
- 이번에는 서울시 흡연 자료를 바탕으로 데이터 전처리 과정을 가져보자
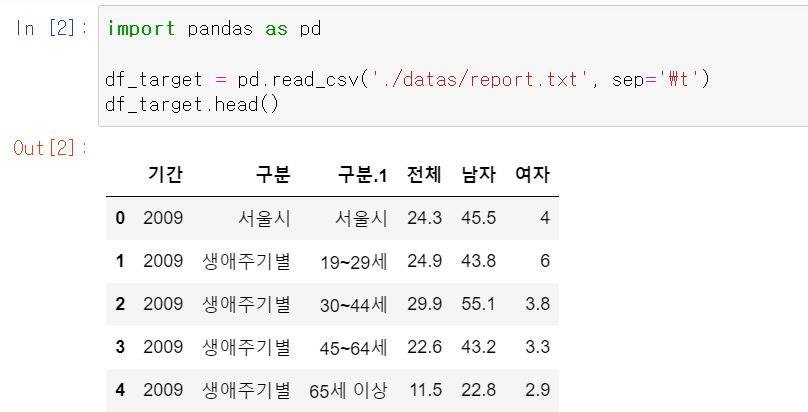
- 기본 데이터 프레임의 위와 같으며, 구분1과 구분2에 따라 데이터의 수치가 집계되어 있다.
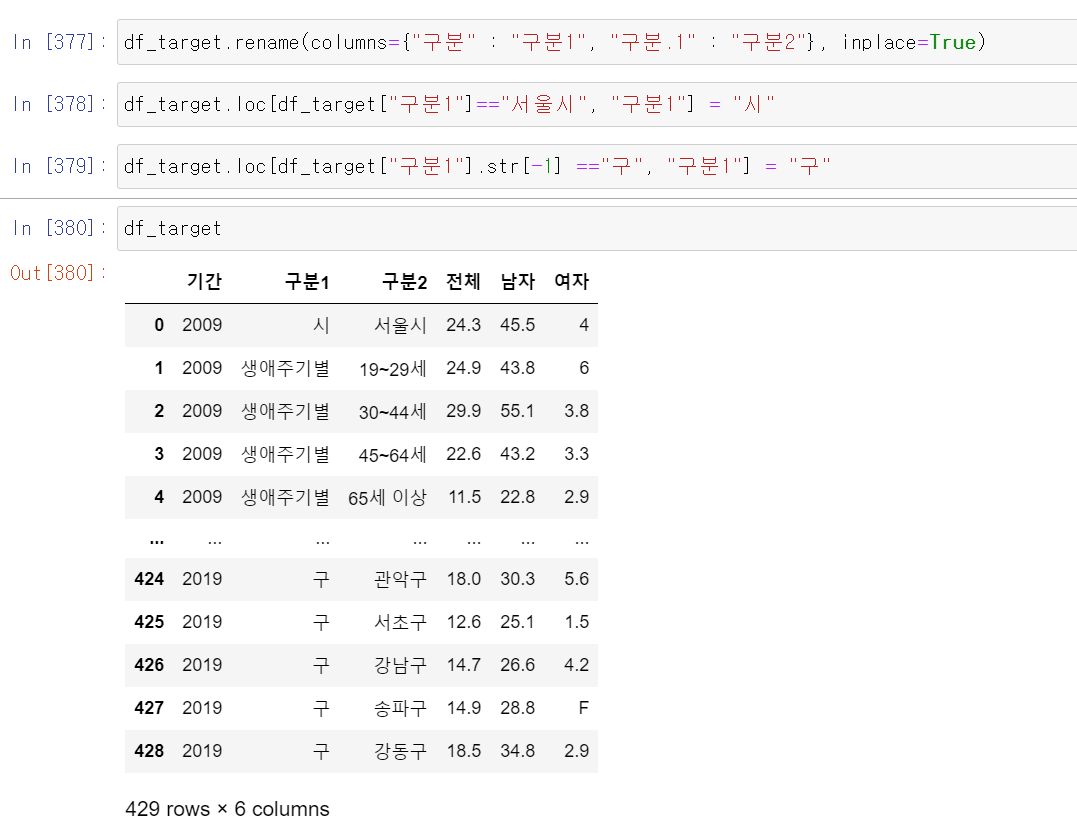
- 일단 보기 편하게 데이터프레임의 이름을 바꾸고, 시 단위의 경우 서울시밖에 없기 때문에 '시'로 바꿔주고 구분1에서 **"구"라고 적힌 모든 데이터는 '구'로 바꿔줬다.
