
CoCa논문을 읽으며 알게된 사실이 주요 기술이 CLIP이나 SimVLM을 모방했다는 것이다. 그래서 CLIP을 우선적으로 공부 후 찾아봐야겠다 결정하고 CLIP 논문을 분석했다.
Abstract
computer vision의 SOTA는 predetermined object categories에서 예측하도록 훈련된다. 이런 제한된 형태는 다른 vision task를 위한 새로운 labeling과 데이터가 필요하기 때문에 일바성과 유용성을 제한한다.
image에 대한 raw text를 직접 학습하는 것이 supervision에 훨씬 광범위한 소스를 주는 대안이다.
이 논문은 인터넷의 400M 데이터쌍을 사용해 어떤 caption이 어떤 image와 함께 할지 예측하는 방식의 pretraining이 SOTA 이미지 표현을 학습하는 효율적이고 확장가능한 방법임을 논증한다.
pretraining 후 자연어를 사용해 학습된 시각적 개념을 참조하여 downstream task에 zero-shot 방법을 사용한다.
30개 영역의 computer vision dataset에서 ResNet50과 비교하며 이때 zero-shot 방식을 사용한다.
Introduction and Motivating Work
raw text에서 Pre-training methods는 NLP에서 큰 혁명을 일으켰다. autoregressive and masked language modeling같은 Task-agnostic objectives 는 compute, model capacity, and data,에 구애받지 않고 꾸준히 확장하고 높은 성능을 보여줬다.
standardized input-output interface로서 text-to-text의 개발은 작업에 구애받지 않는 architecture에서 zero-shot이 가능하게 했다.
output heads 나 data별 사용자 정의가 필요하지 않는 downstream datasets, GPT-3같은 시스템은 맞춤형 모델과 비교해 경쟁력을 갖추면서 데이터 세트별 교육 데이터가 거의 필요하지 않게 되었다.
이런 결과는 web-scale collections of text surpasses로
aggregate supervision accessible to modern pre-training methods가 label이 지정된 highquality crowd-labeled NLP datasets을 이길 수 있음을 시사한다.
하지만 Vision영역에서는 여전히 crowd-labeled datasets을 사용하는 것이 관행이다.
그래서 이 논문은 Vision 영역에서 web-scale collections of text로 학습하는 scalable pretraining 방법이 유사한 혁신을 가져올지 질문한다.
- natural langauage supervision
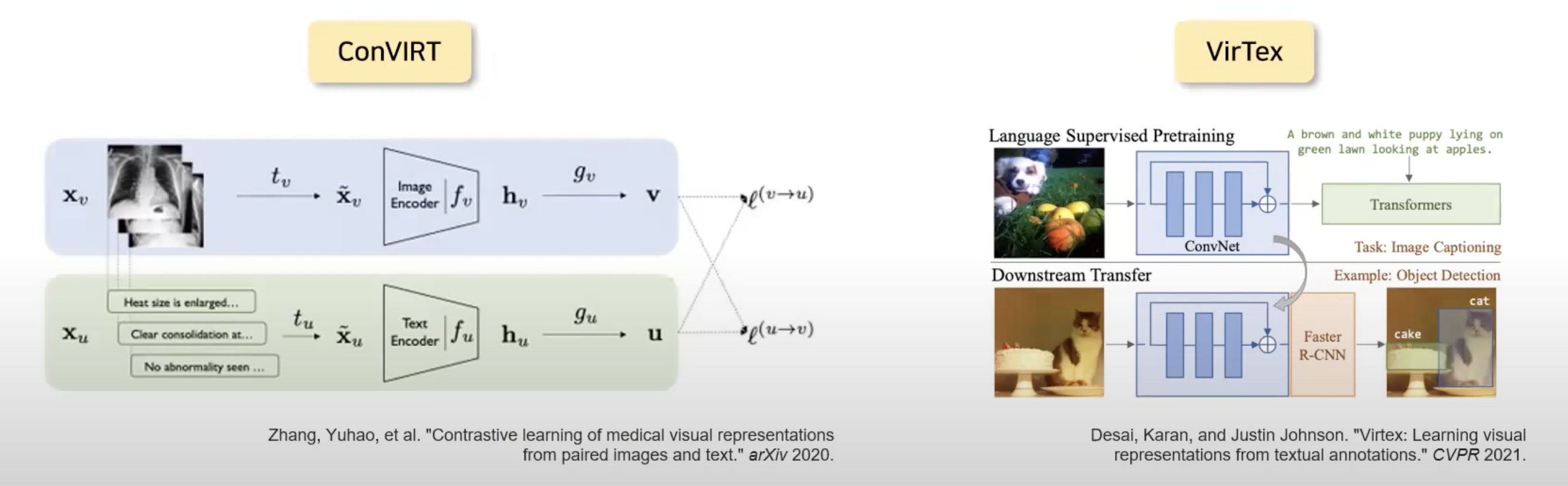
VirTex (Desai & Johnson, 2020), ICMLM (Bulent Sariyildiz et al., 2020), and Con- VIRT(Zhang et al., 2020) 에서 transformer-based language modeling, masked language modeling, 그리고 contrastive objectives to learn image representations from text를 증명했다.
natural language supervision을 image representation learning 에 사용하는 것은 아직 입증된 좋은 결과가 없다.
