
Abstract
large-scale pretrained foundation models은 빠르게 down- stream tasks로 바꿀 수 있어서 vision에서 인기가 많다.
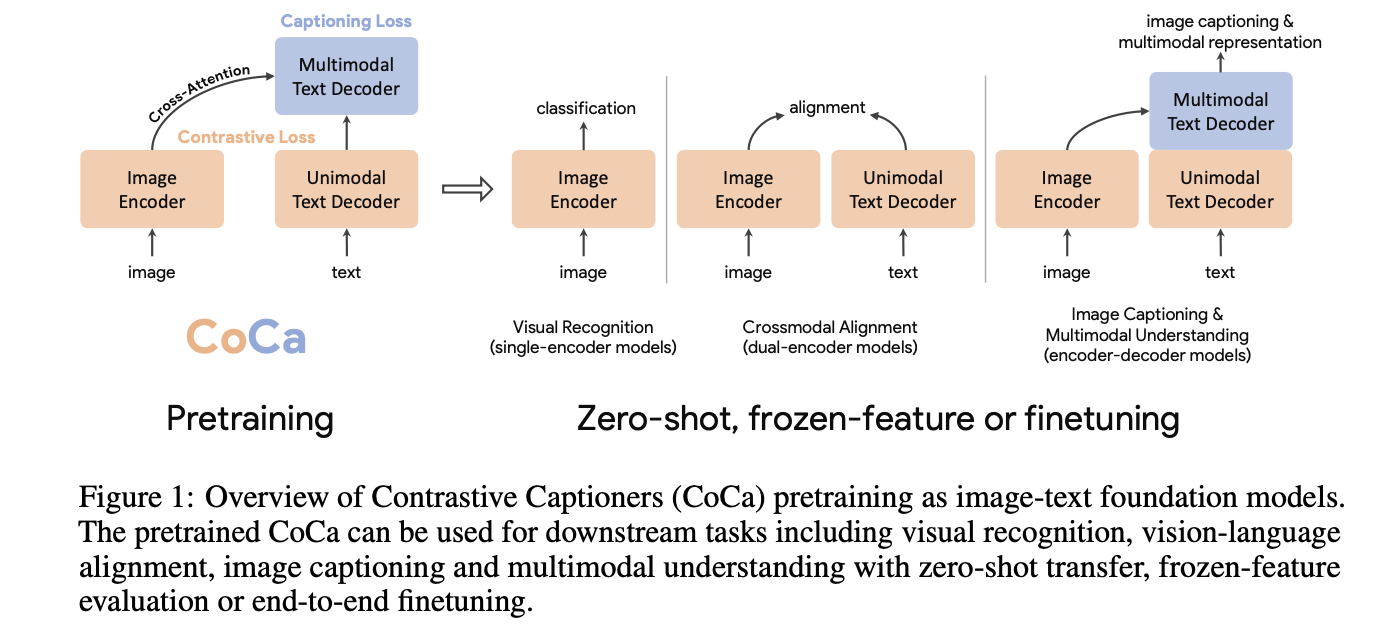
이 논문은 Contrastive Captioner (CoCa) 를 소개한다.
- contrastive loss 와 captioning loss를 함께 pretrain 한 image-text encoder-decoder foundation model
- CLIP과 같은 subsuming model capabilities ,SimVLM과 같은generative methods
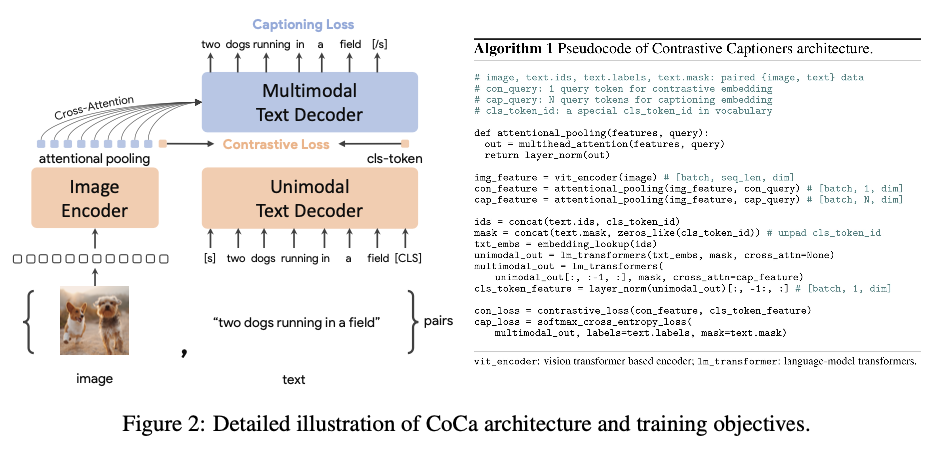
일반적으로 Decoder layer가 Encoder layer의 output에 참여하는 표준 Encoder-Decoder과는 달리 CoCa는 decoder layers 전반부의 cross-attention을 생략하여 unimodal text representations을 encode후 이미지에 cross-attention 하는 나머지 decoder layers을 계단식 배열 한다.
