
지난 해 동안의 성과와 도전에 대한 생각을 정리하고, 앞으로의 성장 방향을 명확히 하기 위해서 작성하였습니다.
📌 Introdution
2023년 올해의 문장!!
오늘의 나는 성장하였나?
매일은 물론 매 순간을 도전과 학습의 기회로 채우고자 한 한해였습니다.
DevOps 엔지니어로서 직무를 수행하며 새로운 기술과 도구를 터득하면서 동료들과의 협업을 통해 의미있는 결과를 만들 수 있었습니다.

📌 Action
2023년 목표는 레거시를 개선하여 클라우드 환경에서 인프라를 더욱 잘 운영할 수 있는 환경을 만들기 위해 노력하였습니다.
프로젝트를 설명하기 위한 구조는 아래의 순서를 따라 작성하였습니다.
- Plan
구체적인 목표를 제시하고, 해당 목표를 달성하기 위한 계획을 설명
- Project Experiences
사용한 기술 스택, 도구, 플랫폼을 나열하고, 해당 기술들을 어떻게 활용했는지에 대한 세부 정보를 제공
- Issues and Challenges
마주한 기술적, 조직적 도전 과제를 솔직하게 언급하고, 어떻게 극복했는지에 대한 과정
- Learning
실수와 실패에서 어떻게 배웠는지, 그리고 이를 통해 개인적 및 전체적인 성장을 이룬 부분을 기술
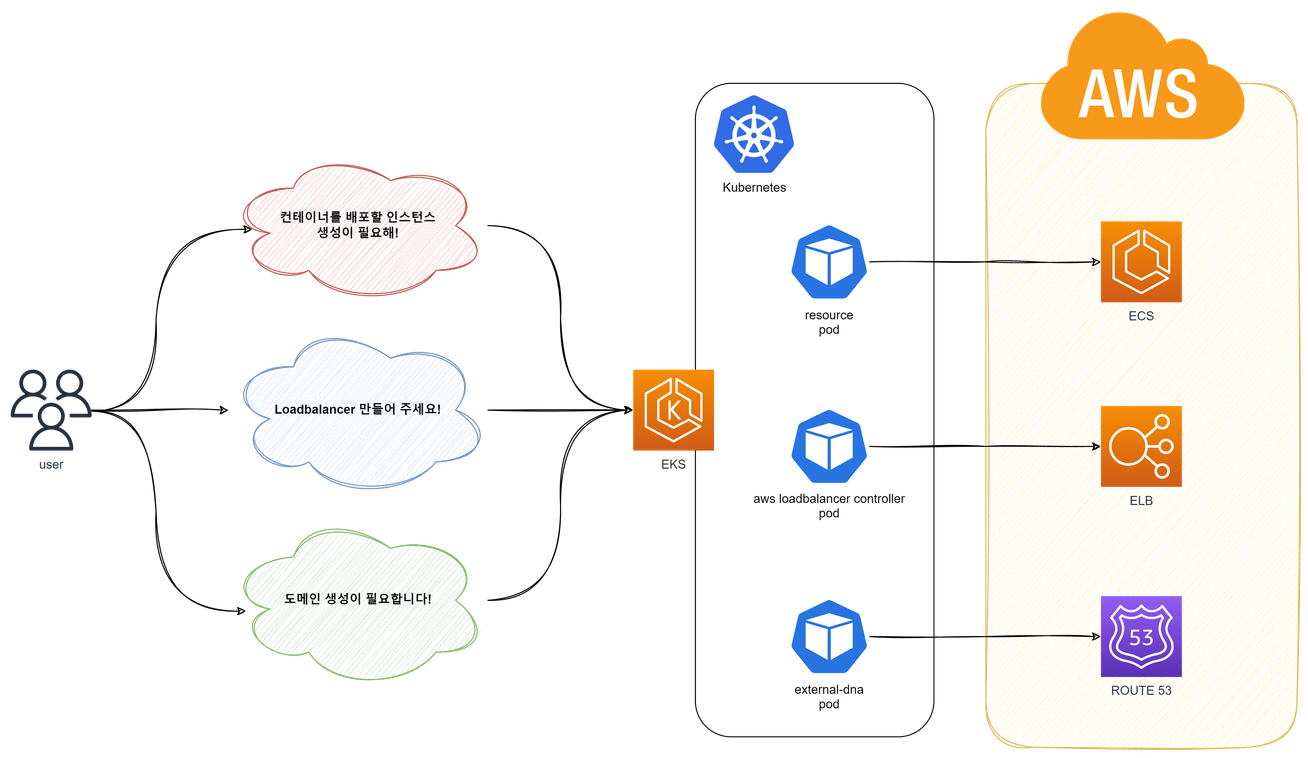
✅ EKS 마이그레이션
ECS에서 운영 중인 서비스를 EKS로의 마이그레이션을 진행했습니다.
회사의 서비스 확장으로 컨테이너 수가 급증하면서, ECS의 제한적 용량과 개발 환경에 따른 확장 어려움으로 인해 EKS로의 전환을 결정했습니다.
