
아래 내용은 개인적으로 공부한 내용을 정리하기 위해 작성하였습니다. 혹시 보완해야할 점이나 잘못된 내용있을 경우 메일이나 댓글로 알려주시면 감사하겠습니다.
Residual Block의 구조
2015년 Microsoft 연구원들은 Skip connection을 활용한 Deep Residual Learning 이라는 방법을 이용해 매우 깊은 네트워크를 학습(최적화)하는데 성공했습니다. Deep Residual Learning의 기본 아이디어는 layer가 identity mapping이 되도록 하는것이며, 이를 위해 skip-connection이라는 구조를 활용하니다.
ResNet은 깊은 망을 학습할 수 있고 좋은 성능을 보여주었지만 아직 개선의 여지가 있음을 Identity Mappings in Deep Residual Networks 에서 증명했습니다.
기존 ResNet 구조
ResNet에서는 2개 이상의 Convolutional Layer와 skip-connection을 활용해 하나의 블록을 만들고 그 블록을 쌓아서 네트워크를 만듭니다. (여기서 BottleNeck 구조는 다루지 않습니다.)
하나의 블록을 블록의 구조와 수식은 아래 그림과 같습니다.
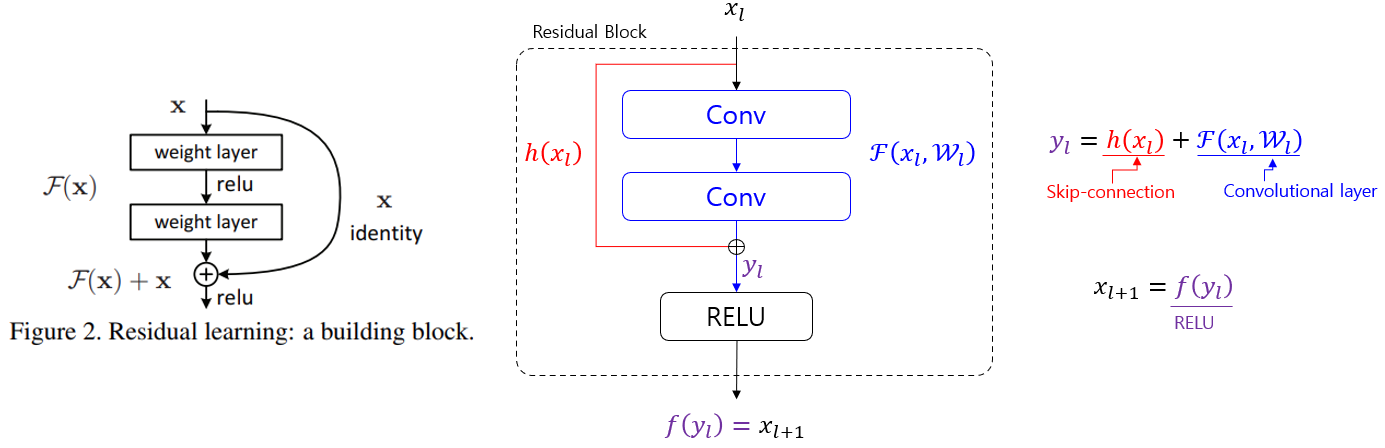
위 그림의 Residual Block은 번 째 블록으로 을 입력으로 받고 skip-connection인 과 Connvolutional layer 를 통과한 결과의 합으로 을 출력합니다. 마지막으로 출력 을 활성함수를 통과시키면 다음 블록의 입력 이 됩니다.
Residual Block이 vanishing gradient를 피하는 원리
앞절의 수식에서 활성함수 를 identity-mapping 이라고 가정하면 이 되고, 수식으로 정리하면 다음과 같습니다.
이 식으로부터 일반화식을 표현하면 다음과 같이 나타낼 수 있습니다.
Loss function의 gradient의 계산식은 backward propagation chain rule로 부터 아래 식으로 나타낼 수 있습니다.
위 식에서 우리는 가 두 개 값의 합으로 분해할 수 있다는것을 알 수 있습니다.