unimodal image 와 text embeddings 사이에 contrastive loss와 text token을 autoregressive하게 예측하는 multimodal decoder outputs에 captioning loss를 사용한다.
같은 computational graph를 공유함으로써 2개의 training objectives가 minimal overhead로 효율적으로 계산된다.
CoCa는 모든 layer을 단순히 text로 취급하며 text와 image에 pretrained된 모델이다.
Imagenet에서 zero-shot에서 1등, FT에서 1등의 결과를 얻었다.
Introduction
DL에서 BERT,T5,GPT-3 같은 language models의 부상을 목격했다. 이 모델들은 web-scale data로 pretrained 되어 있으며 zero-shot, few-shot 또는 transfer learning에서 multitasking 능력을 보여준다.
massive downstream tasks를 위한 pretraining foundation models은 교육 비용을 줄이고 인간을 뛰어넘을 기회를 제공한다.
Vision 이나 Vision to text에서도 cross entropy를 사용한 single-encoder models이 좋은 성능을 보여줬다.
하지만 이런 모델들은 labeled vector를 가지며 image annotation에 크게 의존하여 자유 형식의 인간의 자연어 도메인을 갖지 않아 vision과 NLP를 모두 가진 downstream task를 수행하는데에 방해가 된다. 그래서 대량의 noised 웹 규모의 대량 데이터로 text와 vision을 병렬 encoder을 활용해 cantrastive loss를 얻어 pretraining하여 image to text model의 큰 가능성을 제시했다.
이 모델은 zero-shot의 기능이 가능하지만 fused image and text representations을 학습할 joint components가 없기 때문에 visual question answering (VQA) 같은 task를 해결하기에 부족하다.
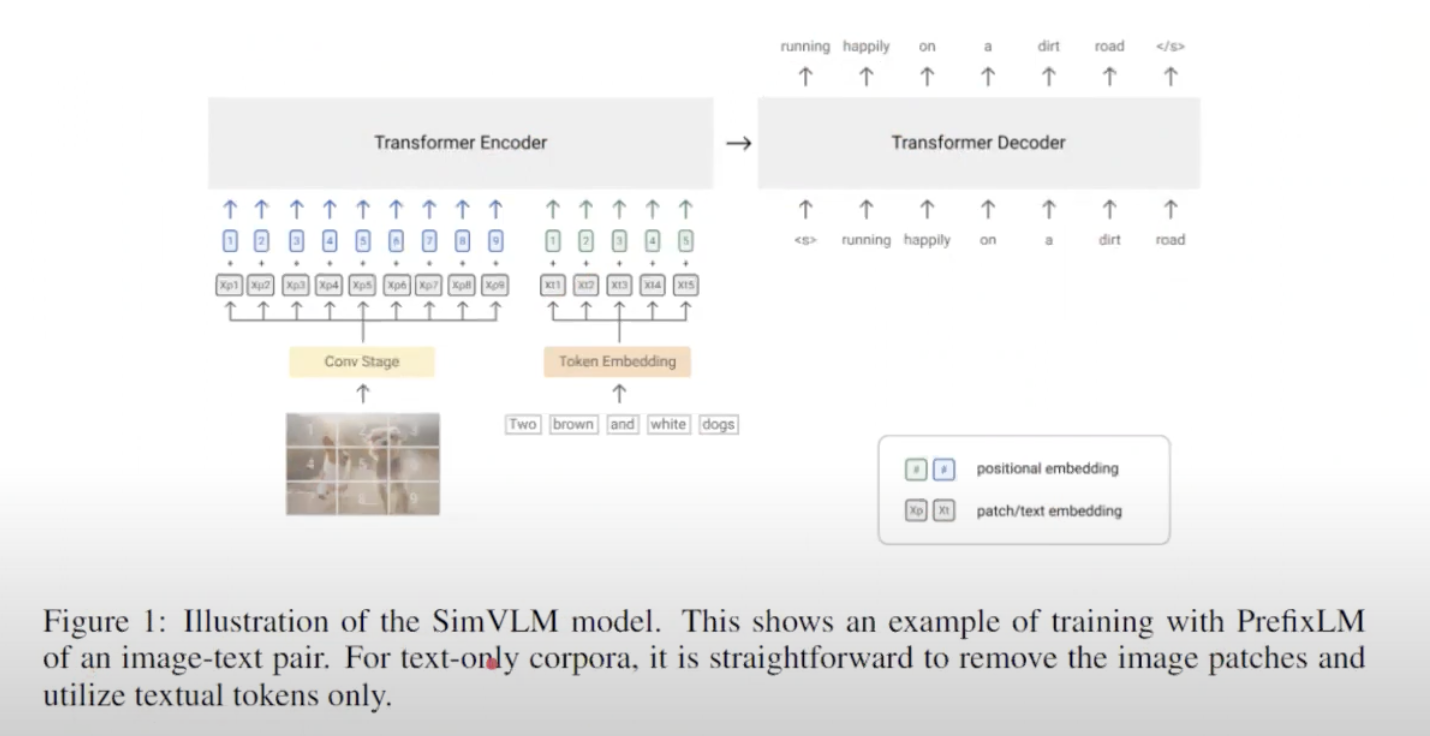
또 다른 연구에서는 일반적인 vision과 multimodal representations 학습하기 위해 encoder-decoder models 사용해 generative pretraining을 탐구했다. pretraining에서 모델은 encoder 측에서 이미지를 가져오고 LM의 decoder출력을 Language Modeling (LM) loss사용해 multimodal understanding tasks로 사용한다. 우수한 결과를 얻었으나 이미지 embedding과 정렬된 텍스트 representation을 생성하지 않으므로 crossmodal alignment tasks에 덜 적합하고 비효율적이다.