ECS 운영시 제한사항
-
ECS에서 허가된 용량의 컨테이너로만 운용할 수 있습니다. (제한적)
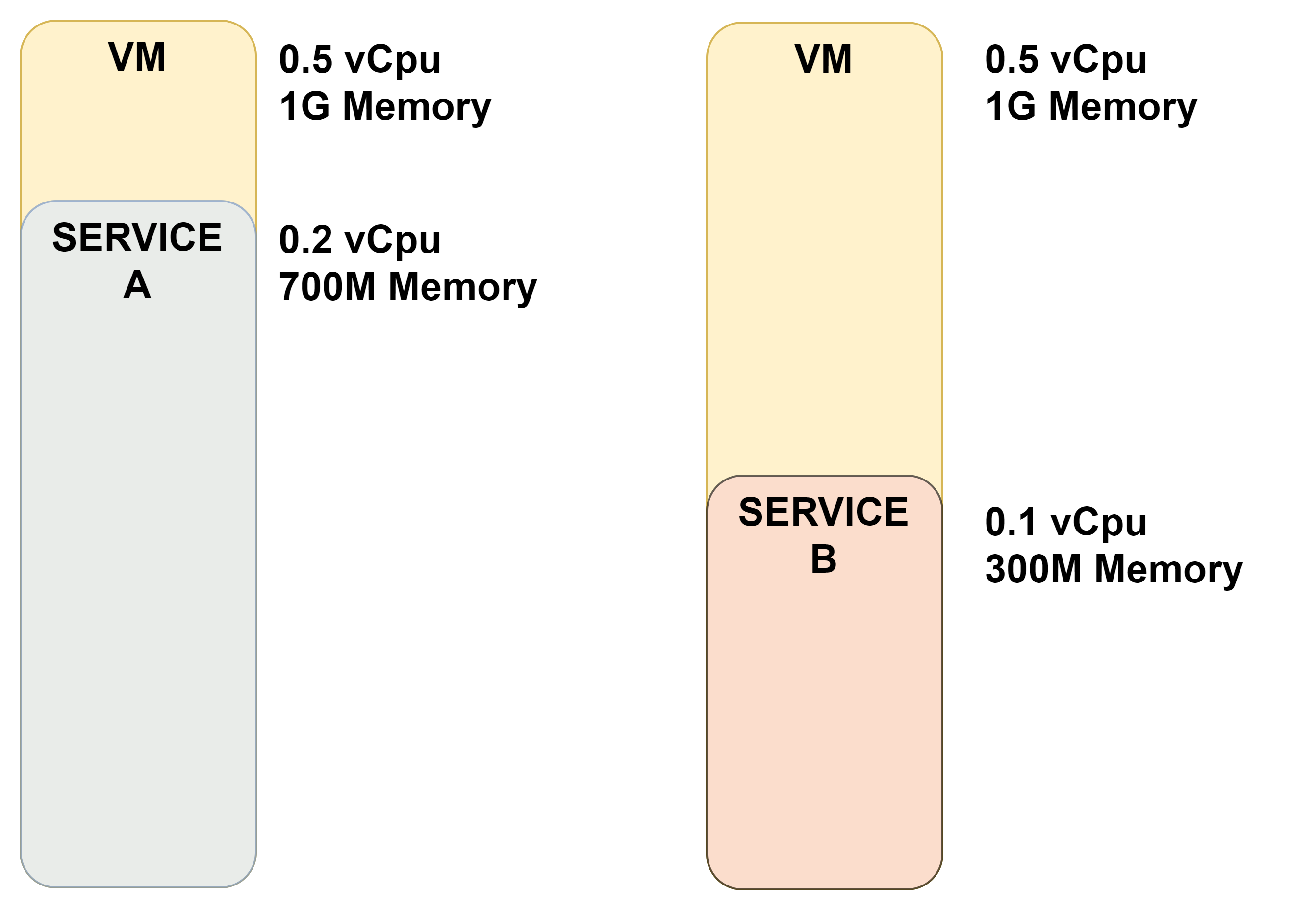
Service에 따라 다른 용량의 리소스를 필요한 경우에도 AWS에서 제한적으로 설정되어있는 리소스 용량을 할당받아 사용해야 하므로 불필요한 리소스 낭비가 발생합니다.
-
개발 환경에 따른 인프라 확장성을 따라가기 힘들어집니다.
하나의 서비스를 생성할때, 각각의 개발 환경(dev,stag,prod)에 맞춰 컨테이너를 생성하고 있습니다.
proxy, domain-name 역시 각각 생성해야 하고 형상 관리의 필요성 또한 커지게 되었습니다.
Plan
EKS로 마이그레이션을 통해 다음과 같은 이점을 기대하였습니다.
-
K8s를 통해 인프라를 직접 관리하므로 불필요한 리소스 낭비가 줄어듭니다.
최적화된 용량의 컨테이너를 직접 배포하므로 자원을 효율적으로 사용할 수 있습니다.

-
리소스 설치 및 연동이 간편해 집니다.
- Manifest 파일로 인프라를 관리하므로 GitOps를 통해 SSOT 원칙으로 인프라를 관리할 수 있습니다.
SSOT란?
SSOT는 Single Source of Truth의 약어로, 데이터베이스, 애플리케이션, 프로세스 등의 모든 데이터에 대해 하나의 출처를 사용하는 개념을 의미합니다. 이는 데이터의 정확성, 일관성, 신뢰성을 보장하고, 일관성 있는 의사결정 및 작업 효율성을 높이는 데 도움을 줍니다 - SSOT(Single Source of Truth)란?
Project Experiences
GitOps(@ArgoCD)
EKS로 마이그레이션을 기대하며 가장 목표로 했었던 GitOps를 도입하였습니다.
서비스가 확장됨에 따라 인프라에 대한 작업을 진행하는 경우 적극적으로 작업내용을 전파해도 종종 잊어버리는 경우가 발생하곤 했습니다.
형상관리를 manifest로 선언하여 팀원과 하나의 소스코드로 인프라를 관리할 수 있게 되었습니다!