먼저 (1)앞부분의 는 weight layer와 무관하게 다이렉트로 전파되는 정보입니다. 따라서 정보는 어떤 layer든 정보가 전파됩니다.
(2)뒷 부분의 은 weight layer를 거쳐 전파되는 정보입니다.
backward propagation을 할 때 이 0이 되기 위해서는 weight layer를 거쳐 역전파되는 값이 -1이 되어야 합니다.
실제 학습을 할 때 전체 데이터를 한번에 학습하는것이 아닌 데이터의 일부분씩 학습하는 mini-batch방식이 사용되는데, 모든 mini-batch에서 역전파값이 -1이 되는것은 불가능에 가깝습니다. 때문에 은 항상 0이 아닌 어떠한 값을 갖게 되고, 역전파된 값이 0에 가깝게 되는 vanishing gradient가 발생하지 않게 됩니다.
이 수식에서 skip-connection인 과 활성함수인 를 identity-mapping이라고 가정했습니다. 그렇다면 과 이 identity-mapping이 아닌경우는 어떻게 될까요?
Skip connection의 변경
skip-connection이 identity-mapping이 아닌 경우
skip-connection 을 이라고 가정해보겠습니다. (λ는 modulating scalar 입니다. 활성함수 f는 여전히 identity-maping이라고 가정합니다.)
이 때, 앞 장에서 정리한 수식과 같이 정리하면 다음과 같습니다.
여기서 내부를 정리하면 아래 식과 같이 나타낼 수 있습니다. 는 scalar 부분을 흡수한 형태입니다.
정리한 식에서 loss function의 gradient를 계산하면 다음과 같습니다.
앞장의 식과는 다르게 weight layer와 무관하게 전파되는 정보가 의 곱 형태인 로 나타납니다. 따라서 λ값이 1이 아닌 경우에 layer가 깊어지면 의 값은 매우 작거나 매우 커지게 되고, 따라서 weight layer와 무관하게 전파되는 정보가 소실되거나 매우 크게 증폭될 수 있습니다.
예를들어 가 단순히 0.9인 경우 한없이 곱하다보면 나중엔 0에 가까운 값이 되고, 결과적으로 weight layer와 무관하게 전파되는 정보의 gradient가 소실(vanishing)되어 버립니다. 반대로 1.1인 경우 한없이 곱하다 보면 나중엔 무한대에 가까운 값이 되어 gradient가 매우 커지는 문제가 발생합니다.
정리한바와 같이 skip-conection시 입력에 어떠한 값을 곱하는 경우 정보 전달에 악영향을 미치고, 최적화(학습)을 어렵게 만듭니다.
skip-connection 변형 후 성능 평가
논문에서는 실험을 통해 skip-connection이 identity-mapping이 아닌 경우의 성능을 측정했습니다.
실험은 ResNet-110에서 skip-connection의 형태 6가지를 설정하고 학습하여 성능을 평가했습니다. 성능평가는 scratch에서 CIFAR데이터에서 5번 학습한 뒤 accuracy의 중간값을 사용했습니다.
여섯 종류의 skip-connection(shortcut)은 아래와 같습니다.
