

- 이번에는 대한민국의 박물과 및 미술관의 데이터를 전처리해보자
- 가격, 사용 시간, 요금 등 다양한 측면에서 분석하기 쉽도록 데이터를 가공할 예정이다.

- 가장 먼저 json파일을 변수에 저장했다.

- 제이슨 파일의 형태를 보니, fields 키값에 데이터의 컬럼이 저장되어 있고,
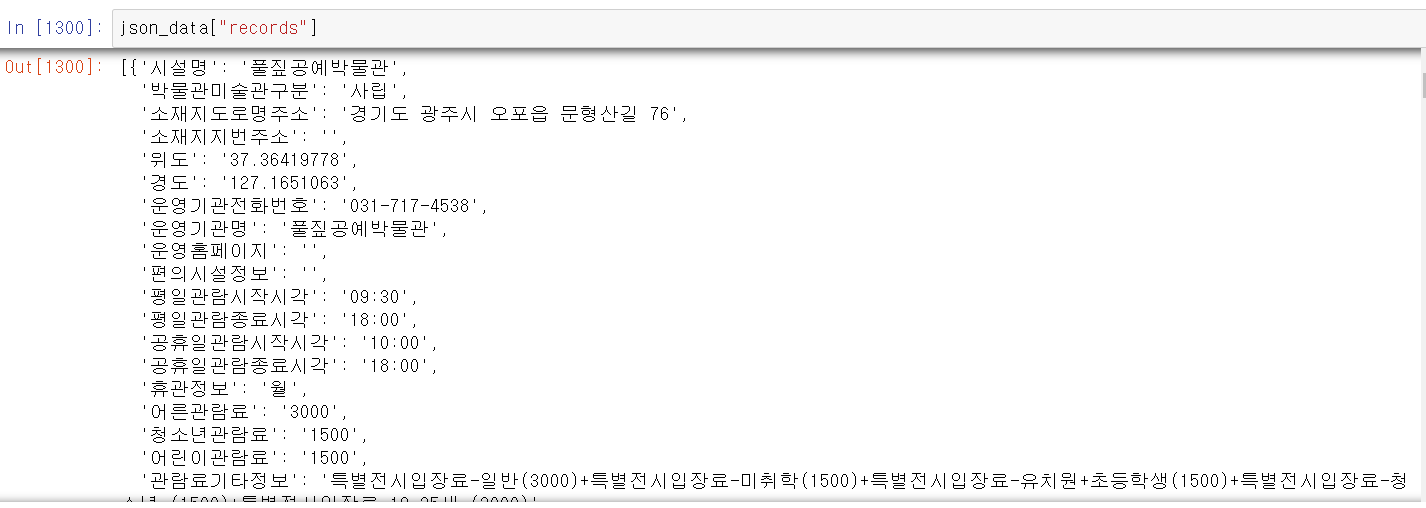
- 두번 째 key인 records에 데이터가 있는데, 리스트 형태로 저장되어 있어서 각 인덱스마다 데이터프레임의 한 행씩 저장되어 있는 것 같다.
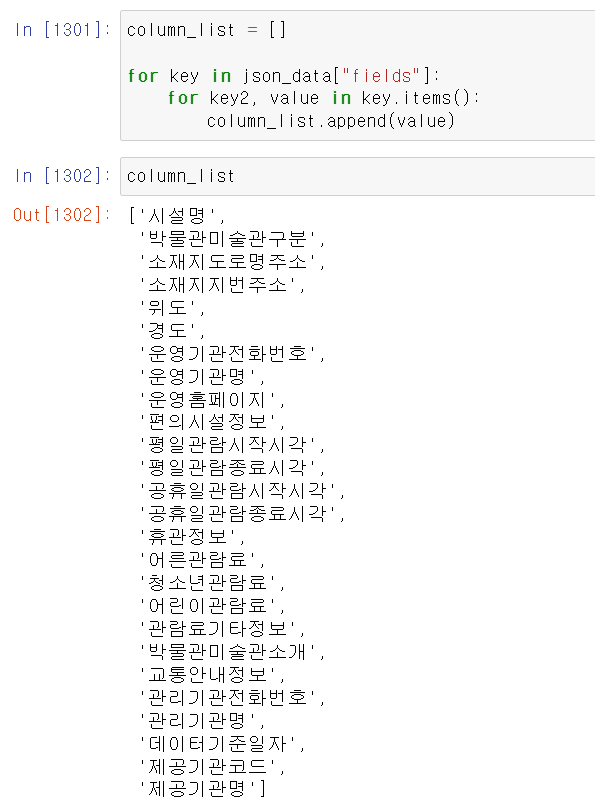
- 가장 먼저 fields key값에서 데이터를 뽑고 이중 for문을 통해 컬럼명만 출력해서 컬럼name으로 사용할 리스트를 만들었다.
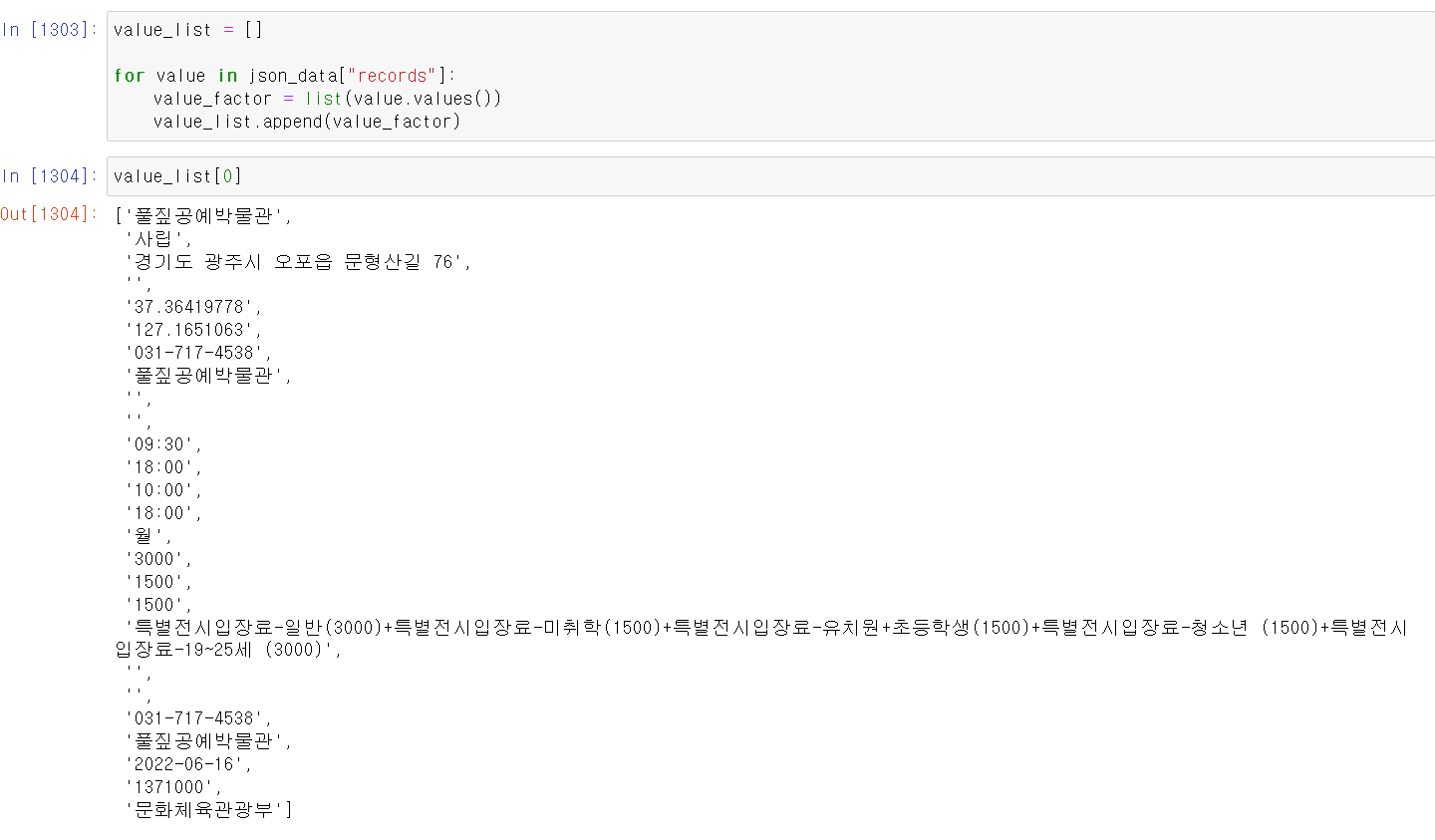
- 다음으로 json파일에서 records를 for을 돌려서 데이터를 불러왔다.
