
최근 자동차 충돌 대회에서 huggingface의 timesformer을 사용해보았다. 실제 핵심 기술을 자세히 알고자 위 논문을 리뷰해보았다.
Abstract
video classification에 self-attention에만 기반한 conv연산이 없는
접근방식을 보여준다. TimeSformer는 frame수준의 patch에서 spatiotemporal feature learning을 가능하게 하여 표준 transformer을 video에 적용한다.
연구로는 다른 self-attention 체계를 비교하고 각 블록 내에서 temporal attention 과 spatial attention에서 별도로 적용되는 divided attention이 가장 높은 분류 정확도를 가진다는 것을 이끌어낸다.
Kinetics-400 and Kinetics-600에서 SOTA의 성능을 이끌어 냈다.
Introduction
오랜 기간 self-attention는 NLP영역에서 혁명을 일으켰다. 단어 사이의 long-range dependencies을 캡처하는것과 높은 교육 확장성으로 NLP 영역에서 최신 기술을 나타낸다. 영상과 문장은 둘다 sequential하기 때문에 video 영역에서 transformer는 좋은 성능을 낼것으로 기대할 수 있다. 지금까지 self-attention이 convolution위에 적용될때의 경우만 있기 때문에 이 논문은 모든 convolution연산을 self-attention으로 교체가 가능 여부에 대해 질문을 제기한다. 이 모델이 convolution의 몇가지 문제점과 한계를 해결할 수 있음을 주장한다.
1. strong inductive biases(local connectivity and translation equivariance)는 적은 데이터셋에서는 효과적이지만 큰 데이터셋에서 모델의 표현성을 과도하게 제약할 수 있다.
2. convolution kernel은 단거리 시공간 정보를 캡처하도록 설계되었기 때문에 receptive field를 넘어서는 확장되는 종속성을 모델링할 수 없다.
3. CNN은 high resolution나 Video에서 expensive하다.
이 논문은 이미지의 ViT를 Video에 확장하여 TimeSformer(Time-Space Transformer)를 제시한다.
Video를 개별 frame에서 추출한 일련의 patch로 보며 ViT에서 처럼 각 patch는 Embedding에 선형으로 mapping되고 위치정보로 보강된다. 이를 NLP에서 Encoder에 공급하기 위한 token embedding과 같게 해석할 수 있다.
Video의 많은 patch수로 계산 비용이 많이 드는데 이를 위해 시공간 volume에 대한 몇가지 확장 가능한 self-attention설계를 제안하고 대규모 action classification datasets에 대해 경험적으로 평가한다.
이때 temporal attention 과 spatial attention에서 별도로 적용되는divided attention이 더 좋은 design임을 보여준다.
Related Work
Non-Local Networks
non-local mean을 사용한다. convolution 기능을 강화하는 self-attention을 제안한다.
DETR
Object Detection에서 Convolution 기능 맵 위에 Self-attention을 사용한다.
The TimeSformer Model
Input clip.
X ∈ RH ×W ×3×F
각 이미지를 PxP의 patch size로 N개로 분해하며 각 frame별로 N개의 patch를 갖는다.
N = HW/P 2
이 patch를 flatten한다. x(p,t) ∈ R3P 2
p 1~N은 patch index, t 1~f는 frame index
Linear embedding.
각 patch를 embedding vector에 연결한다.
positional encoding을 연결하여 위치기반의 정보를 제공한다.
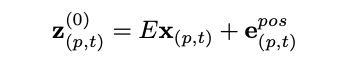
Query-Key-Value computation.
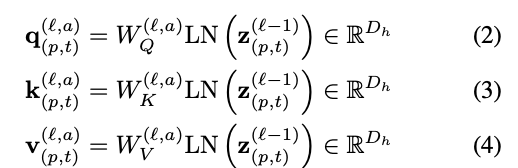
LN은 LayerNorm이다. A는 index over multiple attention heads이다.
Self-attention computation.
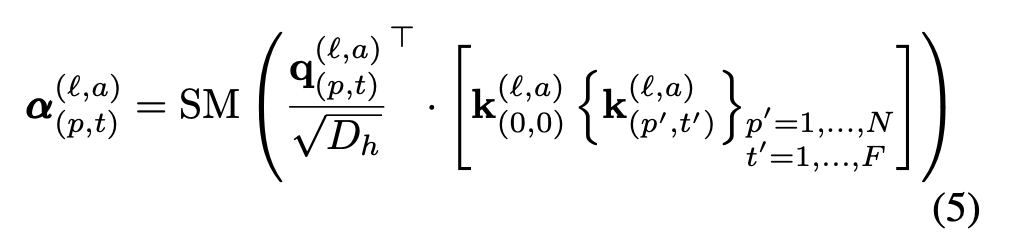
SM은 softmax이다. spatial-only or temporal-only를 할 경우 계산이 줄어들 것이다.
