
그저께 스터디에서 스터디원이 GAN논문을 발표했다. GAN의 대략적 내용은 알지만 Unsupervised Learning 이라는 점에서 굉장히 특별하고 유용하기 때문에 그 내용을 자세히 들여다 보고자 나도 논문을 읽어보았다.
Abstract
adversarial process -> simultaneously train two models
서로 적대적 관계의 두 모델을 동시에 학습시키는 컨셉이다.
generative model G
captures the data distribution.
-> 즉 original Data distribution과 유사한 distribution을 가진 dataset 생산
discriminative model D
estimates the probability that a sample came from the training data rather than G.
-> 0 or 1로 estimate
Minmax Training game:
G는 D가 못맞추도록, D는 G와 Real Data 중 G의 것을 맞추도록
D의 정확도가 1/2가 되도록...
Introduction
DL의 Trend는 Discriminative model을 학습시키는 것이다.
GAN은 Deep generative model이 core이다.
Generative model의 2가지 문제점은 다음과 같다.
1. difficulty of approximating many intractable probabilistic computations that arise in maximum likelihood estimation and related strategies.
2. difficulty of leveraging the benefits of piecewise linear units in the generative context.
Generative model의 output이 Data distribution과 model distribution 둘중 어디서 왔느냐로 맞추는 컨셉으로 위의 문제를 해결한다.
the generative model 은 random noise를 a multilayer perceptron에 통과시켜 sample을 만든다.
the discriminative model is also a multilayer perceptron.
Related work
restricted Boltzmann machines (RBMs) deep Boltzmann machines (DBMs)이 대안으로 소개된다.
Adversarial nets
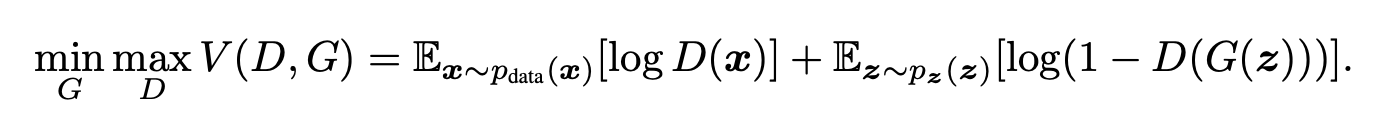
Train D to maximize the probability of assigning the correct label to both training examples and samples from G
Train G to minimize log(1 − D(G(z)))
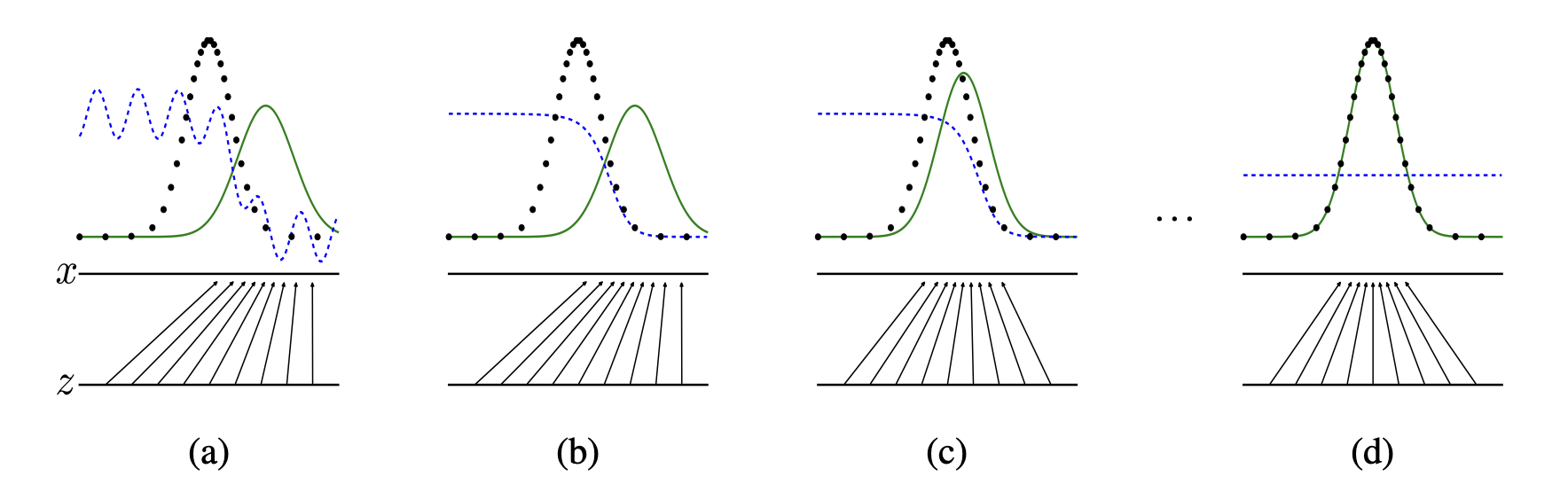
초록색의 model distribution이 원래 data의 distribution에 같아지는 것을 볼 수 있다.
z가 x라는 dataset에 maping되는 과정이다.
Theoretical Results

Optimizing D to completion in the inner loop of training is computationally prohibitive, and on finite datasets would result in overfitting.
we alternate between k steps of optimizing D and one step of optimizing G.
Early in learning, when G is poor, D can reject samples with high confidence because they are clearly different from the training data. In this case, log(1 − D(G(z))) saturates.
Rather than training G to minimize log(1 − D(G(z))) we can train G to maximize log D(G(z)). This objective function results in the same fixed point of the dynamics of G and D but provides much stronger gradients early in learning.
Global Optimality of pg = pdata




