
Abstract
일관성있고 의미있는 text를 자동으로 생성하는 기계번역, 대화 시스템, Image-caption 등에서 많은 응용분야를 가지고 있다. Reinforcement learning policy로써 generative model은 text생성에서 유망한 결과를 보여줬지만 scalar guiding signal는 전체 text가 생성된 후에만 사용할 수 있었으며 생성프로세스중에 text 구조에 대한 중간 정보가 부족하다. 따라서 생성된 text의 길이가 길면(20단어 이상) 성공률이 제한된다.
본 논문은 긴 Text생성을 해결하기 위해 LeakGAN이라는 새로운 framework를 제한한다.
discriminative net이 자체적으로 추출한 높은 수준의 기능을 generative net로 유출하여 지침을 추가로 돕도록 허용한다. generator는 이런 정보 신호를 추가 MANAGER 모듈을 통해 모든 생성 단계에 통합한다. 이 모듈은 현재 생성된 단어의 추출된 기능을 취하고 latent vector을 출력하여 차세대 단어 생성을 위해 WORKER 모듈을 안내한다.
Turing test를 통한 합성 데이터 및 다양한 실제 작업에 대한 실험은 LeakGAN이 긴 text 생성에 매우 효과적이며 짧은 text 생성 시나리오에서도 성능을 향상시킨다는 것을 보여준다. 더 중요한 것은 supervision 없이 LeakGAN은 MANAGER와 WORKER 간의 상호 작용을 통해서만 문장 구조를 implicitly하게 학습할 수 있다는 것이다.
Introduction
일관성 있고 의미론적인 전체 text를 생성하는 기능은 많은 관심을 받고 있다. 일반적인 접근 방식은 이전에 관찰된 단어가 주어진 각 실측 단어의 log-likelihood를 maxmize 하기 위해 RNN을 훈련하는 것이다.
학습 및 추론 단계: 모델은 추론 중에 이전에 생성된 단어를 기반으로 다음 단어를 sequential하게 생성하지만 자체적으로는 ground-truth 단어가 주어지면 단어를 생성하도록 학습된다.
GAN은 연속 데이터에 대해 처음 제안한 후 이산, 순차 데이터로 확장하여 위의 문제를 완화하고 유망한 결과를 부여주었다.
text sample의 이산적 특성으로 인해 text generate는 sequential decision making process modeling 된다.
- state: 이전에 생성된 단어
- action: 생성할 다음 단어.
- stochastic policy: generative net G that maps current state의 분포에 대한 현재 state
전체 text생성이 완료된 후 생성된 text sample은 G 업데이트에 대한 reward signals을 얻기 위해 실제 text sample과 생성된 text sample을 구별하도록 trained 된 classifiers인 D에 공급된다.
이후 GAN을 통해 text 생성에 다양한 방법이 제안되었다.
그럼에도 불구하고 보고된 결과는 생성된 text가 짧은 경우(20단어 미만)로만 제안되고 긴 text 생성 연구는 거의 이루어지지 않았다. 기존 긴문장 text 생성의 단점은 전체 text sample이 생성될 때만 사용할 수 있기 때문에 D의 binary guiding signal이 희박하다. 또한 전체 text에 대한 scalar guiding signal는 G가 충분히 학습할 수 있도록 생성되는 text의 중간 구문 구조 및 의미에 대한 그림을 반드시 보존하지 않기 때문에 non-informative하다.
한편, D는 알려지지 않은 블랙박스가 아닌 CNN과 같은 훈련된 모델이기 때문에, guiding signals를 더 유익하게 만들기 위해 Classifier D는 잠재적으로 최종 reward 값 외에 더 많은 지침을 제공할 수 있다. 그 아이디어로는 D의 보상을 최대화하기 위해 G를 직접 훈련시키는 대신 D에 의해 실제 텍스트와 생성된 텍스트의 학습된 feature representations을 강제로 일치시킴으로써 생성자 G를 훈련시킬 것을 제안했다. 이러한 방법은 짧은 텍스트 생성에 효과적일 수 있지만, 텍스트가 끝날 때까지 안내 신호는 여전히 없다.
반면에, the sparsity problem of the guiding signal를 완화하기 위해, 실제 text sample은 의미 구조 및 음성 부분과 같은 일종의 hierarchical structure를 따라 생성되기 때문에, text 생성에서 hierarchical structure의 아이디어가 자연스럽게 발생한다. 전체 생성 작업을 hierarchical structure에 따라 다양한 sub-tasks으로 분해하면 모델이 훨씬 쉽게 학습할 수 있다. 계층 개념을 텍스트 생성에 통합하기 위한 초기 노력이 이루어졌지만, 모두 도메인 지식에서 미리 정의된 sub-tasks sets를 사용하므로 임의 sequence 생성 작업에 적응할 수 없다.
본 논문에서는 non-informativeness 와 the sparsity issues를 모두 해결하기 위해 LeakGAN이라는 새로운 algorithm framework를 제안한다. LeakGAN은 hierarchical reinforcement learning의 최근 발전을 차용하여 discriminator에서 generator로 더 풍부한 정보를 제공하는 새로운 방법이다.

