-
이번에는 인구수, 인터넷 사용량, 지역 등 3개의 데이터를 통해 인터넷 사용 정도에 대한 데이터를 가공 및 전처리를 해보자
-
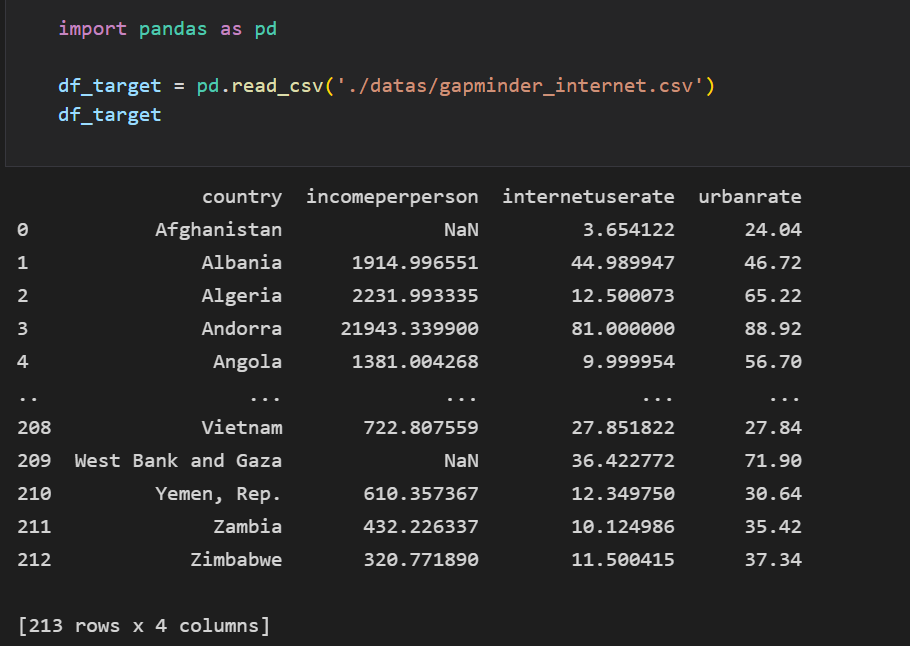
먼저 1인당 소득, 1인당 인터넷 사용량, 요금에 대한 데이터를 불러온다.
-
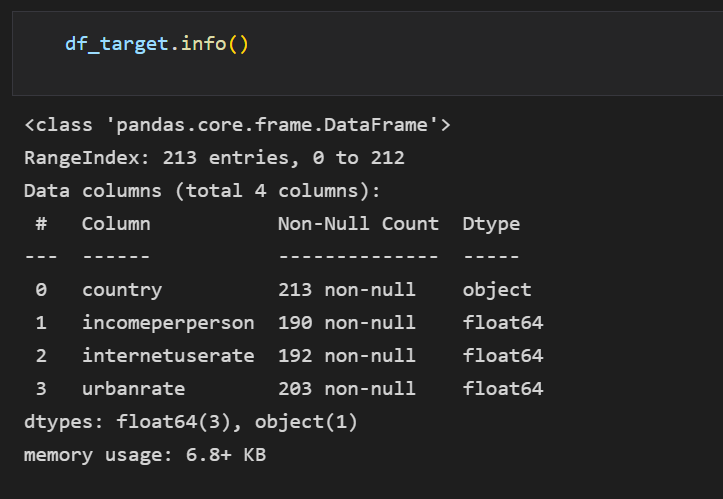
데이터의 정보를 보니 국가는 string, 나머지는 float형태로 저장되어 있다.
-
Null값은 없으나 데이터의 컬럼이 동일하지 않기 때문에 결측값, 빈값 등 다양한 이상 데이터가 있다는 것을 확인할 수 있다.

-
가장 먼저 Nan값이 있는 행을 제거했다.
-
여담이지만 pandas를 쓰면 쓸수록 데이터 처리 기능이 정말 좋은 것 같다.