KL Divergence를 사용해서 optimal 한 상태의 D와 G를 증명해 나아간다.
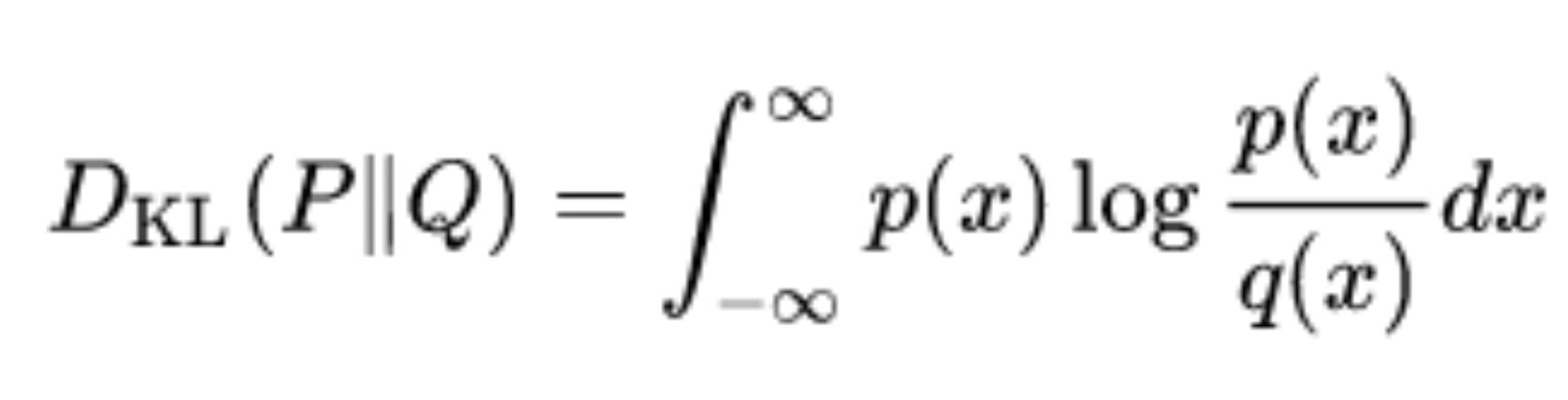
KL Divergence는 두 확률분포의 차이를 구하기 위해 사용되며 논문에서 요즘 자주 보고 있다.
Jensen–Shannon divergence가 최종적으로 사용되며 KL Divergence와 역할이 비슷하다.
the Jensen–Shannon divergence is a method of measuring the similarity between two probability distributions.
the Jensen–Shannon divergence between two distributions is always non-negative and zero only when they are equal.
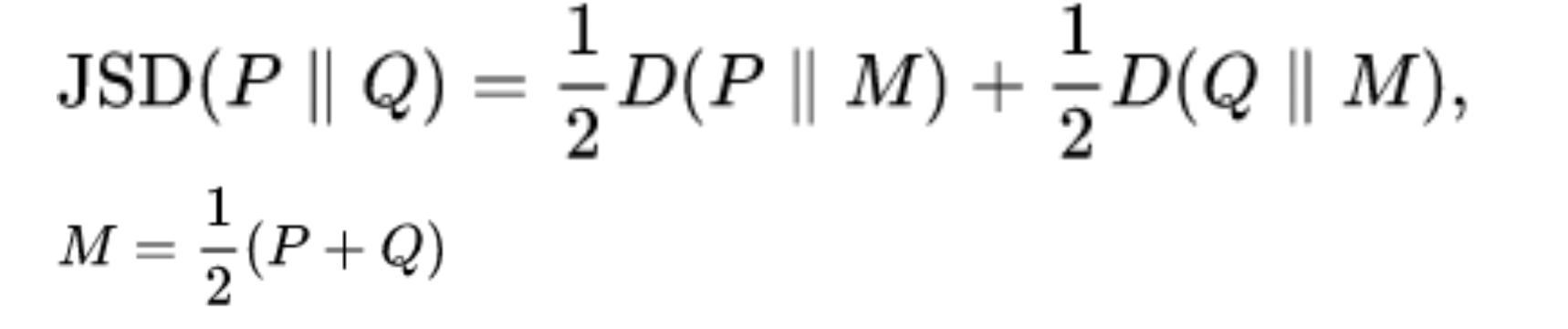
Experiments
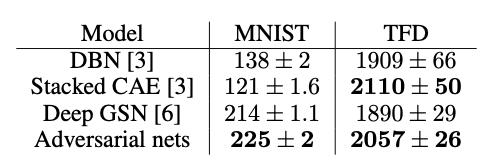

노란색의 원본 이미지를 학습한 GAN의 Generater는 다음과 같이 굉장히 유사한 이미지를 만들어 낸다. MNIST Data에서는 거의 같다고 볼 수 있다.
Advantages and disadvantages
the Helvetica scenario
G와 D는 동시에 훈련되어져야 한다. 너무 훈련된 G를 가지고 학습시키면 mode collapse가 일어날 수 있다고 한다.
이점은 Markov 체인이 전혀 필요하지 않고 기울기를 얻기 위해 역전파만 사용되며 학습 중에 추론이 필요하지 않으며 다양한 기능을 모델에 통합할 수 있다는 것 이다.
Conclusions and future work
This paper has demonstrated the viability of the adversarial modeling framework, suggesting that these research directions could prove useful.
나의 결론
GAN의 아이디어는 놀랍다. Plain GAN은 앞서 말했듯이 너무 많이 학습된 G를 가지고 훈련시킬 경우 model collapse가 일어나며 D가 앞도하는 것은 괜찮지만 너무 정확한 경우는 G의 gradient가 vanishing 된다고 한다.
generate가 잘 학습되어 좋은 이미지를 만들어 낸다면 이것으로 무슨 일을 대체할지 궁금하면서 신기하다.