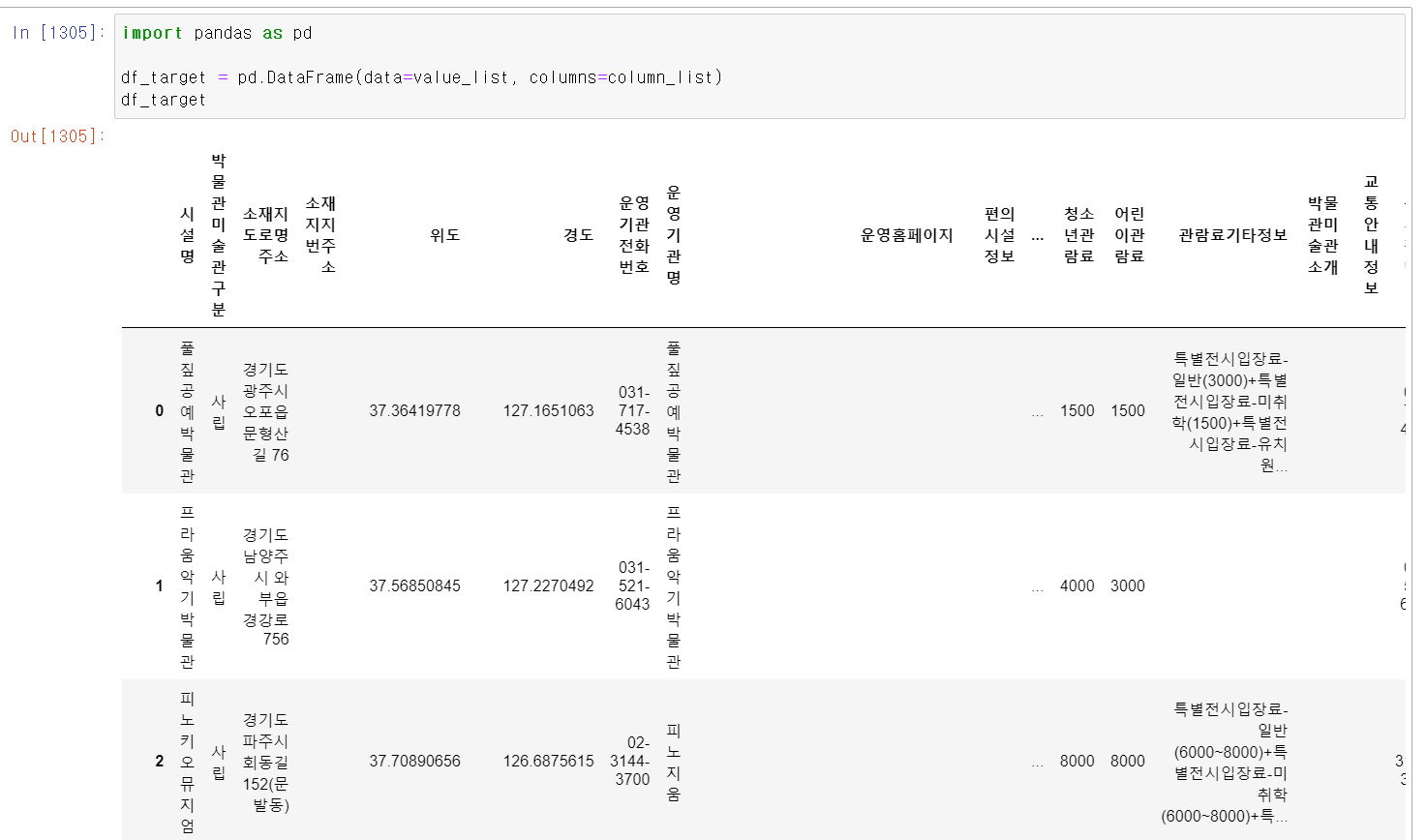
- 이제 pandas 모듈을 통해 두 개의 리시트로 데이터프레임을 생성했다.

- numpy 모듈을 사용해서 빈값을 Nan처리함으로써 수식에 에러가 없도록 만들었다.
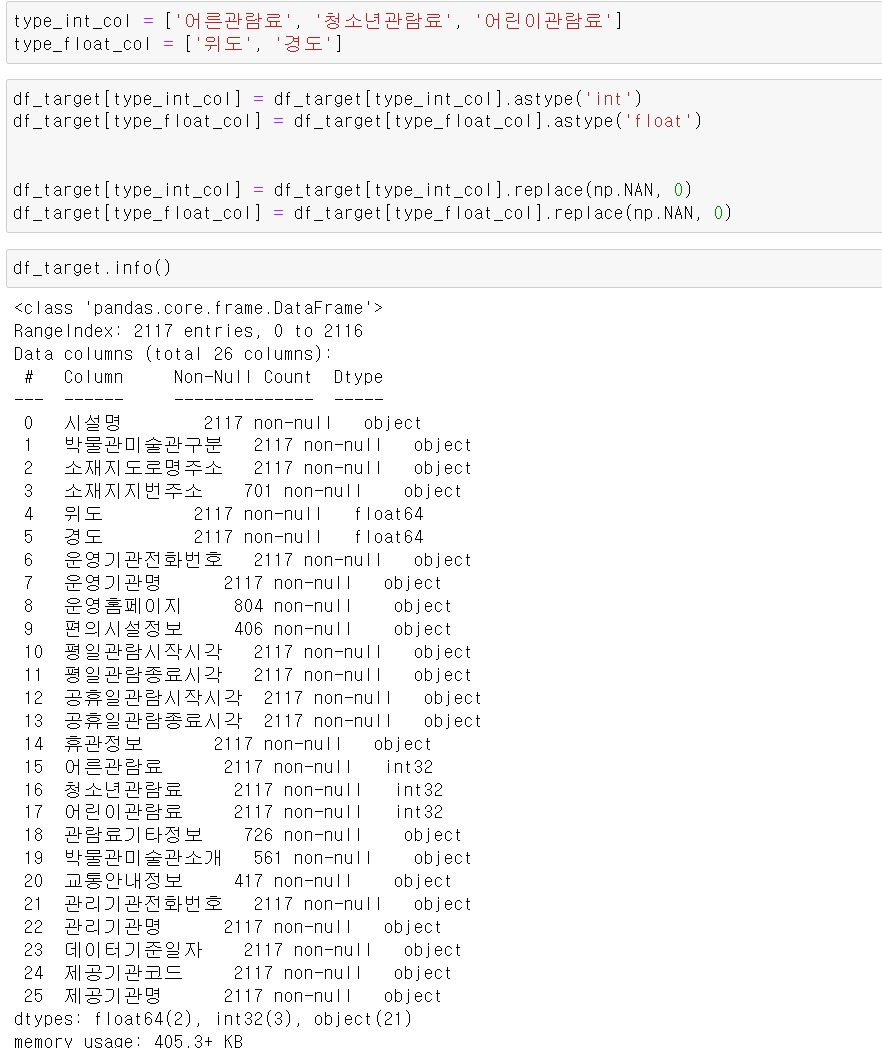
- 이제 각 컬럼을 분석 및 계산할 수 있도록 관람료 컬럼들은 int값으로, 위도과 경도는 float형태로 만들었다.