그래서 이 논문은 3가지 접근방식과 기능을 모두 포함하는 하나의 encoder-decoder model을 훈련한다. contrastive loss와 captioning (generative) loss 2가지 loss를 사용하는 encoder-decoder architecture인 Contrastive Captioners(CoCa)를 제안한다.
CoCa는 Decoder을 Unimodal과 Multimodal 두부분으로 분리한다. CoCa는 text-only representations을 encoding하기 위해 cross-attention in unimodal decoder layers 을 생략한다. multimodal image-text representations을 배우기 위해 multimodal decoder(layers cross-attending to image encoder outputs)을 cascade한다. 또한 이미지 encoder와 unimodal text model의 사이 contrastive objective와 multimodal decoder output에서 captioning objective을 사용한다.
CoCa는 모든 이미지를 단순 text취급하여 image annotation과 noised image를 모두 학습한다. 그리고 다양한 task에서 SOTA의 성능을 낸다.
Related Work
Approach
Natural Language Supervision
Single-Encoder Classification.
고전적인 Single-Encoder annotation text가 large crowd-sourced image annotation dataset에 맵핑되며 pretraining한다.
이러한 image annotation은 일반적으로 cross-entropy loss로 학습하기 위해 discrete class vectors 에 맵핑된다.
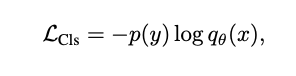
여기서 P(y)는 ground truth label에서 one-hot, multi-hot 또는 smoothed label distribution 이다. 학습된 이미지 encoder는 downstream tasks 위한 visual representation extractor로 사용된다.