-
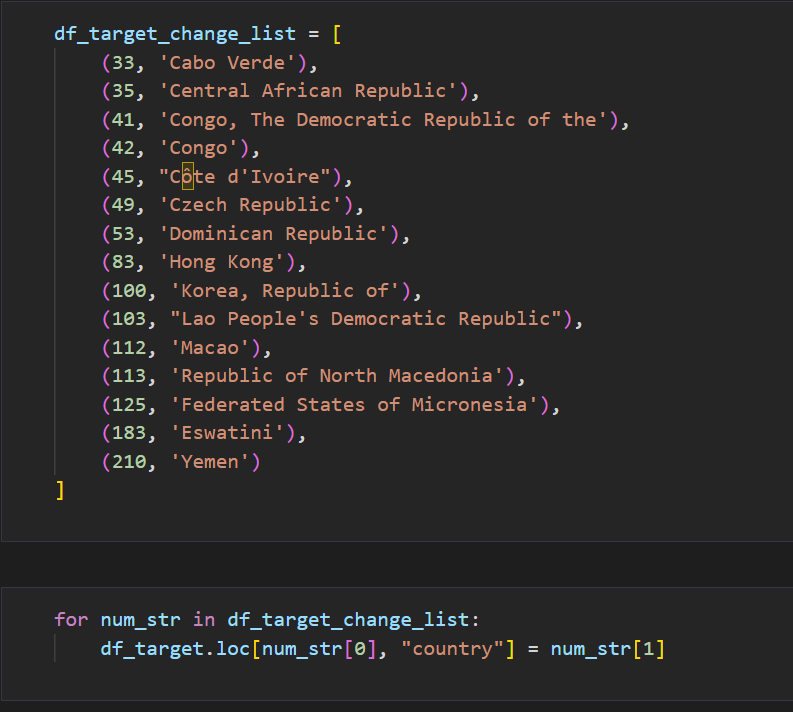
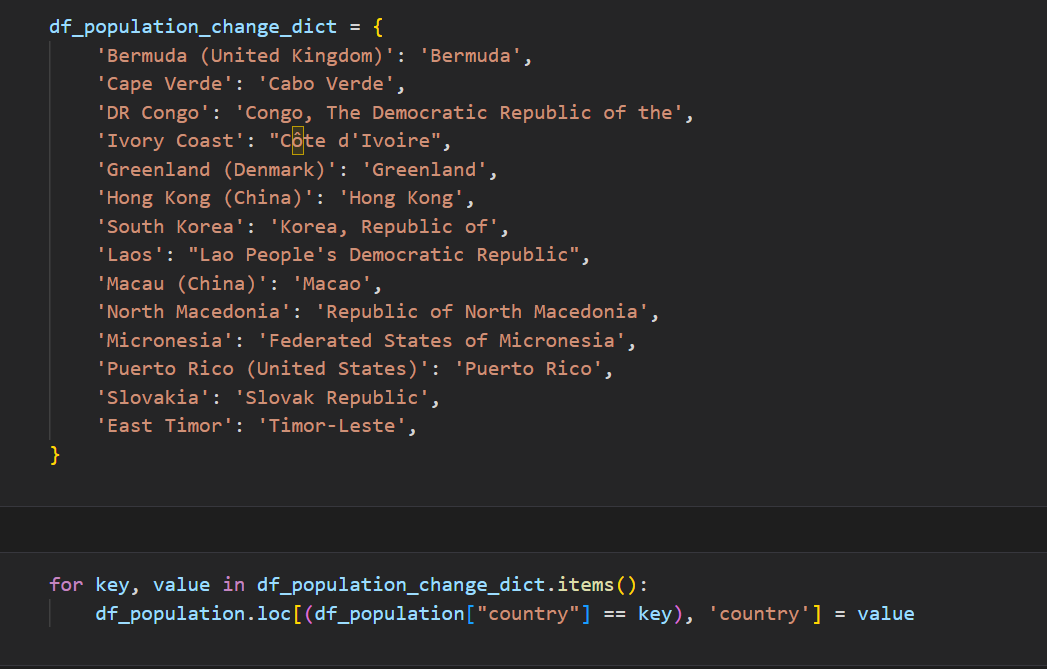
하나의 국가를 여러 명칭으로 적는데 우리나라의 경우 Korea, south korea, Korea Repulic of 여러 명칭으로 불린다.
-
데이터 분석 시 그룹별 집계를 수행할 때 계산 에러가 없도록 각 행의 나라이름을 통일할 수 있도록 Dict형태의 자료로 국가의 이름을 바꿨다. 또한, pycountry모듈을 사용하기 위해 통일시켰다.
-
loc함수를 사용해서 딕셔너리의 키값을 인덱스로 넣고, value를 값으로 입력했다.
-
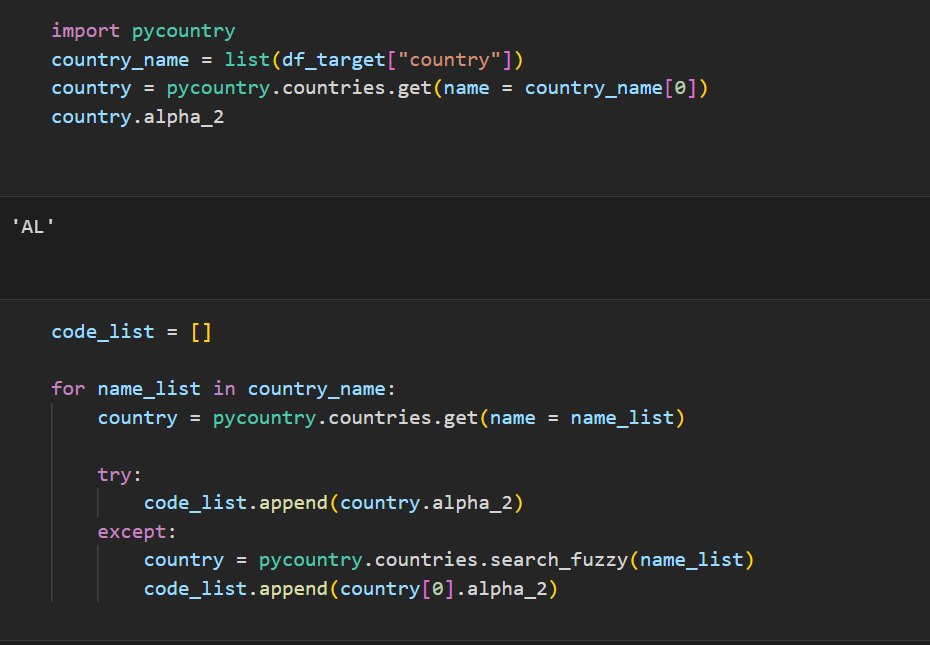
이제 pycountry모듈을 사용해서 국가의 약자를 입력했다.