자연어는 일반성을 통해 훨씬 더 광범위한 시각적 개념을 표현하고 감독할 수 있다.
하지만 이런 접근 방식에서 static softmax classifier을 사용하는데 이는 동적 출력에 mechanism이 부족하여 유연성을 심각하게 줄이고 zero-shot을 제한한다.
결정적으로 자연어에서 직접 이미지로 표현되는 모델의 결정적 차이는 규모다.
VirTex, ICMLM, and ConVIRT는 1~20만개의 데이터를 학습시킨다.
이 논문은 internet으로 부터 얻은 4억개의 image,text pair dataset을 만들고 학습시키며 그 모델을 CLIP이라 명명한다.
이 모델을 zero-shot성능으로 30개 이상의 dataset에서 supervised model과 비교한다.

CLIP zero-shot 모델은 결과적으로 동급 supervised model에 비해 계산 효율성이 높음을 보여주며 zero-shot 영역의 기능을 대표하는 모델임을 나타낸다.
Approach
Natural Language Supervision
핵심 아이디어: learning perception from supervision contained in natural language
visual representations from text paired with images
자연어 학습은 standard crowd-sourced labeling for image classification 에 비해 확장하기 쉽다.
자연어 학습은 해당 표현을 언어에 연결시켜 zero-shot이 가능하게 한다.
Creating a Sufficiently Large Dataset
MS-COCO같은 고품질 데이터는 100000개로 적다. YFCC100M 데이터도 필요한 데이터를 filltering을 거치면 15M만 사용 가능하다. 저자는 internet을 통해 400M개의 image-text pair dataset을 사용한다. text는 500000개의 query 집합중 하나를 표현한다.
각 한 batch 종류의 검색어당 사진은 20000개로 제한하여 데이터 불균형을 막았다.
Selecting an Efficient Pre-Training Method
최첨단 vision모델은 너무 많은 시간을 훈련하는데 사용한다. ResNeXt101-32x48d는 19 GPU years이 Noisy Student EfficientNet-L2 는 33 TPUv3 core-years 가 필요하다. 이 둘다 1000개의 imageNet 데이터만을 예측하는 모델이다.
그래서 natural language supervision을 확장하는 메트릭을 기반으로 pretraining을 진행했다.
초기에는 virTex와 유사한 방법으로 CNN과 text transformer를 공동으로 교육했으나 확장하는데 어려움이 있었다. 두번째는 63 million parameter transformer language model이 predicts a bag-of- words encoding of the same text.방법으로 학습한다.
두 방법은 각 이미지에 수반되는 정확한 text를 예측하려는 공통점이 있다.
최근 연구에서 (contrastive representation learning for images) equivalent predictive objective 보다 contrastive objectives 가 더 좋은 representations 학습을 할 수 있음이 밝혀졌다.
generative models of images이 동등한 성능을 가진 contrastive models 보다 더 많은 computation을 사용함이 밝혀졌다.
그래서 이 논문은 해당 텍스트의 정확한 단어 보다 어떤 텍스트가 어떤 이미지와 짝을 이루는지 예측하는 더 쉬운 교육 방법으로 학습하는 방법을 탐색했다.
동일한 bag-of-words encoding 기준선에서 시작해서 predict 목표 대신 contrastive 목표로 교체했으며 ImageNet zero-shot 기준 효율성에서 4배 더 상승한 결과가 있었다.