| 타입 | 형태 | 특징 |
|---|---|---|
| (a) original | 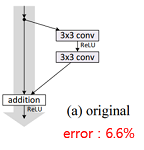 | - ResNet에서 사용한 기본 구조 - 입력을 그대로 전달 - 가장 성능이 좋음 |
| (b) constant scaling | 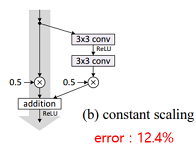 | - 입력과 출력에 scalar값을 곱함 - weight layer에 λ값을 곱 - shortcut에는 (1-λ)를 곱 - 실험에서 λ는 0.5를 사용 |
| (c) Exclusive gating | 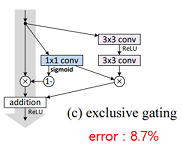 | -gating function )을 곱함 - shortcut에는 를 곱함 - 학습시 의 바이어스 의 초기값에 영향을 크게 받음 - 0 ~ -10값 중 최적값을 찾아 활용 - 가 0에 가까워지면 shortcut만 남아 identity-mapping에 가까워져 성능이 좋음 |
| (d) shortcut-only gating | 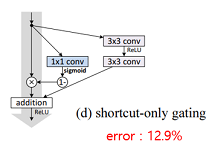 | - shortcut에만 gating function 적용 - (c)와 마찬가지로 가 0에 가까워지면 성능이 좋아짐 (원래 ResNet과 동일한 형태) |
| (e) conv shortcut | 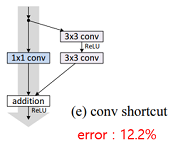 | - ResNet논문에서 projection shortcut과 동일 - ResNet논문과는 다르게 항상 성능이 좋아지지는 않음 - 깊이에 따라 성능이 좋아지기도 나빠지기도 함 |
| (f) dropout shortcut | 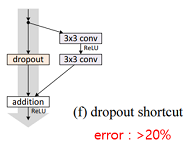 | - Shortcut에 Dropout을 적용 - 학습수렴에 실패 |
