
- 이번 Toy_project는 故 최동원 선수가 현재 KBO리그에서 활동한다면 얼마의 연봉을 받을 수 있을지 머신러닝을 통한 예측을 해보자
- 먼저, 故 최동원 선수의 투수로서 데이터를 추출하고, 최근 선수들의 기량 데이터와 비교 및 분석 후 최근 선수들의 연봉을 Label값으로 주고 교육시켜 회귀분석을 실시해보자
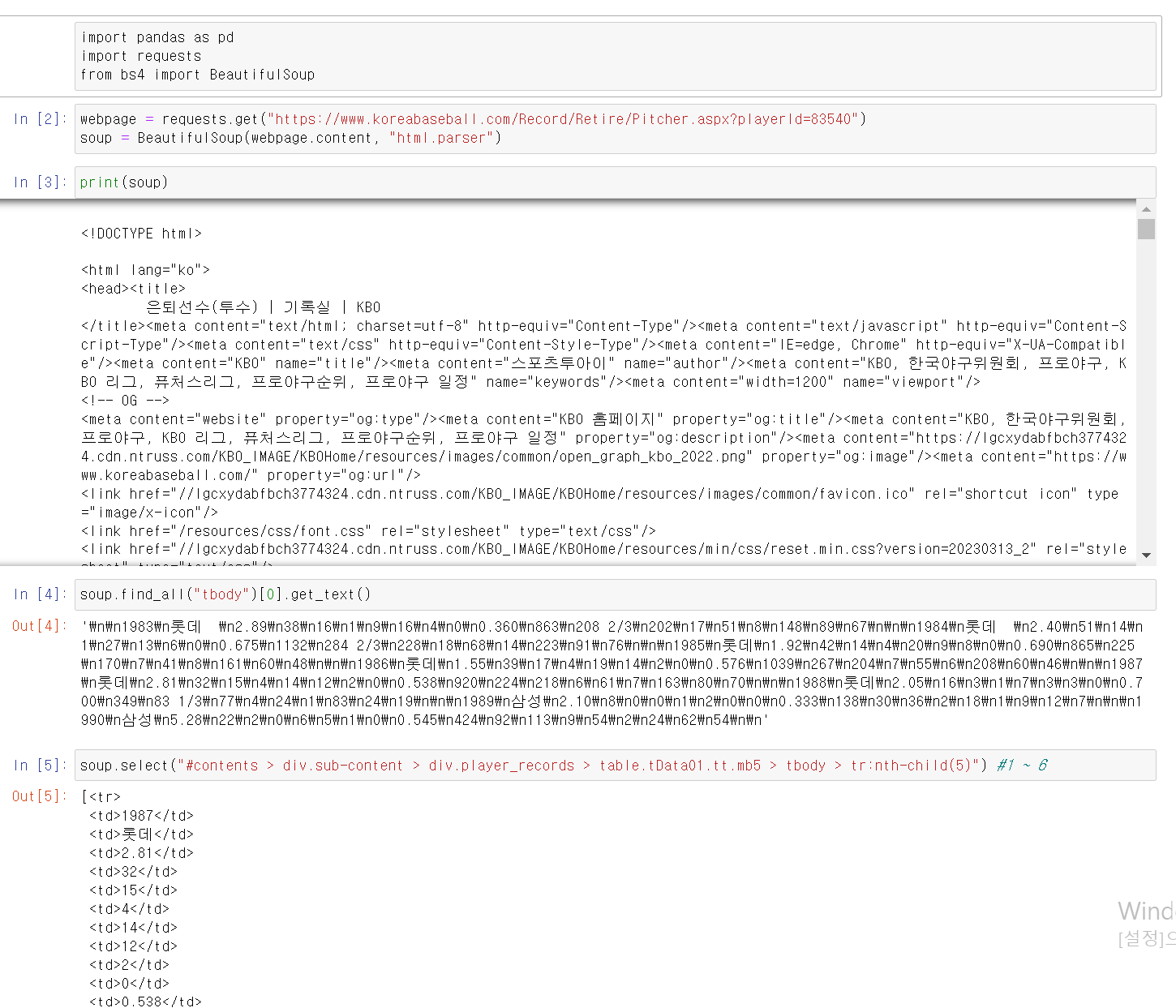
- 먼저 BeatifulSoup으로 데이터를 추출 후 html에서 body에 해당하는 부분을 text로 데이터를 추출했다.
- tr:nth-child(n) 부분에서 1~6까지 숫자를 넣어서 1983~1988년까지 최동원 선수의 데이터를 추출할 수 있는 것을 확인했다.
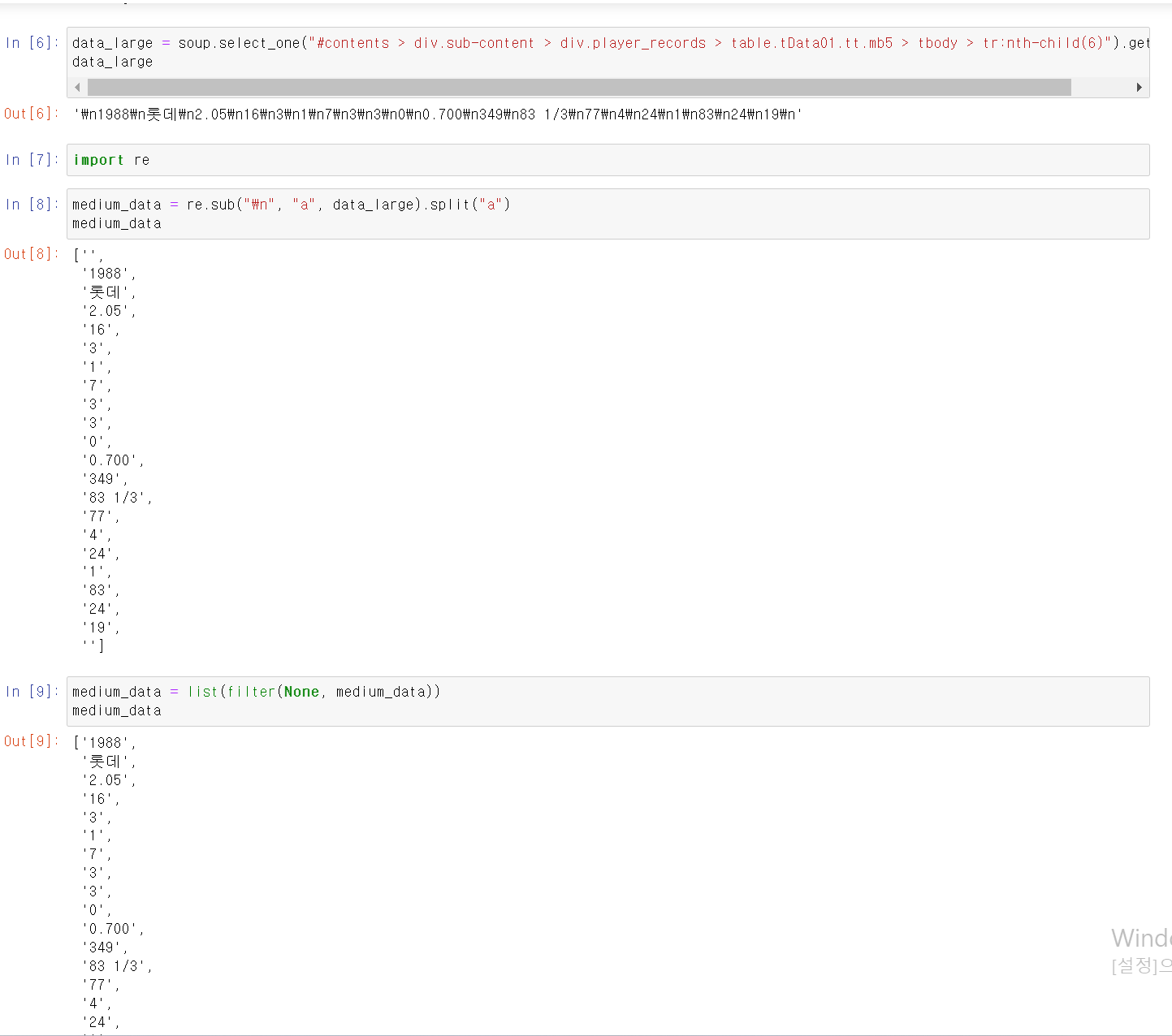
- text추출 시 \n html문자가 같이 추출되서, re모듈을 통해 a로 변환 후 a를 기준으로 split해서 필요한 데이터만 리스트 형태로 추출했다.