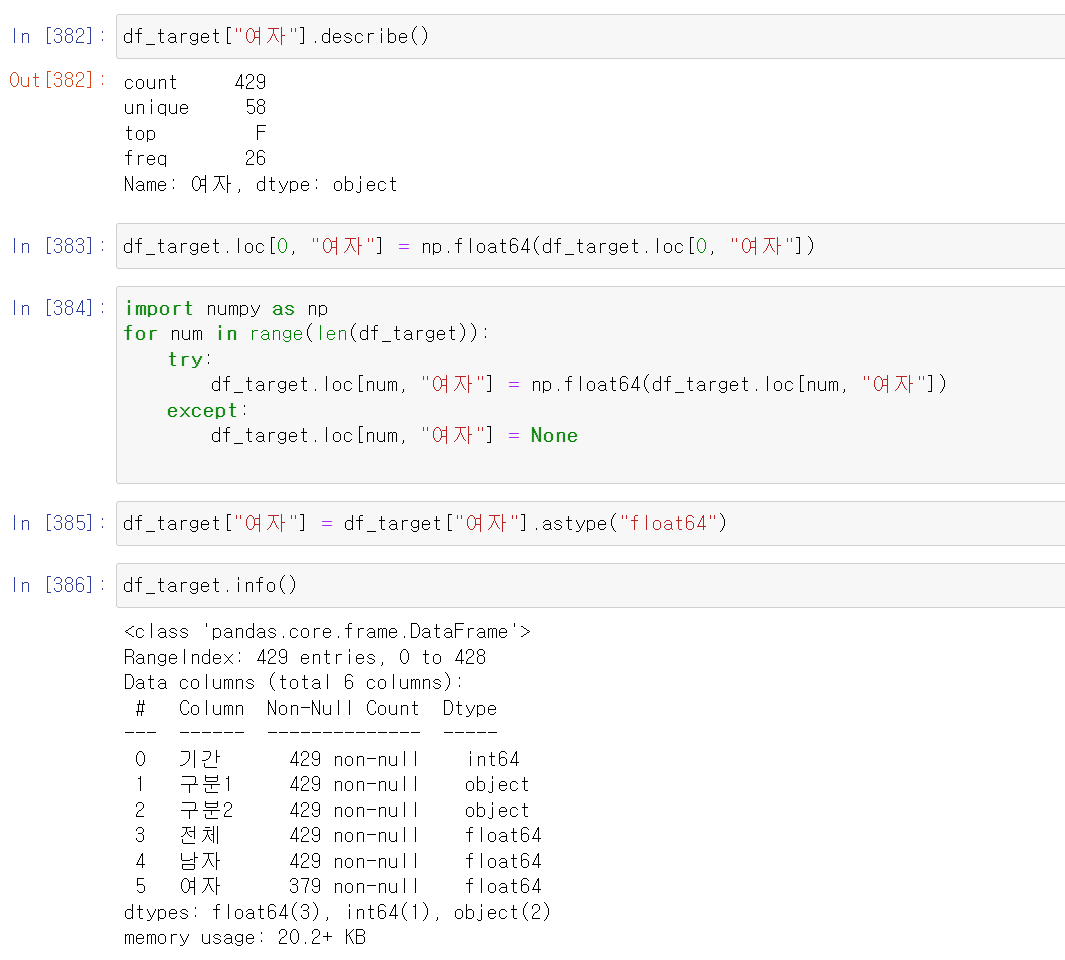
- 문제는 여자 컬럼의 데이터 중 수치가 아닌 'F'로 적힌 데이터가 많다.
- 그리고 데이터 type이 object이기 때문에 먼저 numpy를 사용해서 float형태로 한 인덱스씩 바꿔주고, 만약에 'F'자료가 나와서 에러가 발생할 경우 None을 넣어줘서 집계 시 문제가 없도록 만들었다.
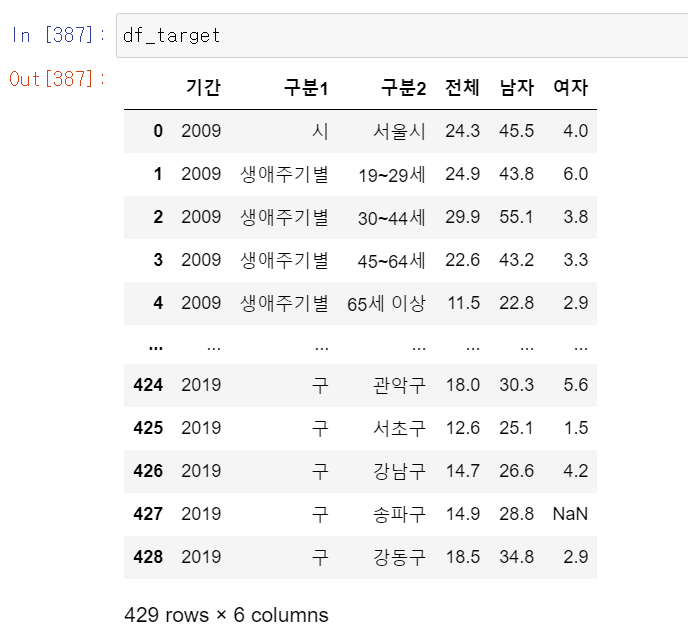
- NaN값도 정상적으로 들어갔고, 컬럼명도 가독성 좋게 만들어졌다.