Encoding

우선 위의 Multi-head-attention을 사용해 attention score을 얻는다. 그뒤 head를 연결한 후 MLP를 통과시킨다.(FeedForward Network)
Classification embedding
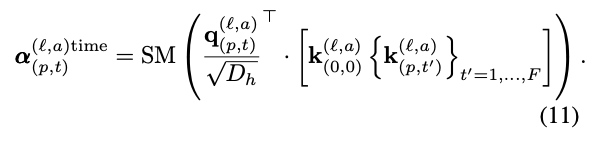
마지막에는 분류를 위해 1-hidden-layer을 사용한다.
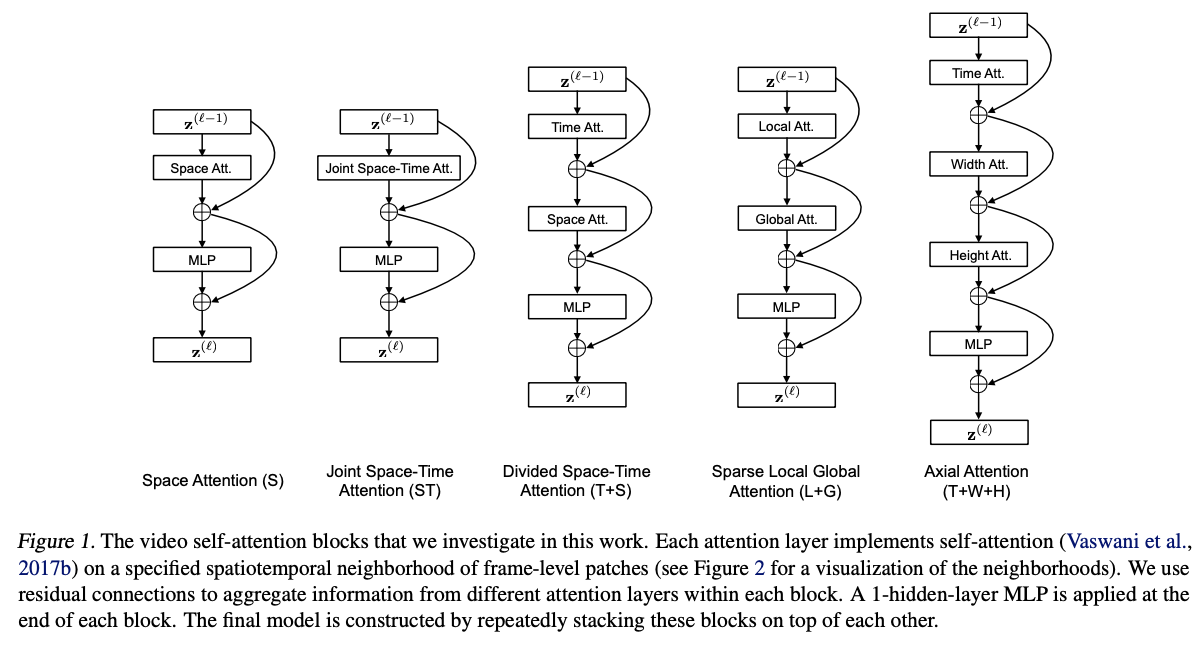
Space-Time Self-Attention Models.

위 논문은 Divided Space-Time Attention라는 효과적인 방법을 제시한다.
