앙상블
앙상블 기법이란 여러개의 분류 모델을 조합해서 더 나은 성능을 내는 방법입니다.
배깅
부트스트랩(bootstarp) 과 어그리게이팅(aggregating)의 어원에서 온 것으로, 한 가지 분류 모델을 여러개 만들어 서로 다른 학습 데이터로 학습시킨 후 , 투표를 통해 가장 높은 예측값으로 최종 결론을 내리는 앙상블 기법입니다.
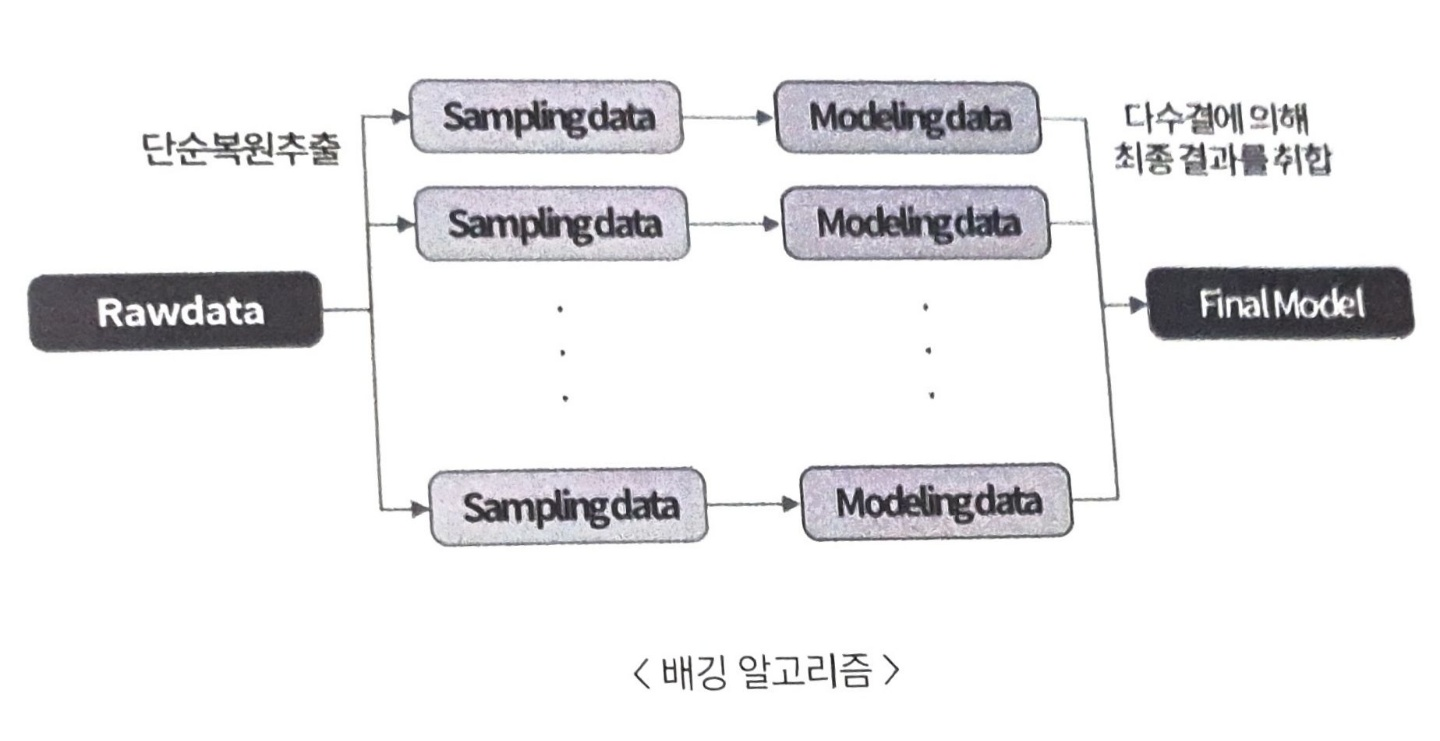
- 배깅에서는 가지치기를 하지 않고 최대로 성장한 의사결정나무들을 활용합니다.
- 배깅은 훈련자료를 모집단으로 생각하고 평균예측모형을 구하여 분산을 줄이고 예측력을 향상 시킬 수 있습니다.
부트스트랩(Bootstrap)
부트스트랩이란 데이터를 조금은 편향되도록 샘플링하는 기법입니다. 보통 의사결정 트리처럼 과대적합되기 쉬운 모델을 앙상블할 때 많이 사용됩니다.