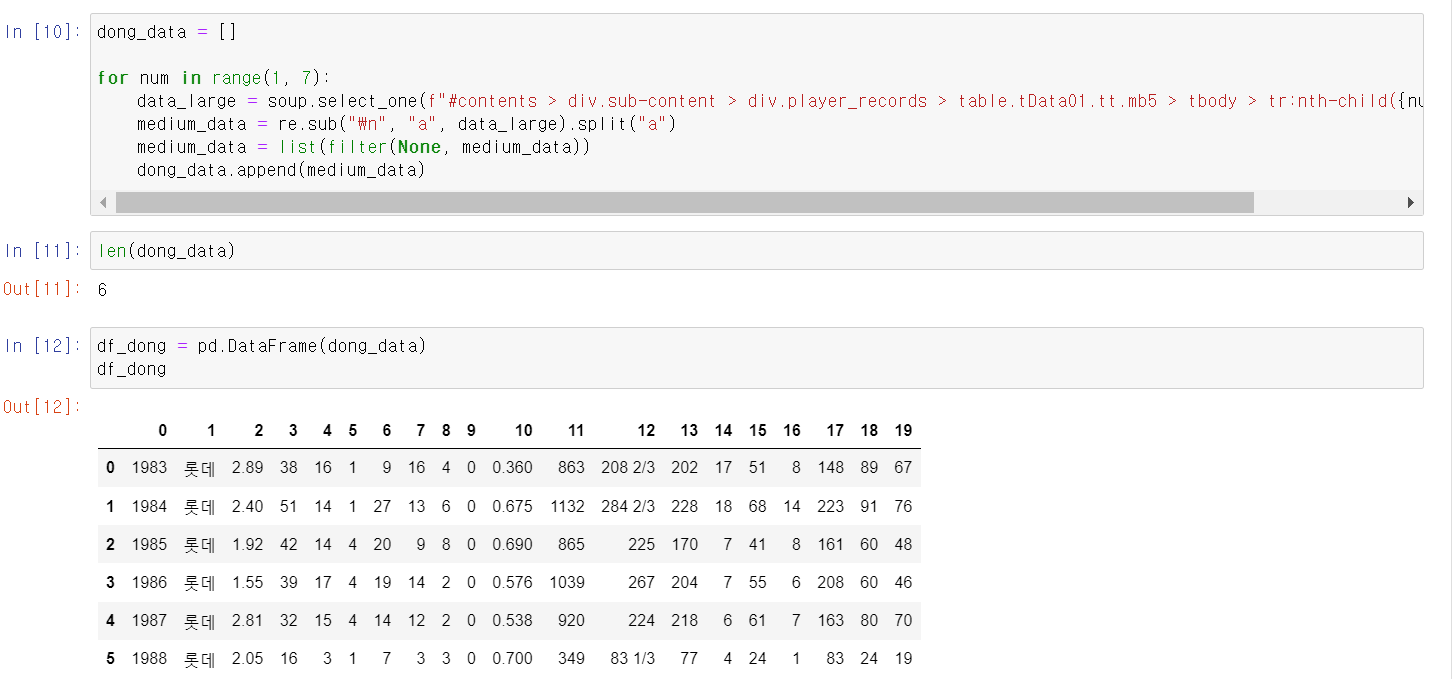
- 이제 for문을 통해 위에 작업을 1~6번 즉 1983~1988년 데이터를 쭉 뽑고 Dataframe을 df_dong에 저장했다.
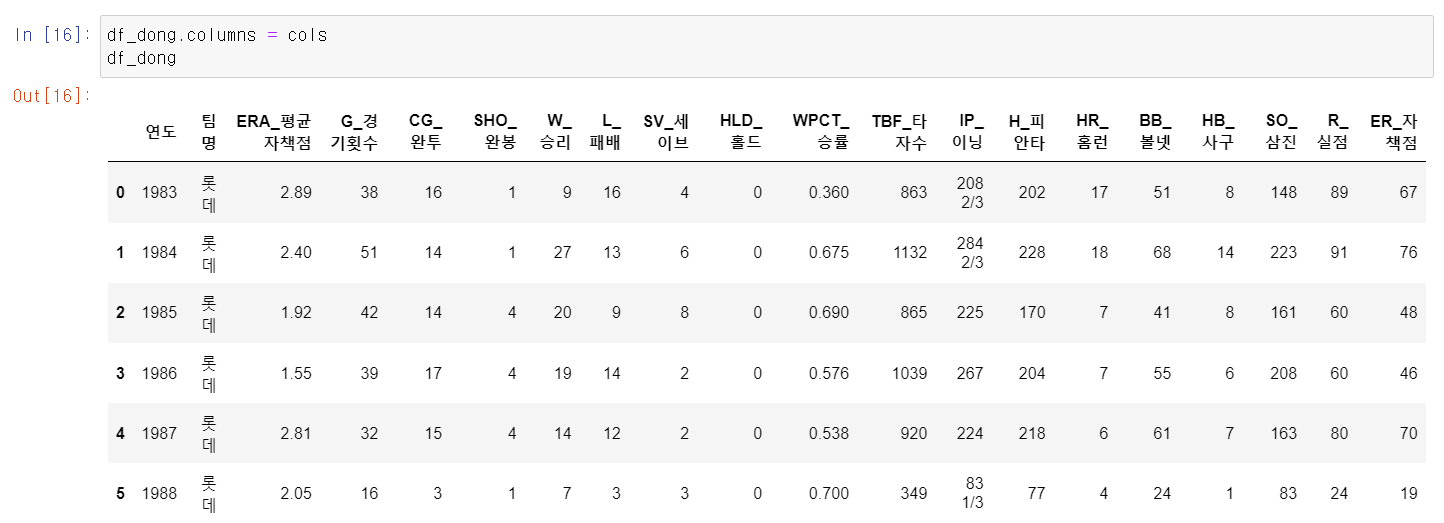
- 그리고 저장한 cols 변수로 프레임의 컬럼값을 바꿨다.
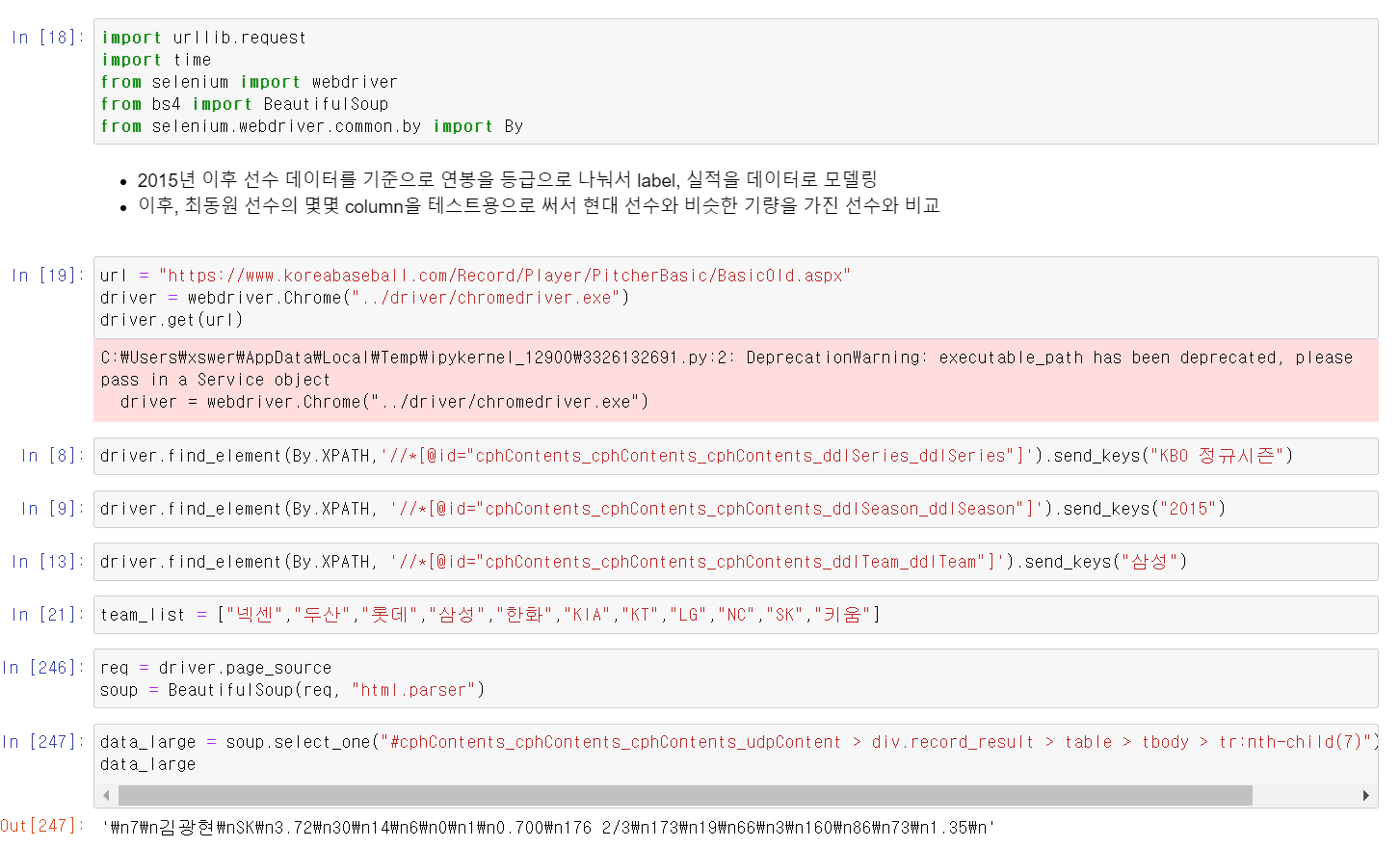
- 이제 2015~2020년 사이 선수들의 데이터를 추출하는 과정을 확인했다.
- 최근 선수들의 데이터를 뽑는 url의 경우 연도, 시즌, 팀이름 등 url 작업이 필요해서 selenium 모듈을 사용했다.
