
기존 검색 트리(BST, RB Tree, B-Tree)에서는 코드를 식별하는 검색 키(Key)가 하나로 이루어져 있었다.
하지만 지도 상의 위치를 나타내는 좌표처럼 여러 속성을 복합적으로 다뤄야 하는 경우에는 일차원 검색트리를 사용할 수 없게된다.
이를 보완하기 위해 나온것이 다차원 검색트리이다.
다차원 검색트리는 KD-Tree, KDB-tree, R-tree, Grid File등이 있지만 KD-Tree만 설명해 볼 예정
KD-Tree
이진 검색 트리(BST)를 확장한 것으로, 개의 필드로 이루어진 키를 다룬다.
각 레벨(Level)마다 하나의 차원(필드)만을 번갈아 가며 분기 기준으로 사용한다.
특징
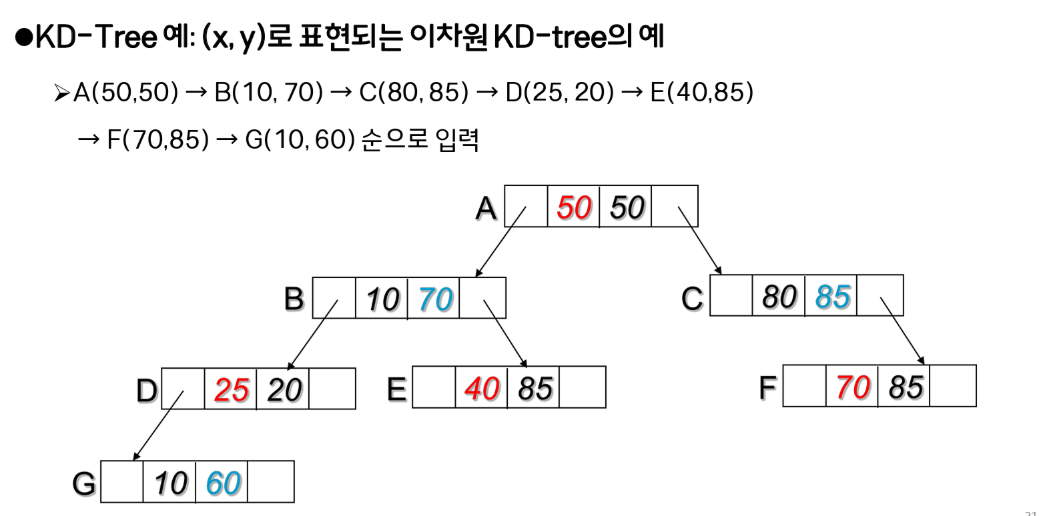
-
Root (Level 0): 첫 번째 필드(예: 축)만 사용하여 분기
-
Level 1: 두 번째 필드(예: 축)만 사용하여 분기
-
Level : 번째 필드를 사용하여 분기
너무 복잡하게 생각하지 말고 root에서 축을 기준으로 분기하고 그 다음엔 축으로 분기... 반복하는 것이다.
이는 검색을 수행하며 트리를 내려가는 과정은 다차원 공간에서 나누어진 영역을 따라 공간을 점점 좁혀 나가는 것과 같다.
삽입
삽입은 리프노드에 이루어지며, 기본적으로 이진 탐색 트리의 삽입 과정을 따르되, 비교하는 기준 축이 레벨마다 바뀐다는 부분만 주의하면 된다.