-
해당 모듈은 국가의 이름을 입력하면 해당하는 국가의 alpha_2, alpha_3에 해당하는 약어를 출력한다.
-
하지만 제대로 검색되지 않는 국가도 있기 때문에 try, except 기능을 사용해서 에러가 발생할 경우 pycountry의 fuzzy기능으로 검색했다.
-
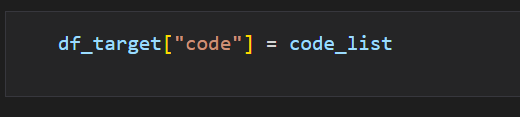
이제 해당 데이터프레임에 code라는 컬럼을 국가의 약어로 추가했다.
-
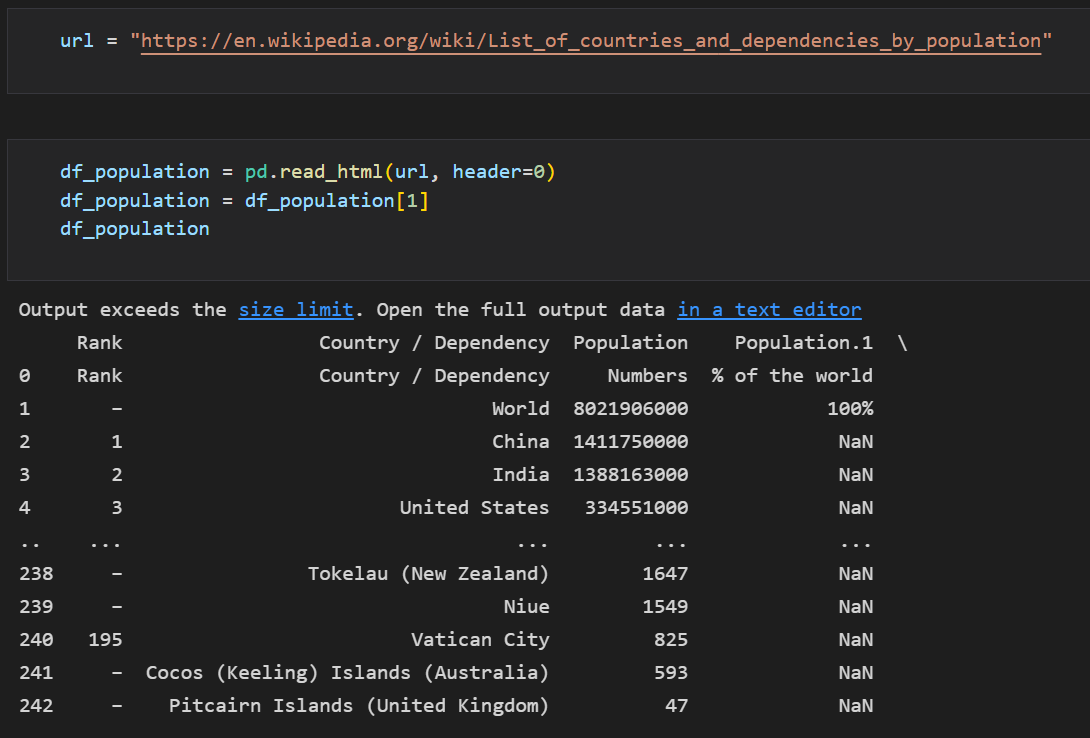
이번에는 국가의 인구수 데이터를 불러왔다.
-
해당 데이터를 웹상에서 존재하는 테이블 데이터를 read_html로 불러왔는데, 2번 째 해당하는 테이블이 필요한 데이터라 불러온 리스트 형태의 테이블 데이터에서 2번째만 변수에 저장했다.