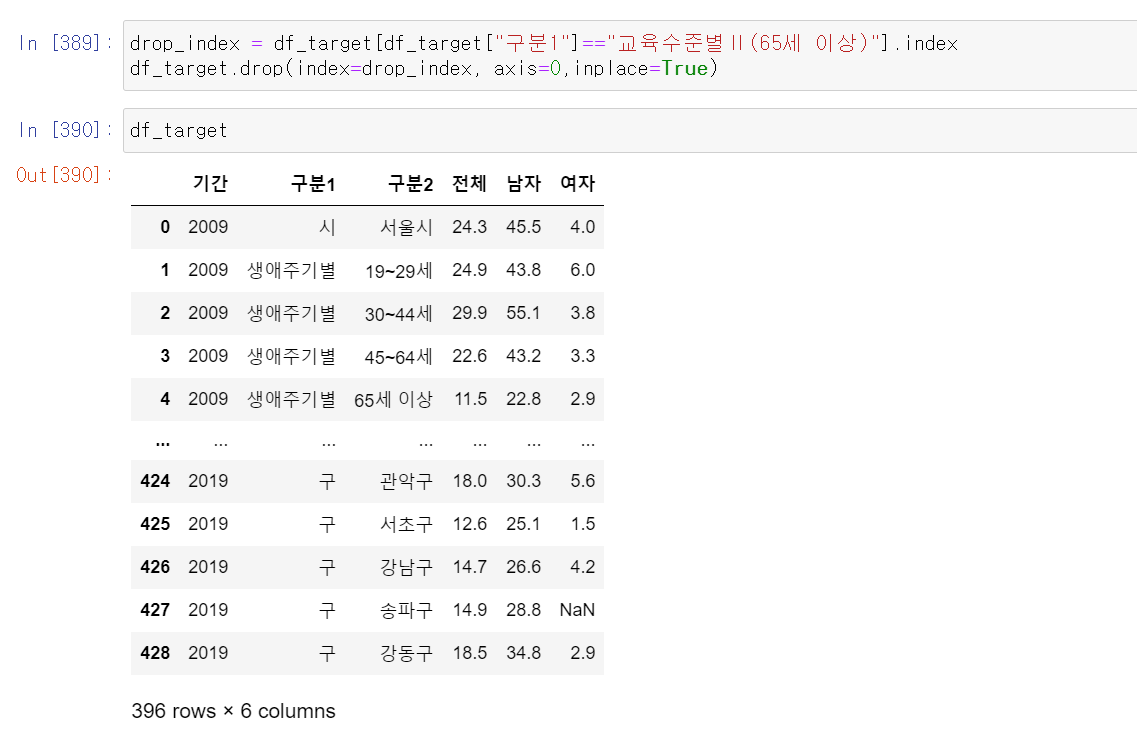
- 65세 이상 인덳의 데이터는 Nan값이 너무 많아서 분석이 어렵기 때문에 조건을 통해 index번호를 찾고, 해당 인덱스의 데이터를 모두 삭제했다.
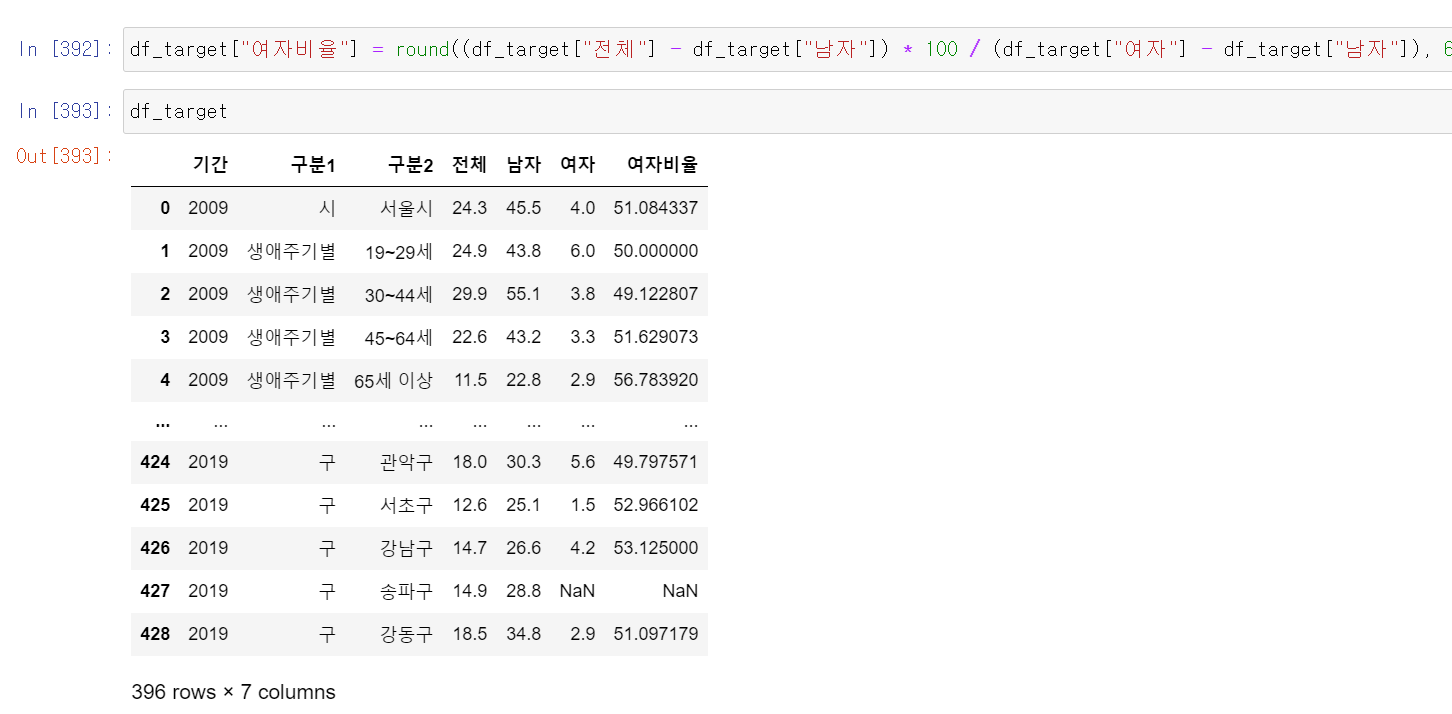
- 이제 여성의 흡연 NaN값을 유추하기 위해 작업을 시작했다.
- 가장 먼저 전체 흡연율 중 여성의 흡연율을 계산했다.
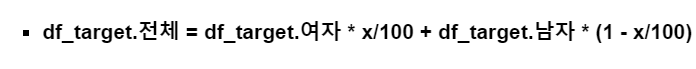
- 여기서 값이 여성의 비율이기에 방정식을 통해 여성의 비율을 찾았다.

- 이제 NaN값을 채우기 위해 먼저 NaN값이 있는 구분2의 고유값을 찾았다.
- 보통 구 단위의 구분2에서 여자 데이터 Nan값이 많이 있었다.