- 과대적합 모델 → 학습 데이터에 대한 분산은 높고 편향이 적은 모델 → 학습 시에는 정확도가 높게 나오지만 학습에 사용된 적이 없던 데이터의 분류는 정확도가 낮게 나오는 모델
- 편향을 높혀 분산이 높은 모델의 과대적합 위험을 줄임
부트스트랩은 주어진 자료에서 단순랜덤 복원추출 방법을 활용하여 동일한 크기의 표본을 여러개 생성하는 샘플링 방법이다. 부트스트랩을 통해 100개의 샘플을 추출하더라도 샘플에 한번도 선택되지 않는 원 데이터가 발생할 수 있는데 전체 샘플의 약 36.8%가 이에 해당한다.
어그리게이팅
어그리게이팅은 여러 분류 모델이 예측한 값들을 조합해서 하나의 결론을 도출하는 과정입니다.
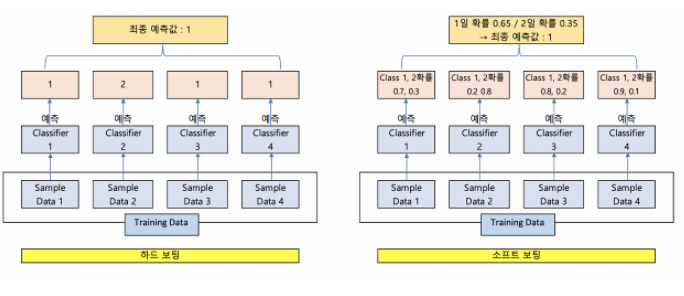
출처 -https://injo.tistory.com/22
- 하드보팅 → 가중치 없이 최다 득표를 받은 값을 결론으로 도출하는 방법
- 소프트보팅 → 모든 분류값의 확률을 리턴하여 각 분류값 별 가중치를 더한 값을 점수로 사용해 결론을 도출하는 방법
랜덤 포레스트
랜덤포레스트는 여러 의사결정 트리를 배깅해서 예측을 실행하는 모델입니다.
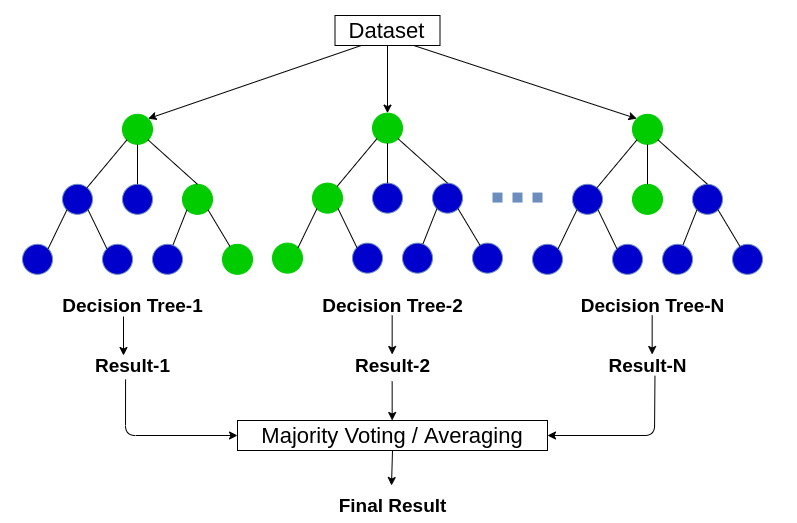
의사결정 트리에서는 최적의 특징으로 트리를 분기하는 반면에 랜덤 포레스트는 각 노드에 주어진 데이터를 샘플링해서 일부 데이터를 제외한 채 최적의 특징을 찾아 트리를 분기합니다.
이 과정으로 모델의 편향을 증가시켜 과대적합의 위험을 감소시킵니다.
부스팅
배깅은 서로 다른 알고리즘에 기반한 여러 분류기를 병렬적으로 학습하는 반면, 부스팅은 동일한 알고리즘의 분류기를 순차적으로 학습해서 여러 개의 분류기를 만든 후, 테스트 할 때 가중투표를 통해 예측값을 결정합니다.