-
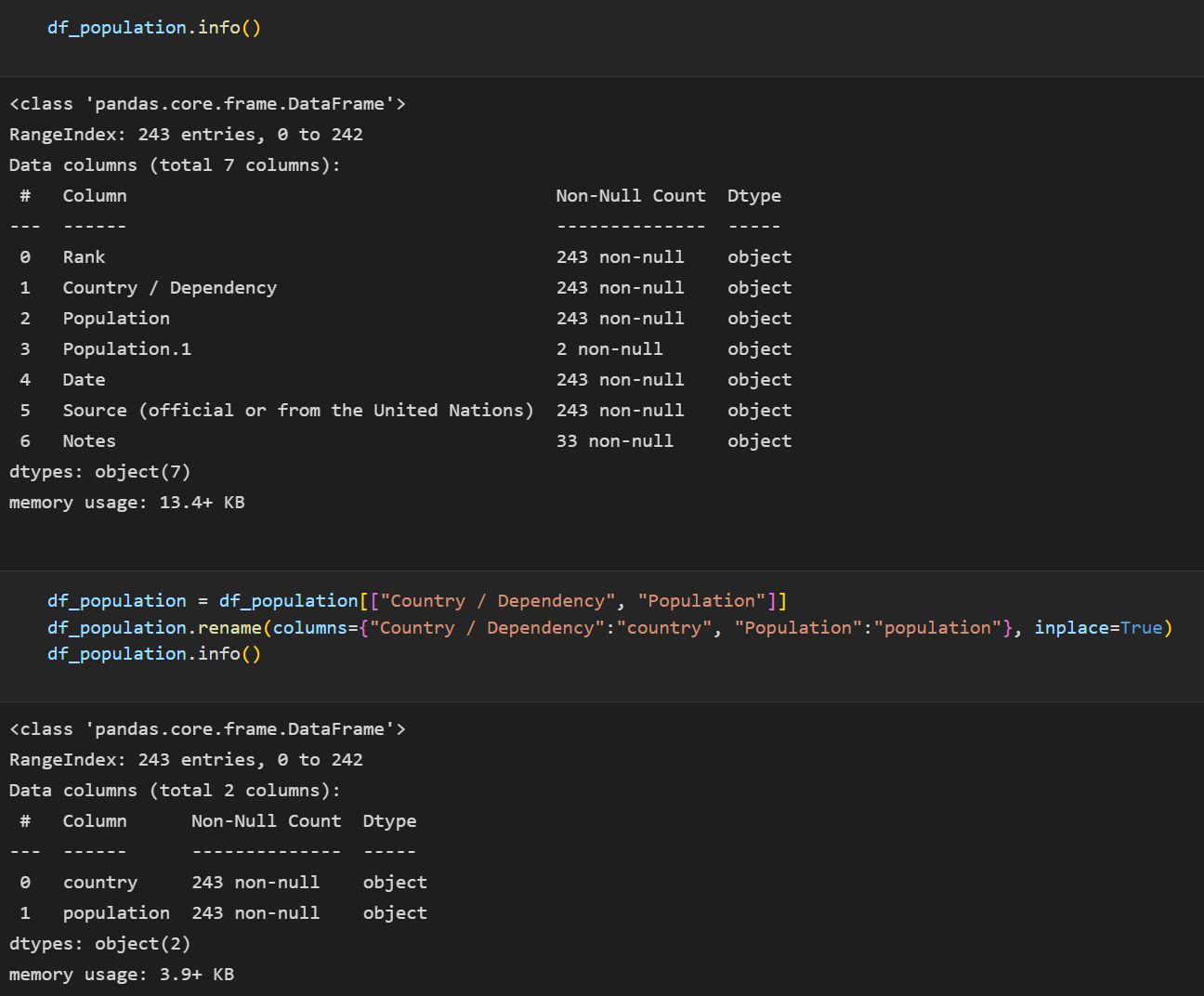
데이터의 정보를 출력하고 확인 결과, 필요한 데이터인 국가, 인구수만 변수에 다시 저장하고, 가독성을 높이기 위해 컬럼의 name을 변경했다.
-
이번에도 국가의 이름을 업데이트하기 위해서 Dict형태로 된 데이터를 for을 통해 key값 조건에 맞을 경우 value값으로 변경했다.
-