실험 결과에서 입력 그대로 전달하는 원래 구조가 가장 성능이 좋은 것을 볼 수 있습니다. 결과로부터 shortcut에 어떠한 조작을 가하는 것은 정보 전달에 악영향을 주고, 최적화를 어렵게 만든다고 결론 내릴 수 있습니다.
Pre-Activation
앞 장의 실험은 활성함수 가 identity-mapping이라는 가정했습니다. 하지만 Resnet에서 사용하는 residual block에서 활성함수 는 ReLU함수이며, shortcut된 신호와 합쳐지는 곳 뒤에 위치합니다. 논문의 저자들은 를 identity-mapping으로 만들기 위해 새로운 residual block을 제안합니다.
아래 그림은 논문 저자들이 제안한 여러 구조들이며 밑에는 제안된 구조를 사용하여 cifar-10을 학습 후 test-set에서의 error를 나타냅니다. 실험할 때 weight layer는 2개의 Convolutional layer가 아닌 Bottleneck구조를 사용합니다.
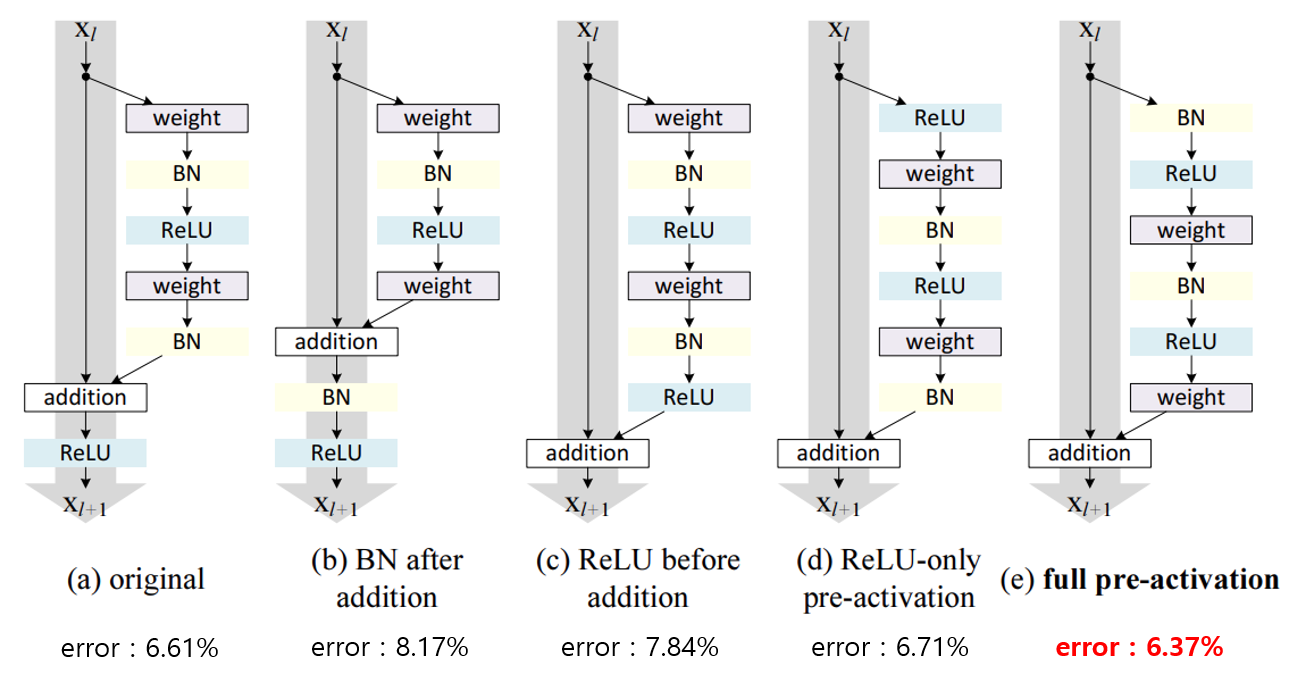
(a) 구조는 resnet논문에서 제안된 가장 기본적인 구조입니다. shortcut된 신호와 합쳐지는 addtion연산 뒤 ReLU함수를 통과합니다.
(b) 구조에서는 마지막 Batch Normalization을 addtion연산 뒤로 옮겼습니다. 학습한 결과는 원래 형태인 post-activation 보다 나빠진 error 8.17%가 되는것을 볼 수 있습니다.
(c) 구조는 활성함수 ReLU를 weight layer안으로 옮겨, ReLU를 통과한 신호를 shortcut한 신호와 합치는 구조입니다. 이 아이디어는 좋아보이지만, 잔차를 학습할 때 신호 값의 범위가 양수가 되어 forward propagation시에 신호가 양수로 편향됩니다. 따라서 네트워크의 표현력이 낮아져 성능이 나빠집니다.
