 identity mapping이 되도록 학습된다는 것을 알 수 있습니다. 또한 망이 깊어질수록 각 layer의 신호가 더욱 작아져서 residual block이 더욱 identity mapping이 되도록 최적화됨을 알 수 있습니다.
3) 1000 layer가 넘는 구조 설계
마지막으로 네트워크를 매우 깊게 설계한 경우 어떠한 결과가 나오는지 확인하기 위해 1202-layer 네트워크를 설계 후 테스트 했습니다. 그 결과 매우 깊은 망에서도 네트워크를 학습하여 최적화하는것은 문제가 되지 않았습니다.
특이한점은 더 깊은 1202-layer의 네트워크가 110-layer 네트워크보다 성능이 안좋게 나왔습니다. 논문에서는 네트워크 크기에 비해 데이터가 너무 작기 때문에 overfitting 발생한 것으로 추정했습니다. 여기서 발생한 overfitting은 maxout, dropout같은 regularization 기법으로 해결할 수 있을 것이라고 밝혔습니다. 하지만 매우 깊은망에서 최적화가 가능한지만을 확인하기 위한 실험이기 때문에 추가적인 실험은 진행하지 않았다고 합니다.
4) Object Detection에 적용
마지막으로 다른 task에서도 좋은 성능을 보여주는지 증명하기 위해 resnet을 object detection에도 적용해 보았습니다. PASCAL VOC 2007, 2012데이터셋과 COCO 데이터셋을 활용하였고, Faster R-CNN의 backbone인 VGG-16을 resnet-101로 변경 후 성능을 확인했습니다.
실험결과 좋은 성능을 보여주었고, 2015년의 네 개 부분(ILSVRC detection, ILSVRC localization, COCO detection, COCOsegmentation)에서 모두 1등을 차지하였습니다.
이런 결과로부터 object detection이나 segmentation과 같은 다른 task에서도 좋은 성능을 보여주는것을 증명했습니다.
마무리
ResNet은 깊은 망을 최적화할때 발생하는 문제를 shortcut을 활용한 간단한 구조로 해결한 참신한 논문입니다. Resnet에서 제안한 residual learning과 shortcut은 이후에 발표되는 네트워크들에서도 사용되는 기본적인 내용이기때문에 꼭 알고가야할 내용이라고 생각됩니다.
이 논문이 발표된 뒤 resnet의 성능으 더욱 끌어내기 위한 Pre-Activation에 대한 연구도 진행되었습니다. 해당내용은 다음 글에서 다루도록 하겠습니다.
참고자료