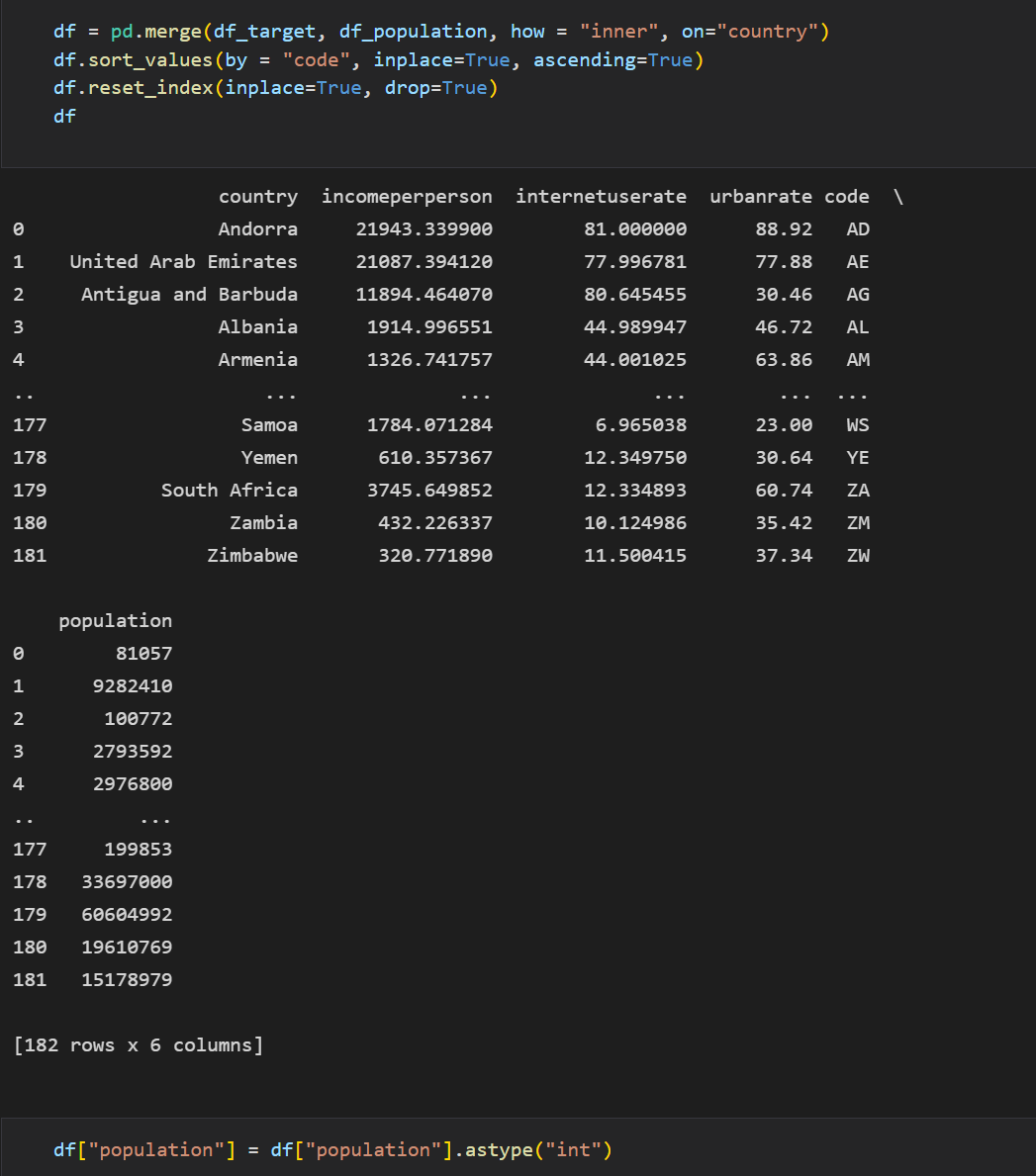
이제 가공한 두 개의 데이터를 국가 이름을 기준으로 inner조인하고
-
국가의 코드네임을 기준으로 내림차순으로 정렬했다.
-
마지막으로 기본 인덱스를 0부터 출력하도록 reset_index했다.
-
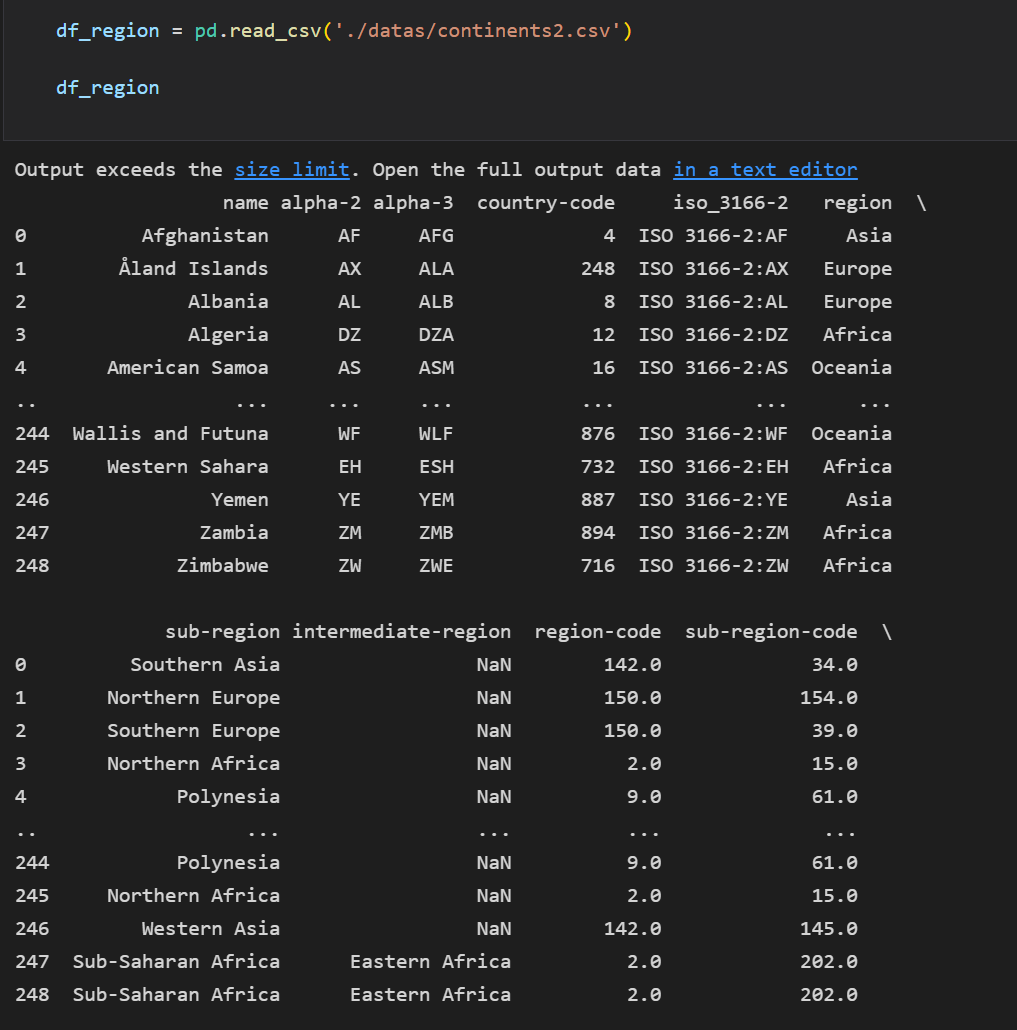
이번에는 지역 데이터를 불러왔다.