- 이제 NaN값이 없는 데이터의 기간과 여성비율을 뽑았다.

- NaN값이 있는 구분2의 데이터를 기준으로 NaN값이 없는 데이터로
- 일차 단순회귀계수(), MinMax, 평균, 표준편차를 구했다.

- NaN_gu는 아까 구한 NaN값이 있는 구분2의 고유값이며, 밑에 for반복문은 위에서 구한 공식을 넣어서 구했다.
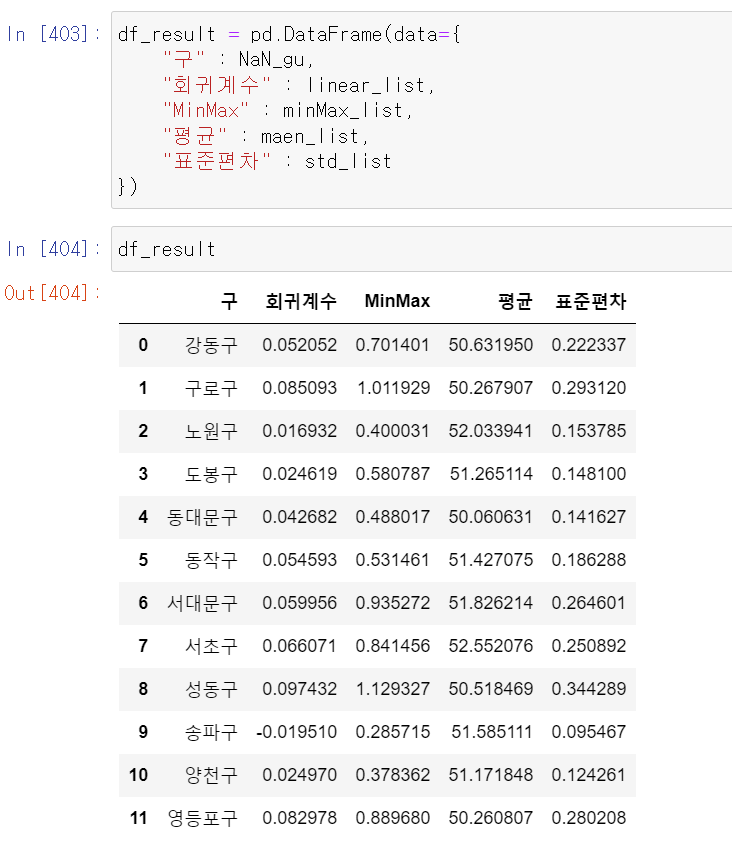
- 이제 NaN값이 있는 구분2의 데이터의 각 값들을 구했는데,
- 특징이 표준편차의 값이 크지 않다. 이는 중심으로부터 값들의 분포가 크지 않아 정규분포 모양에 근사하는 것 같다고 추측할 수 있고, 회귀계수 또한 매년 0.08값을 넘는 수치가 없다.