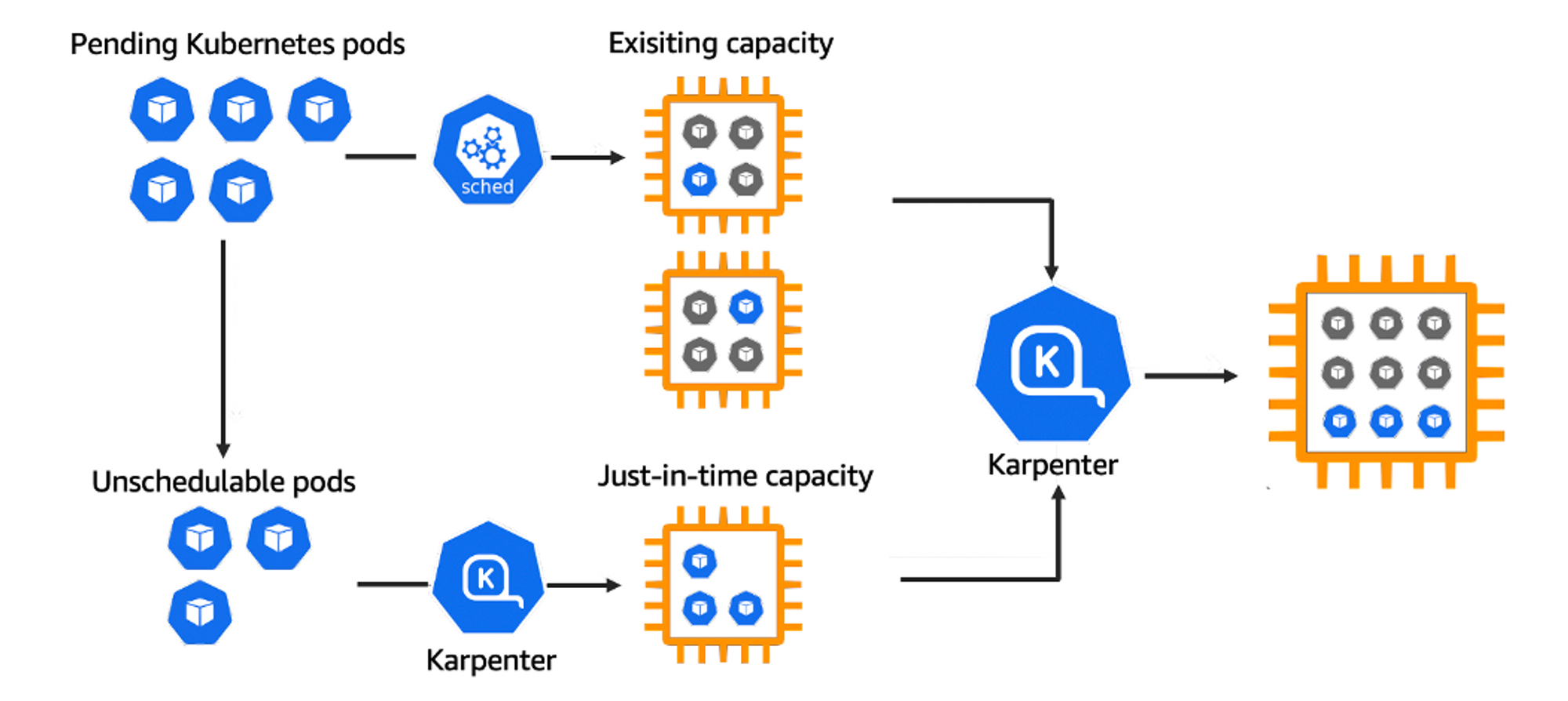
Karpenter
카펜터를 도입하여 실제 서비스를 운영하는 Pod가 배포되는 Node를 자동으로 관리할 수 있도록 구성할 수 있었습니다.
EKS와 카펜터를 통해 그림을 그릴때 무제한의 크기의 도화지(?)를 얻은 것 같이 인프라를 운영할 수 있게 되었습니다.
Issues and Challenges
쿠버네티스 스터디
EKS 마이그레이션을 계획하고 제일 먼저 쿠버네티스에 대해서 스터디를 시작하였습니다.
EKS 및 KOPS 관련 스터디 내용은 아래 링크를 통해 확인할 수 있습니다.
1년간의 지속적인 스터디를 통해 쿠버네티스의 필요성과 활용 가능성을 명확히 이해하게 되었습니다.
쿠버네티스 자격증 CKA,CKAD 취득
DOIK2, AEWS, PKOS 등의 시리즈를 통해 깊이 있는 내용을 공부하고 실전 경험을 쌓음으로써, 쿠버네티스의 어려움을 극복할 수 있었습니다.
ECS to EKS Migration
24/7 운영되고 있는 서비스를 중단없이 마이그레이션하는 것은 항상 어려운 작업인 것 같습니다.