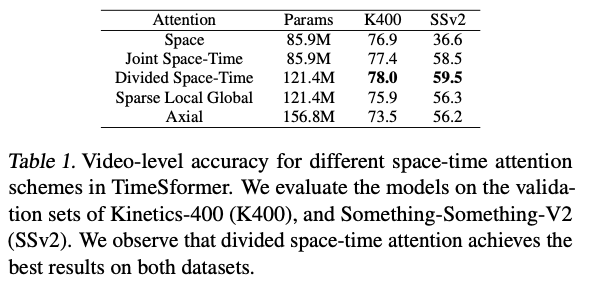
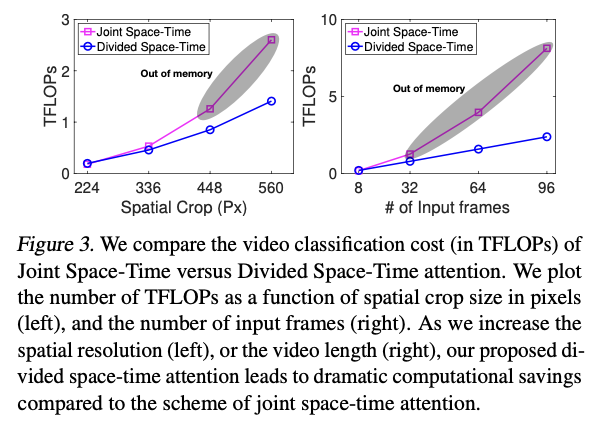
Experiments
Analysis of Self-Attention Schemes
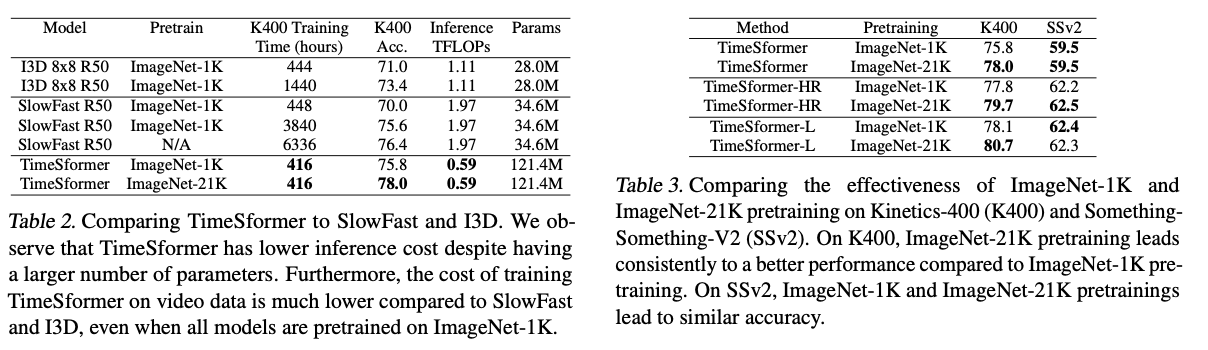
The Importance of Pretraining. & Varying the Number of Tokens
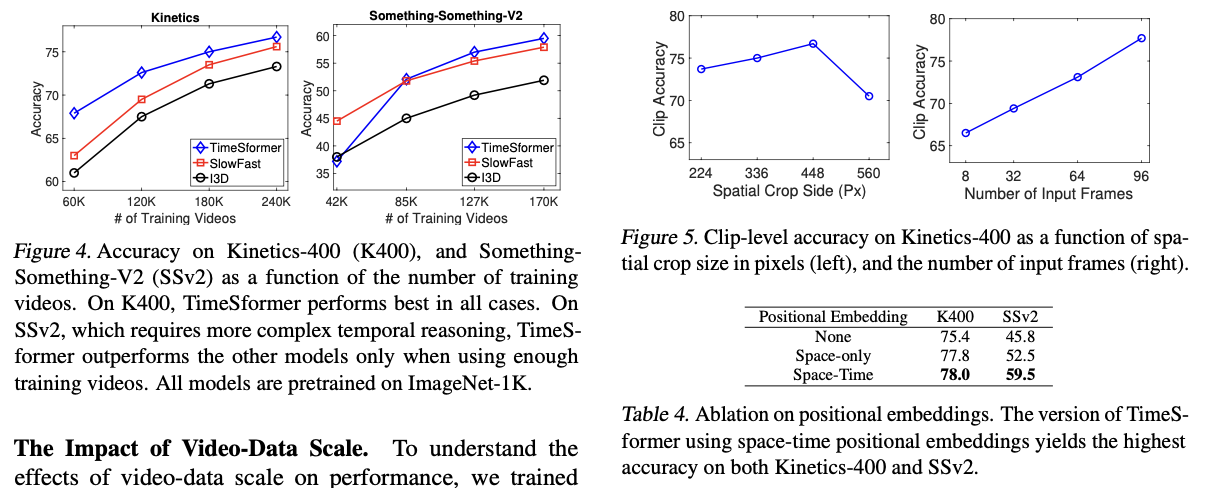
Comparison to the State-of-the-Art
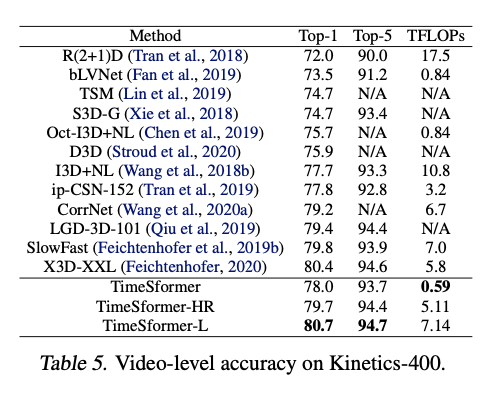
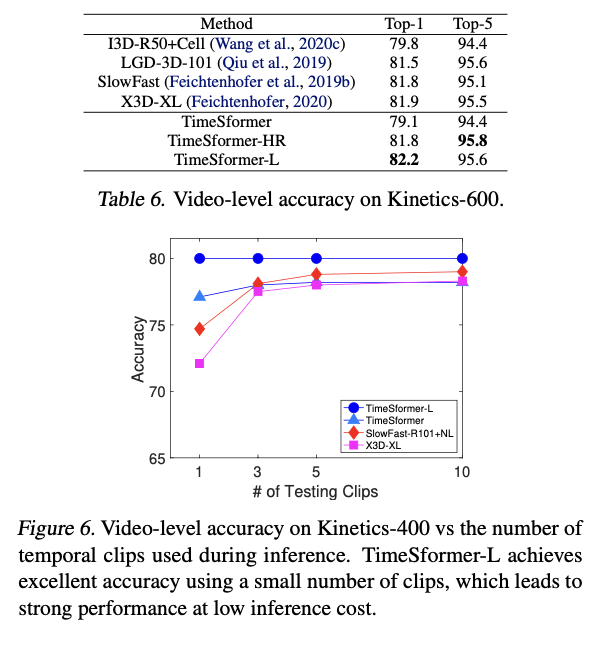