- 또한 해당 5개의 컬럼에서 Nan값은 0으로 replace기능을 사용해서 변경했다.

- 이제 데이터 중 필요없는 데이터를 drop했는데, 위도랑 경도는 drop하는데 굳이 데이터를 바꿔야했나...?😒
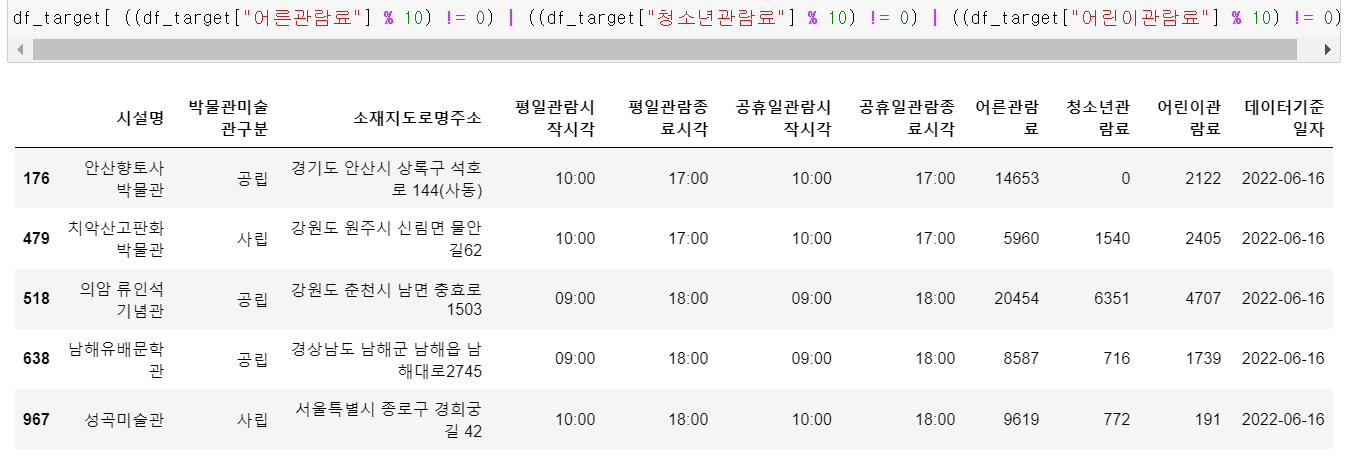
- 관람료의 경우 10원 단위로 계산되는 곳이 없기 때문에 10으로 나누고 0이 안 될 경우 이상 데이터로 판단했다.
- 어른, 청소년, 아이 관람료 중 어느 하나라도 10으로 나눠서 0말고 다른 값이 나오는 데이터의 index를 확인했다.

- 또한 요금이 10만 원이 넘는 경우 해당 데이터 또한 신뢰성이 없기에 drop시켰다.
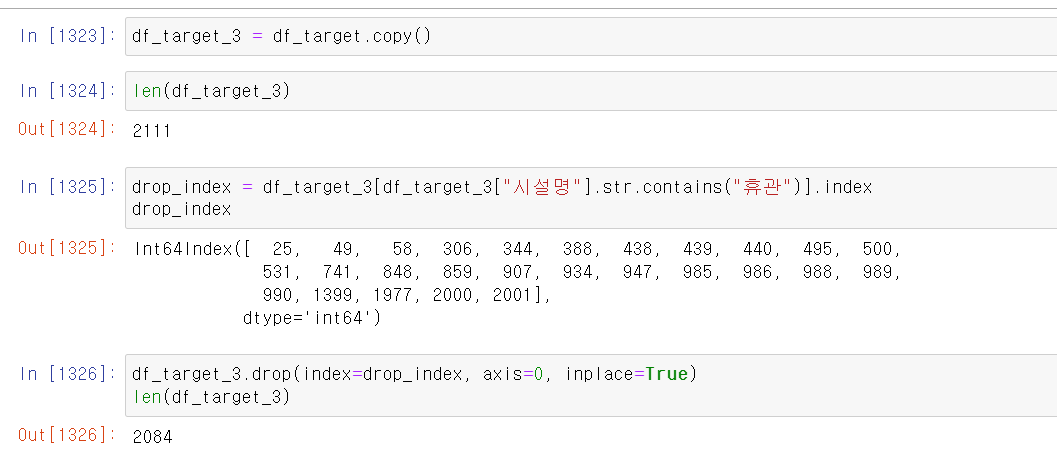
- 요금 이상 데이터를 찾은 후, 휴관하고 있는 미술관 및 도서관의 데이터 index를 확인하고 해당 인덱스의 데이터를 drop했다.