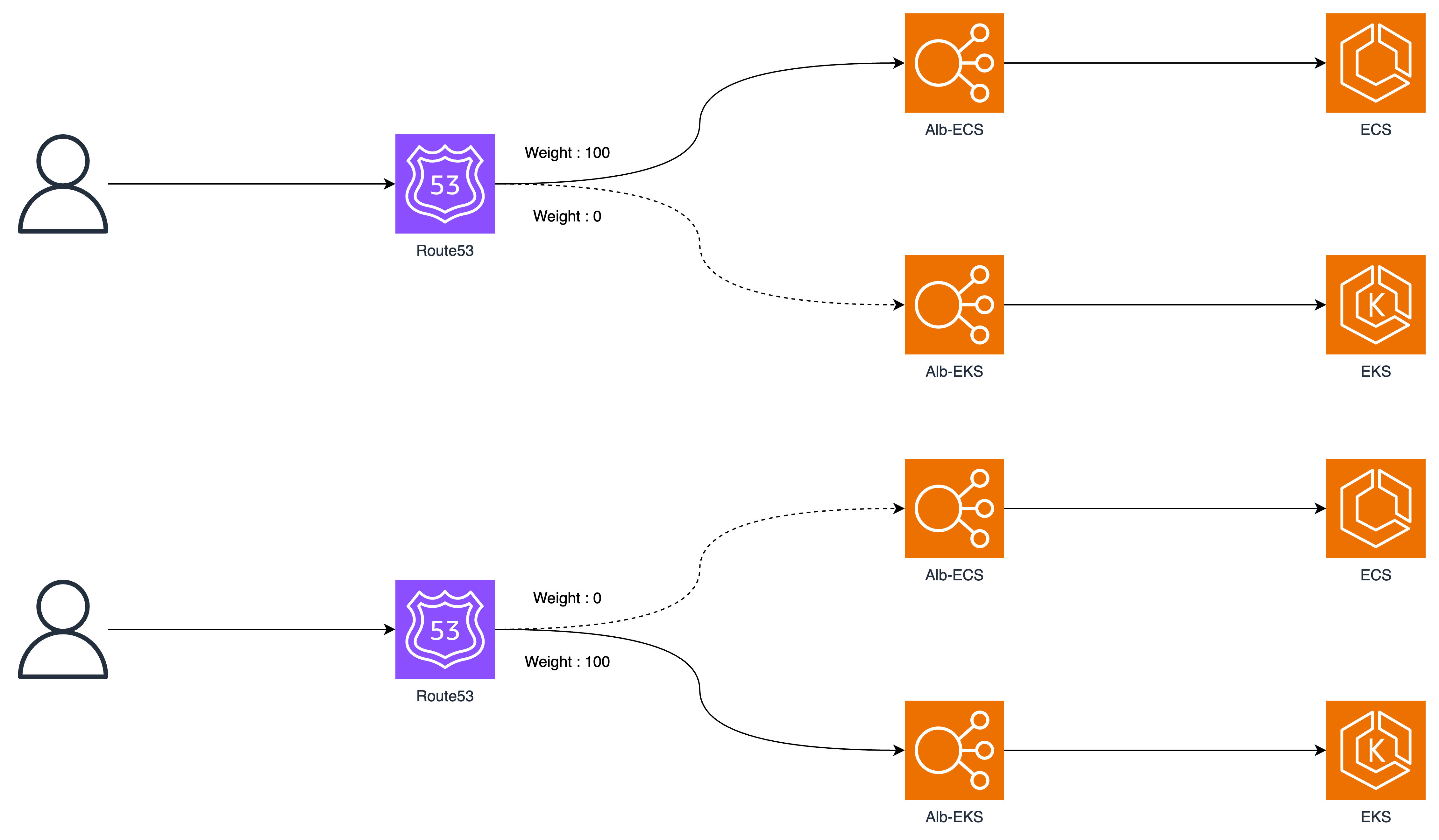
ECS 클러스터를 통합하면서 ALB 내부에서 가중치 기반으로 Target 그룹을 조정하여 배포하는것은 이번 마이그레이션에서 사용할 수 없었습니다.
새로 배포되는 EKS의 파드는 AWS-Loadbalancer-controller를 통해 관리하고자 하였으므로 기존의 ALB와는 분리하여 생성하였습니다.
이러한 챌린지를 성공적으로 완수하기 위해 Route53의 가중치 기반 라우팅 기능을 활용하여 ECS에서 EKS로 성공적으로 무중단 마이그레이션을 진행할 수 있었습니다.
Learning
구성원들의 성장에 대한 동기화
단순히 '나' 혼자만의 성장을 위한 노력이 아닌 '팀'의 성장을 위한 고민할 수 있게 시야를 넓힐 수 있는 계기가 되었습니다.
EKS 도입 시 가장 어려웠던 점으로 쿠버네티스의 높은 러닝 커브로 인해 팀 구성원들이 동시에 새로운 기술에 대해 이해하는 것이 힘들었습니다.
다양한 개념과 용어, 복잡한 아키텍처로 구성된 쿠버네티스는 초기에는 이를 이해하고 숙지하는 데에 시간이 많이 소요되었습니다. 이로 인해 팀원과의 기술적 협업과 소통에 어려움을 겪기도 하였습니다.
정말 감사하게도 각자 문제를 해결하기 위해서 아주 적극적으로 기술문서를 정리하여 서로 정리한 내용을 공유하고, 기술 세션을 통해서 Over-Communication에 가까울 정도로 서로 공유를 위해서 노력하였습니다.
이러한 노력으로 인해서 성공적으로 EKS 마이그레이션을 완수 할 수 있었습니다.
✅ CI/CD 파이프라인
CI/CD 파이프라인을 효율적으로 개선하고 확장함으로서 소프트웨어 전달 속도를 높이고 품질을 향상시키기 위해 프로젝트를 진행하였습니다.
Plan
레거시 환경은 단일 마스터를 통해 소스코드가 빌드 배포되고 있었습니다.
단일 마스터의 병렬 빌드 수행으로 인해 메모리 부족으로 성능 저하가 발생하여 빌드의 속도가 현저히 느려지기도 하였으며 주기적으로 API를 콜하는 Batch Job들이 정상적으로 수행되지 못하는 현상이 자주 발생하였습니다.
Jenkins에서 단순 Job으로 이루어진 프로젝트를 최신화하고 자동화된 테스트 및 배포 프로세스를 구축하여 개발 및 운영의 효율성을 극대화 할 수 있도록 계획하였습니다.