그림 1과 같이, 우리는 특히 높은 수준의 MANAGER 모듈과 낮은 수준의 WORKER 모듈로 구성된 hierarchical generator G를 소개한다. MANAGER는 LSTM이며 중재자 역할을 한다. 각 단계에서 D의 높은 수준의 특징 표현을 수신하고 이를 사용하여 해당 시간 단계에서 WORKER 모듈에 대한 지침 목표를 형성한다. D의 정보는 내부적으로 유지되며 적대적인 게임에서는 G에게 이러한 정보를 제공하지 않는다. 따라서 우리는 그것을 D로부터의 정보 유출(leakage of information)이라고 부른다.
다음으로, MANAGER에 의해 생성된 goal embedding이 주어지면, WORKER는 먼저 현재 생성된 단어를 다른 LSTM으로 인코딩한 다음, LSTM의 출력과 목표 임베딩을 결합하여 현재 상태에서 최종 작업을 수행한다. 이와 같이, D의 guiding signals는 scalar reward signals 측면에서 G에게 마지막에 제공될 뿐만 아니라, 생성 과정 중 goal embedding vector 측면에서도 사용 가능하여 G가 개선되는 방법을 안내한다.
sum
D: 높은 단계의 feature들을 G에게 유출(Leak)
G: Manager, Worker로 구성
- Manager: 현재 생성한 단어로 latent vector를 추출, Worker에게 전달
- worker: latent vector로 다음 단어를 예측
기존 연구 문제점:
- 문장이 완성되어야 신호를 줄 수 있는 D 때문에 문장이 길어질 경우 D의 신호가 희박해짐
- 미리 정해진 도메인에서 문장을 생성하는 시도는 있었음.
idea
- 전체를 생성하는 문제에서 여러 부분을 생성하는 문제로 변경-> hierarchical task
- 정해진 도메인의 데이터 뿐만 아니라 다른 데이터도 생성
Related Work
SeqGAN - LeakGAN의 선행 연구이자 Sequential Decision process로 모델링하고 생성 모델을 policy gradient 방법으로 훈련
RankGAN - GAN의 vanishing gradient 문제를 해결하기 위해 제안됨. 생성된 데이터로부터 예상되는 cosin 거리에 대해 softmax를 취함으로써 원래의 binary classifier인 discriminator을 순위 모델(Rank system)으로 대체하여 솔루션 제안.
Methodology
우리는 텍스트 생성 문제를 sequential decision making process로 공식화한다. 각 시간 단계에서 agent는 이전에 생성된 단어를 st=(x1,...,xi,...,xt)로 표시된 현재 상태로 받아들인다. 여기서 xi는 주어진 어휘 V에서 단어 토큰을 나타냅니다. 확률론적 정책에 해당하는 γ 매개 변수 생성 넷 Gθ는 전체 어휘, 즉 Gθ(|st), 여기서 액션 xt+1, 즉 선택할 다음 단어가 샘플링된다. 또한 전체 문장 T가 생성되었을 때 매개 변수를 조정하기 위해 Gθ에 대한 스칼라 안내 신호 Dφ(sT)를 제공하는 γ 매개 변수 차별 모델 Dφ를 훈련한다.
앞서 논의했듯이, 위의 adversarial 훈련이 원칙적이지만 문장 길이 T가 클수록 scalar guiding signals는 상대적으로 정보가 부족해진다. 이를 해결하기 위해 제안된 LeakGAN 프레임워크는 discriminator Dφ가 현재 문장 st의 특징 ft로 표시된 추가 정보를 Gφ(·|st) 생성자에게 제공할 수 있도록 합니다. LeakGAN에서 hierarchical RL architecture는 Gθ의 생성 절차에 이러한 유출 정보 ft를 효과적으로 통합하기 위한 유망한 메커니즘으로 사용된다.
Leaked Features from D as Guiding Signals
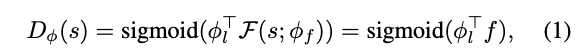
s: input, Pi: model parameter, F:CNN, f:feature vector(leaked information)
A Hierarchical Structure of G
D의 유출된 정보를 이용하기 위해 Manager-Worker hierarchical structure 형태를 가짐
MANAGER: 각 시점 t에서 유출 정보 ft를 이용해 goal vector: gt를 생성
WORKER: manager의 gt를 토대로 다음 단어 생성