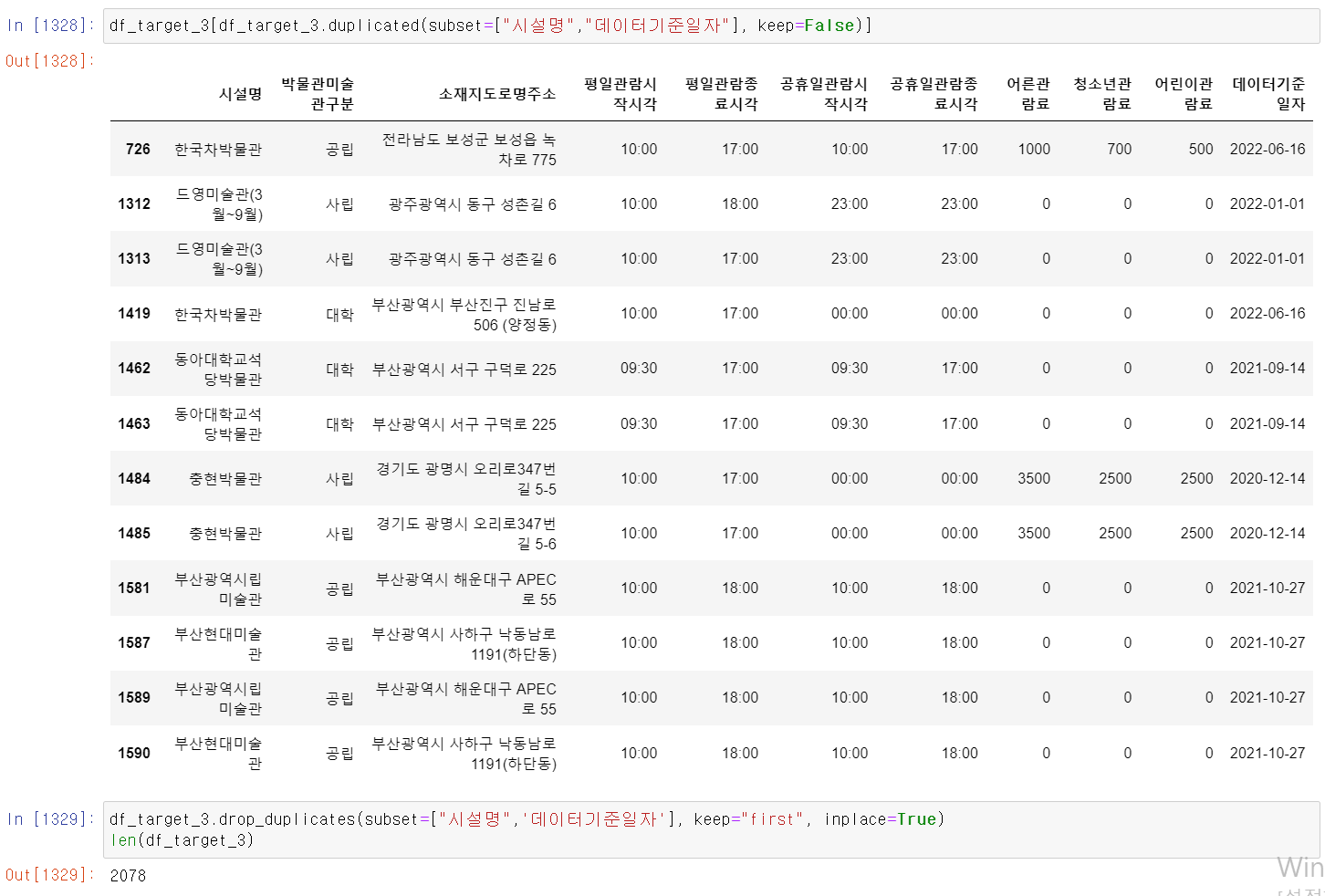
- 데이터 출력 과정에서 중복된 데이터가 있을 수 있기에 [시설명, 기준일자] 두 데이터를 기준으로 중복된 값이 있는 index를 확인하고 가장 최근의 index데이터를 살리고 나머지는 drop했다.
- 이후 시설명이 같을 경우 기준일자로 정렬한 후 가장 최근 날짜의 데이터만 살리고 나머지는 drop했다.
- 데이터의 head를 확인하니 정상적으로 출력되는 것을 확인했다.
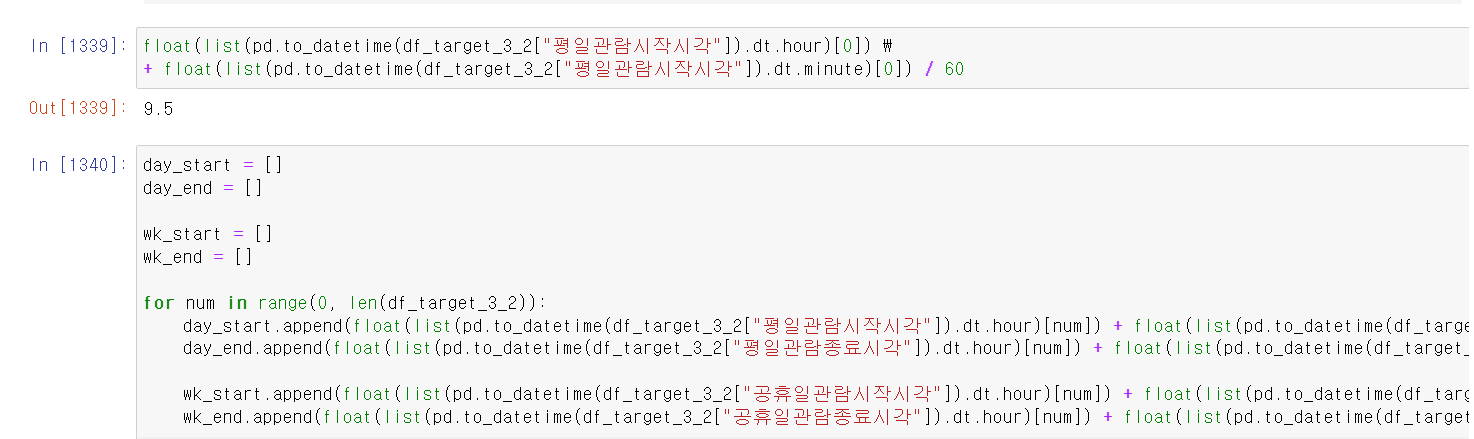
day_start = []
day_end = []
wk_start = []
wk_end = []
for num in range(0, len(df_target_3_2)):
day_start.append(float(list(pd.to_datetime(df_target_3_2["평일관람시작시각"]).dt.hour)[num]) + float(list(pd.to_datetime(df_target_3_2["평일관람시작시각"]).dt.minute)[num]) / 60)
day_end.append(float(list(pd.to_datetime(df_target_3_2["평일관람종료시각"]).dt.hour)[num]) + float(list(pd.to_datetime(df_target_3_2["평일관람종료시각"]).dt.minute)[num]) / 60)
wk_start.append(float(list(pd.to_datetime(df_target_3_2["공휴일관람시작시각"]).dt.hour)[num]) + float(list(pd.to_datetime(df_target_3_2["공휴일관람시작시각"]).dt.minute)[num]) / 60)
wk_end.append(float(list(pd.to_datetime(df_target_3_2["공휴일관람종료시각"]).dt.hour)[num]) + float(list(pd.to_datetime(df_target_3_2["공휴일관람종료시각"]).dt.minute)[num]) / 60)- 해당 코드를 통해서 도서관 운영 시간을 확인했다.
- datetime_to기능을 통해서 시간 형태로 변경 후 오픈시간의 시간과 분을 마감 시간의 시간과 분에 빼서 float형태로 운영 시간이 확인되는 것을 확인하고
- 해당 코드를 for문을 통해 전체 데이터에 돌렸다.

- 그리고 23시간 이상 운영하는 경우 24시간 운영하는 것으로 데이터를 변경했다.