기존 젠킨스 구성 방식의 문제점
- 젠킨스 단일 노드로 구성 (only master)
- 단일 마스터에서 여러개의 병렬 잡을 수행할 수 있도록 설정
빌드시 많은 자원을 필요로하는 작업이 병렬로 실행되면 리소스 부족으로 인해 성능 저하가 발생
- 파이프라인으로 구성되어 있지않고 젠킨스 인스턴스 내부에 쉘스크립트(deploy.sh)를 실행하여 배포
Project Experiences
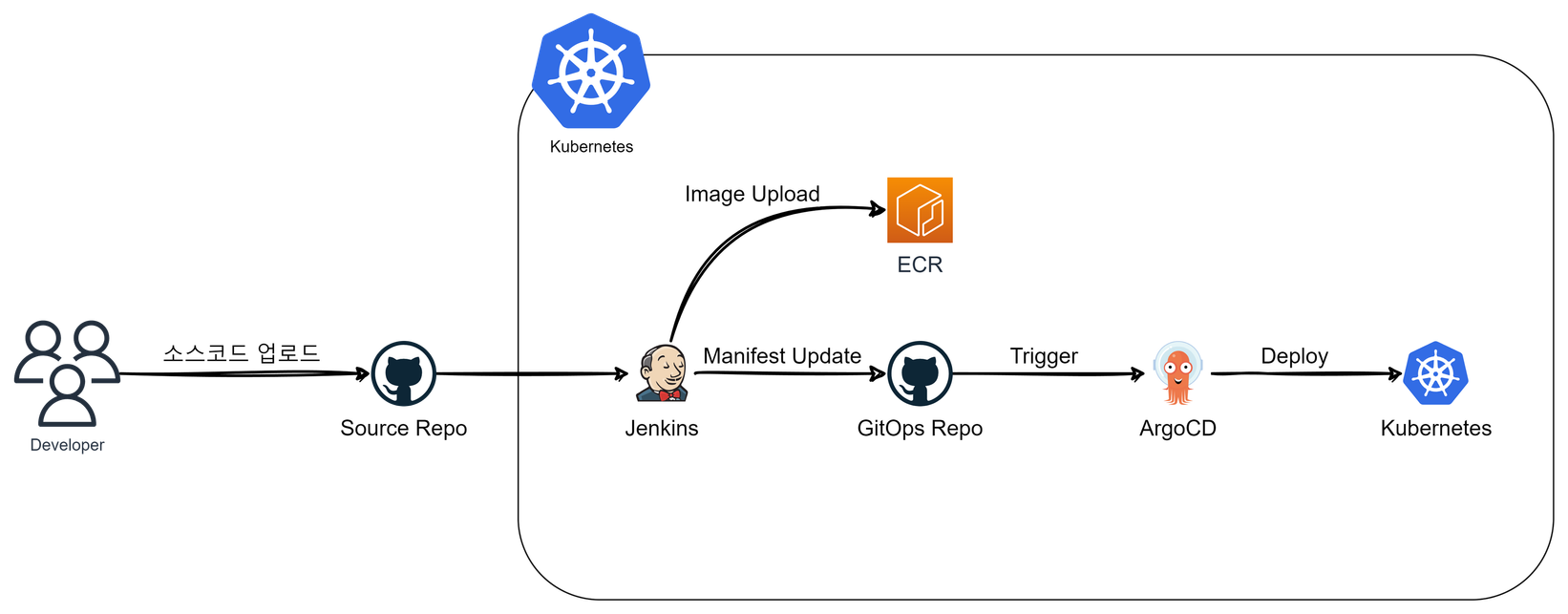
단일 Jenkins 구조 개선 - link
빌드를 위한
Jenkins Agent Node를 생성하고 젠킨스 마스터에서 연결합니다.이 구조를 통해 마스터에서 직접 Job을 수행하지 않게 되므로 CI/CD 수행에 대한 병목현상을 제거 할 수 있었습니다.
추가적으로 용도에 맞는 에이전트를 사용할 수 있으므로 확장성이 용이해지는 결과를 도출할 수 있습니다.

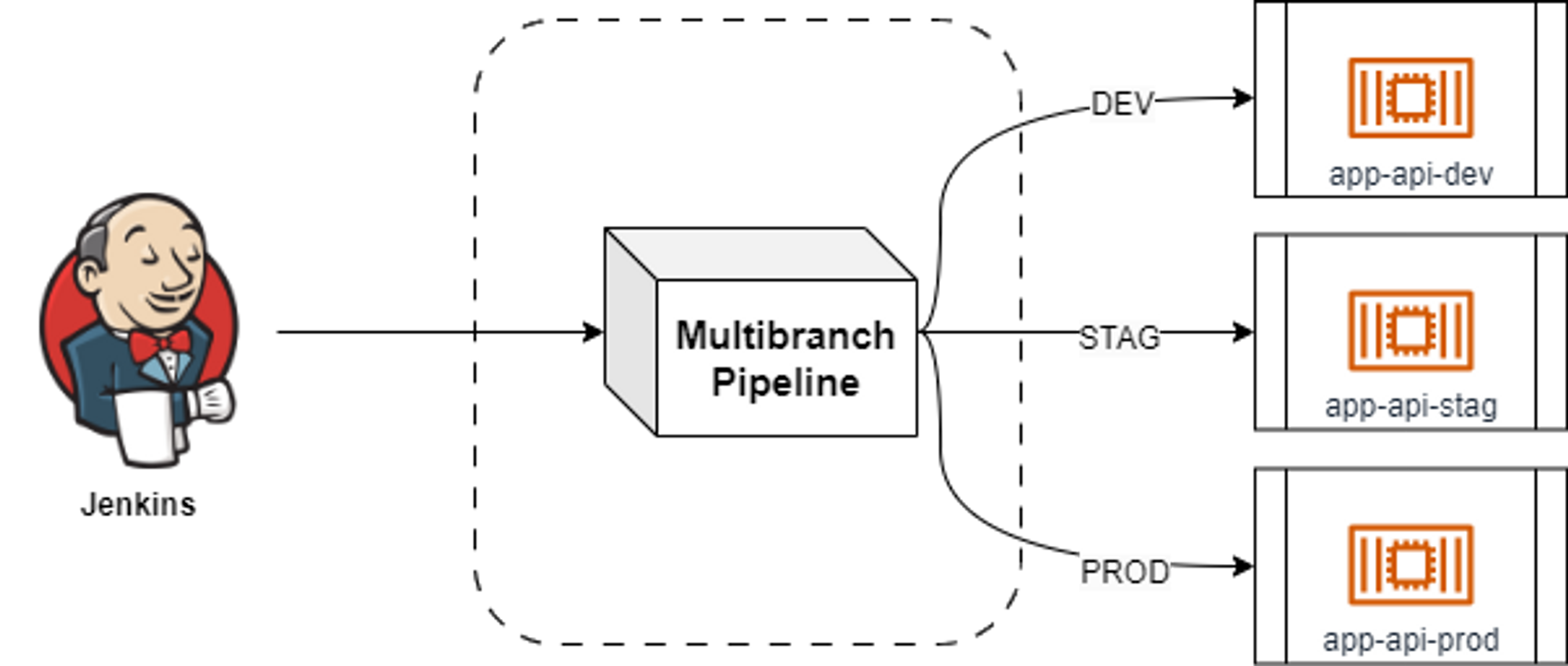
스크립트 형식의 Job 프로젝트를 Multibranch Pipeline으로 고도화 - link
Job 방식으로 구성된 젠킨스 Item을 Multibranch Pipeline로 마이그레이션하여 관리 오버헤드를 줄이고 일관성 있는 파이프라인을 제공할 수 있게 되었습니다.