-
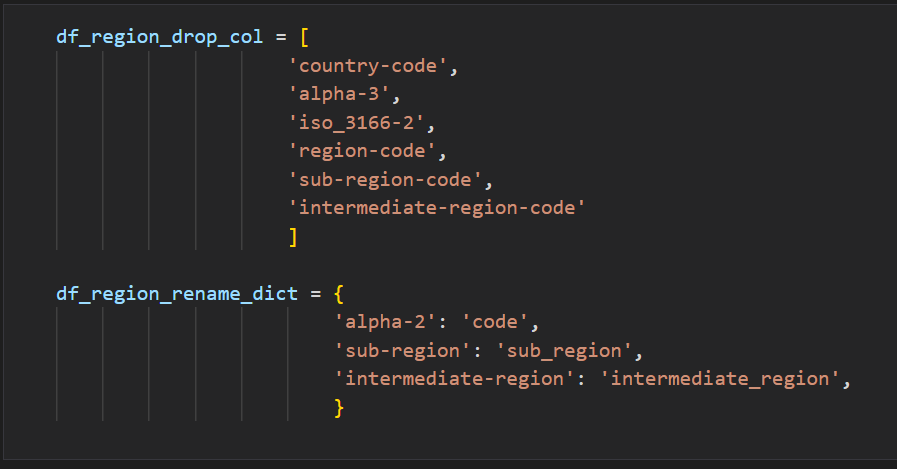
필요없는 컬럼과 변경할 컬럼 이름을 리스트와 Dict형태로 먼저 변수로 저장했다.
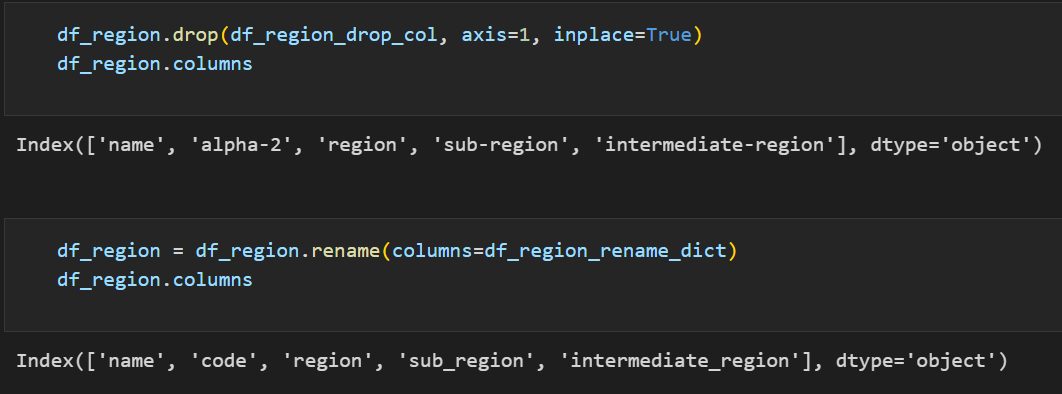
-
이제 지역 데이터에서 필요없는 자료는 drop하고, 컬럼의 이름을 변경했다
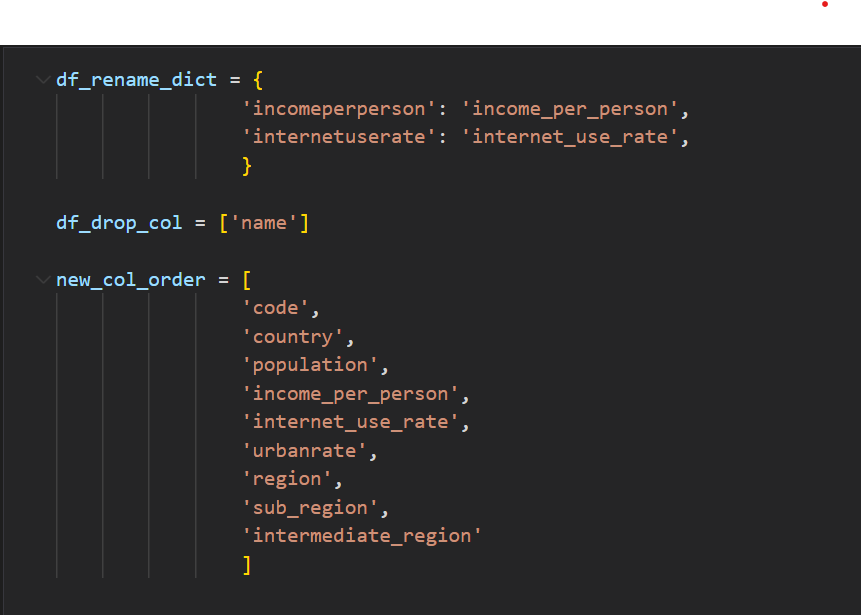
-
이제 세 개의 데이터를 합치기 전에 먼저 다 합친 데이터에 사용할 변경할 이름, 버릴 커럼, 컬럼 이름 정리 등 변수를 미리 만들었다.