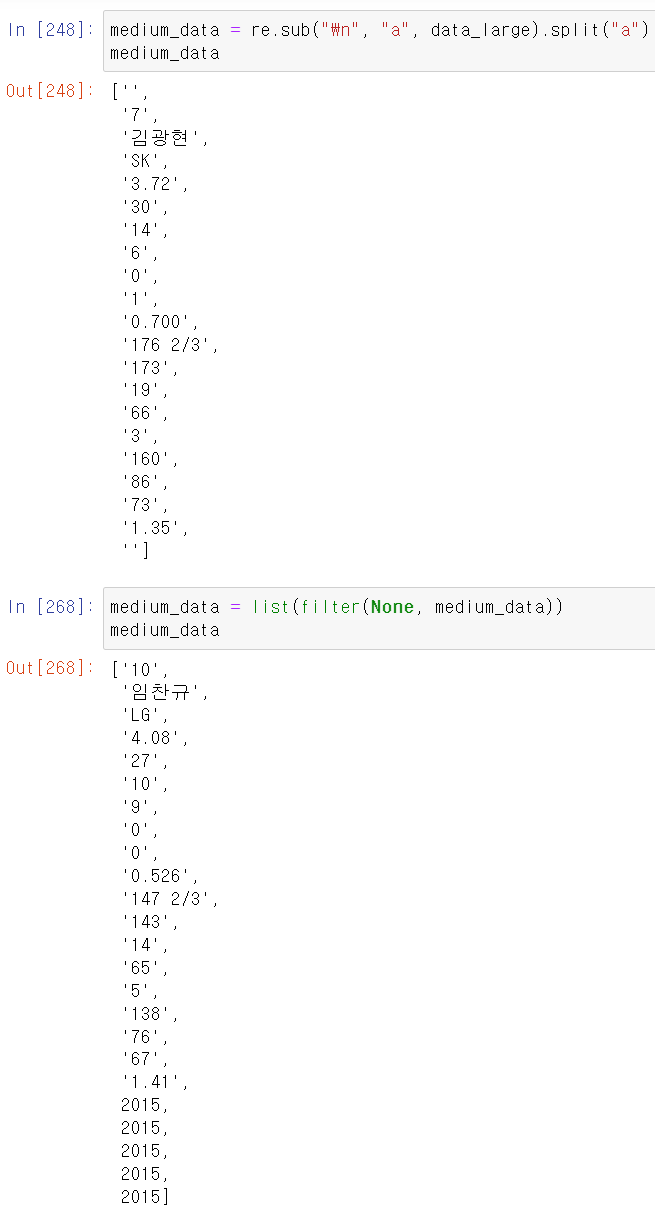
- 뽑은 데이터를 최동원 선수의 데이터 뽑을 떄 과정과 같이 re모듈과 빈값을 채우고,

- 연도, 팀이름, 각 선수들 데이터 번호를 3개의 for으로 돌리고, 중간에 오류가 발생할 경우를 방지해서 try, except 기능을 사용했다.
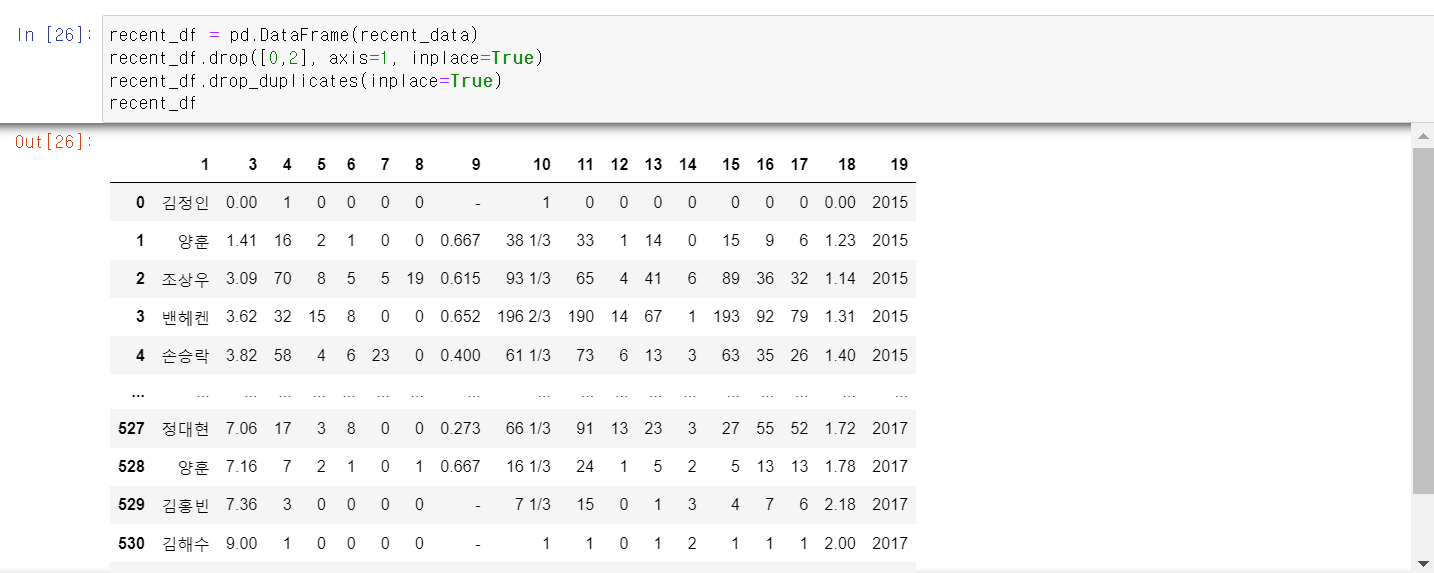
- 이제 뽑은 데이터에서 필요없는 컬럼은 drop하고, 중복값을 제거한 후 데이터가 정상적으로 추출된 것을 확인했다.
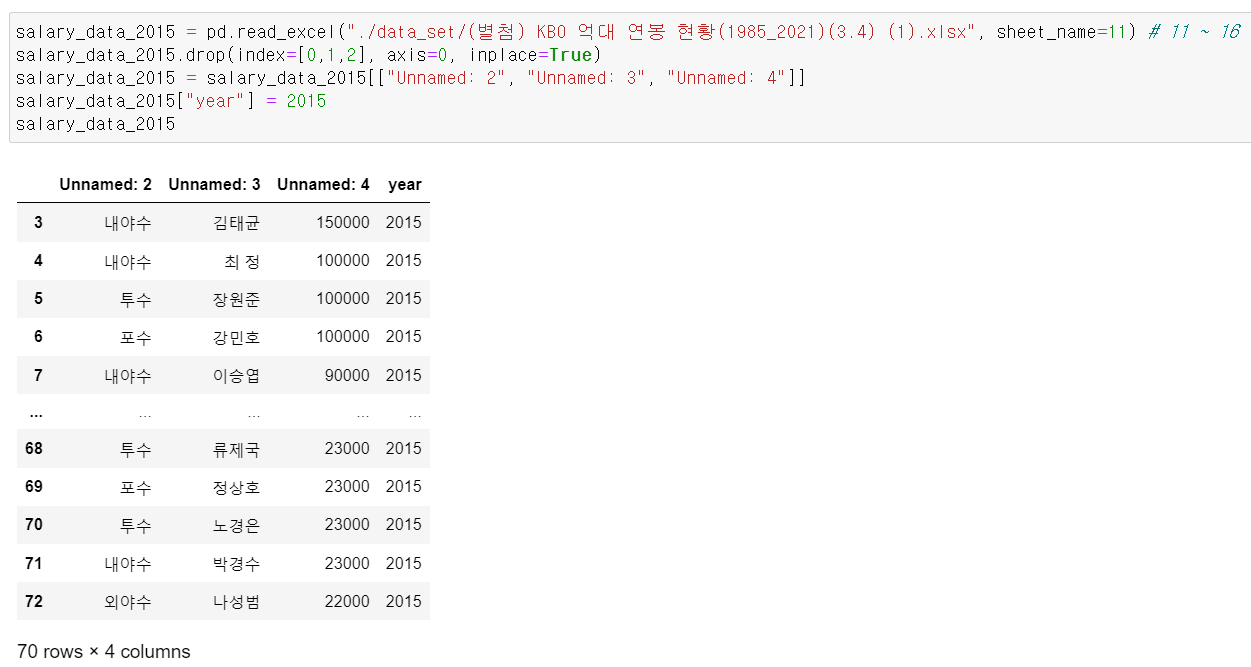
- 이후 선수들의 연봉에 대한 데이터를 엑셀로 다운 후 엑셀 파일은 read_excel로 다운받는데, 해당 파일에 각 연도별로 시트가 나눠져 있어서 6개의 데이터 프레임을 만들고,
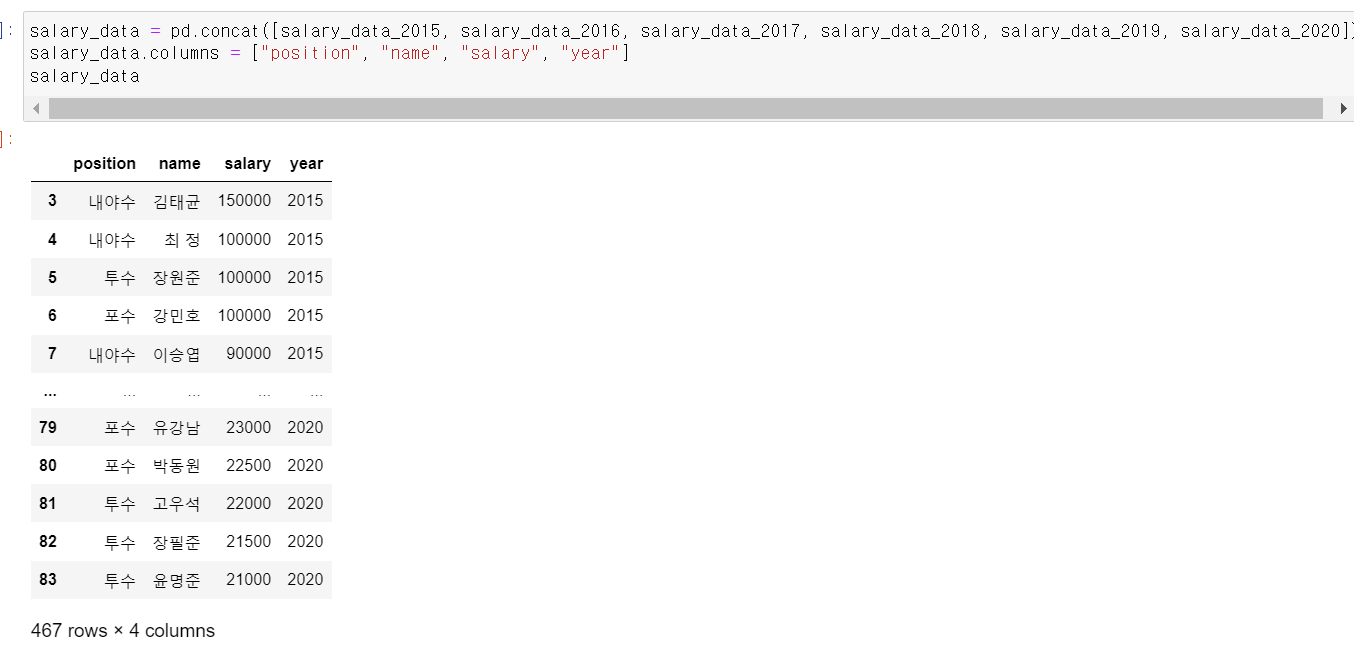
- 2015~2020년 데이터를 하나의 프레임으로 concat했다.