- 결과적으로 평일, 공휴일의 도서관 및 미술관의 운영시간을 확인
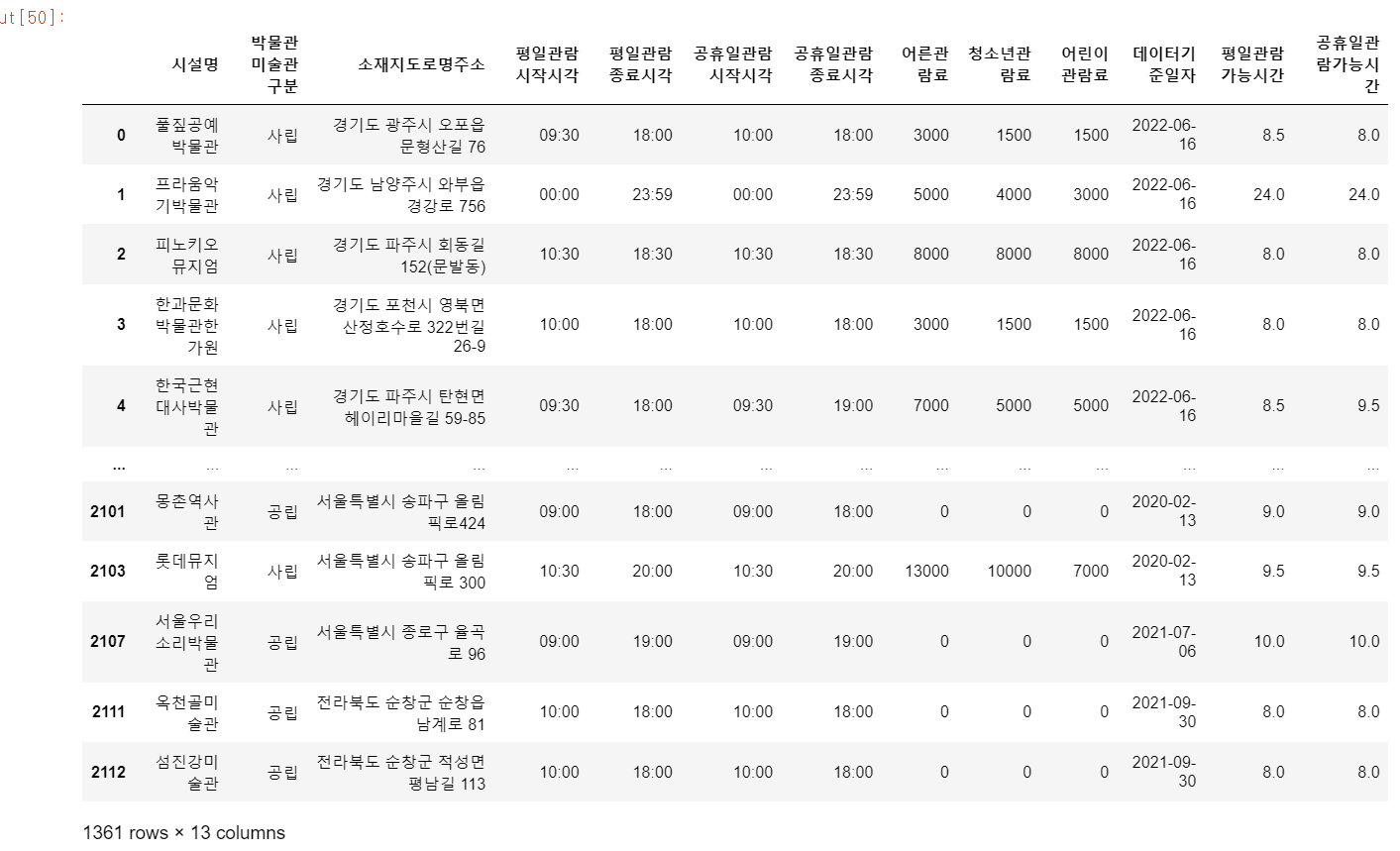
- 데이터프레임을 보면 정상적으로 평일, 공휴일 가능시간이 적혀있는 것을 볼 수 있다.
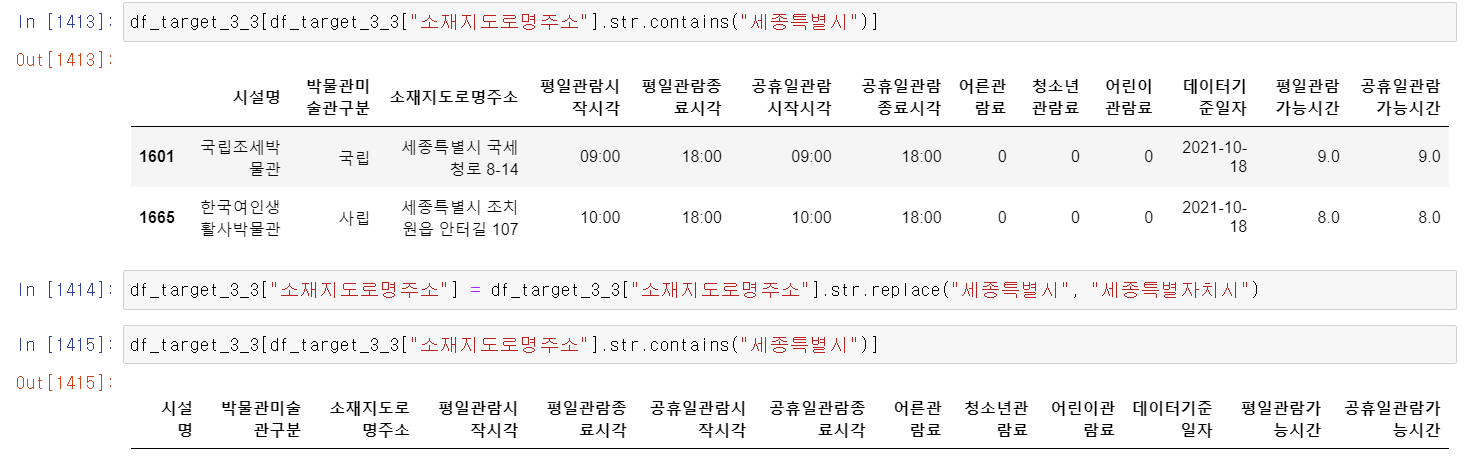
- 이제 도로명 주소를 통해 광역, 기초, 세부 3개의 주소로 나누는 식으로 데이터를 가공했다.
- 먼저 세종특별자치시의 경우 중간에 이름이 바뀜으로써 두 개의 이름이 있어서 하나의 이름을 통일하기 위해 세종특별시라고 적힌 데이터를 모두 세종특별자치시라고 바꿨다.