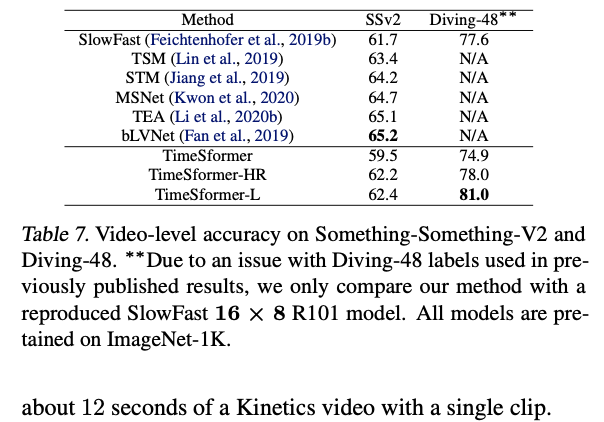
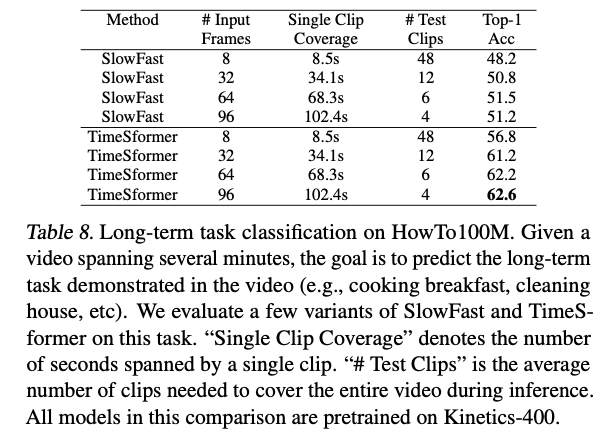
Long-Term Video Modeling
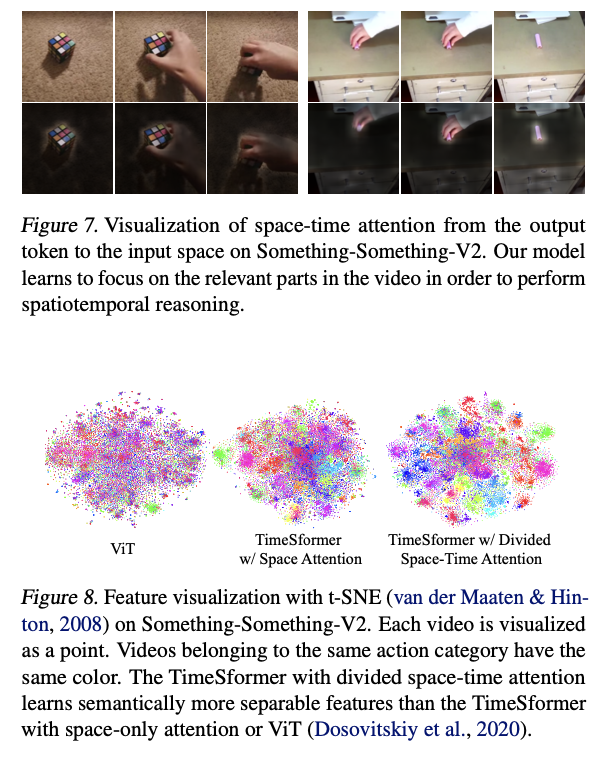
Additional Ablations
Conclusion
TimeSformer라는 Video classfication의 SOTA모델을 제시.
ViT를 frame영역으로 시간이 더해진 영상에서 활용함.
self-attention을 시간과 공간 key vector을 사용하며 총 5가지의 방법중 가장 효율적이고 높은 성능을 보인 Divided Space-Time Attention 제시.