- 이후 sqlalchemy 모듈의 engine기능을 사용해서 엔진 객체를 만든 후 연봉 데이터를 sql에 보내고
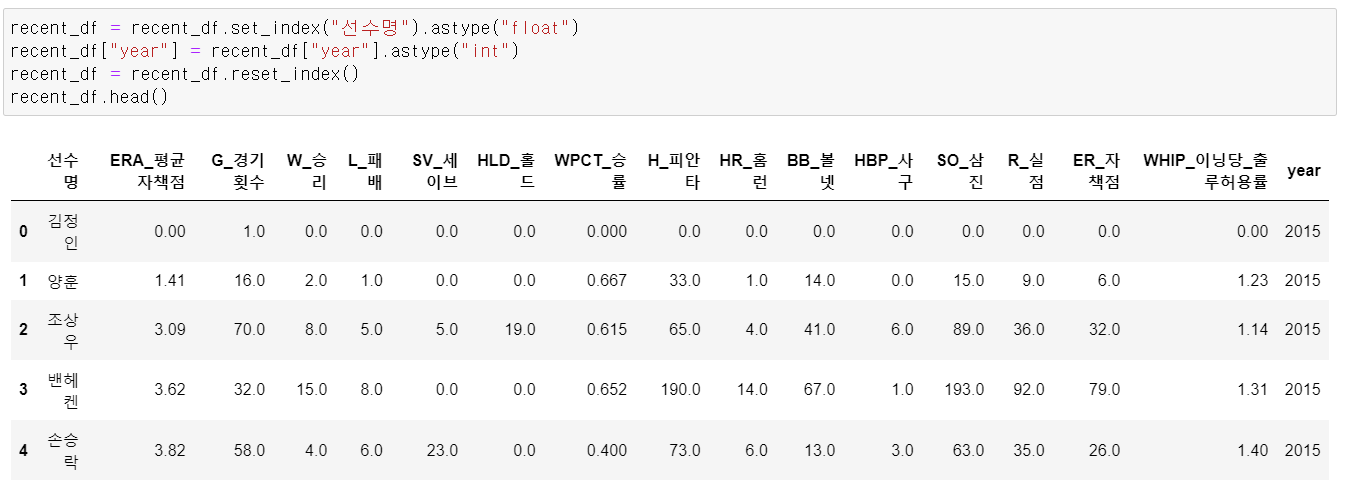
- 선수 데이터의 형태를 sql에 맞는 타입으로 변환하고,

- 선수들의 데이터도 sql에 보냈다.
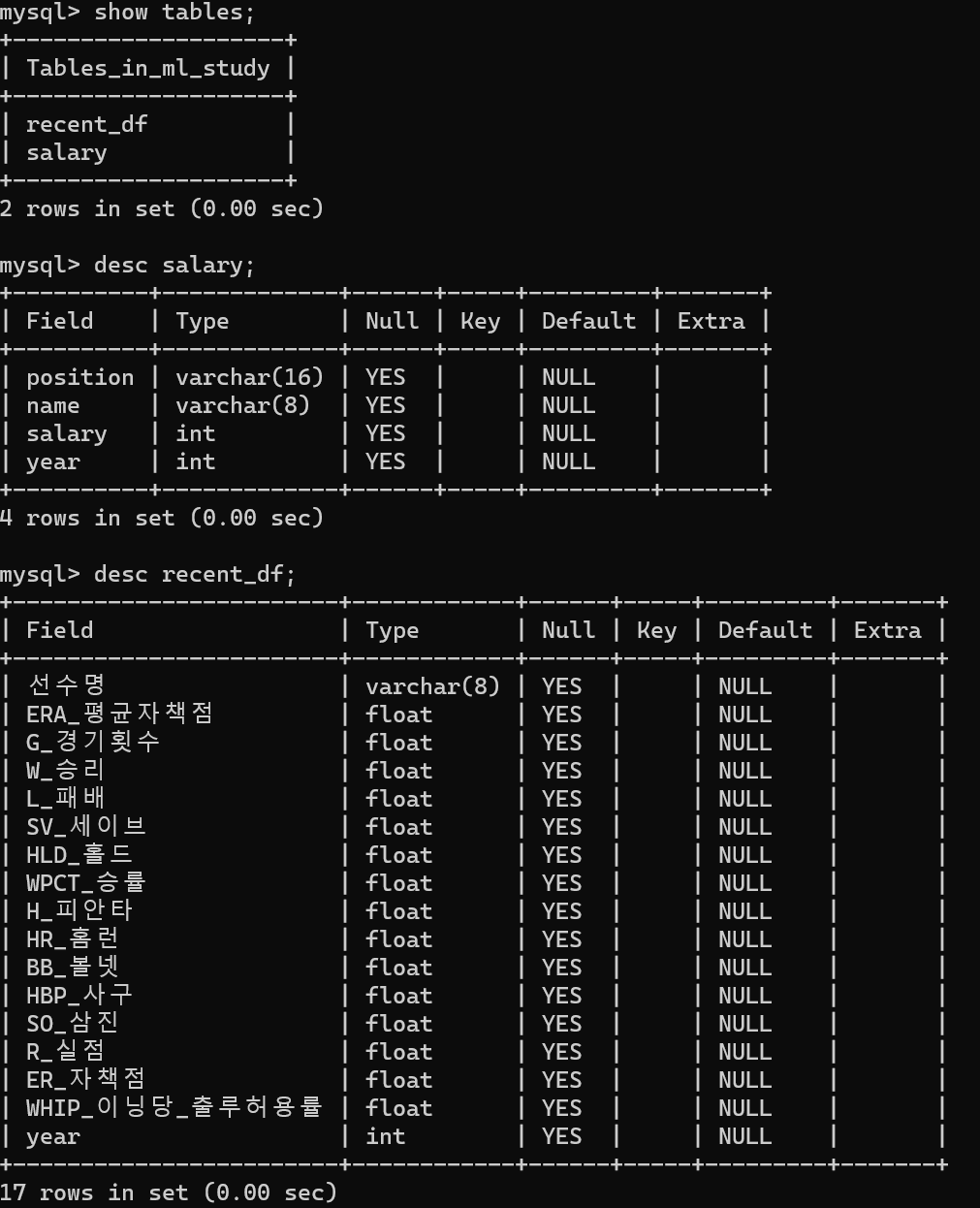
- sql데이터 확인 결과 정상적으로 테이블이 존재한다.
- 이제 mysql.connector를 이용해서 sql에 저장된 데이터를
select r.*, s.salary from recent_df r, salary s
where r.선수명 = s.name and r.year = s.year- sql 문법으로 연도와 이름이 같을 경우 선수 데이터 전체와 연봉을 합쳐서 새로운 player_salary_df를 sql에서 jupyter notebook에 데이터프레임 형태로 저장했다.
- 저장한 데이터 프레임에 컬럼값을 주고

- 해당 데이터프레임에서 salary에 영향을 주는 column을 주기 위해서 먼저 해당 데이터에서 최동원 선수 데이터프레임의 컬럼과 같은 컬럼을 뽑고
- 연봉을 내림차순 기준으로 데이터를 확인했다.

- 그리고 연봉에 대한 상관계수를 확인 결과 승리, 피안타, 삼진 3개의 컬럼이 높은 상관계수를 보여주는 것을 확인했다.
- 이제 본격적인 머신러닝 작업 이전에 먼저 최동원 선수의 데이터 컬럼의 이름을 바꿔줬다.
- 머신러닝을 하기 위해 모듈을 설치하고, x변수에는 라벨값(salary)을 제외한 데이터를, y에는 label값을 줬다.
- 그리고 train_split으로 데이터를 8:2로 나눠주고, OLS(Ordinary Least Squares)기법을 사용하기 위해 statsmodels.api 모듈을 sm으로 저장했다.
- 이제 OLS를 확인하기 전에 x_train데이터 값이 필요하기 때문에 으로 1를 주고 y_train데이터와 x_train데이터를 교육시켰다.