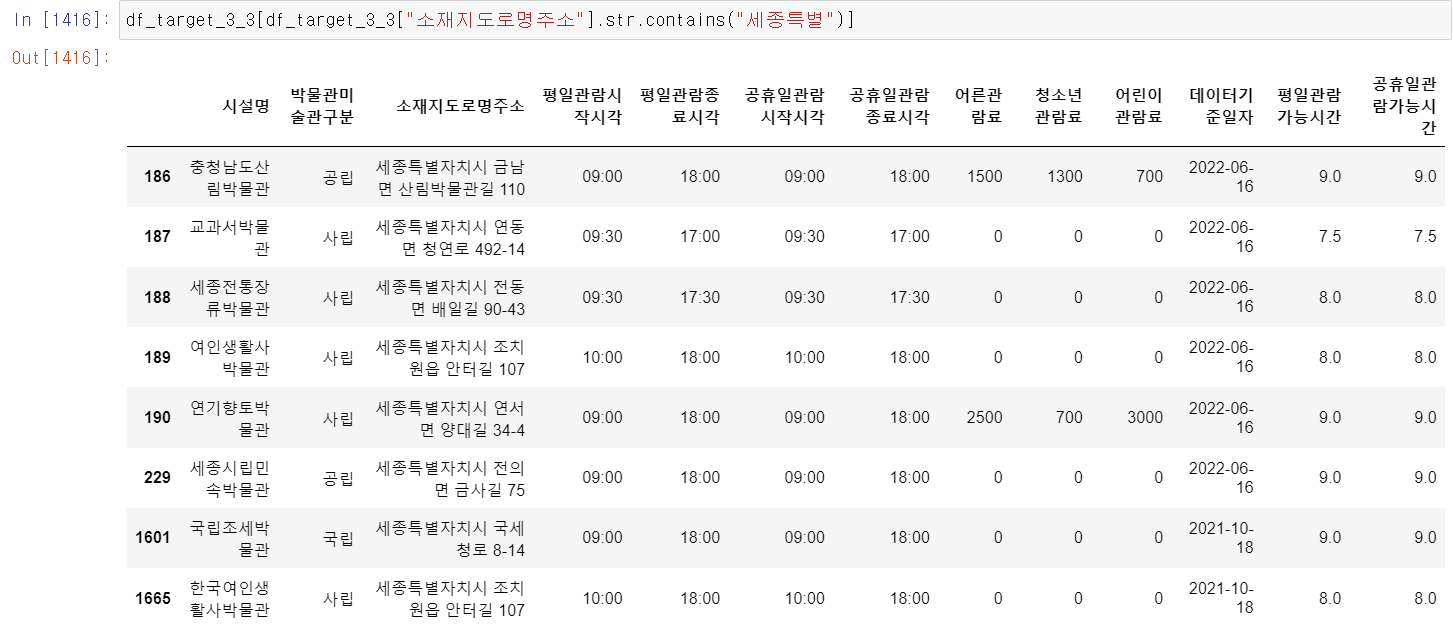
- 세종특별자치시에 정상적으로 8개의 데이터 변경된 것을 확인했다.

- 이제 도로명주소를 3개의 주소로 나누는데 사용한 코드다.
- 해당 주소들은 띄어쓰기로 구분되어 있기 때문에 split함수로 띄어쓰기로 구분 후 첫번 째 인덱스는 광역, 두번 째 인덱스는 기초, 나머지는 세부주소로 구분했다.
- 세종시의 경우 중간에 자꾸 데이터 값이 이상하거나, len숫자가 맞지 않아서 에러를 찾을려고 print(bug)로 에러 부분을 탐색했다.

- 이제 for문을 통해 구한 광역, 기초, 세부주소에 대한 각 리스트를 데이터프레임에 저장했다.
- 그리고 각 데이터의 양끝에 공백이 있을 경우 불필요한 용량을 쓰기 때문에 공백을 제거했다

- 이제 가공한 데이터로 결과값을 확인해봤다.
- 가장 먼저 groupby로 광역시별 도서관 및 미술관의 수를 확인했다.
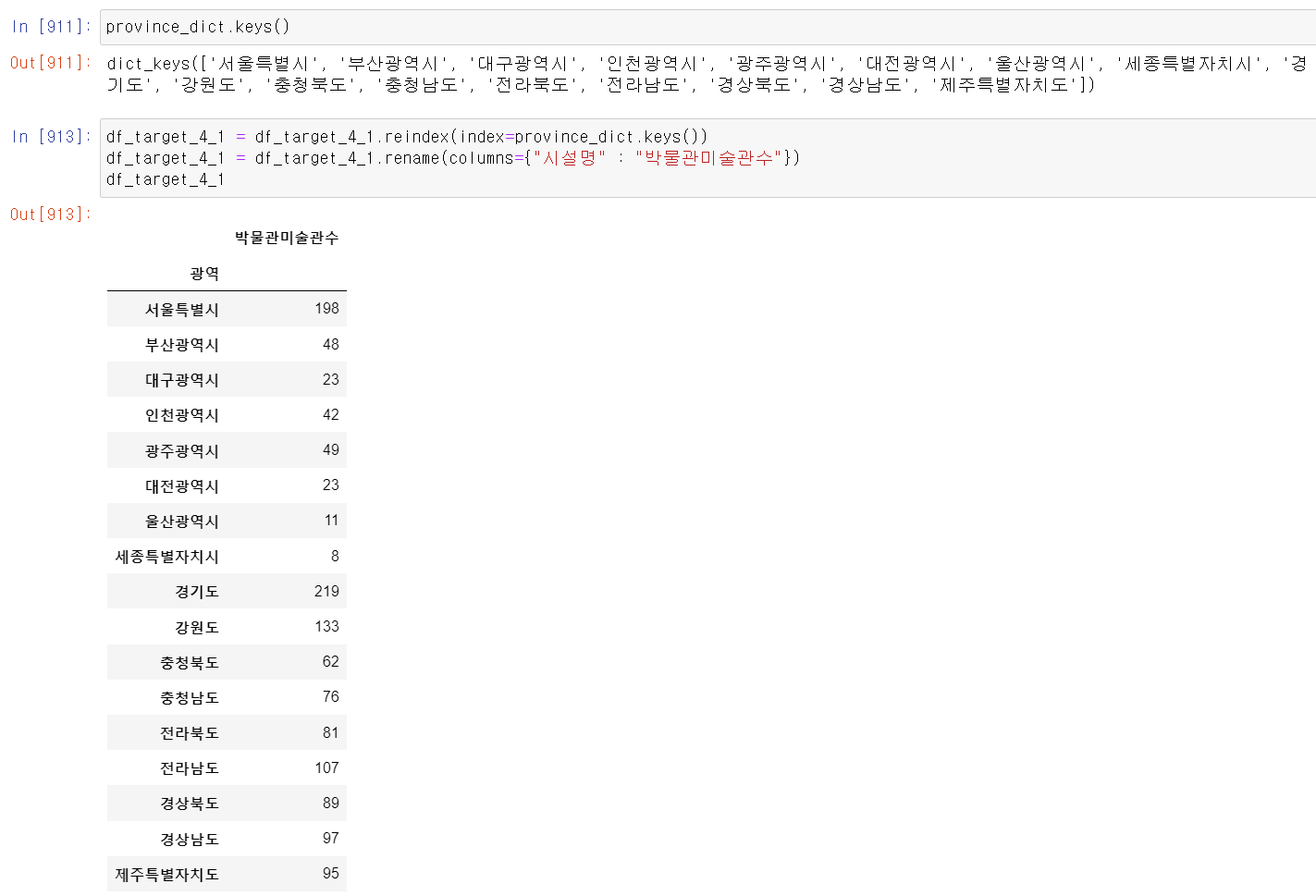
- 이제 가독성을 높이기 위해 광역시별 순서를 만든 Dict데이터의 key값을 기준을 index의 순서를 변경했다.
- reindex 기능을 사용했는데, index에 넣은 값을 기준으로 index의 순서를 바꿔준다.