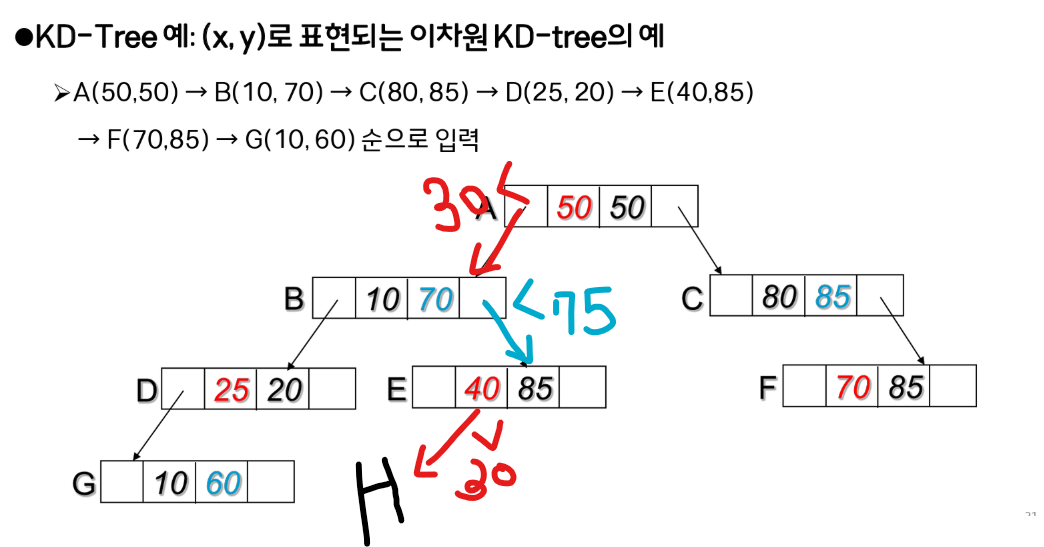
특징에서 다룬 KD-Tree에 H(30, 75)를 삽입한다고 가정하면 아래와 같이 된다.
삭제
삭제 또한 이진 트리의 삭제를 확장한 것이지만, 자식 노드 처리 시 트리의 성질을 유지하는 것이 중요하다
자식이 없는 경우 (Leaf Node)
해당 노드()를 단순히 제거
자식이 하나뿐인 경우
단순히 자식을 끌어올리면 레벨이 바뀌어 비교 축이 달라지므로 트리의 성질이 깨지게 된다.
따라서 자식이 둘인 경우와 동일한 방법으로 대체 노드를 찾아 처리한다.
자식이 둘인 경우
-
오른쪽 서브트리가 있다면: 삭제하려는 노드()의 현재 레벨 분기 기준(예: 축) 값이 가장 작은(Min) 노드를 오른쪽 서브트리에서 찾아 대체한다.
-
왼쪽 서브트리만 있다면: 반대로 분기 기준 값이 가장 큰(Max) 노드를 왼쪽 서브트리에서 찾아 대체한다.
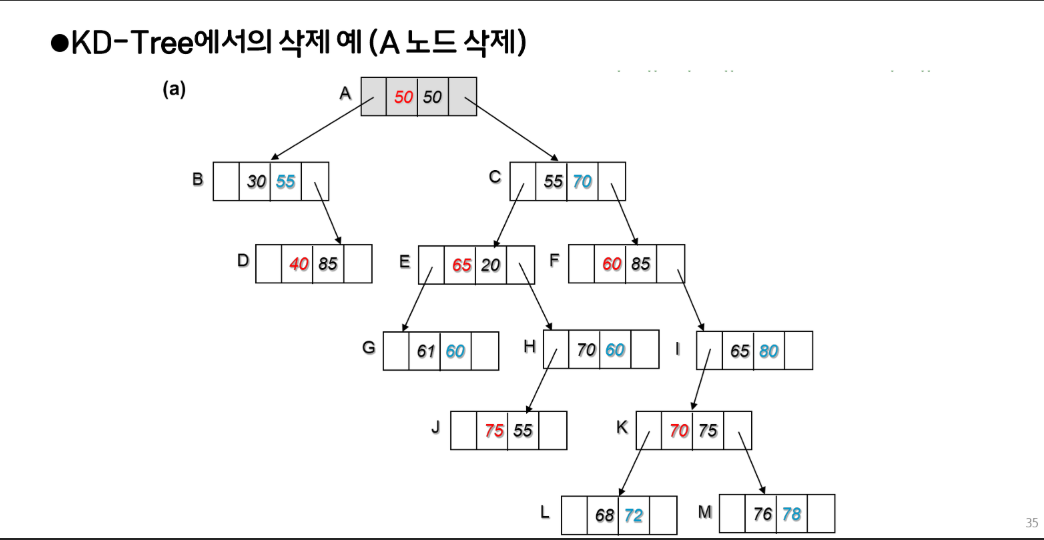
여기서 A노드가 삭제되면 자식이 둘인 경우에 오른쪽 서브트리가 있으므로, 오른쪽 서브트리에서 분기 기준 (50) 가장 작은 값을 찾는다.