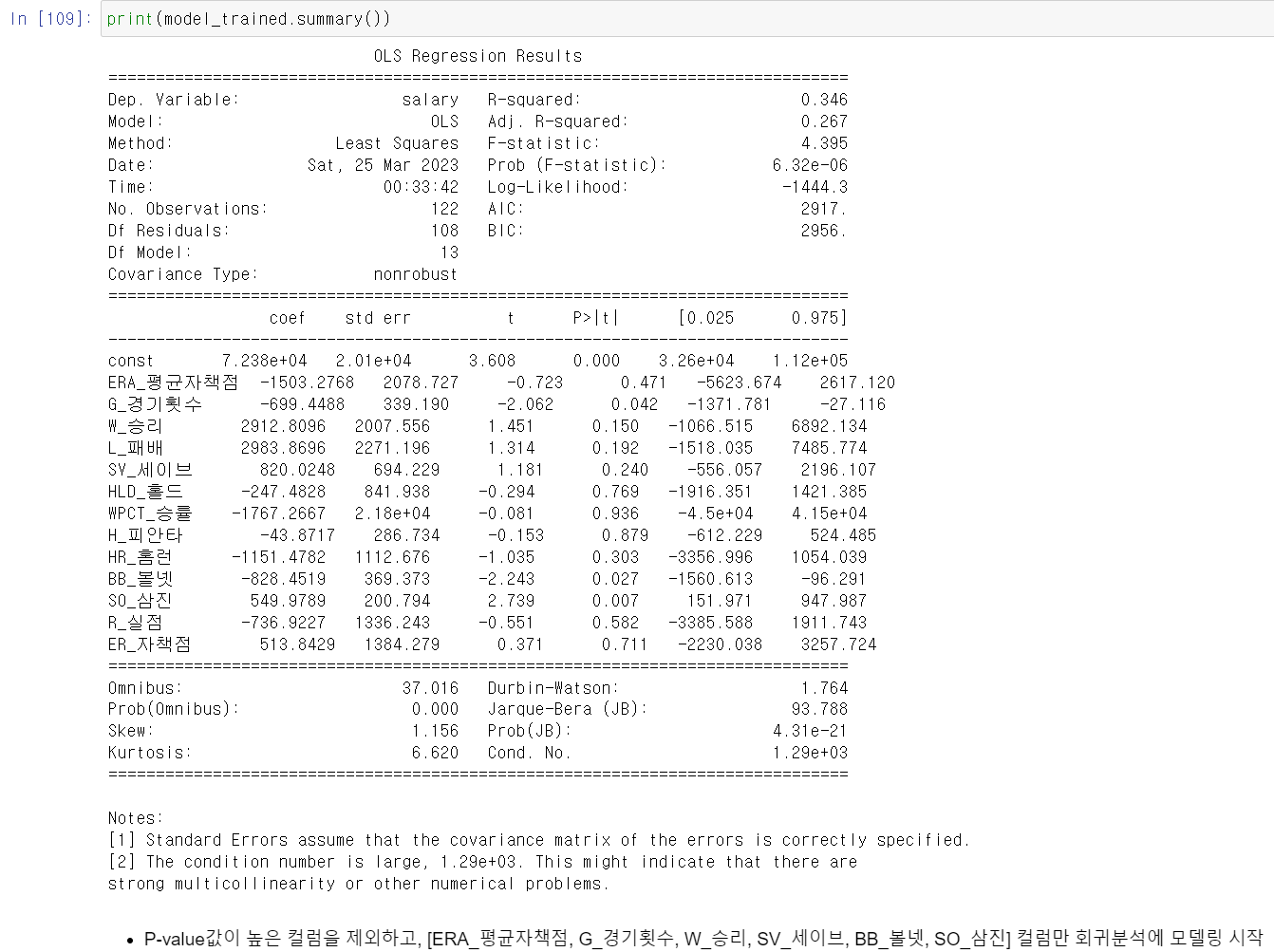
- 모델 결과를 확인하니 p-value값이 높은 몇몇의 컬럼은 변수로서 설명력이 부족하기 때문에 p-value값이 낮은 컬럼을 확인했다.
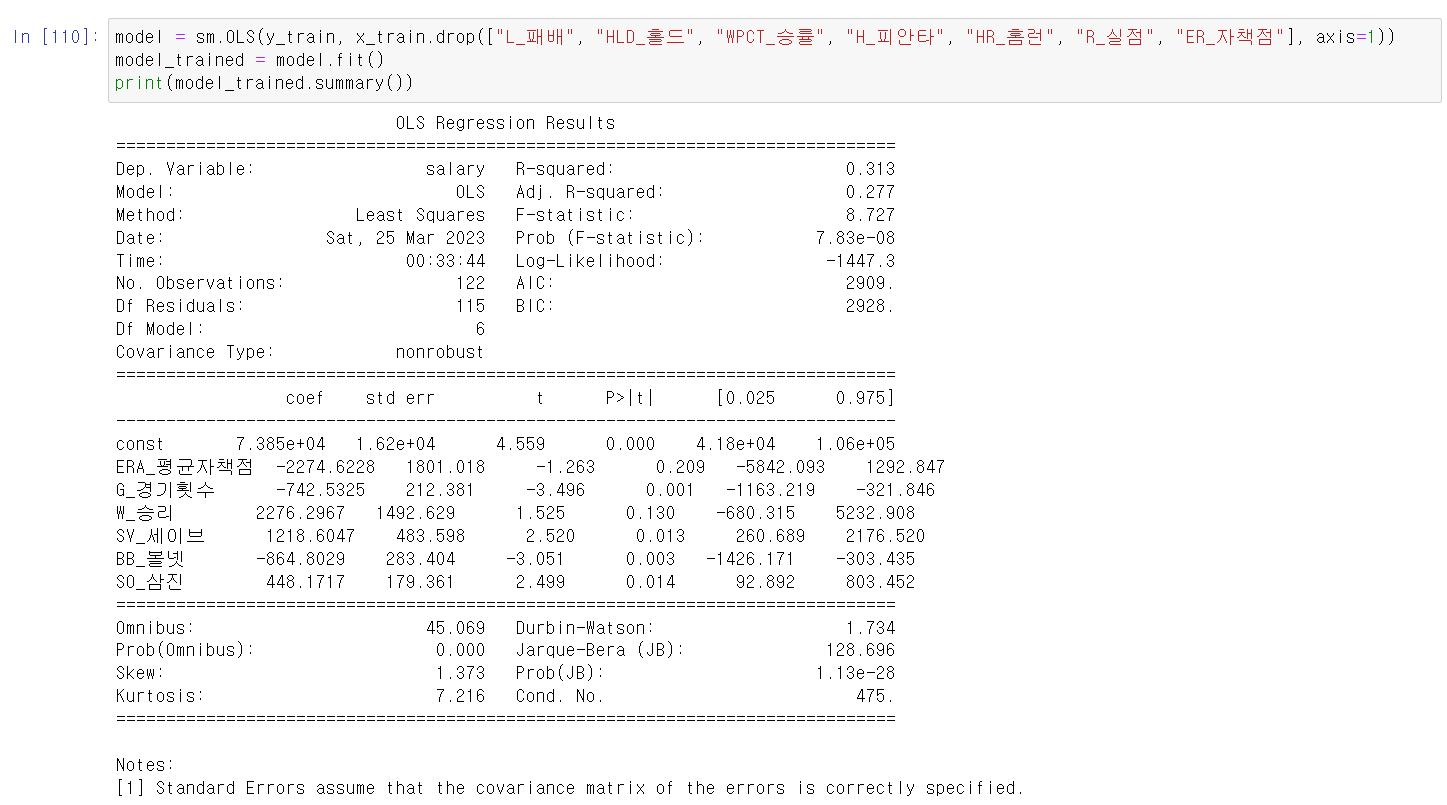
- p-value값이 높은 값을 drop하고 다시 결과를 확인했다.
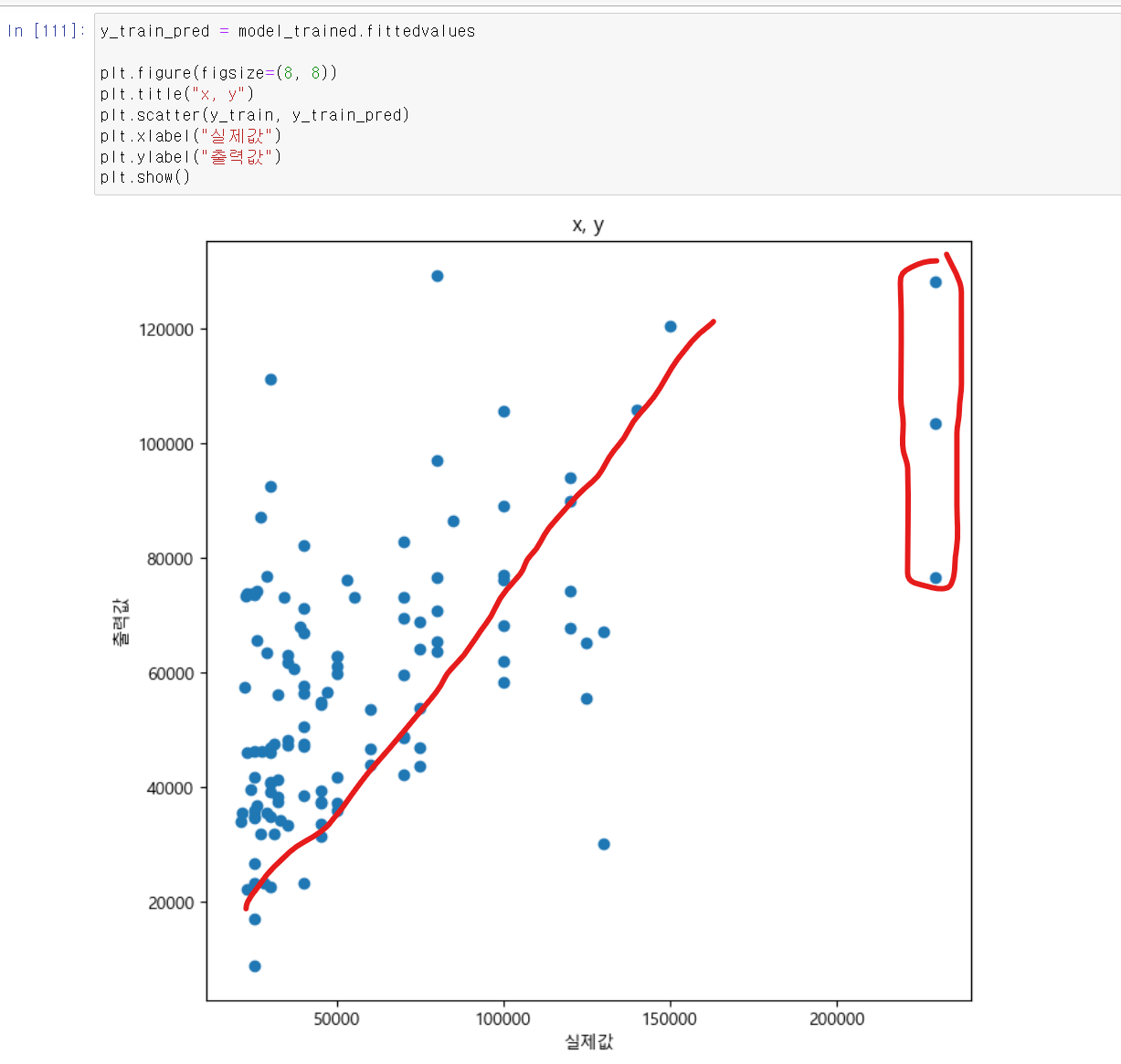
- 이제 예측한 모델을 통해 실제값과 예측값으로 산점도 그래프를 그려보니 아웃라이너 데이터가 몇몇 존재하며, 완벽한 선형직선이 그려지지는 않았다.