- 그렇기 때문에 NaN값을 평균으로 넣어도 데이터 분석에 큰 무리가 없을 것 같다고 생각했다.

- 이제 여자비율에 NaN값에 구한 평균을 넣어보자
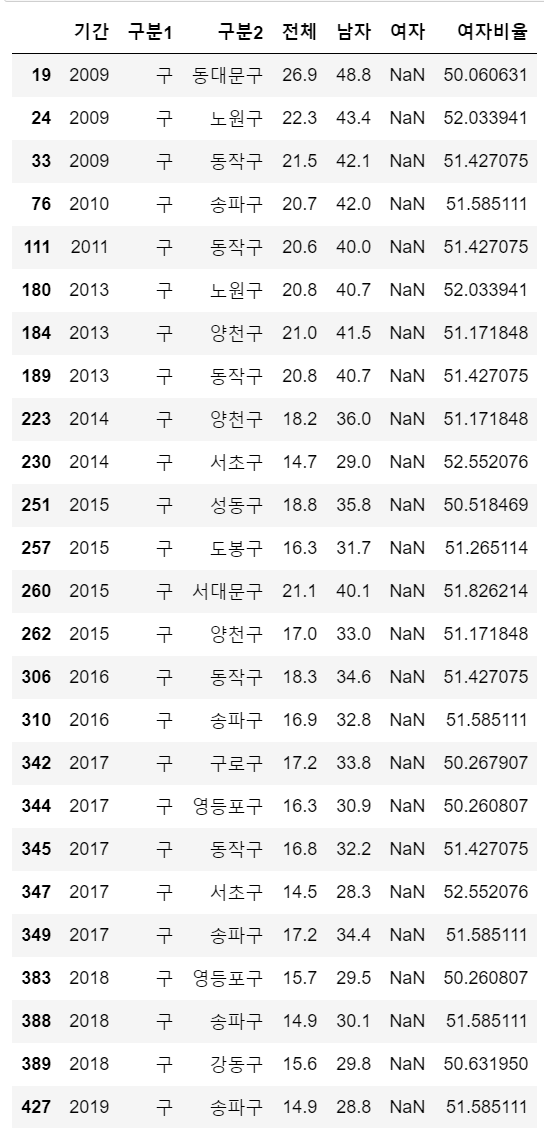
- 이전에 여자비율을 구할 때 여자 컬럼의 값이 NaN인 경우 여성비율을 구하지 못했지만, 평균을 넣어서 여자비율 컬럼의 NaN을 모두 채웠다.
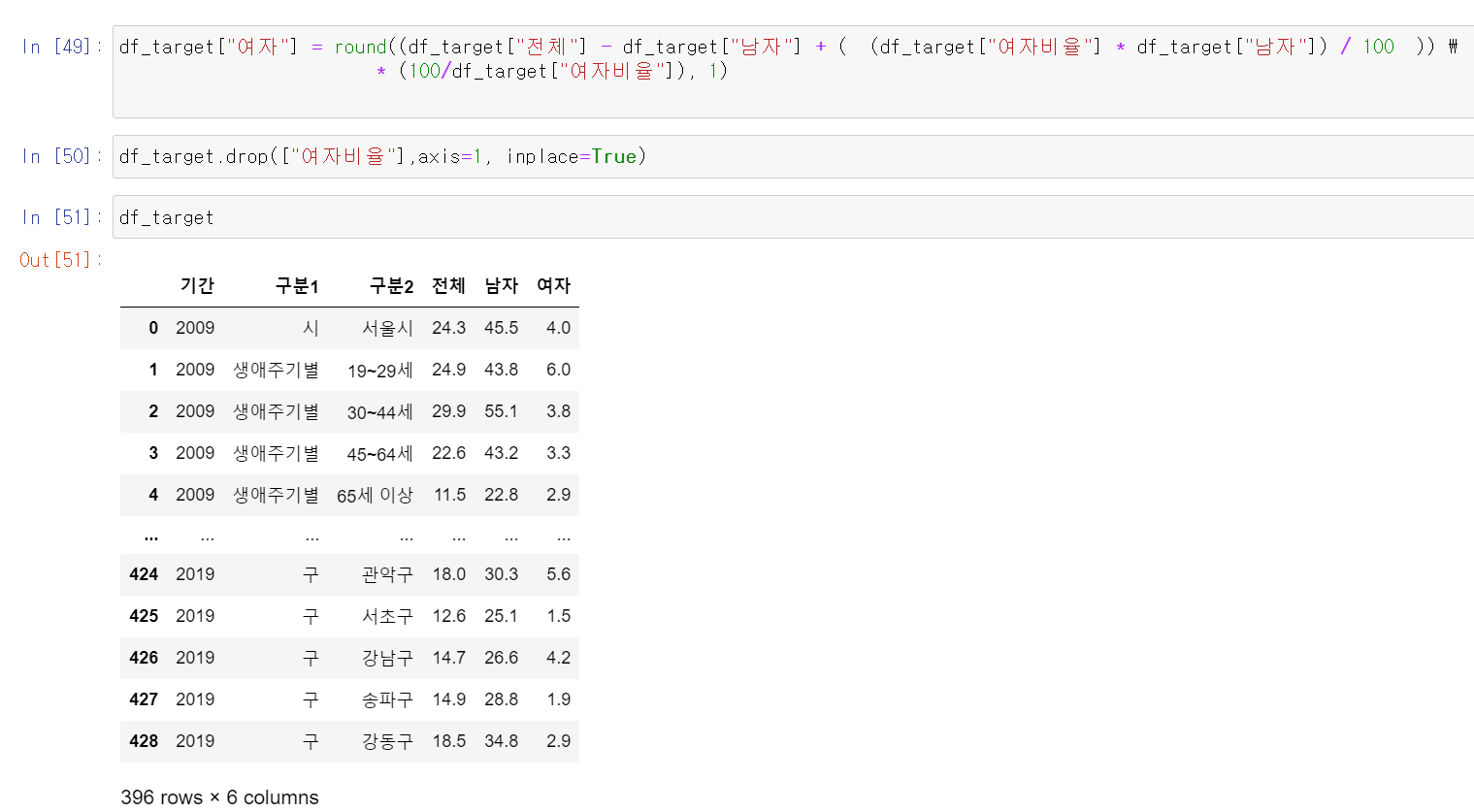
- 이제 구한 여자 비율을 통해 여자의 값을 넣어보자
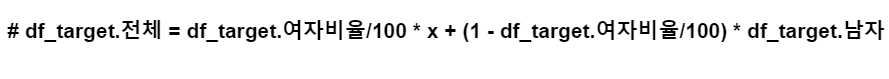
- 여기서 값이 여자 데이터이기 때문에 방정식을 풀어서 계산하며 여자 컬럼의 데이터를 확인할 수 있다.

- 이제 구분2를 기준으로 기간에 따라 전체, 남자, 여자의 데이터 어떻게 변하는지 분석해보자