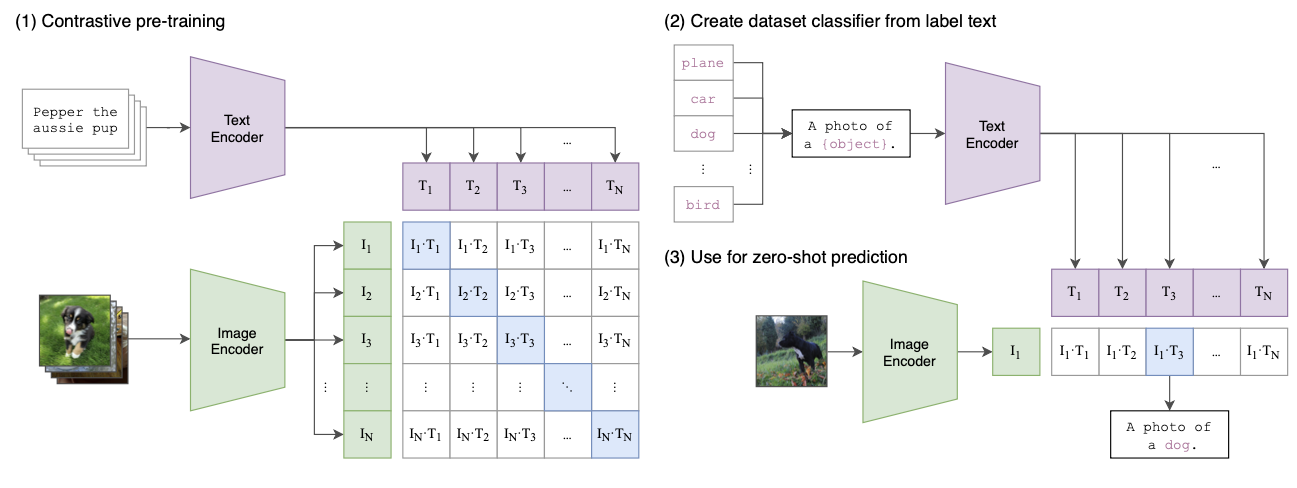
CLIP은 NxN 배치의 이미지,텍스트 pair 데이터에서 실제로 발생한 쌍을 예측하도록 훈련한다. N개의 correct 데이터셋 쌍에서 이미지와 텍스트의 embedding 값의 cosine similarity 가 최대가 되는 동시에의 N^2-N의 incorrect 데이터셋의 cosine similarity가 최소화 함으로써 symmetric cross entropy loss를 최적화 한다.
각각의 encoder’s representation to the multi-modal embedding space 에서 linear projection 만을 수행한다.