- 특히 낮은 연봉대 선수가 많이 있기에 낮은 실제값에 데이터 많이 분포되어 있었다.
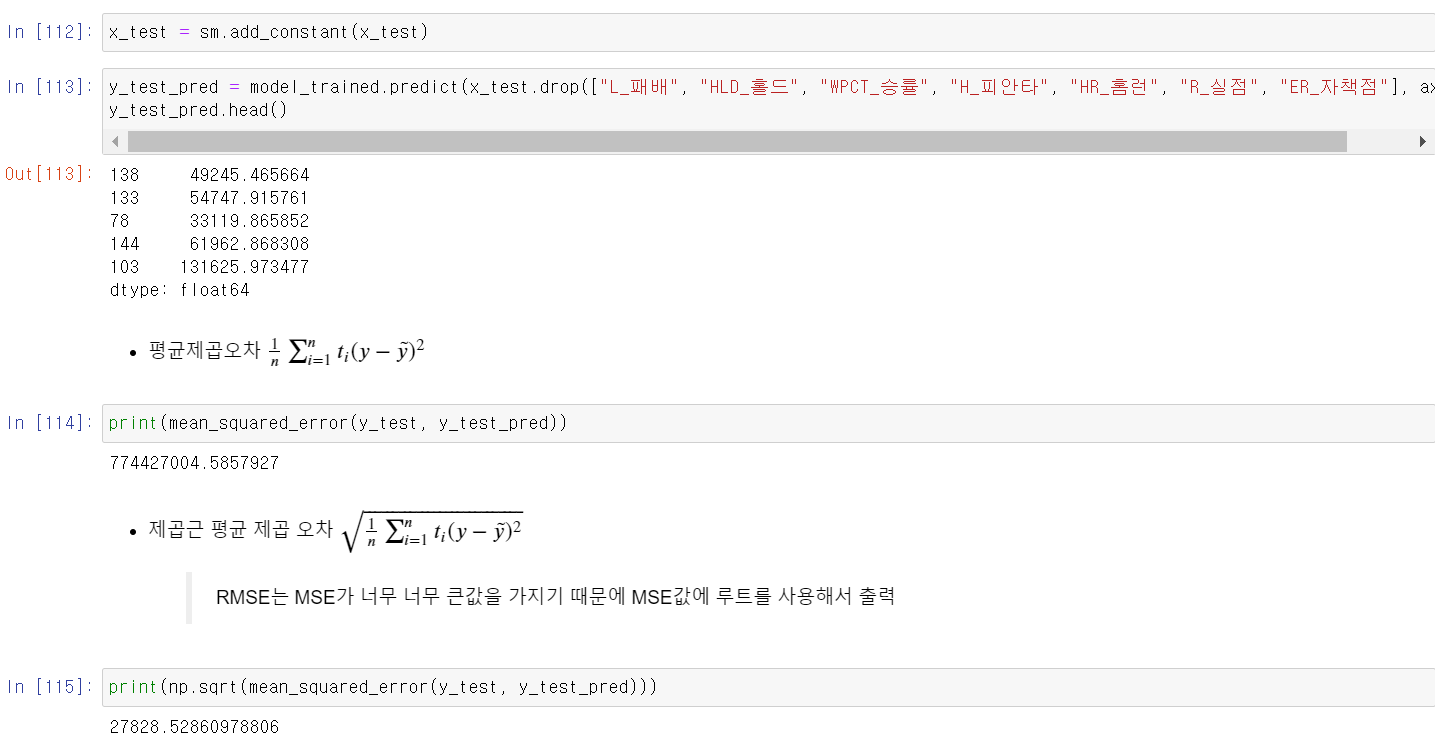
- 이제 해당 모델의 성능을 확인하기 위해 두 지표를 사용하는데, MSE와 RMSE 두 지표를 확인했다
- RMSE를 기준으로 연봉 2억 7천 정도의 오차값이 존재했다.
- 최소 2억에서 최대 23억 연보에서 오차값이 2억 7천이라 오차값이 적지는 않다고 판단했다.
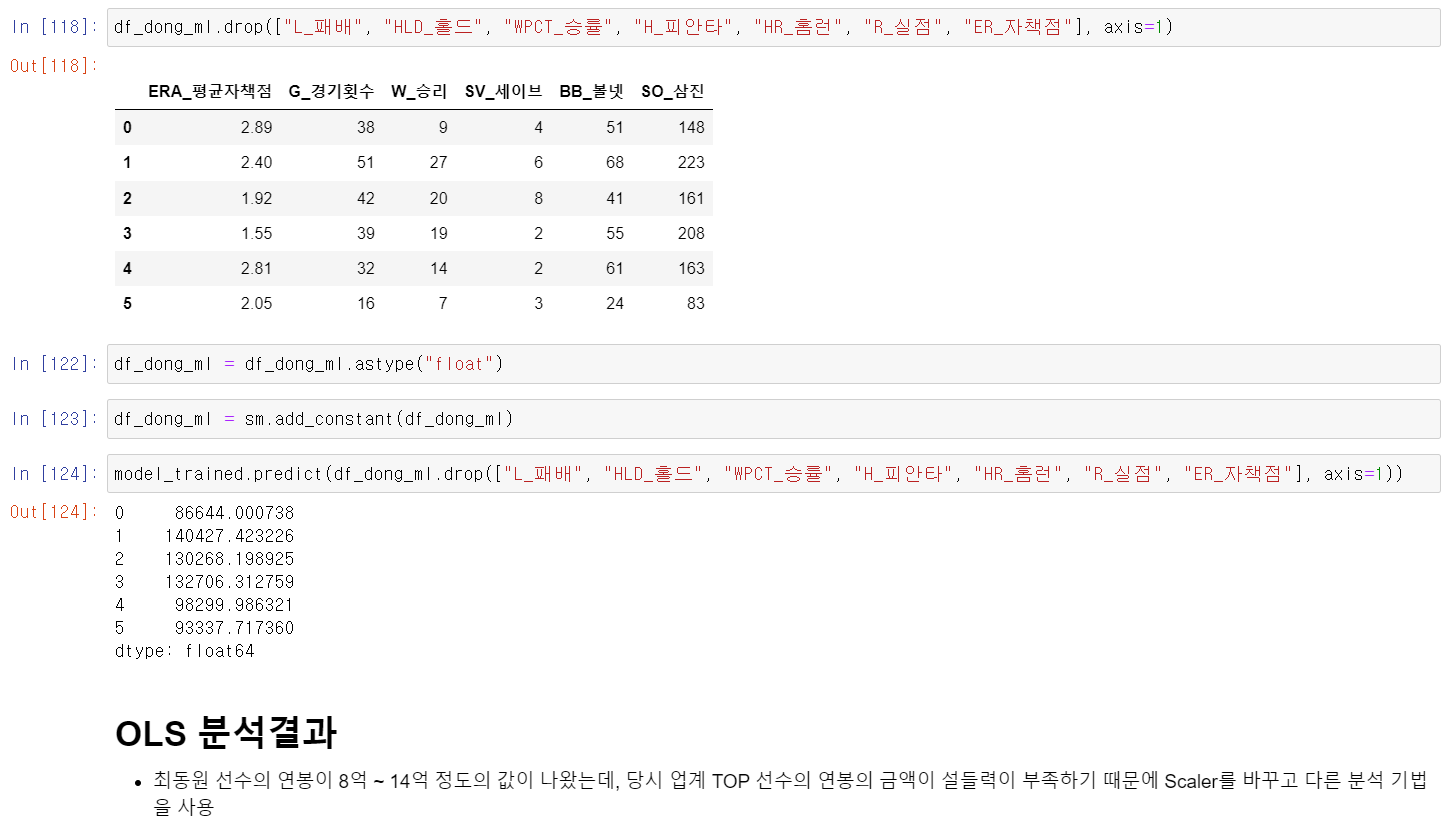
- 이제 해당 모델에 최동원 선수의 데이터를 넣어서 예측값을 확인해보니 8억~14억이라는 결과를 얻었다.
- 하지만 당시 업계 TOP선수였던 선수의 연봉이 너무 낮기에 교육시킨 데이터의 scaler 문제인지 StandardScaler로 다시 모델을 시켰다.