Issues and Challenges
스크립트 형식의 Job 프로젝트를 Multibranch Pipeline으로 고도화
단순 Job으로 구성되어 배포 스크립트를 수행하는 레거시에서 Multibranch Pipeline을 도입하기까지 단계별로 적용해나가며 프로젝트를 개선하였습니다.
-
Job으로 구성된 스크립트 구조 파악
Job으로 구성된 쉘스크립트 실행하는 것의 문제로는 프로젝트 생성에 따라서 환경 변수를 하나하나 젠킨스 마스터 내부로 접근하여 변경해주고 있었습니다.
이로인해 동일한 파이프라인 동작이라고 할 지라도, 관리자의 휴먼에러로 인해 빈번하게 보수작업을 해야하는 문제가 발생했습니다.
Git Clone, 빌드, 배포 등 각각의 과정에 따른 진행시간, 성공 유무를 파악하기 힘든 단점도 있었습니다.

Job으로 배포되는 구성을 파악하여 각각의 스텝으로 분리할 수 있도록 구조를 파악하였습니다.
-
Pipeline item로 마이그레이션
위 단계에서 분리된 스텝을 파이프라인 item으로 마이그레이션 진행하였습니다.
기존의 환경변수를 수동으로 작업해야 하는 문제를 개선하기 위해서 환경변수를 별도로 분리하여 주입할 수 있도록 개선하였습니다.
각각의 스텝에 따라 진행 시간, 성공 유무를 파악할 수 있게 되었습니다.

하지만 여전히 브랜치 별로 프로젝트를 생성해야 하는 문제점을 가지고 있었습니다.
-
Multibranch Pipeline
최종적으로 Github Repo에서 배포에 필요한 Branch만 선별하고 하나의 파이프라인 프로젝트로 서비스를 배포할 수 있게 되었습니다.
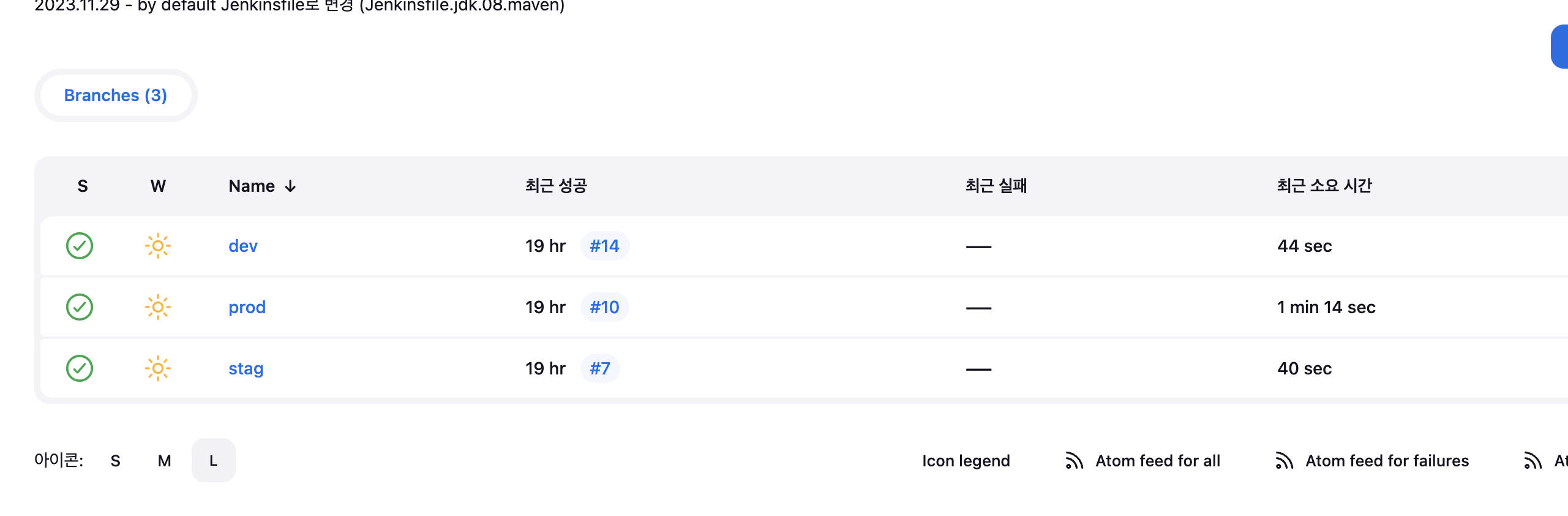
해당 작업을 기점으로 더이상 젠킨스 마스터 및 에이전트에서 관리자가 수동으로 조작해야 하는 작업이 사라져 파이프라인에 대한 관리 의존성이 사라지는 계기가 되었습니다.