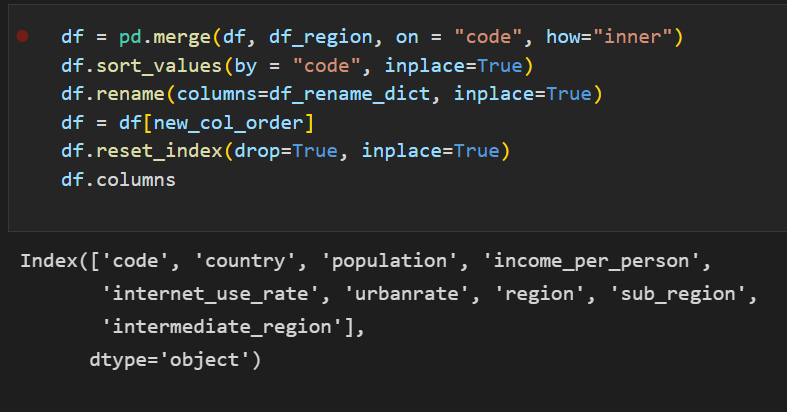
-
이제 인터넷 사용량과 인구수를 합친 데이터를 지역 데이터와 같은 방법으로 merge해서 합치고
-
code를 기준으로 정렬한 후 새로운 컬럼 이름으로 변경했다.
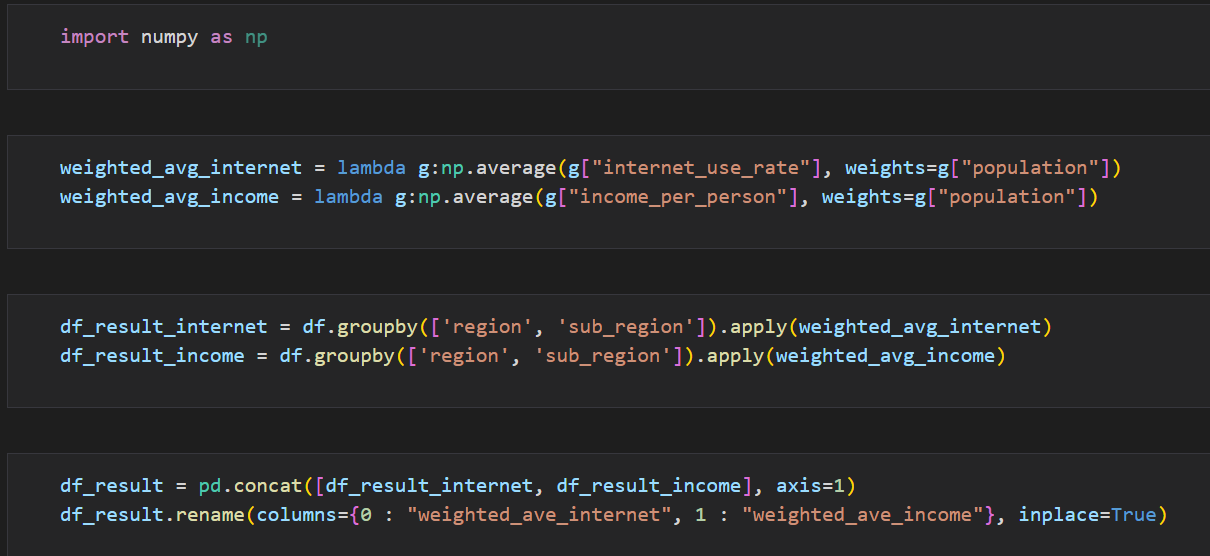
-
이제 지역별로 인구수를 가중치로 둬서 인터넷 사용량에 대한 가중평균을 구해보자
-
lambda함수와 numpy함수를 사용해서 인터넷 사용량을 평균값으로, 인구수를 가중치로 둬서 가중평균을 구하는 함수를 만들었다.
-
이후 해당 함수를 데이터프레임에서 지역 및 서브 지역을 그룹별로 나눠서 apply함수를 사용해서 적용시켰다.
-
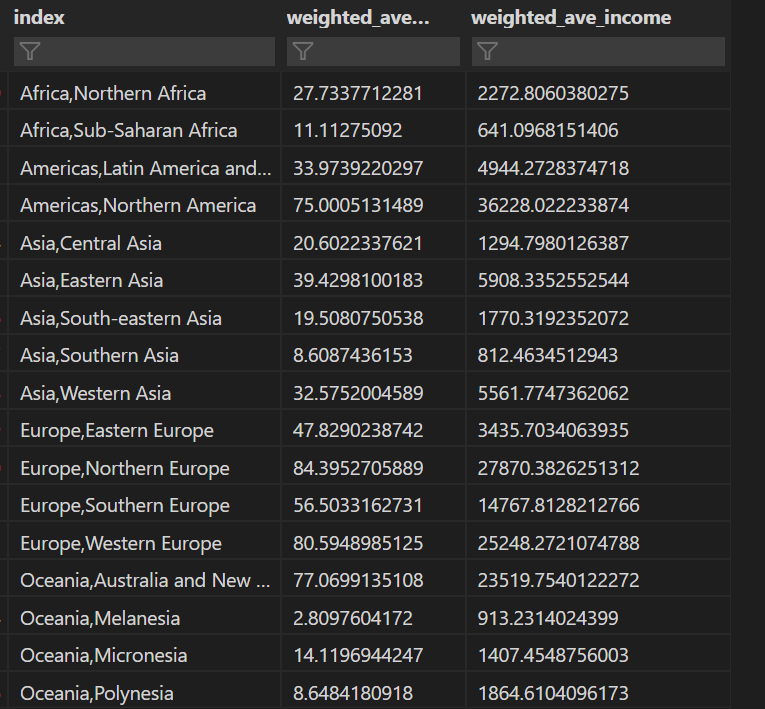
마지막으로 그룹by를 사용하느라 바뀐 컬럼 이름을 바꿔주고 결과를 확인했다.
