군집화
군집화는 비지도학습의 일종으로, 데이터의 특징만으로 비슷한 데이터들끼리 모아 군집된 클래스로 분류합니다.
k 평균 알고리즘 (k-means clustrering)
K 평균 알고리즘은 간단하면서도 강력한 클러스터링 알고리즘입니다.
- 데이터 준비
- 몇 개의 클래스로 분류할 것인지 설정(k 값 설정)
- 각 군집의 최초 중심 설정
- 데이터를 가장 가까운 군집에 포함시킴
- 클러스터 중심을 클러스터에 속한 데이터들의 가운데 위치로 변경
- 클러스터 중심이 바뀌지 않을 때 까지 4번부터 5번 과정을 반복적으로 수행
k 평균 알고리즘의 클러스터 중심을 설정하기 위해서 세가지 방법을 사용할 수 있습니다.
- 무작위 설정 방법
- 최초 중심값 부여 방법
- kmean ++ 방법
kmean++ 알고리즘
사이킷런의 k 평균 라이브러리는 기본적으로 kmean++라는 알고리즘을 써서 클러스터의 최초 중심을 설정합니다. 최초 데이터 포인트 지점을 첫 번째 클러스터의 중심으로 설정하고, 그에서 가장 먼 포인트를 두 번째 클러스터의 중심으로 설정합니다. 이와 같은 식으로 k 평균 알고리즘의 초기 값이 가까우면 clustering의 결과가 나쁘고, 시간이 오래걸리기 때문에 이를 보완하고자 만들어진 알고리즘 입니다.
k 평균 알고리즘에 따라 무작위로 클러스터의 중심을 설정하고 각 데이터를 가까운 클러스터에 지정하는 과정
아래의 그림은 c1, c2, c3라는 클러스터를 분류하기 위해 중심을 부여하고, 첫 번째 데이터부터 마지막 데이터까지 순회하면서 데이터로부터 가까운 클러스터로 데이터를 분류시키는 과정입니다.