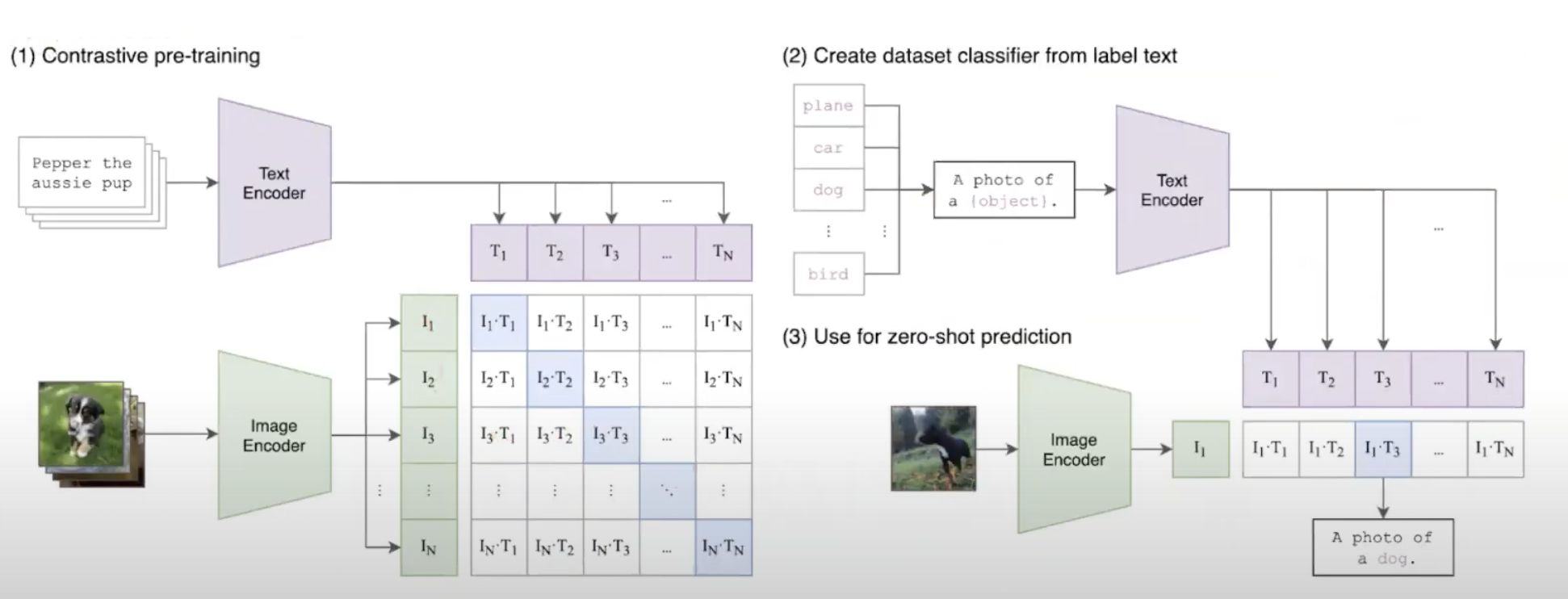
Dual-Encoder Contrastive Learning.
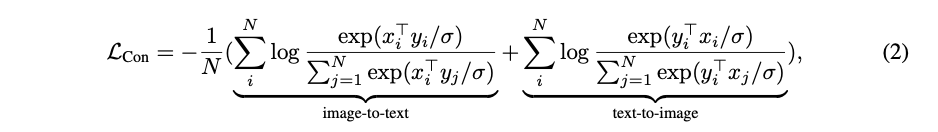
Dual-Encoder Contrastive Learning은 noised한 web dataset의 설명을 활용하고 text tower을 활용하며 자유롭게 학습한다.
두개의 encoder는 pair을 이루는 text를 sample batch의 다른 text와 대조하여 공동으로 최적화한다.
xi: i번째 이미지
yi: i번째 text embedding vector
N: batchsize
σ: temperature to scale the logits.
dual-encoder는 aligned text encoder를 학습한다.
Encoder-Decoder Captioning
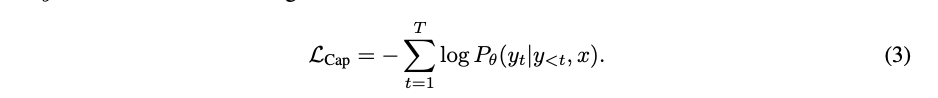
Dual-Encoder 접근 방식은 텍스트를 전체적으로 encoding하는 반면 generative approach는 detailed granularity를 목표로 하며 모델이 y에 정확한 토큰화된 text를 autogressively 하게 예측한다.
표준 encoder-decoder architecture에 따라 image encoder는 latent encoded features 를 제공하고 text decoder는 forward autoregressive factorization을 이루는 paired text y의 conditional likelihood가 maximize 하도록 훈련한다.
encoder-decoder parallelize computation and maximize learning efficiency하기 위해 teacher-forcing 으로 훈련된다.