- 먼저 알아본 것은 단조 증가 및 단조 감소의 유무를 파악한 것이다.
- 구분2별 기간의 데이터를 행렬로 데이터를 뽑고, 해당 데이터를 오름차순, 내림차순으로 정렬한 데이터와 비교했을 때 True값이 나오면 단조적으로 증가하거나, 단조적으로 감소한 것이라고 판단할 수 있다.

- 이제 해당 방법을 for문을 돌려서 36개의 인덱스를 기준으로 단조적으로 증가했는지, 단조적으로 감소했는지 파악했다.
- 위 코드를 통해 전체, 남자, 여자 모두 알아봤다.
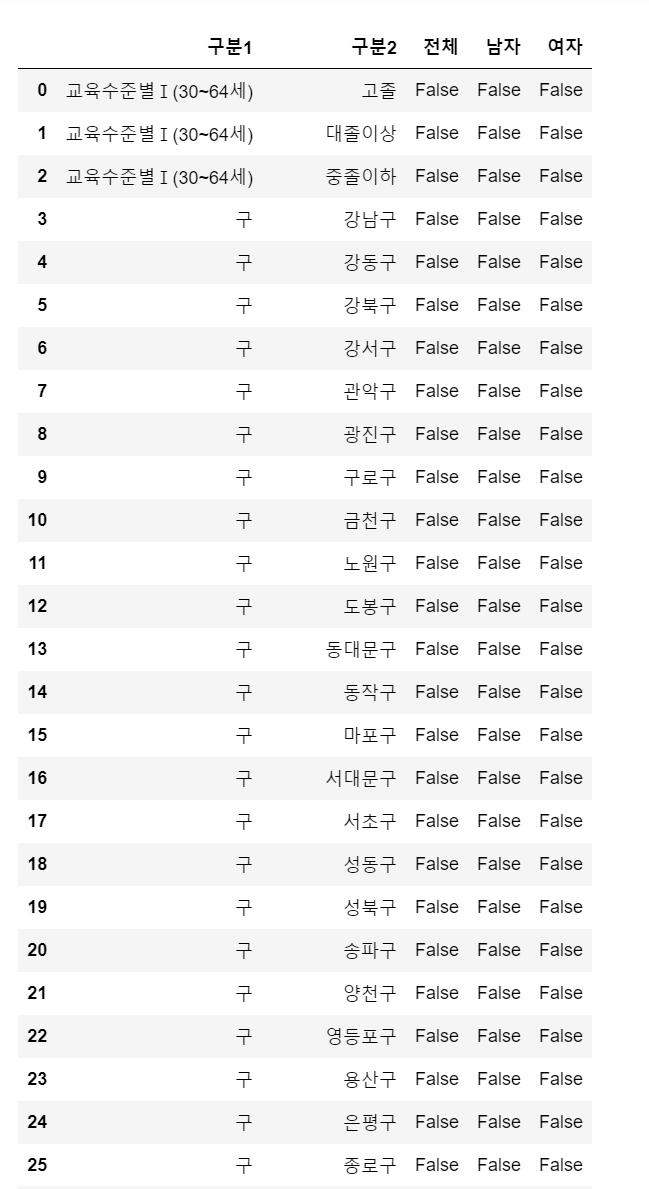
- 검색 결과 모든 데이터가 단조적으로 변화한 경우는 없다
- 전체, 여자, 남자 데이터 모두 올라가면서 내려가거나, 내려가면서 올라가고 데이터의 변화가 있었다.