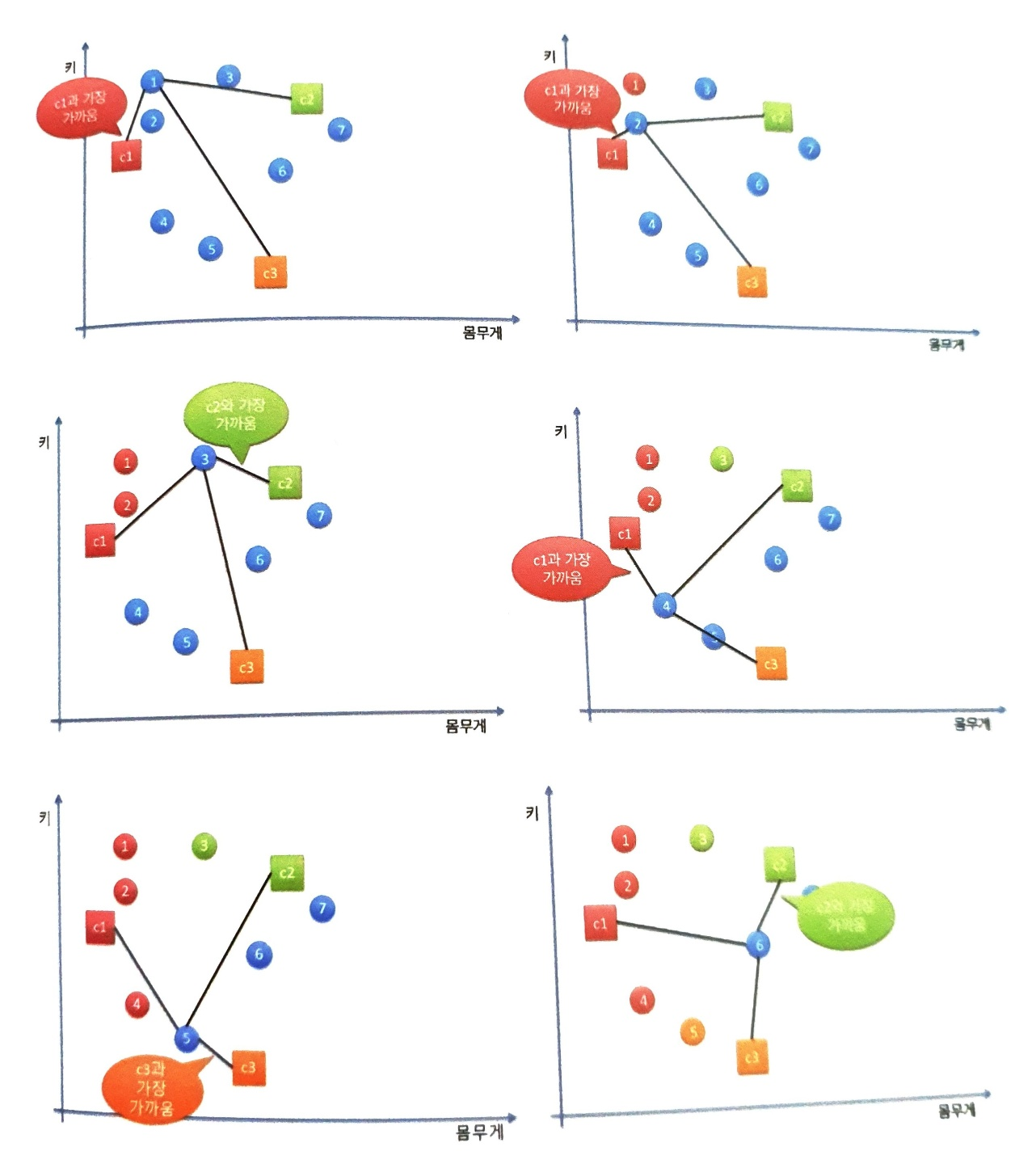
클러스터 중심을 군집에 속한 데이터들의 가운데 위치로 변경
데이터의 순회가 완료되면 각 클러스터의 중심값을 실제 클러스터 내부의 데이터들의 중앙값으로 변경합니다.
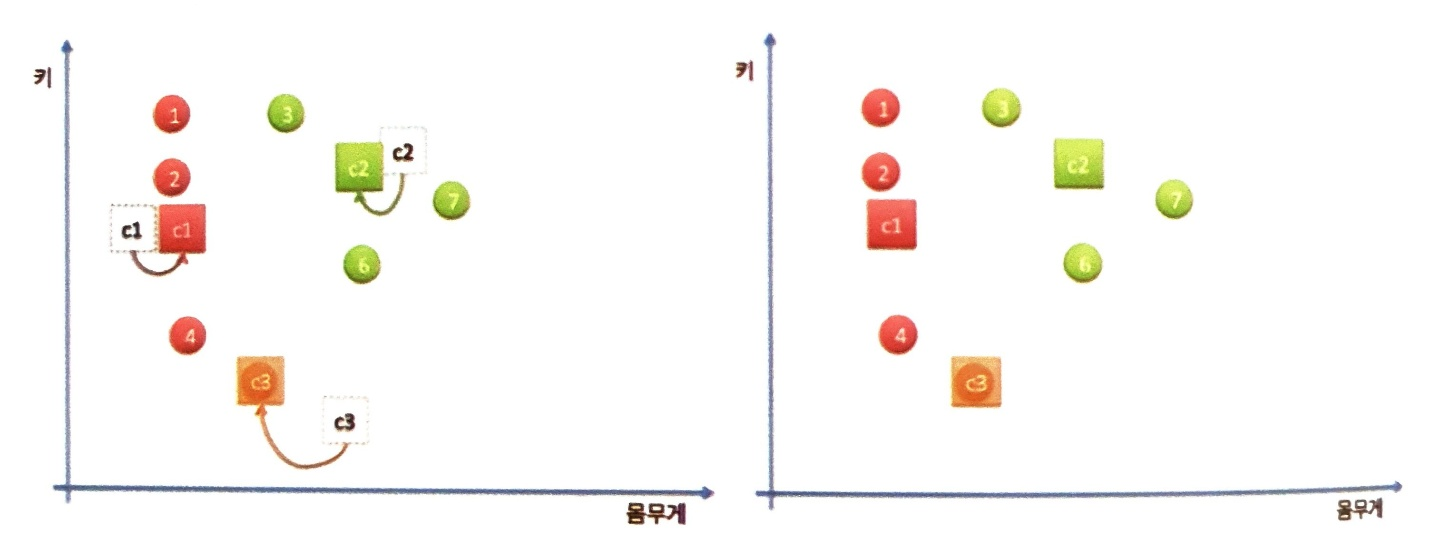
클러스터 중심이 바뀌지 않을 때까지 반복적 수행
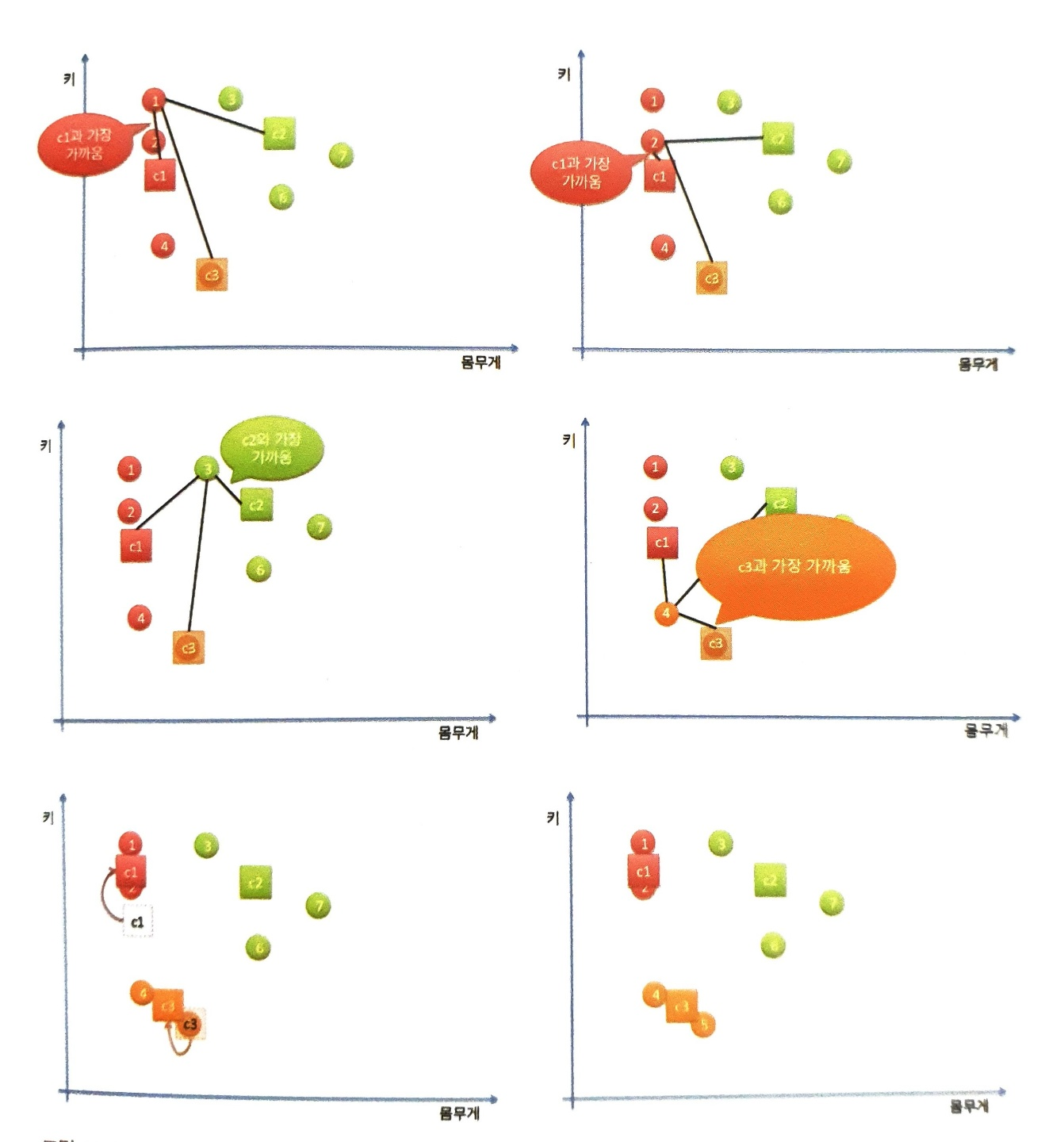
클러스터의 중심이 바뀌면 다시 모든 데이터를 순회하며, 데이터들을 가까운 클러스터로 분류시킵니다. 데이터의 순회가 완료되면 다시 클러스터의 중심을 소속된 데이터들의 중앙으로 옮깁니다. 이 과정을 데이터가 변경되지 않을 때 까지 반복합니다.