Contrastive Captioners Pretraining

위의 3가지 교육 paradigms으로 CoCa가 만들어진다.
CoCa는 image encoder(ViT) 에의해 latent encoded features을 만들고 causal mastransformersking transformer decoder로 text를 만든다.
CoCa의 decoder transformers에서 unimodal text encoder을 표현하기 위해 decoder layer 전반부에서 cross-attention를 생략하고 multimodal image-text representation을 위해 image encoder에 cross-attending하여 나머지 decoder layer을 cascade한다.
결과적으로 CoCa decoder는 unimodal and multimodal text representations을 동시에 생성하여 contrastive and generative objectives을 동시에 적용하도록 한다.
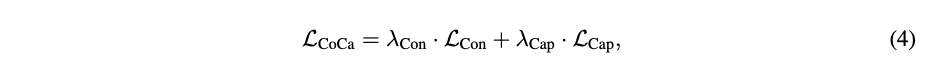
Decoupled Text Decoder and CoCa Architecture
captioning approach는 conditional likelihood of text를 최적화 하는 반면 contrastive approach는 unconditional text representation을 사용한다. 이 딜레마를 해결하기 위해 cross-attention mechanism을 건너 뛰어 decoder을 unimodal and multimodal components로 분리하여 해결한다.
unimodal은 causally-masked self-attention 으로 latent vectors 을 decode하고 multimodl은 causally-masked self-attention과 cross-attention을 적용한다.
모든 decoder layer는 토큰이 미래에 참여하는거 불가.
288x288크기 image resolution과 18x18patch 로 pretraine하여 총 256개의 image token 생성.
Attentional Poolers.
contrastive loss는 single embedding을 사용하는 반면 decoder는 일반적으로 sequence of image output tokens에 attention을 한다.
예비 실험에서 single pooled image embedding이 global embedding으로써 visual recognition에 도움을 줌을 밝혔다.
그래서 CoCa에서는 pooler을 사용하고 single multi-head attention layer with nquery learnable queries 을 사용한다.
generative loss nquery = 256 and contrastive loss nquery = 1
Pretraining Efficiency
분리된 decoder는 계산효율성에서 설계적 이점이 있다.
decoder는 단방향으로 훈련되기 때문에 contrastive and generative losses에 대해 효율적 계산이 가능하다.
CLS토큰을 Contrastive Loss 계산에 이용하기 때문에 한 모델 안에서 공유가 가능하다.
Contrastive Captioners for Downstream Tasks
zero-shot
Frozen-feature Evaluation
task별 pooler을 채택하여 downstream task해결
새로운 pooler 만을 학습하는 고정 encoder
CoCa for Video Action Recognition.
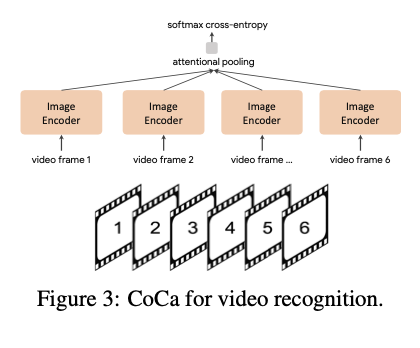
비디오의 여러 프레임을 가져와 각 프레임을 공유 image encoder에 개별적 input 그리고 softmax를 사용해 추가 pooler을 학습.