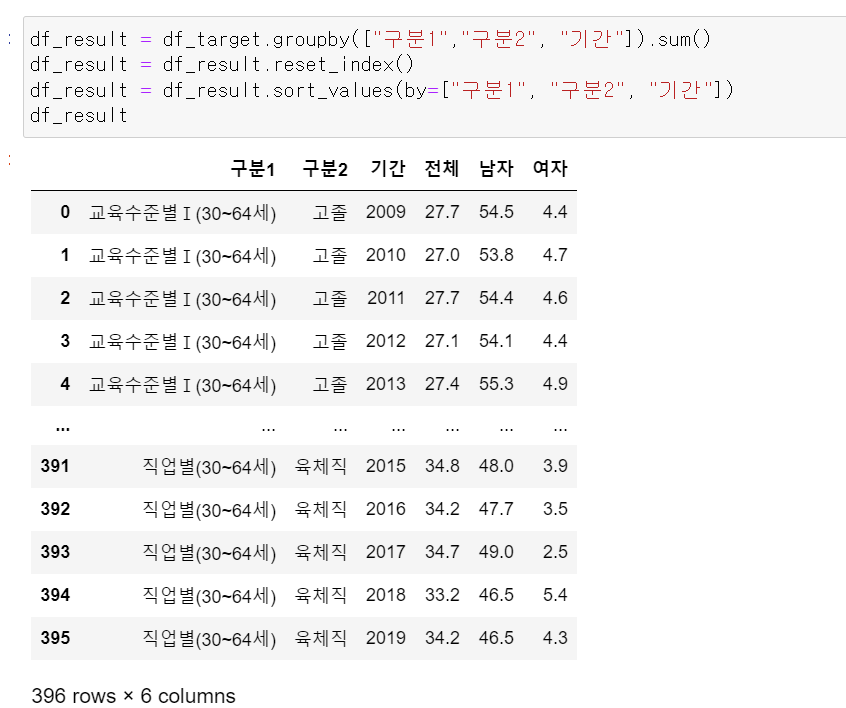
- 이제 위에서 뽑은 groupby데이터를 다시 확인해보고

- 기간을 축에 넣고, 여자, 남자, 전체 데이터를 축에 넣어 기간에 따른 데이터의 회귀계수의 기울기 값을 구했다.

- 이제 위 방법을 for문을 돌려서 데이터의 기간에 따른 데이터 변화에 대한 기울기를 구했다.