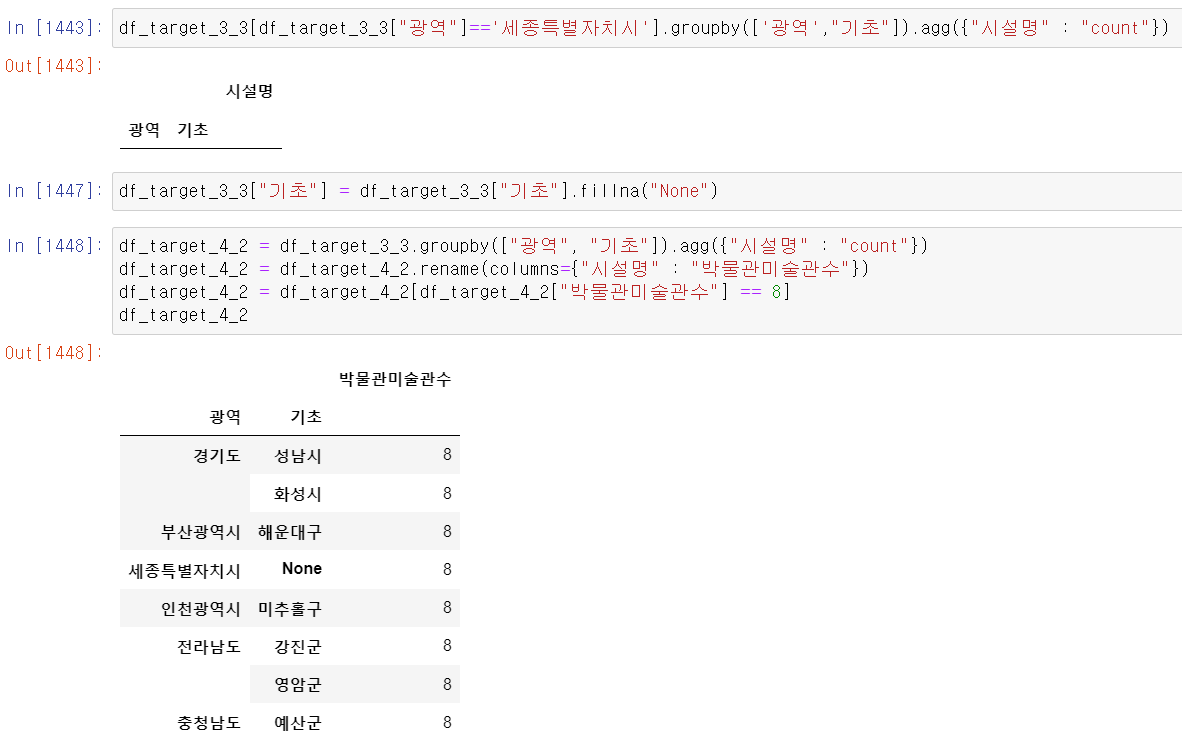
- 이번에는 기초 주소까지 포함해서 데이터를 뽑았는데 임의로 8개 박물관 및 미술관을 소유한 기초자치단체를 검색했다.
- 먼저 groupby와 조건을 통해 기초자치 중 8개의 시설을 가진 데이터만 뽑았다.
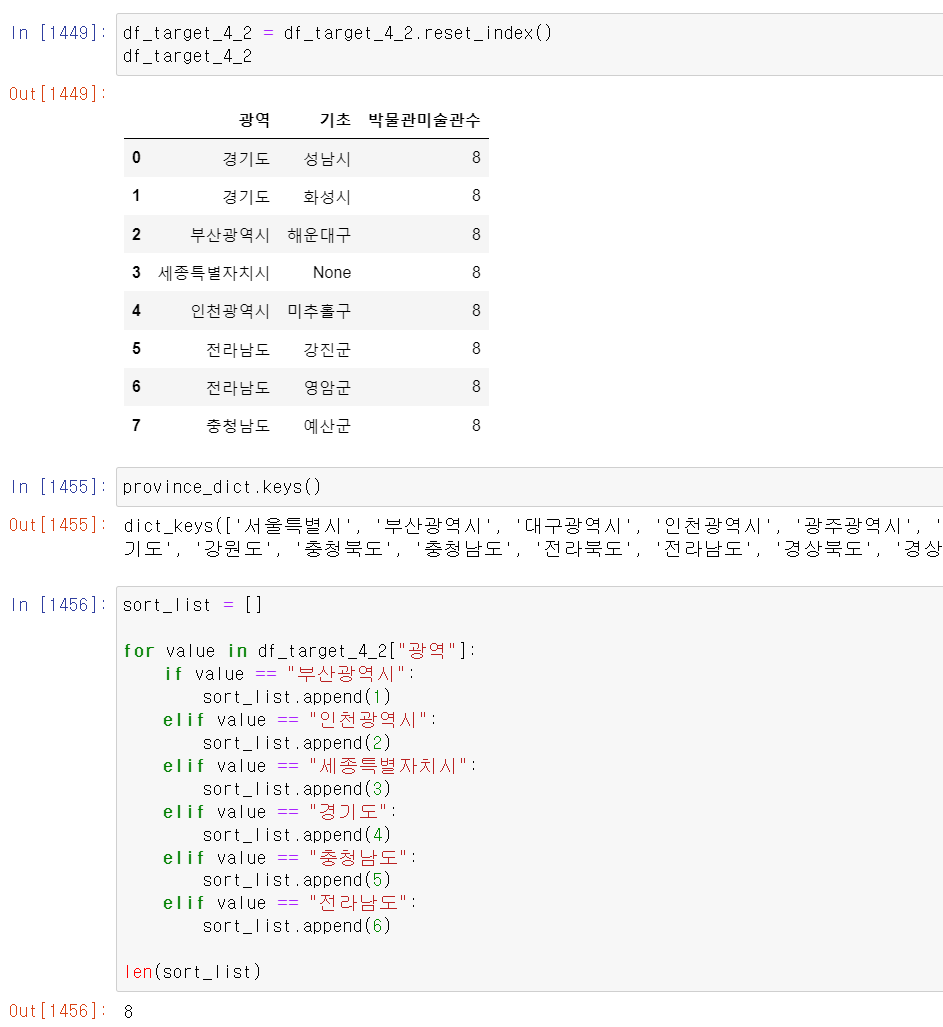
- 이후 인덱스의 순서를 바꾸기 위해서 reset_index으로 기존의 index를 컬럼으로 변경 후
- 광역시 순서별로 정렬하기 위해 sort_list라는 빈 list데이트를 만들고
- 광역 컬럼을 for문을 돌려서 광역시별 순서대로 숫자를 넣었다.