Experiments
Data = JFT와 ALIGN 65535 image-text pair
cap lambda: 2 con lambda: 1
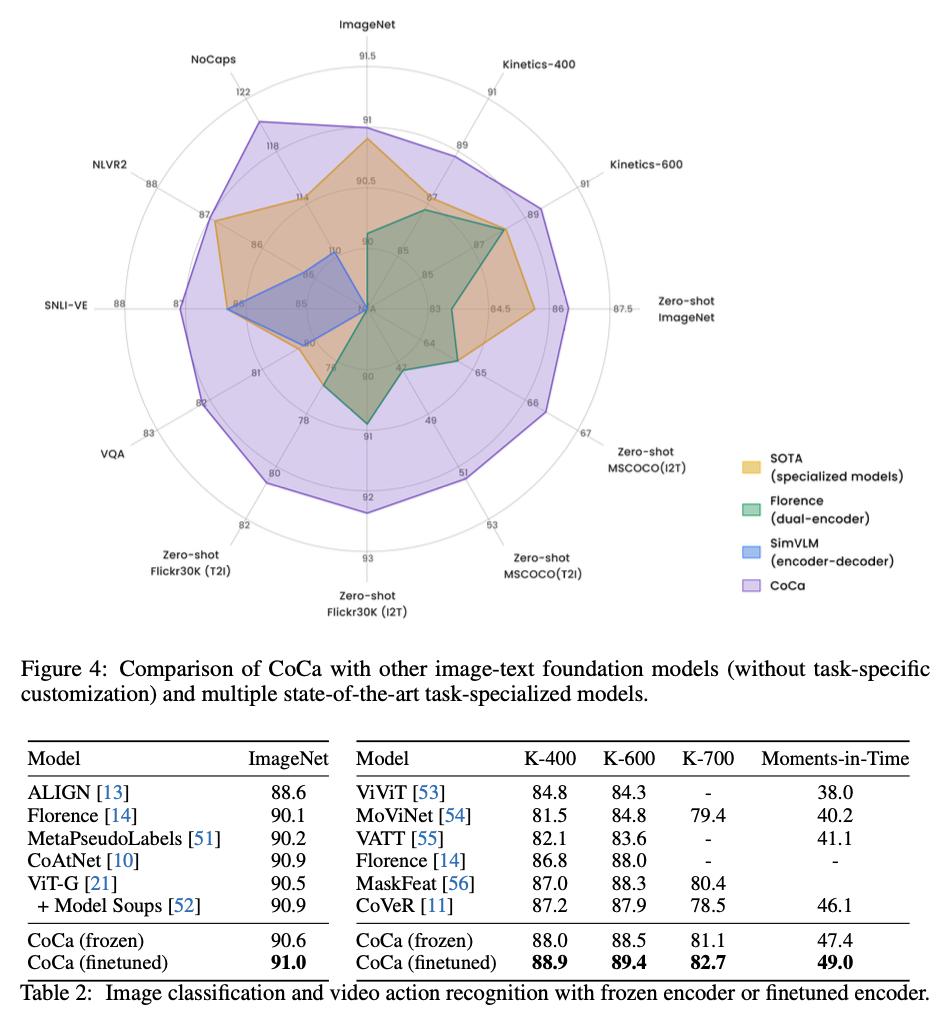
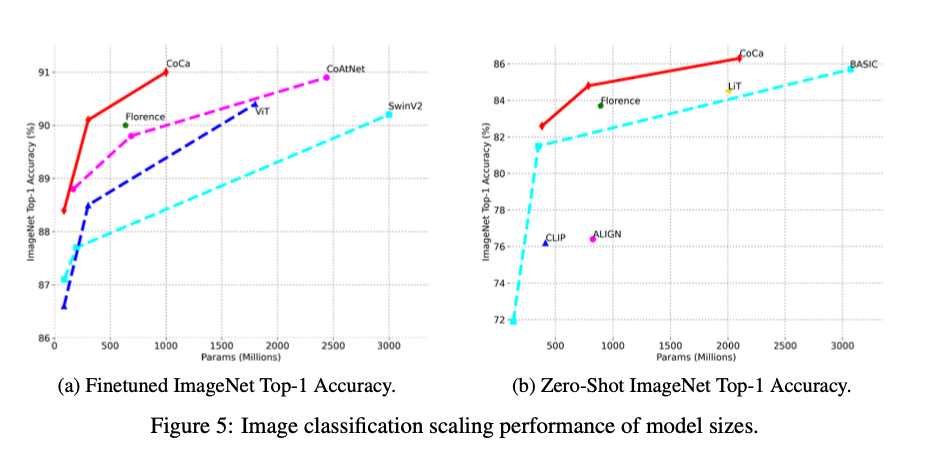