Choosing and Scaling a Model

image encoder에 2가지 모델 고려: ResNet,vision transformer
text encoder에 두가지 모델 고려: CBOW, Text Transformer (8개의 attention head)
일반적인 Computer Vision은 모델의 깊이만 증가시키지만 CLIP에서는 깊이 넓이 resolution 모두 추가컴퓨터 할당.텍스트의 경우 깊이는 그대로 사용하고 넓이만 조절.
Training
ResNet 5개와 ViT 3개
ResNetx4, ResNetx16, ResNetx64, ResNet101, EfficientNet
ViT-B/32, ViT-B/16, ViT-L/14
32epoch, Adam
Batchsize = 32,768
Experiments
INITIAL COMPARISON TO VISUAL N-GRAMS
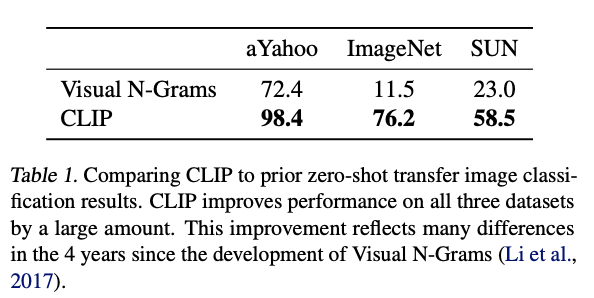
visual N-gram -> 유일한 zero-shot transfer model
PROMPT ENGINEERING AND ENSEMBLING
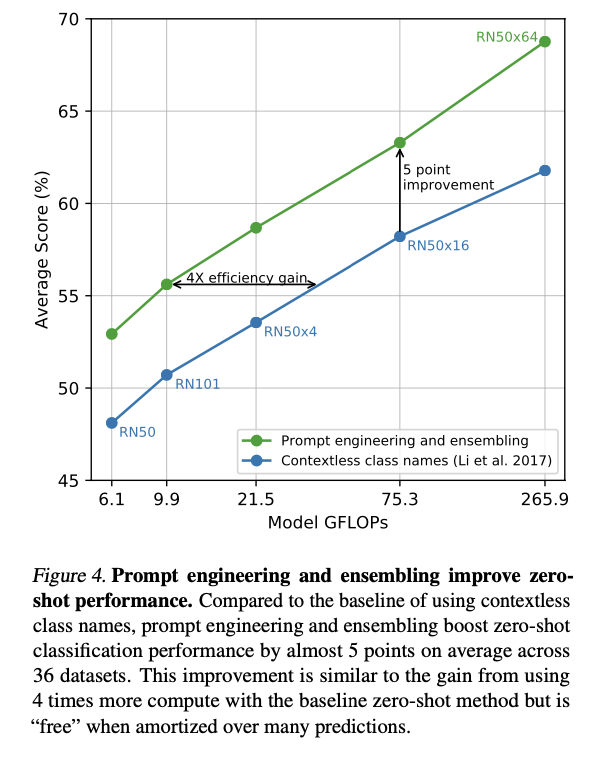
simple prompt engineering
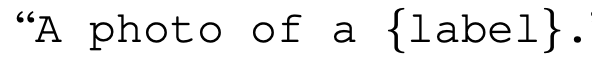
-> ingreasing 1.3%
customizing prompt engineering
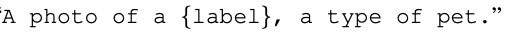