여기서 논문 저자들은 resnet에서 신호 범위가 양수가 아닌 전체 실수영역 (- ~ )을 가져야 한다고 예상합니다. 따라서 뒤에 나오는 새로운 구조는 신호범위가 (- ~ ) 이도록 설계합니다.
(d), (e) 구조는 에서 비대칭(asymmetric)적인 구조로 신호가 weight layer를 먼저 통과하는 구조가 아닌 Activation(ReLU, Batch Normalization) 앞에 위치시키는 구조 입니다.
아래 그림에서 왼쪽에 위치한 기본구조에서 활성함수가 weight layer를 거쳐가는 신호에만 영향을 주도록 가운데 그림의 구조로 변경합니다. 그 다음 동일한 구조에서 residual unit의 영역을 수정하여 pre-activation 구조를 설계합니다.
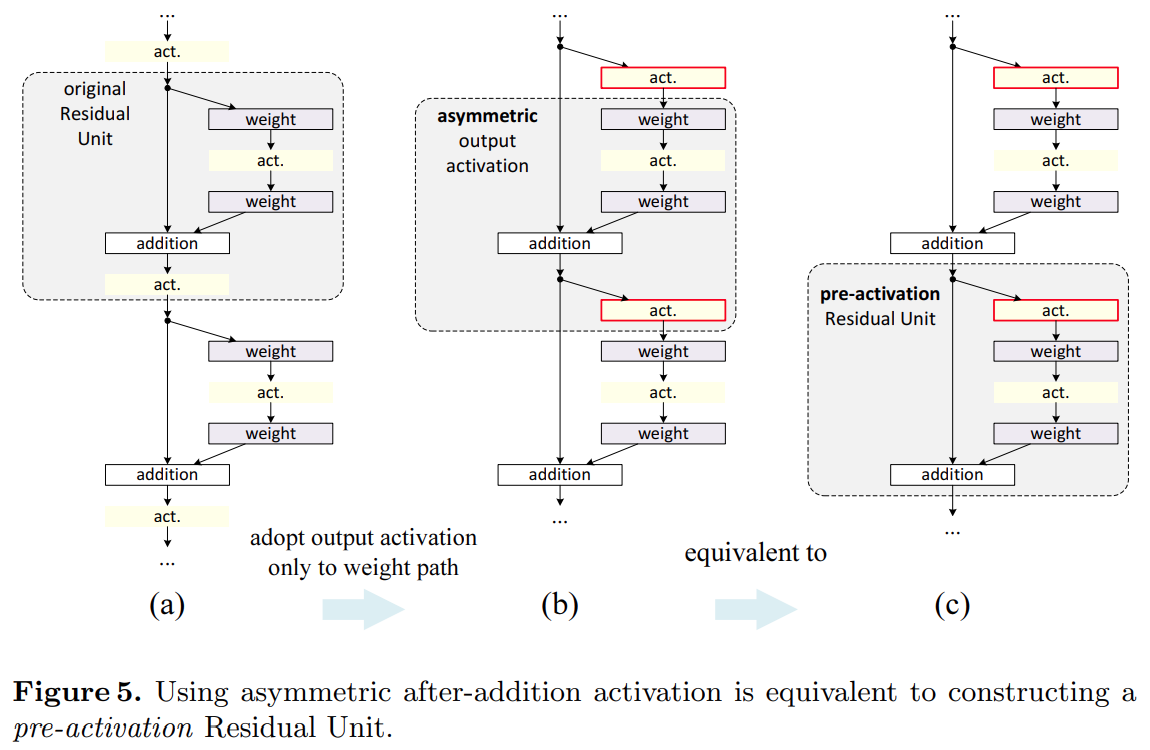
(d) 구조는 ReLU만 weight 앞에 위치시킨 구조입니다. 기본구조인 (a)보다 미미하게 성능이 낮은것을 볼 수 있습니다.
(e) 구조는 Batch Normalization과 ReLU 모두 weight앞에 위치한 full pre-activation 구조로 기본구조보다 좋은 성능을 보여줍니다.
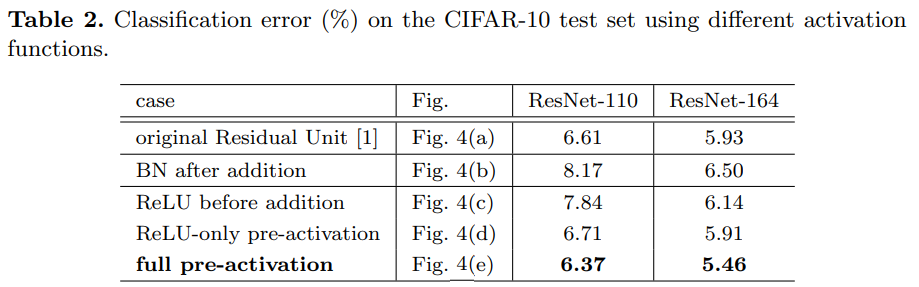
논문에서 가져온 위 Table 2를 보면 full pre-activation 일 때 ResNet-110/164 모두 가장 좋은 성능을 보여주는 것을 볼 수 있습니다.
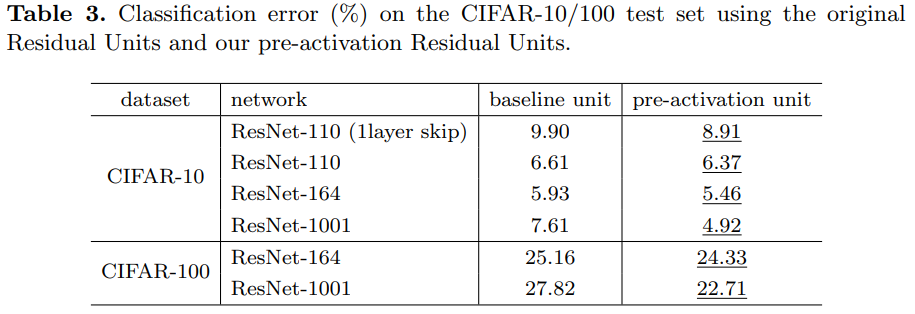
Table 3에서 Depth를 110부터 1001까지 바꿔가며 Cifar-10/100 에서 테스트해본 결과 모든 경우에 pre-activation 구조가 성능이 좋은 것을 볼 수 있습니다.