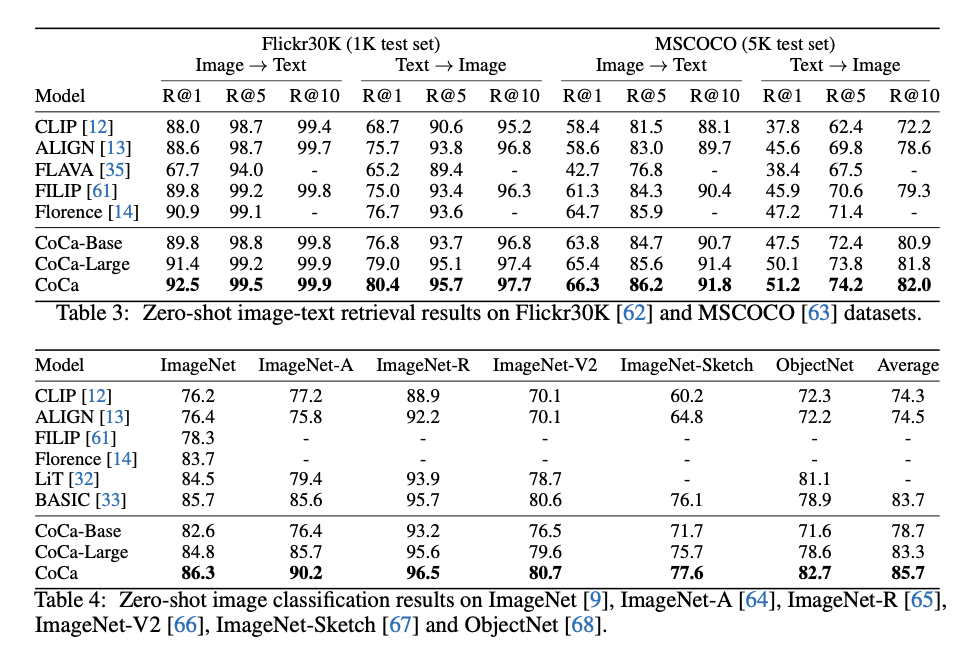
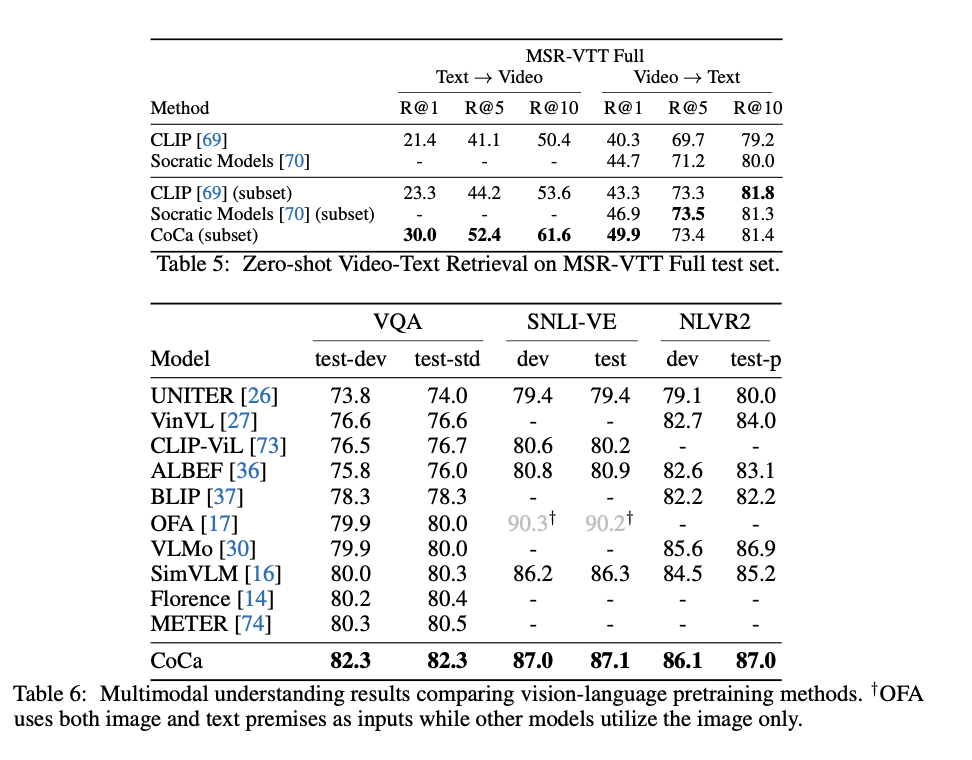
Crossmodal Alignment Tasks
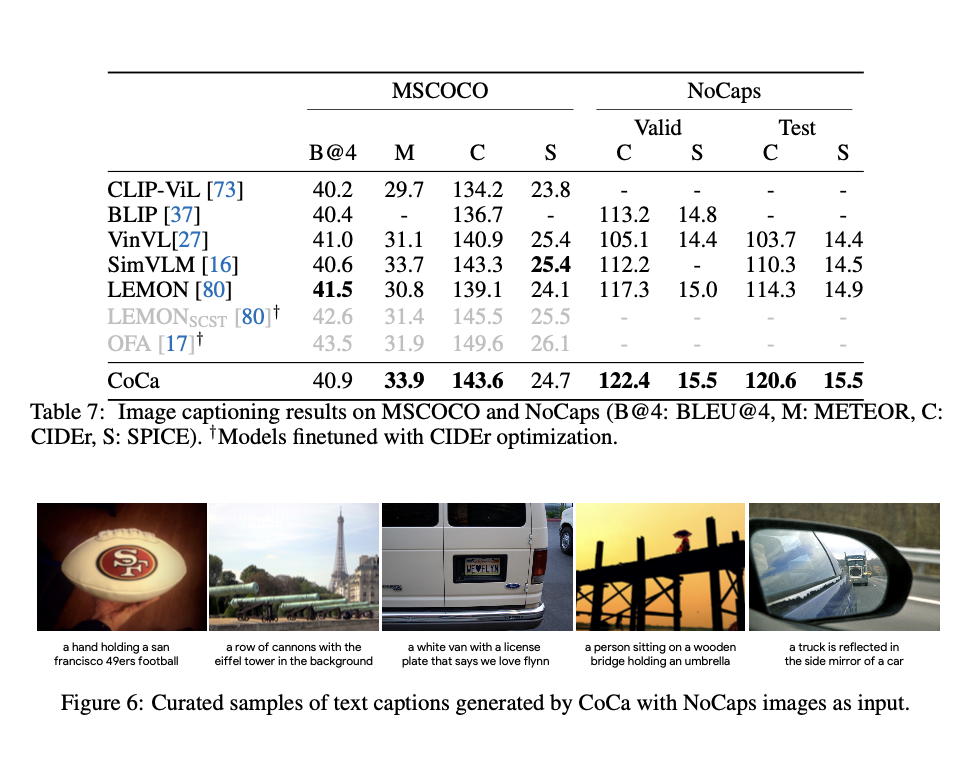