-> Well on oxford3
Emsembleing prompt engineering
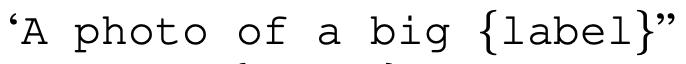
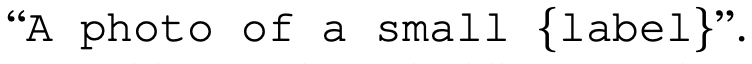
embedding space에서 Emsemble
-> 3.5% increasing
ANALYSIS OF ZERO-SHOT CLIP PERFORMANCE

ResNet50과 Zero-Shot CLIP의 Clissifier 성능 비교
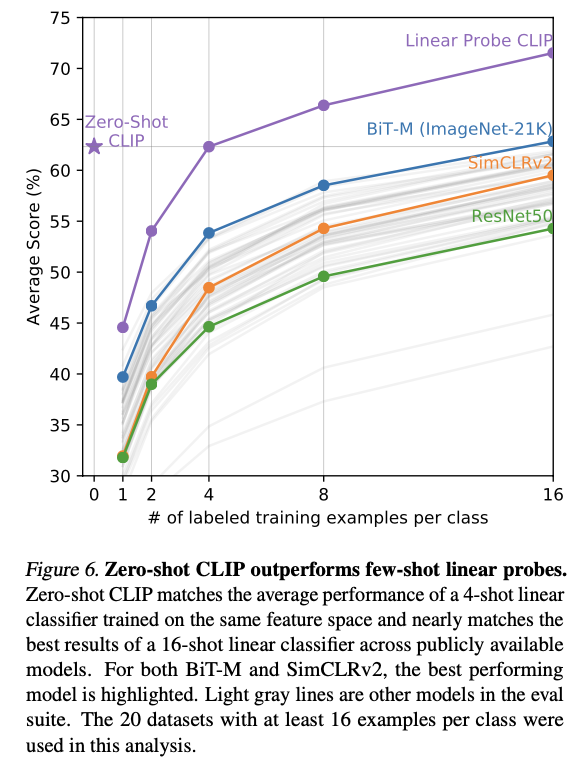
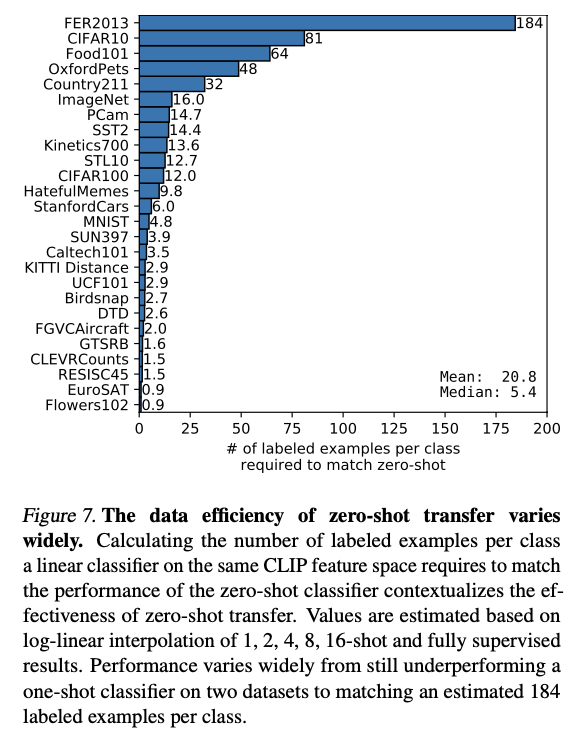