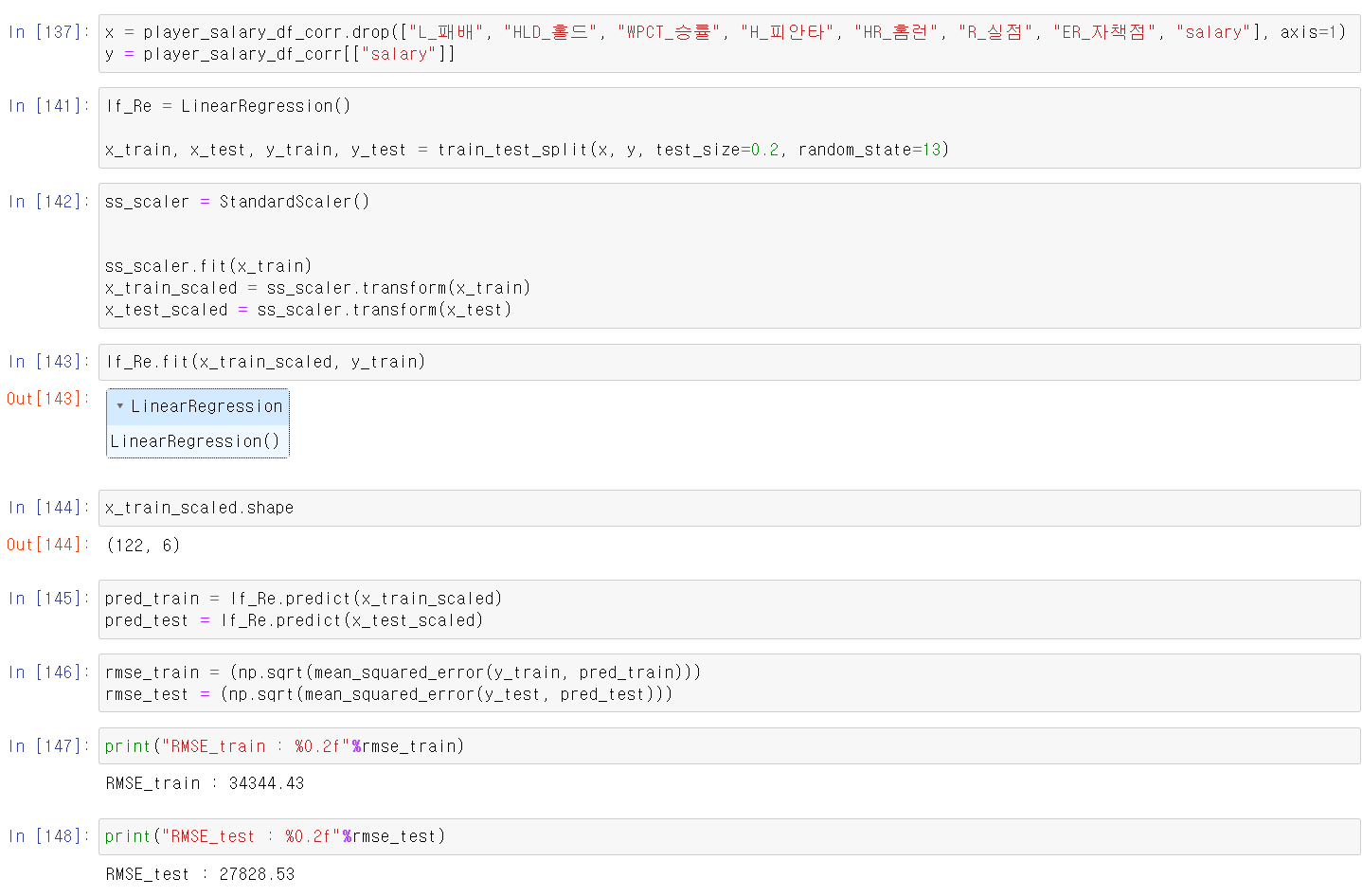
- 먼저 x,y 데이터를 저장하고, 8:2로 나눈 후 StandardScaler모듈로 데이터의 scaler를 바꿨다.
- 여기서 중요한 포인트는 train데이터로 스케일을 교육시키고 transform할 때 test데이터를 교육시키면 안된다는 것이다. test 데이터는 train데이터로 교육시킨 모델을 그대로 test데이터에 transform에 해야한다.
- 이제 scaler을 바꾼 데이터를 LinearRegression모델에 교육시키고, 결과를 확인하니 크게 변한 점은 없는 것 같다.

- 이제 모델에 최동원 선수의 데이터 scaler을 바꾸고 예측해보니 비슷한 결과를 얻었다. 그래서 이번에는 다른 방법을 생각했다.

- 먼저 선형회귀 결과는 다음과 같다.
- 새로 생각한 아이디어는 연봉을 등급별로 나누어 RandomForest방법을 사용하는 것이다.
- 회귀직선에서 적절한 설득력있는 결과가 나오지 않았기에 연봉을 등급으로 나누어 최동원 선수의 등급은 어디인지 확인해보자
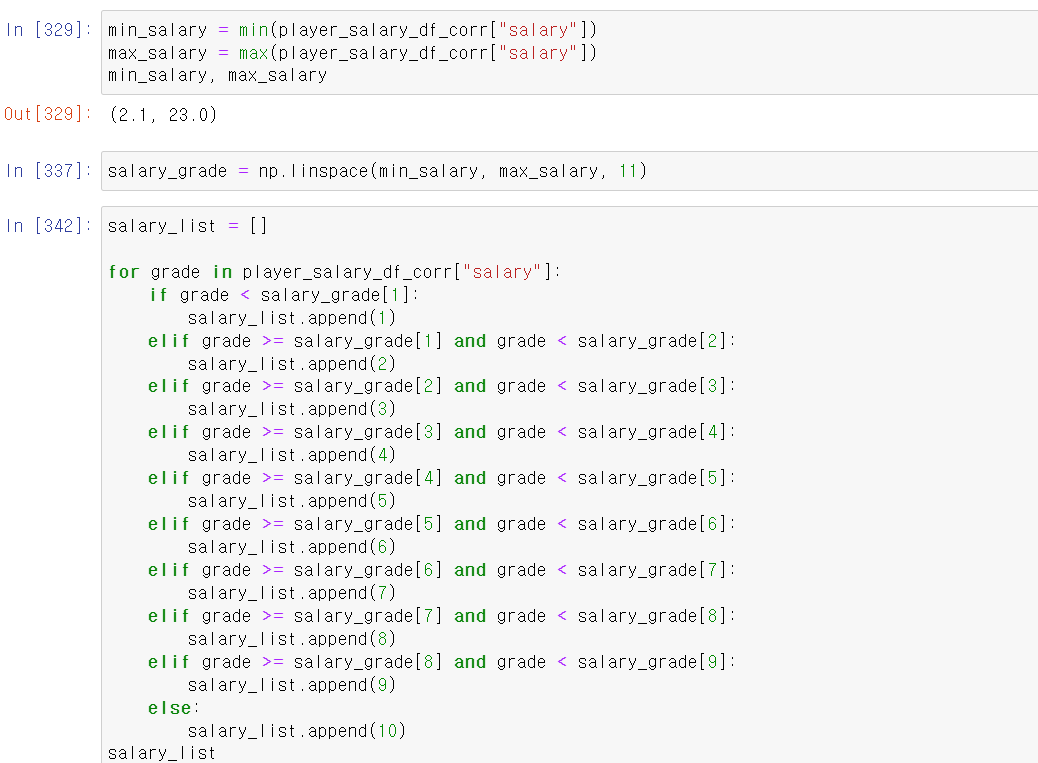
- 먼저 numpy의 linspace기능을 사용해 연봉의 최소값, 최대값을 기준으로 10개의 등급으로 나눴다.
- 그리고 for과 if문을 사용해 선수의 연봉이 해당하는 등급에 맞게 리스트를 만들고,
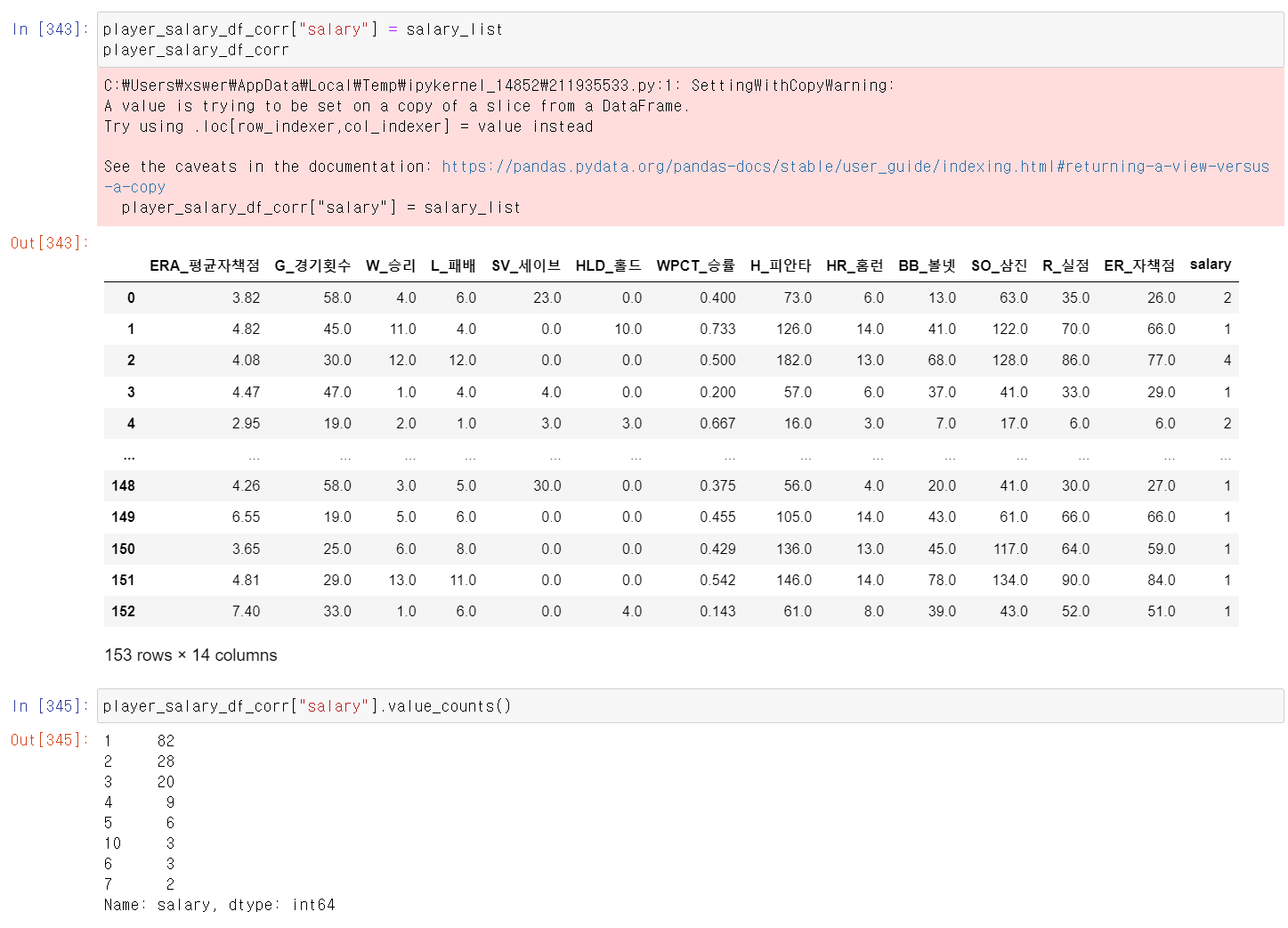
- 해당 리스트를 기존의 프레임에 넣어서 value count를 확인해보니 1~3등급 연봉에 많이 몰려있다(10이 제일 높은 연봉)
- 이제 랜덤포레스트, 교차검증을 위해 모듈을 설치하고,
- 위에 회귀분석과 같이 데이터를 나눈 후 paras 변수에 gridSearchCV에 사용할 값을 저장했다.