코드
데이터 삽입 및 시각화
#데이터 삽입
df = pd.DataFrame(columns=['height', 'weight'])
df.loc[0] = [185,60]
df.loc[1] = [180,60]
df.loc[2] = [185,70]
df.loc[3] = [165,63]
df.loc[4] = [155,68]
df.loc[5] = [170,75]
df.loc[6] = [175,80]
#x축 height, y축 weight 산점도 그리기
sns.lmplot('height', 'weight',
data=df, fit_reg=False,
scatter_kws={"s": 200})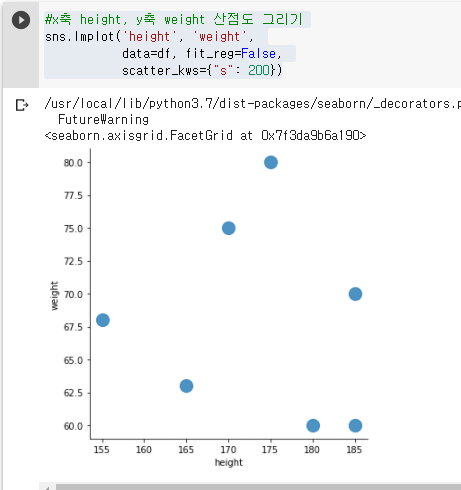
k - clustering 실행 , 컬럼 추가
#k 군집화 실행
data_points = df.values
kmeans = KMeans(n_clusters=3).fit(data_points)
#라벨 추가
df['cluster_id'] = kmeans.labels_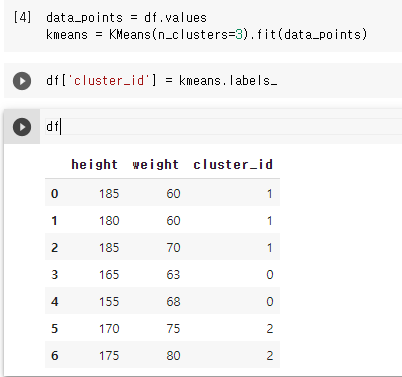
군집별 시각화
#위에서 추가한 clusterid로 구분해서 시각화
sns.lmplot('height', 'weight', data=df, fit_reg=False,
scatter_kws={"s": 150},
hue="cluster_id")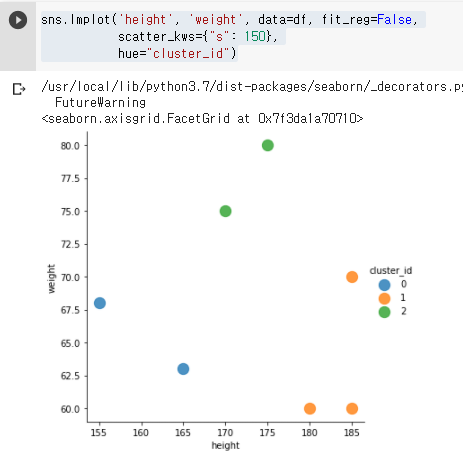
출처 - 나의 첫 머신러닝/딥러닝 -허민석

Positive Vibe