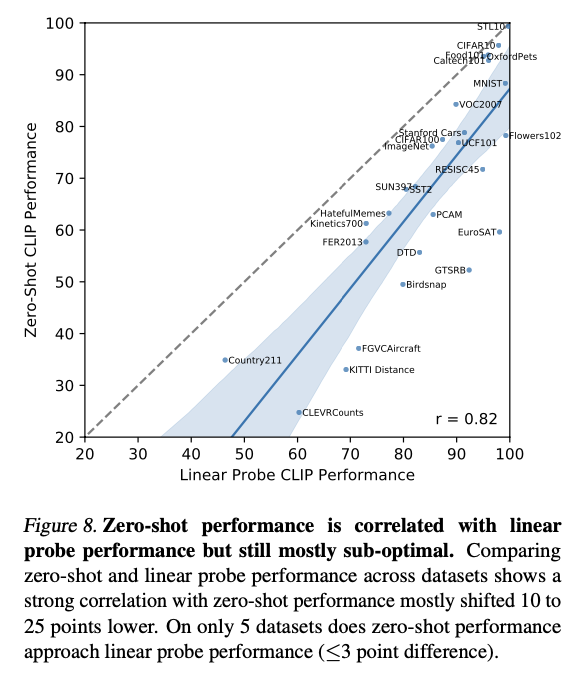
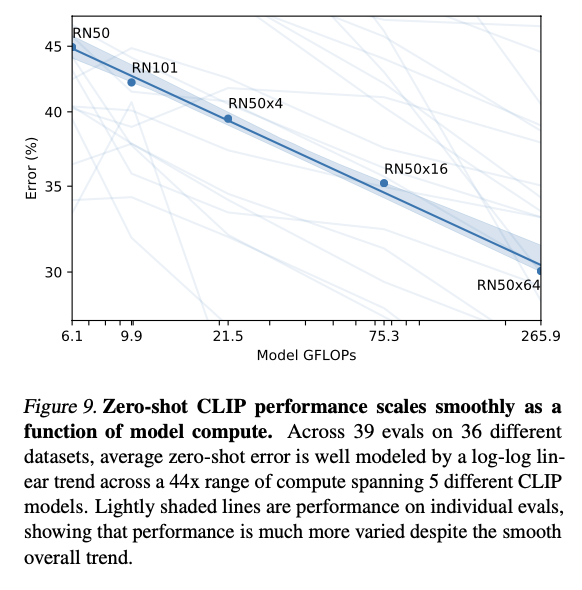
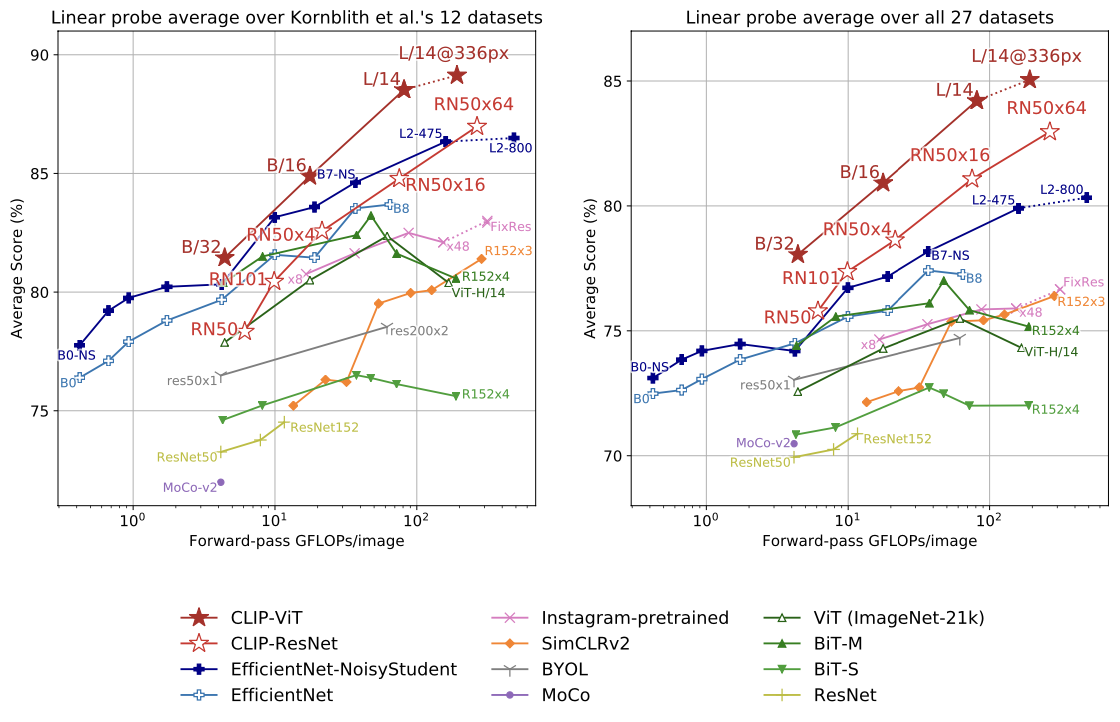
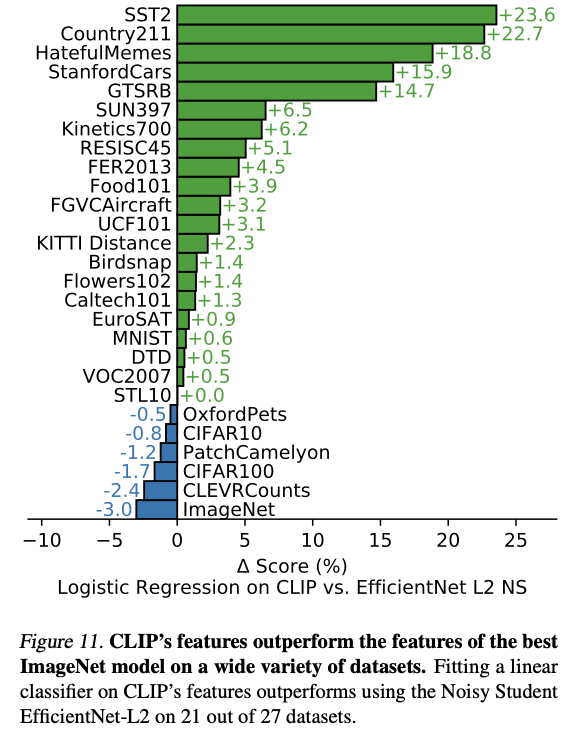
Representation Learning

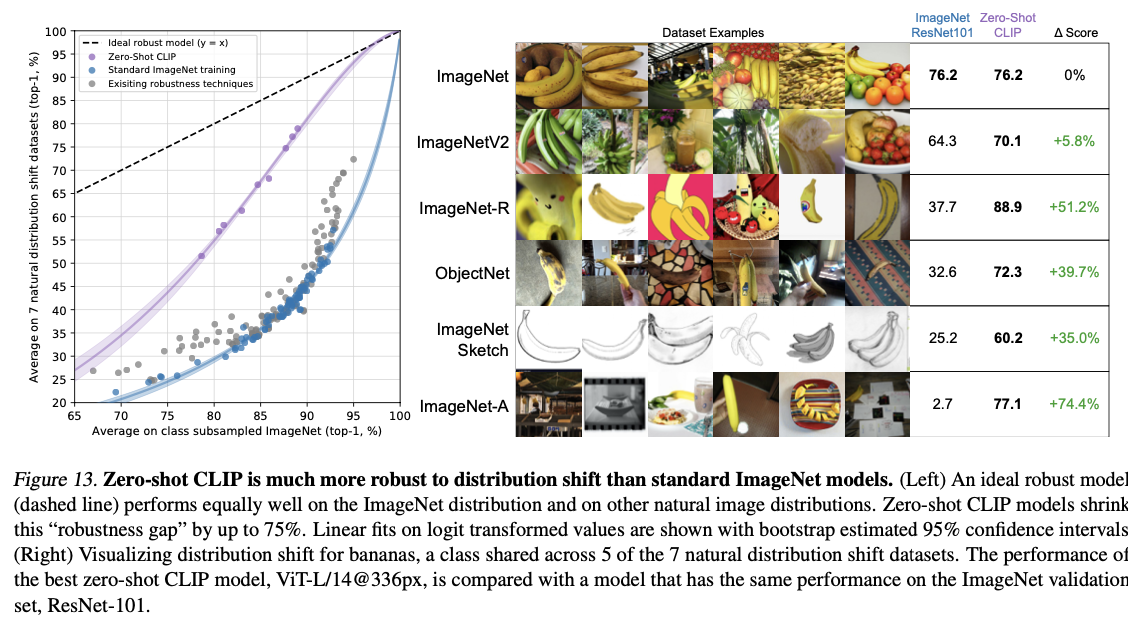
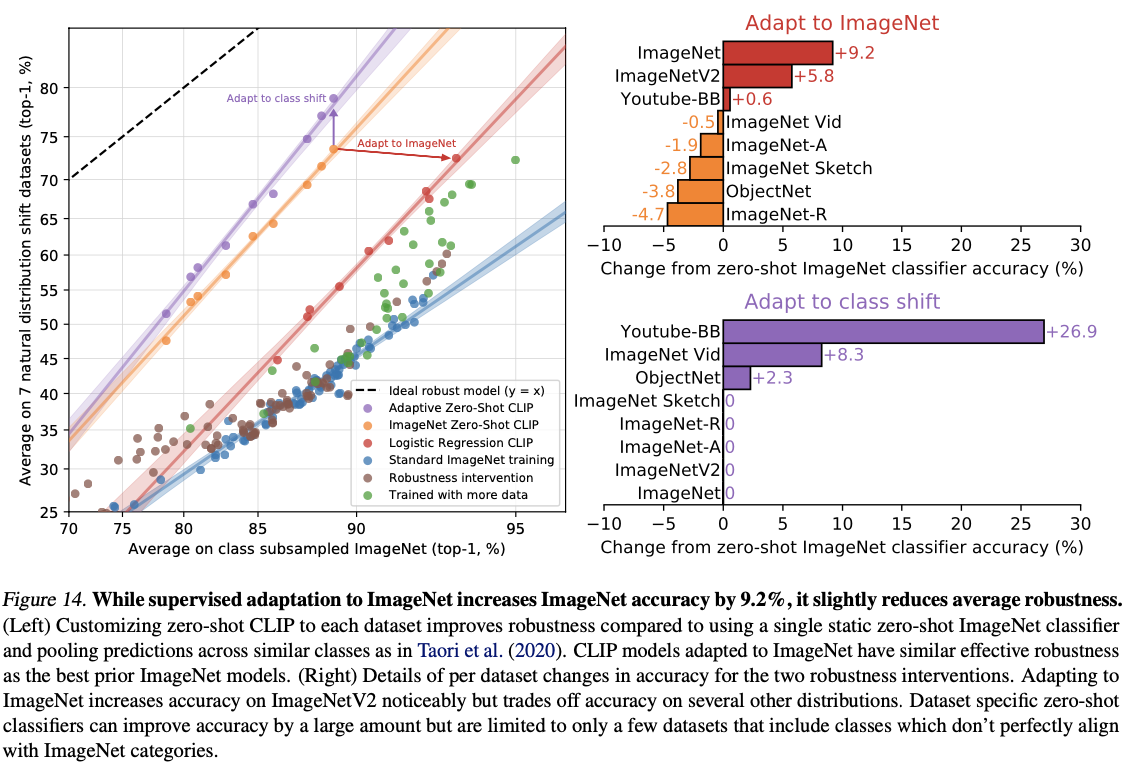
CLIP robust on natural distribution shift
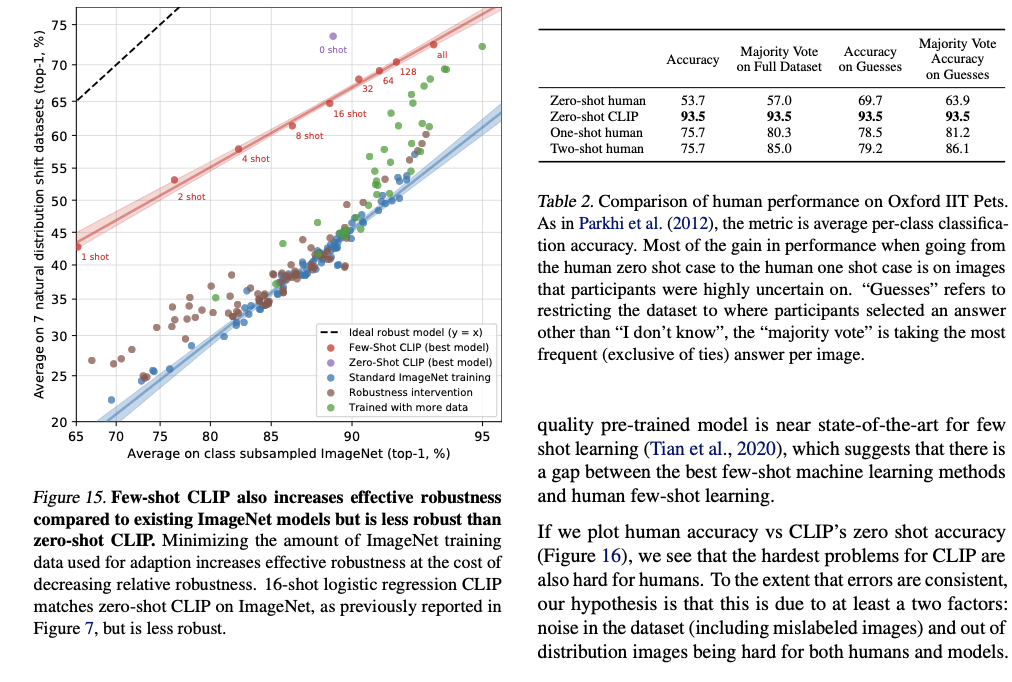
