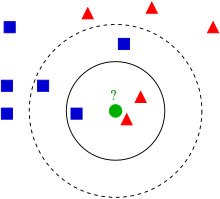
K-Nearest Neighborhood, KNN
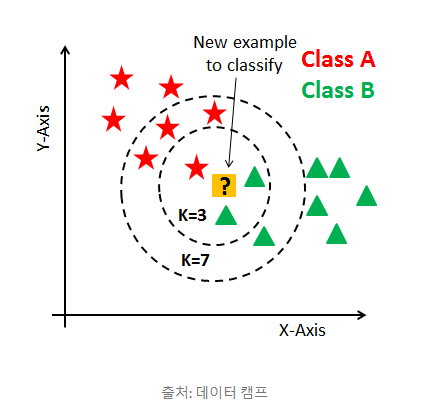
KNN 알고리즘은 분류알고리즘 중 가장 직관적인 알고리즘이다.
또한 KNN알고리즘은 전형적인 lazy learner(게으른 학습모델)이다.
Lazy Learner
- parameter를 학습하여 저장하는 모델(parametic model)과 달리 훈련세트 자체를 전부 저장하는 방식으로 작동하는 모델(non-parametic model)을 말한다.
- 학습과정에서 cost가 0이다.
KNN 알고리즘
- 이웃개수 K와 거리측정 기준을 선택(기본값은 유클리디안 거리)
- 분류하려는 샘플에서 K개의 인접 이웃 찾기
- 다수결 투표를 통해 클래스 할당
이때 적절한 K를 선택해야 과대/과소 적합을 피할 수 있다.
Minkowski Distance
p에 따라 어떤 거리측정 기준을 선택할지 결정할 수 있다.
ex) p=1 -> 맨하튼 거리, p=2 -> 유클리디안 거리(피타고라스 공식)
차원의 저주
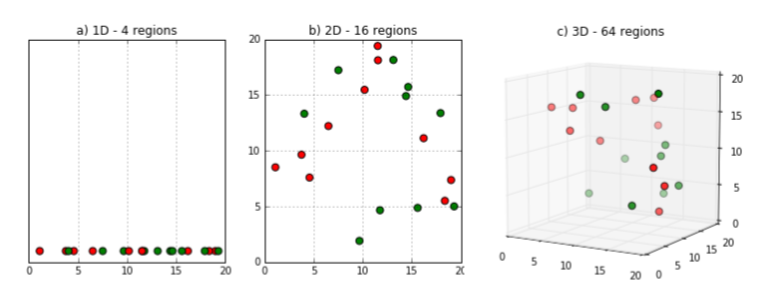
- 고정 크기의 훈련 데이터셋이 차원이 늘어남에 따라 특성 공간이 점점 희소해지는 현상
- 저차원에서는 가까운 거리에 있는 데이터라도 고차원에서는 거리가 꽤 거리가 멀 수 있다.
- 차원의 저주를 해결하기 위해 규제 방법을 사용한다.
- KNN은 차원에 저주에 취약한 알고리즘 중 하나이다. 때문에 차원 축소가 필요하다.
참고자료

AI 엔지니어 김태종입니다. 추천시스템, 이상탐지, LLM에 관심이 있습니다. 블로그에는 공부한 기술, 논문 혹은 개인적인 경험을 올리고 있습니다.