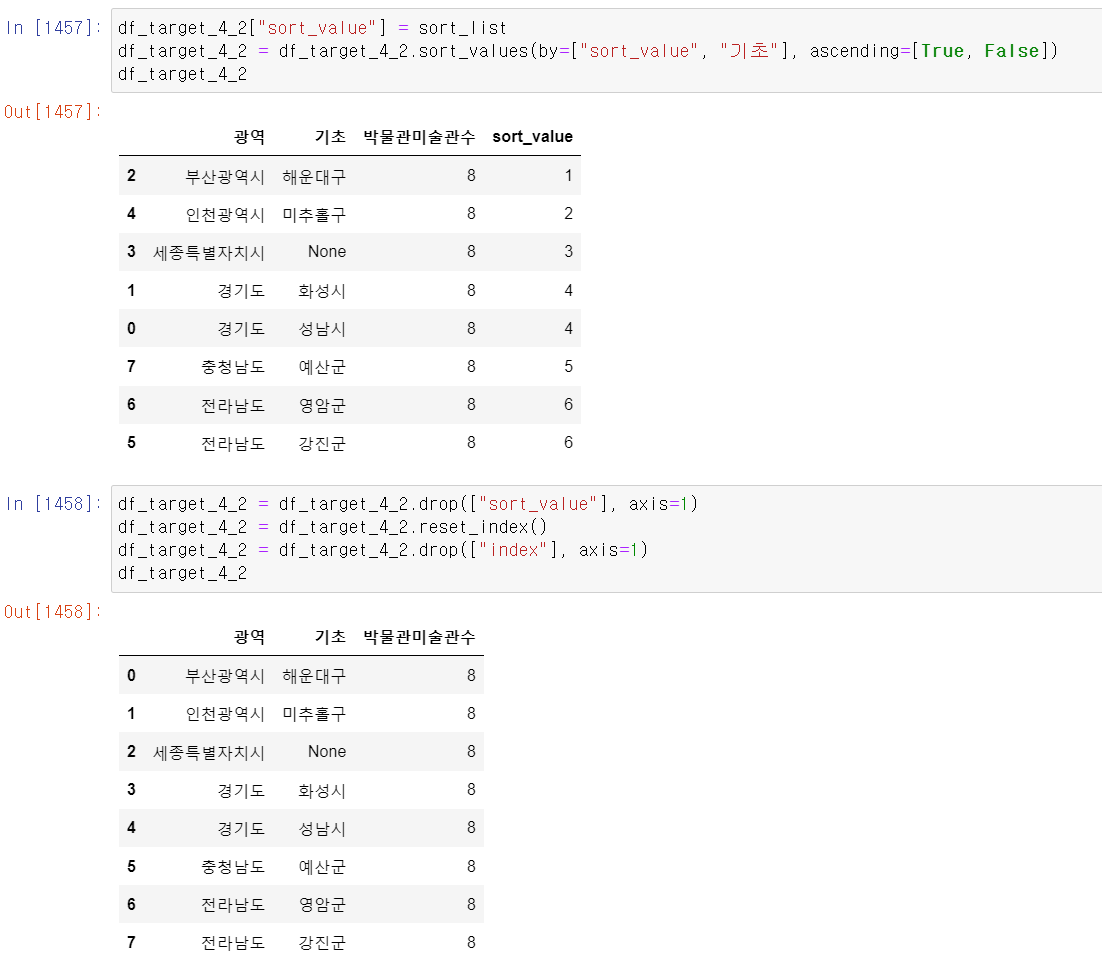
- 만든 sort_value리스트를 컬럼에 넣고 해당 컬럼을 기준을 정렬 후, 두번 째로 광역이 같은 경우 기초자치단체를 역순으로 정렬해서 데이터를 총 2번 정렬했다.
- 그리고 정렬을 위해 만든 sort_value는 뺐다.

- 다음으로는 특정 데이터를 뽑아봤는데, 운영시간 및 제주도, 요금 모두 고려했다.
- 임의로 어른 2명, 청소년과 아이 4명이서 간다는 가정하에 price컬럼을 만들었다.
- 또한, 미술관을 의미하는 갤러리, 미술관, 아트 등이 들어가는 데이터만 출력되도록 조건을 걸고, 요금은 2만 원이하, 공휴일 운영 가능 시간은 4시간 이상 등 다양한 조건으로 탐색했다.
- 제주도 조건을 제외한 데이터는 꽤 나왔는데,
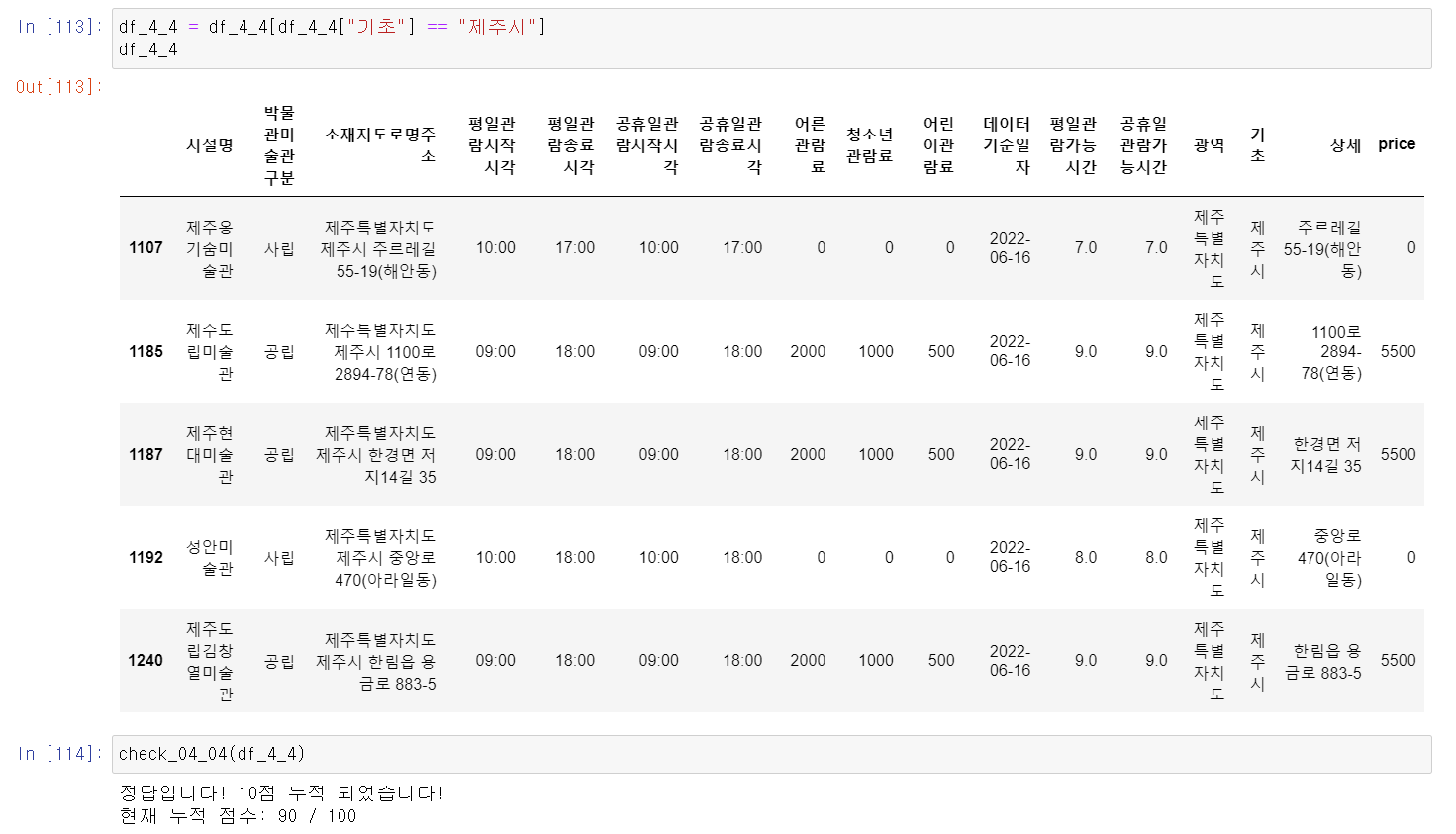
- 제주시를 조건을 걸자 많이 나오지는 않았다. 나도 제주도 가고 싶다...!

상황을 바꿀 수 없다면, 나를 바꾸자