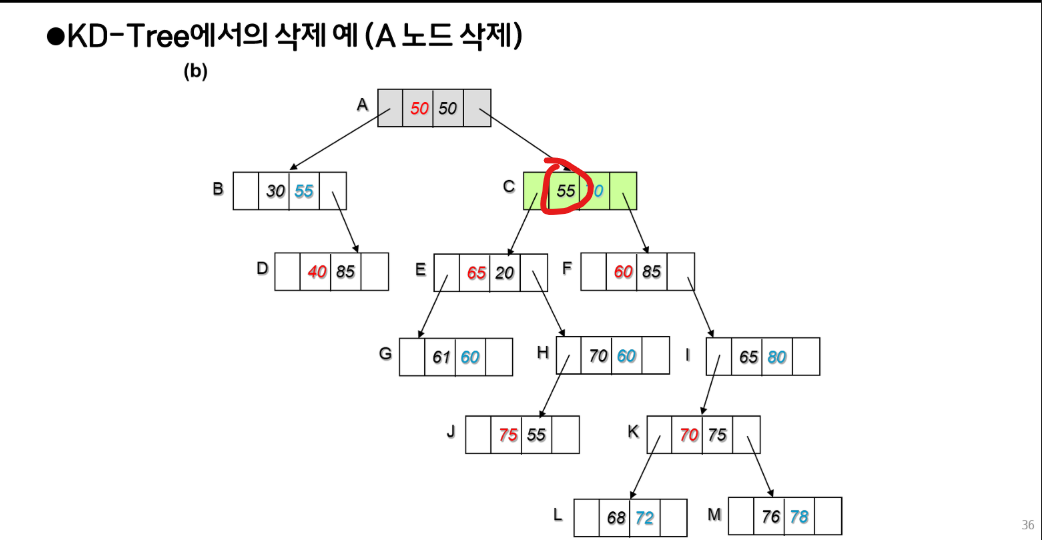
C가 55로 제일 작으니 A가 삭제되고 그 자리를 C로 올린다.
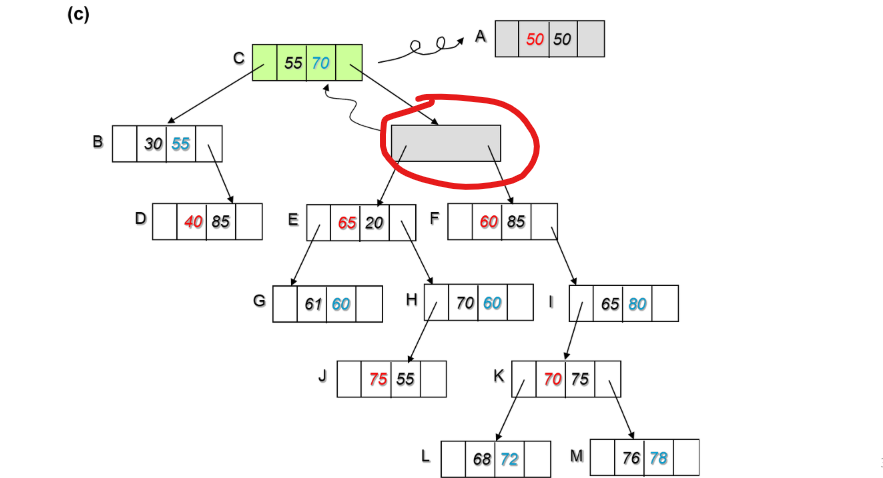
그런데 이러면 또 C가 있던자리가 비게 되어서 이를 재귀적으로 해결하면된다.