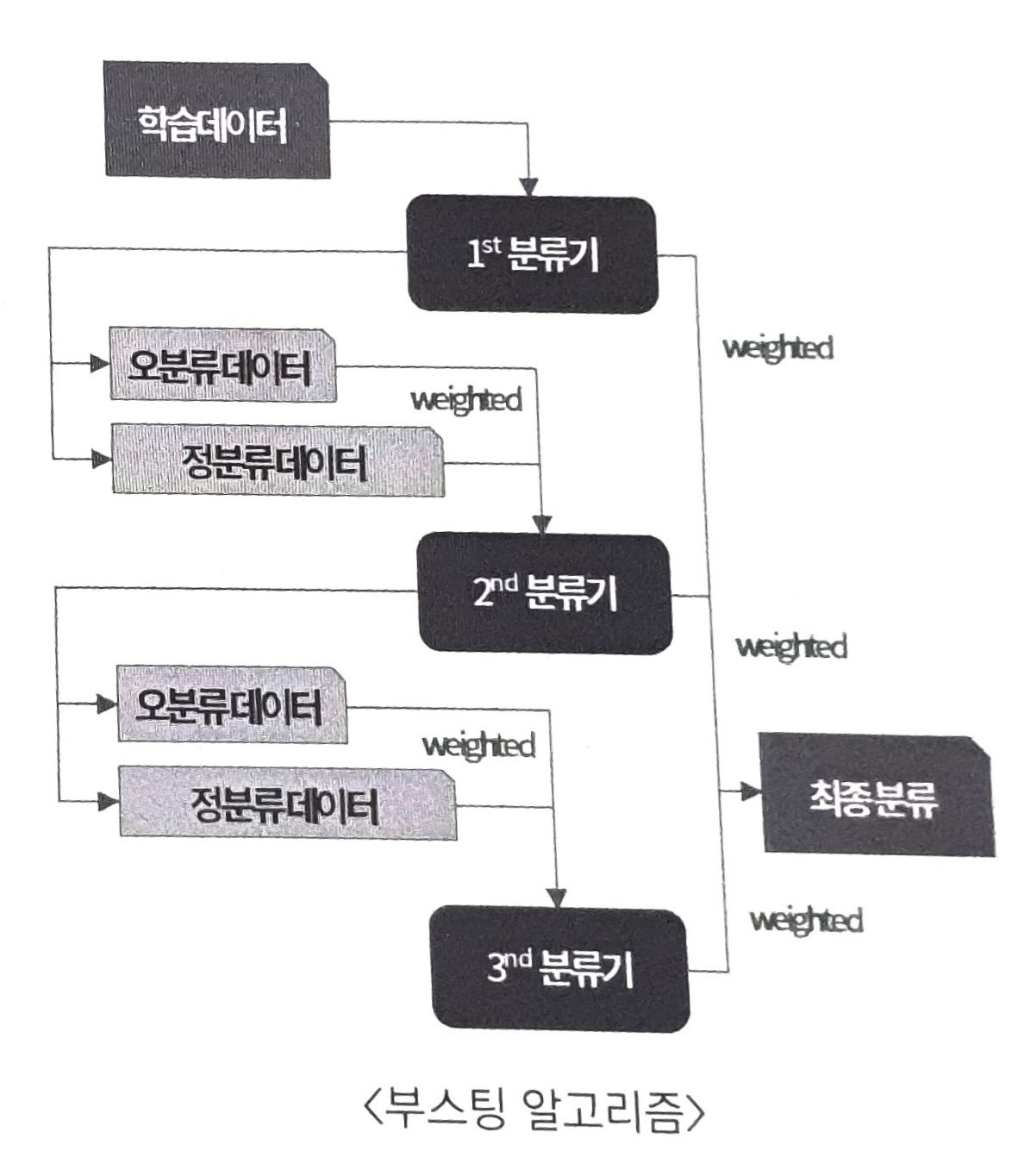
순차적 학습
첫 번째 의사결정 트리를 학습 한 후, 테스트 결과 분류가 미흡할 경우 남자 학습 데이터를 보강한 후 두번째 의사결정 트리를 학습합니다. 또 그 결과에 따라 학습 데이터를 보강하여 세 번째 모델을 학습하면서 순차적으로 결합하는 방법입니다.
가중 투표
한 표의 가치가 다른 투표입니다.
다수결이 아닌 각 분류의 정확도를 더해서 계산하는 방식입니다.
#하드보팅
voting_clf = VotingClassifier(estimators=[
('decision_tree', dtree), ('knn', knn), ('svm', svm)],
weights=[1,1,1], voting='hard').fit(X_train, y_train)
hard_voting_predicted = voting_clf.predict(X_test)
accuracy_score(y_test, hard_voting_predicted)
#소프트보팅
voting_clf = VotingClassifier(estimators=[
('decision_tree', dtree), ('knn', knn), ('svm', svm)],
weights=[1,1,1], voting='soft').fit(X_train, y_train)
soft_voting_predicted = voting_clf.predict(X_test)
accuracy_score(y_test, soft_voting_predicted)
출처 - 나의 첫 머신러닝/딥러닝 - 허민석, 데이터분석 전문가 가이드