따라서 pre-activation 이 post-activation보다 더 성능이 뛰어나다고 볼 수 있습니다.
성능 분석
post/pre-activation 구조의 경향 비교
Pre-activation이 주는 긍정적인 영향 중 첫 번째는 활성함수 가 identity-mapping이 되어 최적화하기 쉬워진 것입니다.
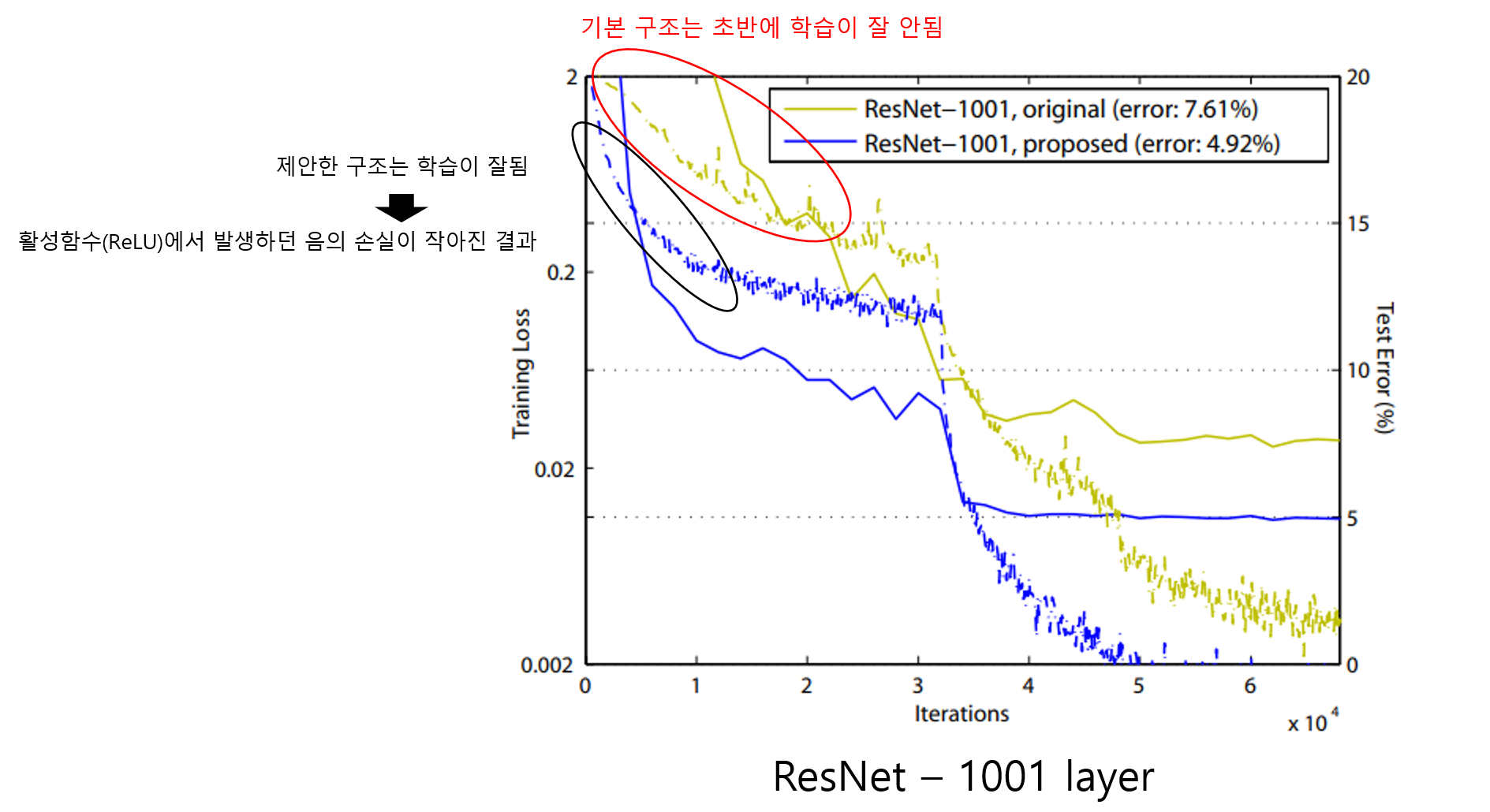
Resnet의 post-activation 구조 에서는 ReLU로 인해 음수 신호가 모두 사라집니다. 깊은 망일수록 이러한 음의 영역 신호손실이 많이 발생하여 제일 처음 가정했던 아래 식이 만족하지 않게 됩니다.