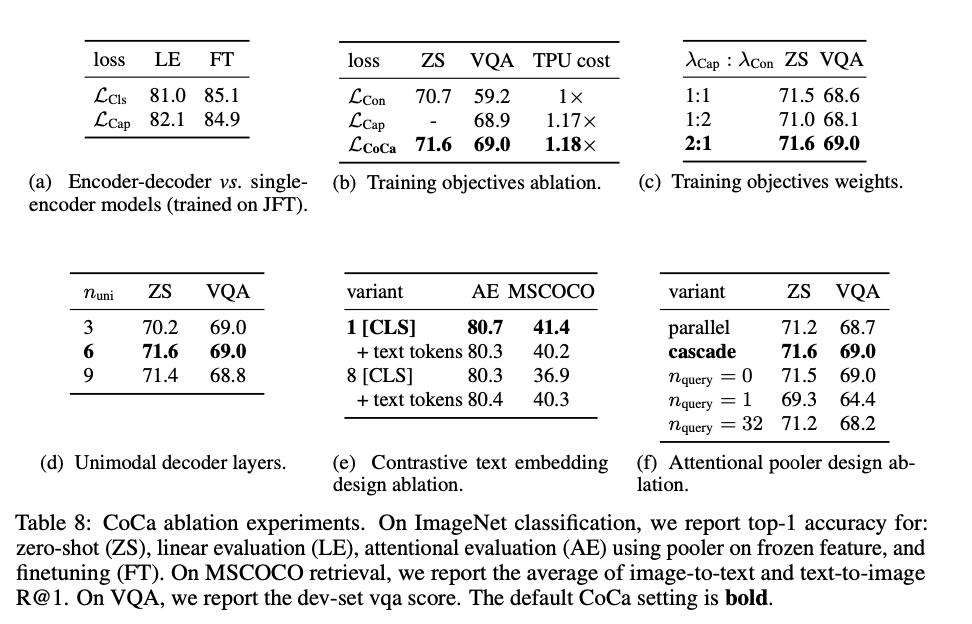
Ablation Analysis
Conclusion
CoCa라는 새로운 모델 제시
Decoder을 분리.
CLIP의 Contrastive loss와 SimVLM의 Captioning Loss를 사용하여 여러 task에서 SOTA 의 성능을 제시