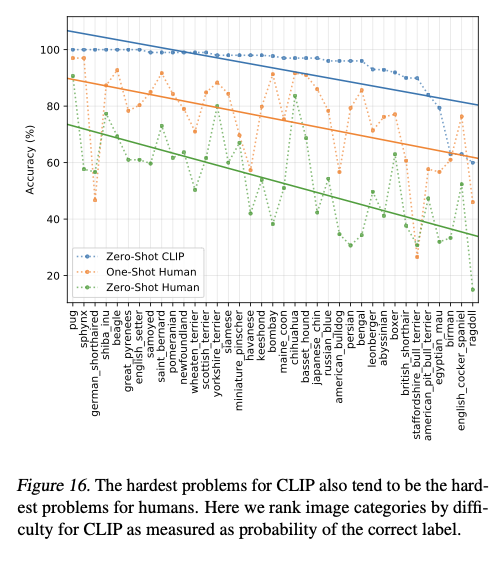
Comprasion to Human performance
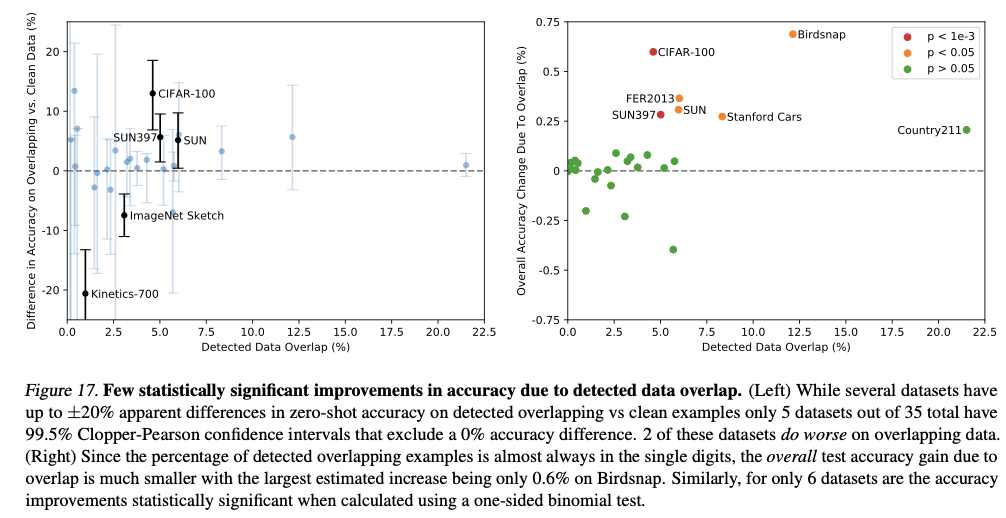
Data Overlap Analysis
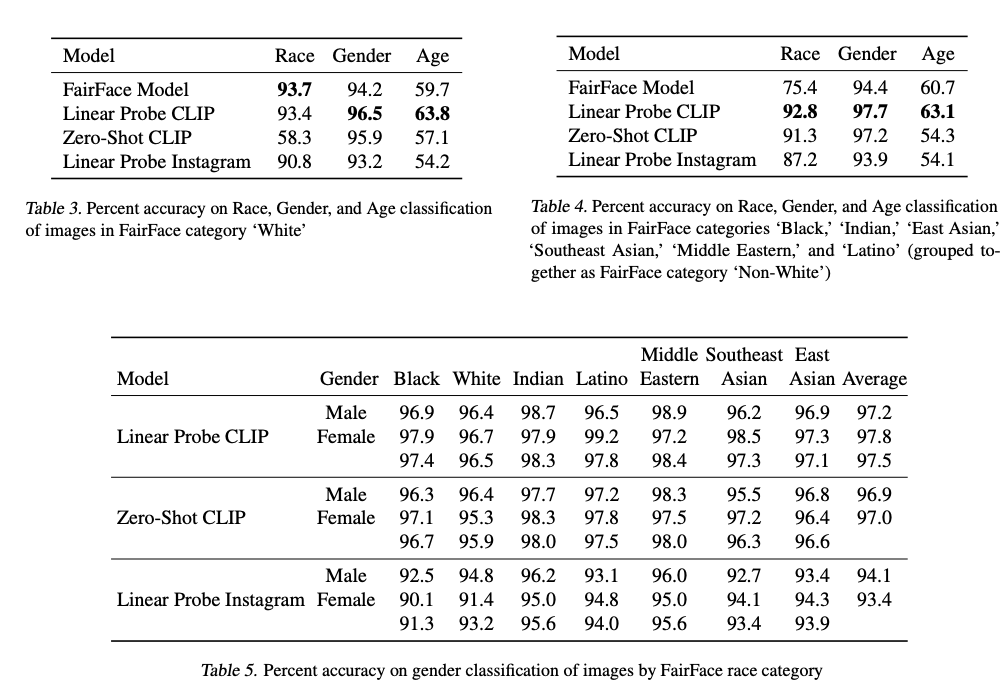
Limitations
아직 SOTA의 근접 효과는 내지 못함, 1000배의 컴퓨팅 학습이 필요할 것으로 예측
Broader Impacts
Conclusion
Contrastive Language Image Pretraining 은 zero-shot 영역에서 좋은 성능을 낸 image to text model
인터넷을 활용한 앞으로 vision task의 성능개선 방향을 제시