이러한 현상은 ResNet-1001을 학습 할 때 확인할 수 있습니다. post-activation 구조에서 학습할 경우 초반에 학습이 잘 이루어지지 않는 경향이 있지만 pre-activation 구조에서는 처음부터 학습이 잘 이루어집니다.
Pre-activation이 주는 긍정적인 영향 중 두 번째는 Batch Normalization 의 영향으로 regularization(정규화)되어 일반화가 잘되는 것 입니다.
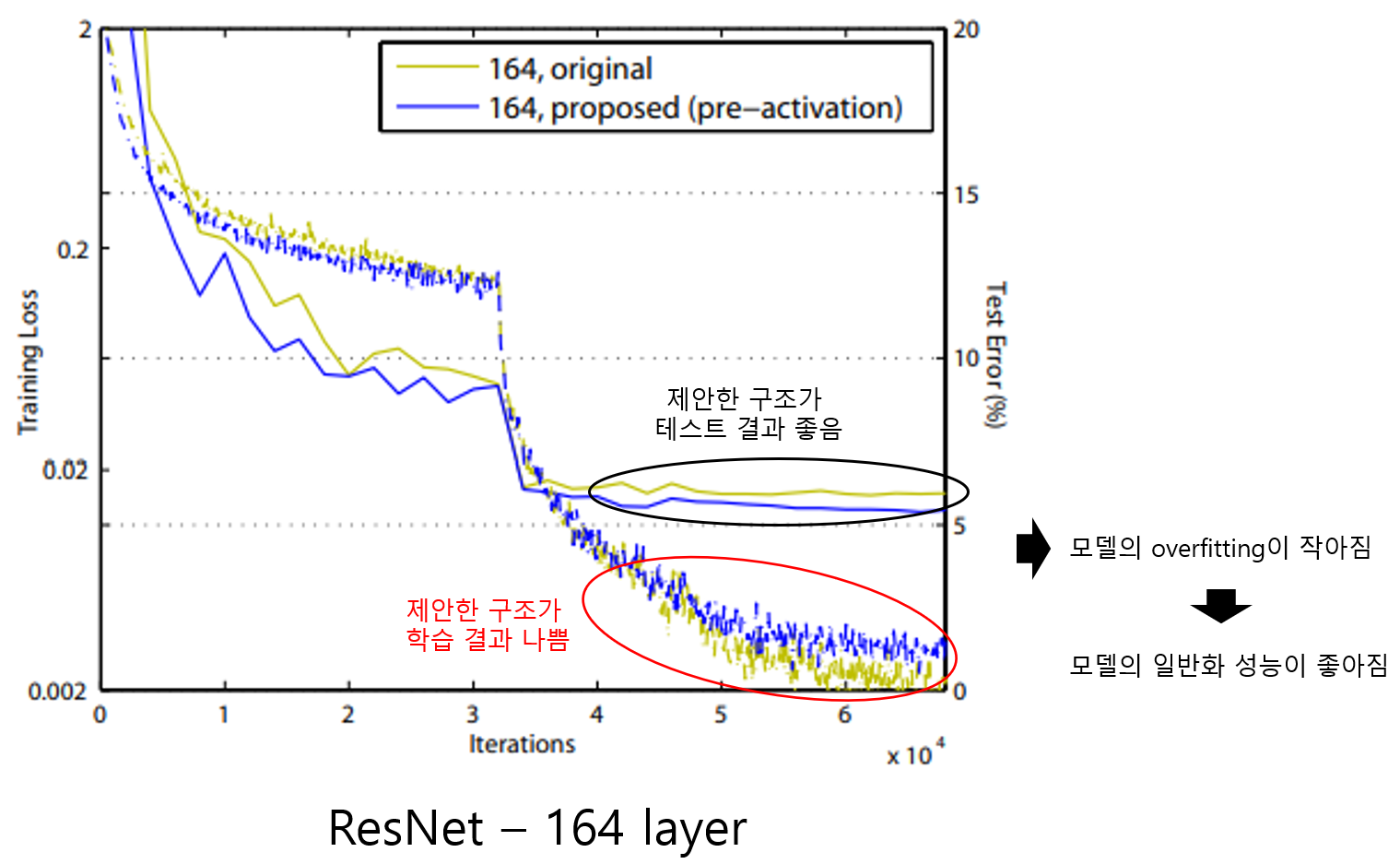
아래 그림은 ResNet-164를 학습한 결과입니다. 특이한 점은 테스트 성능은 제안된 구조가 더 좋지만, 학습 결과는 제안한 구조가 더 나쁘게 나오고 있습니다.
이러한 현상이 발생하는 원인은 제안하는 full pre-activation 구조는 Batch-Normalization을 통과해 정규화된 신호가 weight layer를 통과하기 때문에 일반화 성능이 올라가기 때문입니다.
다른 네트워크와 성능 비교

위 표는 Pre-Activation 구조의 성능을 비교분석하기 위해 Cifar-10/100 데이터셋에서 다른 SOTA 모델들을 비교한 결과이며 가장 좋은 성능을 보여줍니다.

다음으로 ImageNet에서 ResNet-152/200, Inception-v3를 비교한 결과입니다.
실험결과에서 기본구조의 Residual block을 사용한 ResNet-152와 ResNet-200을 비교해보면, ResNet-152가 성능이 더 좋은것을 볼 수 있습니다. 특이한점은 학습할 때 training error는 ResNet-200이 더 낮았기 때문에 논문 저자들은 overfitting이 발생한 것으로 보았습니다. 하지만 일반화 성능이 좋은 pre-activation 구조의 ResNet은 200이 152보다 성능이 좋은 것을 볼 수 있습니다.