Learning
Jenkinsfile 중앙 집중 관리 방식 적용
Multibranch Pipeline으로 마이그레이션을 진행하며 ci/cd를 수행하기 위한 스크립트 관리에 대해서 고민하였습니다.
최종적으로는 case 02. 젠킨스에서 Jenkinsfile 관리하는 방안을 선택하였습니다.
case 01. 프로젝트 소스코드 내부에서 Jenkinsfile 관리
Github Action에서 설정하는 것과 동일하게 소스코드 별로 프로젝트를 관리하는 방식입니다.
처음 Multibranch Pipeline로 마이그레이션 할때는 개별적으로 Jenkinsfile를 구성하고자 하였습니다.
이러한 구성으로 얻을 수 있는 장점은
-
서비스마다 커스텀 가능
-
각각의 스크립트가 소스코드에 종속되므로 Git으로 버저닝 관리
모든 프로젝트(서비스)에
.deploy/Jenkinsfile을 배포하였습니다.20여개가 넘는 백엔드 서비스가
Java Spring boot로 구성된 프로젝트이며 동일한 버전과 빌드 구성을 사용하고 있으므로 프로젝트별 의존성을 반드시 분리해야 하는 상황은 아니었습니다.파이프라인 구성이 변경되는 경우 모든 프로젝트에 배포하는 작업이 훨씬 고통스럽게 다가왔습니다.
case 02. 젠킨스에서 Jenkinsfile 관리
앞서 동일한 구성의 배포 스크립트를 사용할 수 있는 환경이므로 젠킨스 Managed files에서 선언한 groovy script를 통해 하나의 스크립트로 여러 프로젝트에 적용하여 사용할 수 있습니다.
개별적으로 관리하는 것에 대한 장점보다 관리 인력이 적은 현재 상황에서 해당 방법이 지금의 조직에 더 적합하다고 판단하였습니다.
✅ 인프라 구조 개선
클라우드 네이티브 기술과 서비스를 통한 최신화된 인프라 구조 도입을 통해, 레거시 시스템을 클라우드에 최적화하고 효율성과 확장성을 극대화하는데 중점을 두고자 하였습니다.
Plan
ECS 클러스터 통합
첫 입사후 마주하게된 인프라 구조를 보며 클라우드에 구축은 되어 있지만, 클라우드 네이티브하게 사용하지 못하고 있었습니다.
매번 프로젝트 또는 api 서버가 하나 증설 될때 마다 한땀한땀 관리자가 수동으로 생성하였습니다.
생성하고, 세팅하고, 환경별 설정하는 과정에서 분할된 클러스터로 인해 휴먼에러, 관리 오버헤드 증가 등 다양한 문제를 겪었습니다.
Project Experiences
기존 ECS에서 1 클러스터에 1 서비스로 배포/운영되고 있었던 ECS fargate 구조를 환경별 클러스터에서 통합 관리하는 작업을 진행하였습니다.
backend-api 서버 생성시
레거시(As-is)
(클러스터) dev-backend-api -> (서비스) dev-backend-api
(클러스터) stag-backend-api -> (서비스) stag-backend-api
(클러스터) prod-backend-api -> (서비스) prod-backend-api변경(To-be)
(클러스터) dev -> (서비스) backend-api
(클러스터) stag -> (서비스) backend-api
(클러스터) prod -> (서비스) backend-api
60개의 클러스터에서 3개의 클러스터로 운영 오버헤드를 축소 할 수 있게 되었습니다.
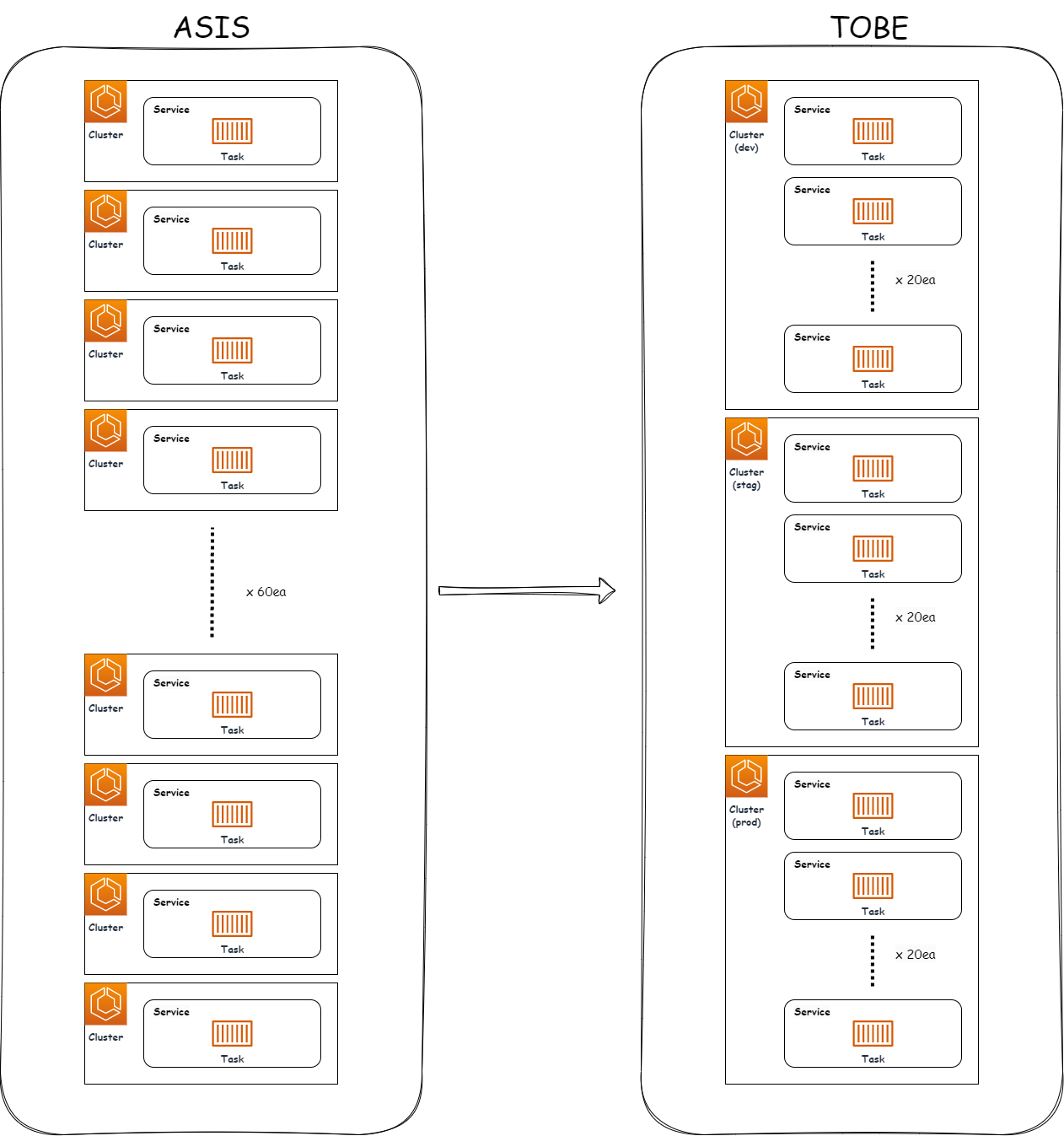