- GridSearCV에 랜덤포레스트 모델을, param변수로 교육하고, 정확도가 나오게 저장했다.
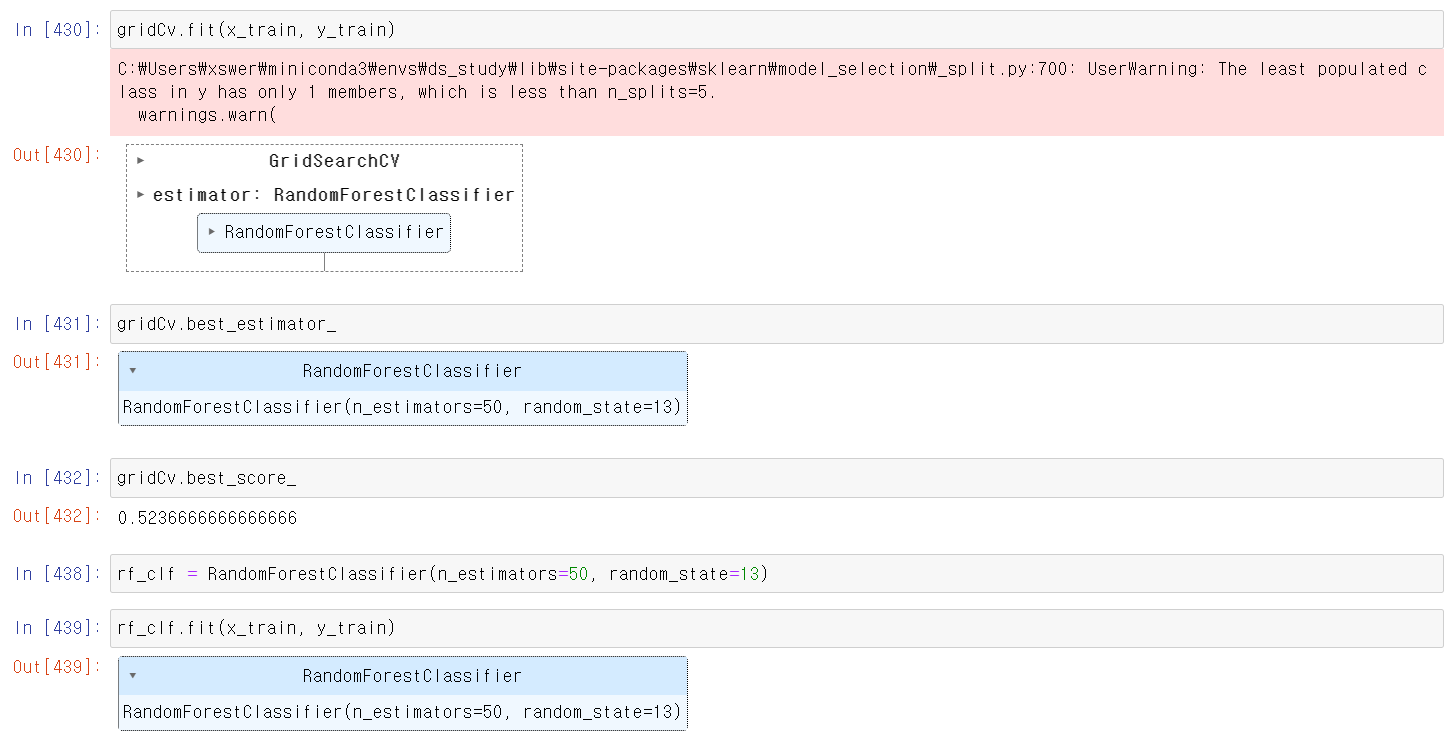
- 이제 x_train, y_train 교육시켜 결과를 확인해보니 최고 모델은 n_estimator값은 50이 나왔다.
- 사실 데이터 index가 153개밖에 없어서 n_estimator값을 높게 주기 힘들었다.
- 그리고 교차검증 정확를 보니 성능이 처참했다. 정말...이유는 마지막에 서술하겠습니다.
- 이제 교차검증대로 50의 n_estimator값을 주고 랜덤포레스트에 train값을 교육시키고
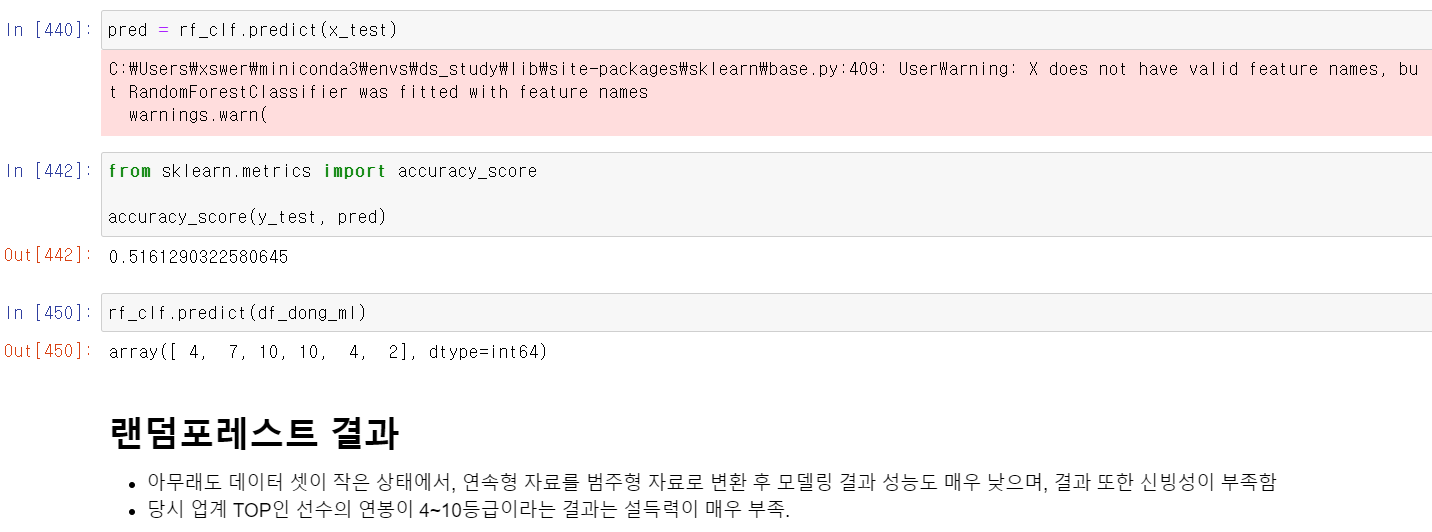
- 최동원 선수의 데이터 형태를 모델에 맞게 바꾼 후 결과를 확인하니 10 10 4 4 7 2 등급의 연봉이 나왔다. 음 설득력은 많이 부족하지만 그래도 10등급의 연봉이 2번이나 나왔으니 마냥 설득력이 부족한 것 같지는 않다.
-
느낀점
- 데이터의 중요성
먼저 해당 Toy_project를 A to Z까지 데이터 수집 , 추출, 가공, 분석 등 모든 과정을 혼자해보니 어떤식으로 데이터 분석이 진행되는지 큰 맥락을 조금 알 수 있었다. 제일 중요한 것은 목적에 따라 데이터를 정확히 수집하고 가공해야한다는 것이었다. 분석은 다양한 기법을 사용하고 비교하기 때문에 비교적(주관적 생각) 실수의 발생 확률이 적지만, 데이터 자체가 잘못됐다면 엉뚱한 결과가 나올 수도 있기 때문이다. 꼭 맞는 비유는 아니지만 이것이 제3종오류와 비슷하다 생각했다. 3종 오류는 문제를 해결하는 과정에서 문제 자체를 잘못 정의한 것인데, 데이터 분석에서 데이터를 잘못 수집한 것은 근본적으로 분석에서 잘못을 했다는 생각이 들었다.
- 도메인의 중요성
1번과 연결되는 내용인데, 나는 야구에 대해서 1도 관심이 없고 지식도 부족했다. 그래서 모든 과정을 끝내고 투수 아마추어 대회에서 우승한 친구에게 해당 과정을 설명하니, 데이터를 분석할 때 중요한 컬럼을 제대로 반영하지 못했다. 내가 조금 더 도메인에 대한 지식이 존재했다면, 중요한 컬럼, 지표를 신중하게 분석했을 텐데 그 점을 제대로 하지 못한 것이 아쉽다.
- 데이터의 중요성
-
마무리 : 그래도 전체적인 분석 과정은 나름 만족스럽다. 다만, 중간 중간 디테일이 부족하니까 다음에는 조금 더 잘해보자

상황을 바꿀 수 없다면, 나를 바꾸자