post-activation 구조에서는 ReLU에 의해 신호손실이 생기지만 pre-activation 구조에서는 신호손실이 없습니다. 네트워크가 깊어질수록 더 많은 활성함수를 통과하기 때문에 post구조에서 손실은 커지지만 pre-activation은 그러한 경향이 없습니다. 실제로 실험에서 pre-activation을 사용하면 resnet-152/200 모두 성능은 개선되지만, Resnett-152에서는 성능개선이 미미한것을 볼 수 있습니다.(0.2%) 하지만 Resnet-200 구조 에서는 상대적으로 성능이 많이 올라간것을 볼 수 있습니다.(1.1%)
최종적으로 pre-activation 구조를 적용하고, single crop등의 agumentation 기법을 적용한 ResNet-200이 가장 좋은 성능을 보여줍니다.
마무리
Pre-activation 구조는 Resnet에서 추구하던 layer가 identity-mapping이 되도록 residual block의 구조를 개선한 결과물입니다.
pre-activation을 발표한 논문에선 resnet 논문에서는 살짝 부족했던 수식적인 설명에 대해 보다 깊이있게 설명해 주어 개인적으로 resnet을 이해하는데 큰 도움이 됐습니다.
resnet은 최근에도 많이 사용되는 네트워크라고 생각하는데, resnet의 수식적 이해가 필요하다고 생각되면 자세히 pre-activation 논문을 자세히 읽어보는것을 추천드립니다.
참고자료