Issues and Challenges
클러스터를 3개로 축소한 이유?
프로젝트를 진행하며, 클러스터링에 대한 고민을 많이 하게 되었습니다.
불필요한 구조를 개선하기 위해 또다른 불필요한 구조를 만드는것이 아닐까?
실제로 서비스/도메인 단위로 묶는 계획 또한 생각했었지만, 현재 관리중인 서버의 구성은 서비스/도메인에 대한 구분으로 나누기가 애매하였습니다.
하나의 기능을 담당하는 서버가 전체 서비스에 걸쳐 업무를 관장하도록 구성되어 있습니다.
따라서 도메인별 클러스터링을 구축하는것이 아닌, 이를 하나의 통합된 클러스터로 분류하여 개발 환경 단위로 분리하는 결과를 도출하였습니다.
Blue-Green 배포를 통한 ECS 무중단 마이그레이션
클러스터당 만들어져 있는 서비스는 24/7 중단없이 운영되어야 하므로 새로운 구조를 적용하고자 할때 중단없이 마이그레이션을 할 수 없을까?에 대해서 고민하였습니다.
마이그레이션을 위해 ALB(Application Load Balancer)를 활용하여 Blue-Green 배포를 진행했습니다.
이를 통해 기존 클러스터(Blue)와 새로 구성한 클러스터(Green)를 병렬로 운영하면서 서비스의 지속적인 가용성을 보장하고, 필요 시 트래픽을 새 클러스터로 전환할 수 있게 되었습니다.
Learning
단순히 클러스터 운영의 오버헤드를 줄이려는 노력은 있었지만, 기존 프로젝트에서는 개발(dev), 스테이징(stag), 프로덕션(prod)과 같은 환경별로 선언된 문자열 변경을 고려하지 않아 클러스터 통합에 어려움을 겪었습니다.
이 경험을 통해 인프라 관리에서의 규칙에 대한 중요성을 깨닫게 되었고 레거시를 적극적으로 개선하여 이후 EKS로의 마이그레이션을 원활하게 이끌어낼 수 있었습니다.
📌 Collaboration Experience
협업을 통해 느낀 점은 목표를 명확히 정의하고 팀원들과의 적극적인 의사 소통이 협업의 핵심이라는 것입니다.
프로젝트를 진행하면서, 우선적으로 동료들과 목표를 명확히 정의하고 의견을 나누는 데에 중점을 두었습니다.
특히, 서비스 마이그레이션 과정에서 발생할 수 있는 문제에 대한 사전 논의를 통해 한 방향을 향하도록 조율하였습니다.
마이그레이션 계획을 설명하고자 할 때는, 동료들에게 시각적인 자료와 함께 명확한 언어로 전달함으로써 목표지점을 명확하게 설정하고자 노력하였습니다.
특정 기술적인 어려움이 예상되는 부분에 대해서는 동료 간의 교육 세션(Tech-talk)을 통해 지식을 공유하고 함께 해결책을 모색했습니다.
최종적인 마이그레이션 단계에서는, Blue-Green 배포 방식을 도입하는데 있어 신속한 의사 소통이 필수적이었습니다.
이를 위해 정기적인 스탠드업 미팅과 이슈 트래킹을 통해 프로젝트 진행 상황을 투명하게 전달하며, 동료의 피드백을 적극 수렴하여 프로젝트의 품질을 높이는데 기여할수 있었습니다.
📌 Conclusion
이번 회고록을 통해 지난 한 해 동안의 성장과 도전, 그리고 지난 프로젝트 경험을 되돌아보았습니다.
아직도 많이 부족하지만 꾸준히 개선점을 파악하고 고도화 하며 기술을 통해 교육격차 뿌셔뿌셔!라는 공동의 목표에 한걸음 더 다가갈 수 있도록 더욱 노력해야겠습니다.
다가오는 1년은 AWS VPC 네트워크 분리, IaC 고도화, 그리고 EKS 클러스터의 분리와 관리에 주력할 예정입니다.