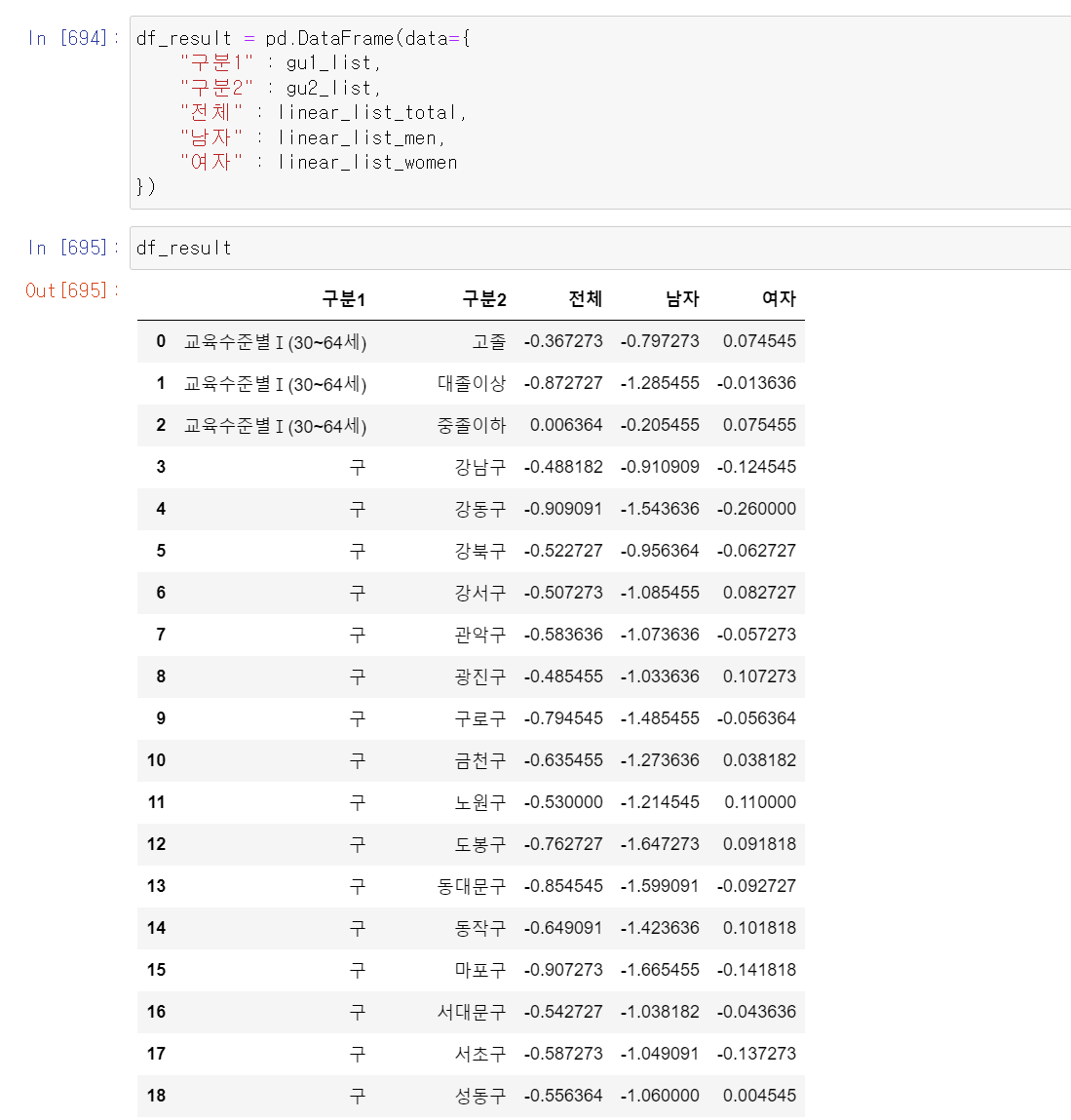
- 이제 구한 데이터를 프레임형태로 만들었다.
- 기간에 따라 전체적으로 감소한 데이터도, 상승한 데이터도 있다.

- 이제 기울기에 대한 max값과 min값도 구해봤다.
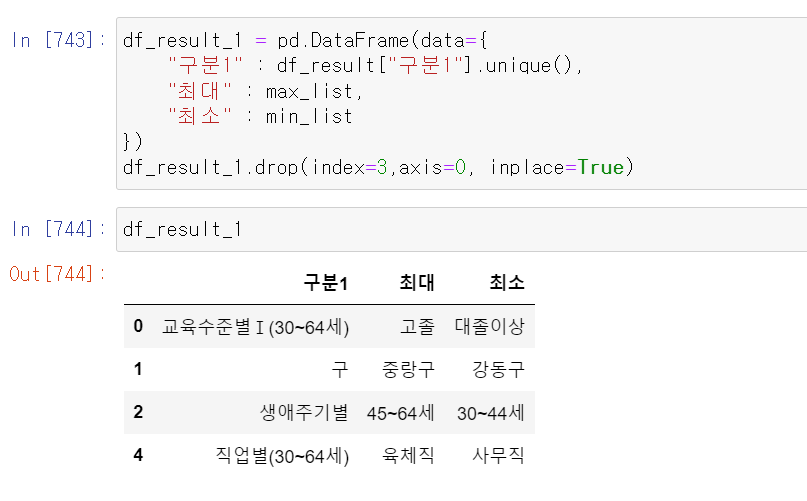
- 기울기의 계수가 가장 높은 구분2의 데이터와 최소 구분2의 데이터를 뽑아 봤을 때 위와 같이 나왔다.
- 현재 금융 데이터를 통한 머신러닝 프로젝트를 진행하고 있는데, feature 연구가 정말 중요한 것 같다.
- 똑같은 데이터를 가지고도, 다양한 방법을 통해 여러 측면에서 분석할 수 있으며, 단순히 주어진 feature만 사용하는 것이 아니라 응용하고 창의적으로 생각하는 것이 정말 중요한 것 같다.

상황을 바꿀 수 없다면, 나를 바꾸자