Generation process(MANAGER)
MANAGER는 유출 정보로 goal vector(Worker들의 Guidline)을 생성해야함.
hM: hidden state, theta: model parameter, M: LSTM
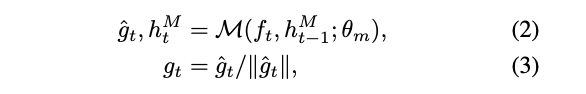
이전 시점의 goal vector와 현재 vector embedding.
Phsai: model parameter
Generation process(WORKER)
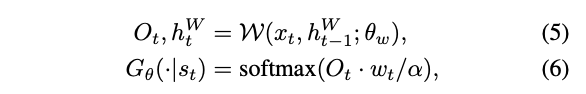
WORKER 는 MANAGER의 goal vector와 현재 단어로 다음 단어를 예측해야함.
Xt: 현재단어, h: hiddenstate, theta: model parameter, W: LSTM, a: temp parameter
Training of G
G의 모든 과정은 미분 가능한 구조로 되었으므로, gradient policy를 따라서 아래와 같이 Manager의 gradient를 계산.

Q: state value function
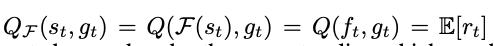
현재 상태 st, goal vector: gt를 바탕으로 monte carlo 를 거쳐 reward를 측정.
Dcos: 두 벡터의 cosin similarlity
Ft+c : c step 이후 유출된 정보
Gt: goal vector by param theta

WORKER 의 reward gradient

본직적인 reward
Experiment


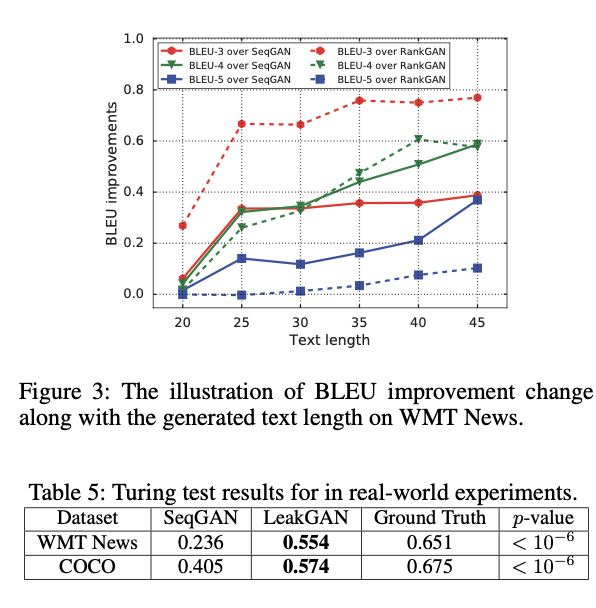

Concolusion
GAN과 RL을 융합한 framwork이자 G에 Manager-Worker hierarchical structure를 가진 LeakGAN은 D로부터 Leaked information을 활용해 G를 학습시키는 구조이다. 이는 현재 text generate 영역에서 SOTA를 기록하고 있다.