C는 자식이 둘인 경우이고, 오른쪽 서브트리가 있으므로 오른쪽 서브트리에서 찾으면된다.
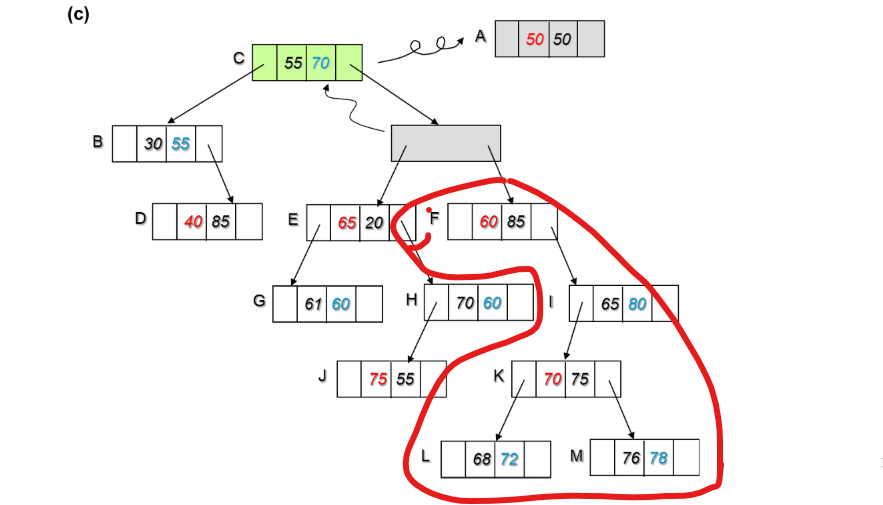
(얘네만 보면 된다.)
C에서 분기는 70이었으므로 위에서 체크한 부분에서 70에 가장 가까운 값은 L이 갖고있는 72이다.
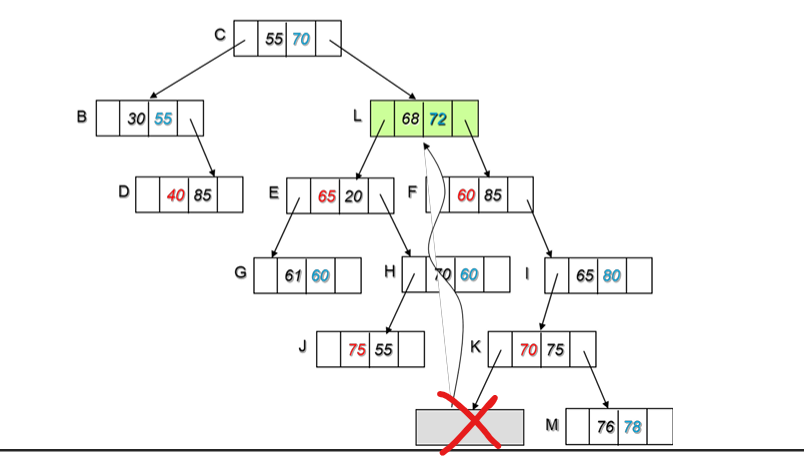
L은 리프노드 였으므로, 더 이상 해결한 문제가 없으므로 삭제 작업이 종료된다.
성능 분석
성능: KD-Tree는 이진 검색 트리의 확장이므로 데이터가 균형 잡혀 있다면 검색, 삽입, 삭제 연산은 평균적으로 의 시간이 소요된다.
활용 예
- 최근접 이웃 탐색 (Nearest Neighbor Search): 지도 앱에서 현재 위치와 가장 가까운 장소를 찾는 등의 문제에 사용할 수 있다.
https://www.quora.com/What-is-a-kd-tree-and-what-is-it-used-for
(위 링크에 또 다른 활용 예들이 있다.)
참고자료
https://haamjamie.tistory.com/31
https://www.geeksforgeeks.org/dsa/search-and-insertion-in-k-dimensional-tree/
Algorithm [#5-2 Search Tree(2)] 2025 FALL Chungbuk National University School of Computer Science Prof. Lee, Euijong