-
부가적으로 1인당 소득도 같이 구했는데, 가장 큰 목적은 인터넷 사용량 😁
-
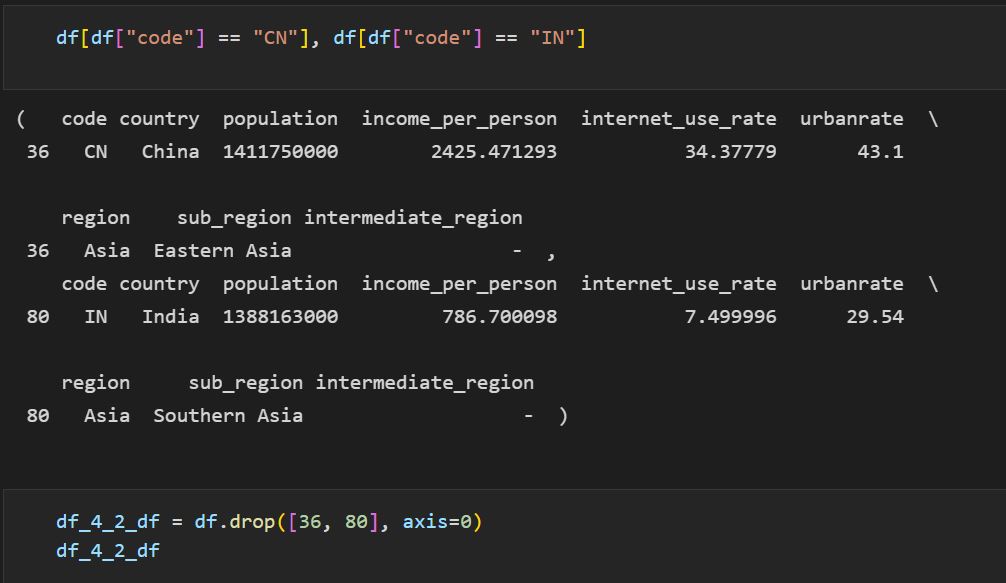
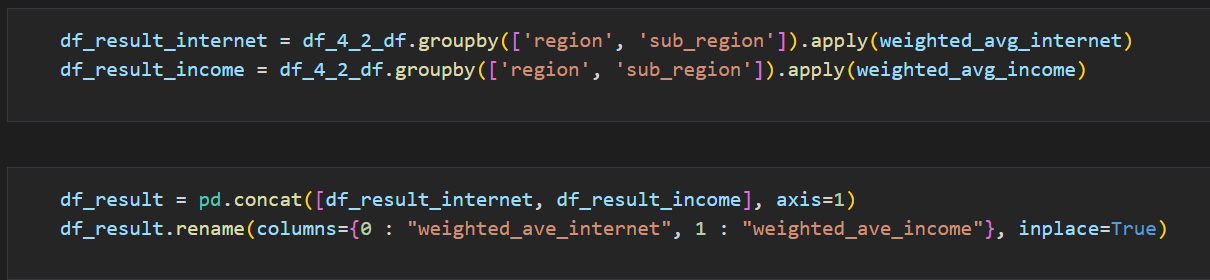
아시아 사용량의 경우 중국과 인도의 값이 다른 값들과 비교해서 너무 높기 때문에 두 개의 데이터에 대한 인덱스를 확인해서 삭제 후
-
다시 아까와 같은 방법으로 데이터 프레임을 만든다.

-
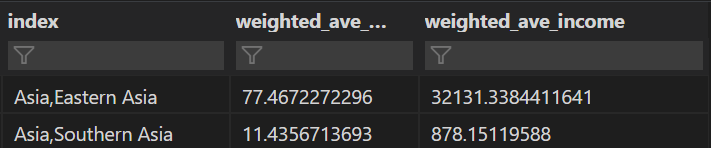
이제 중국과 인도에 속한 서브 지역의 데이터만 변수에 저장해서
-
결과를 확인해봤다.
-
데이터 분석가로서 머신러닝, 딥러닝, EDA 다 중요하지만, 가장 기본적으로 데이터의 가공 및 전처리 역량이 중요하지 않나 생각이 든다. 내가 주장하려는 내용 혹은 데이터 속에서 인사이트를 얻으려고 할 때 가장 먼저 해야하는 것은 데이터의 전처리이지 않나 싶다.
