
- 이번에는 자연어 머신러닝을 통해 그림에 자연어를 넣는 wordCloud작업을 해보자
- 먼저 사용할 text파일을 불러온다.
- 그리고 많이 사용되지만 큰 의미가 없는 단어를 stopword로 지정하고,
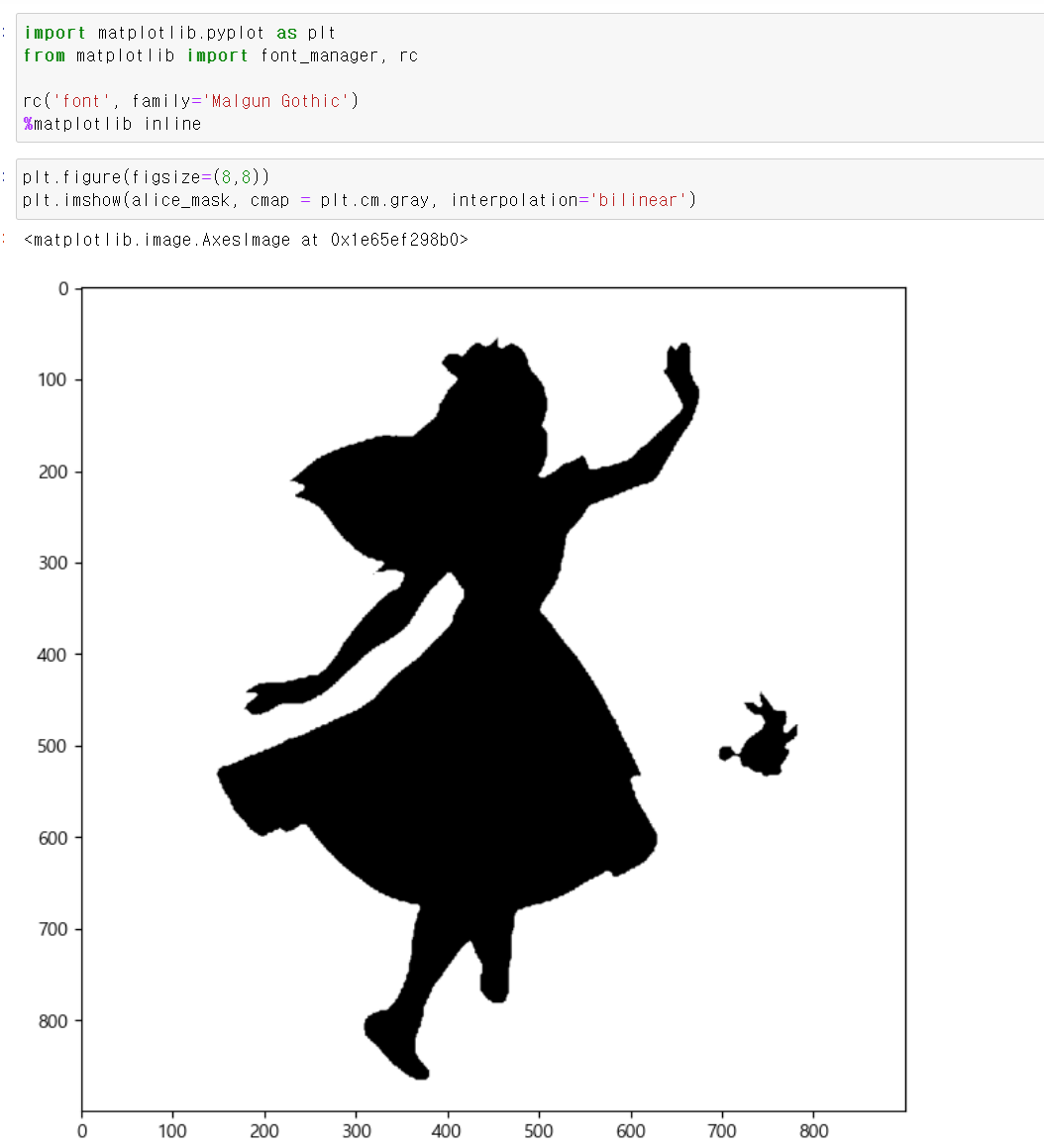
- 사용할 그림 파일을 불러온다.
- 해당 그림은 이상한 나라의 엘리스 그림이다.
- matplotlib.pyplot의 imshow(image show)를 사용하면 간단하게 할 수 있다.
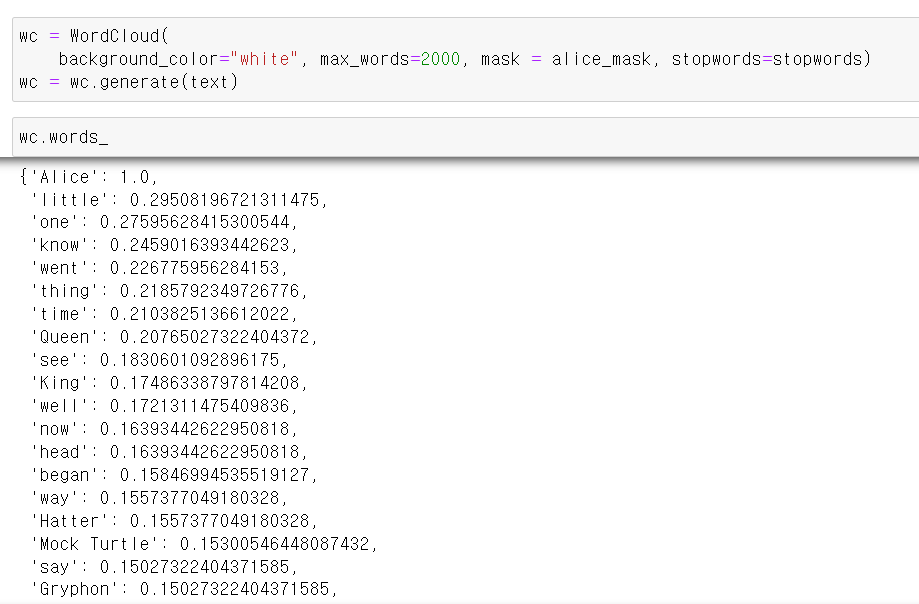
- 이제 아까 불러온 텍스트에서 각 단어 뭉치에 따른 사용 빈도를 분석한다.

- 이제 해당 데이터를 plt로 그려주면 wordcloud가 완성된다.
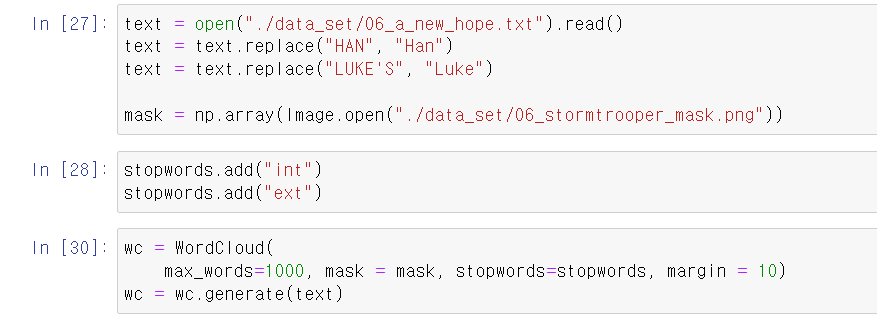
- 이제 다음 wordcloud를 해보자
- 아까와 같은 과정을 거치면 된다. 먼저 stopword를 추가해주고, 그림을 numpy의 행렬 형태로 변환한다.
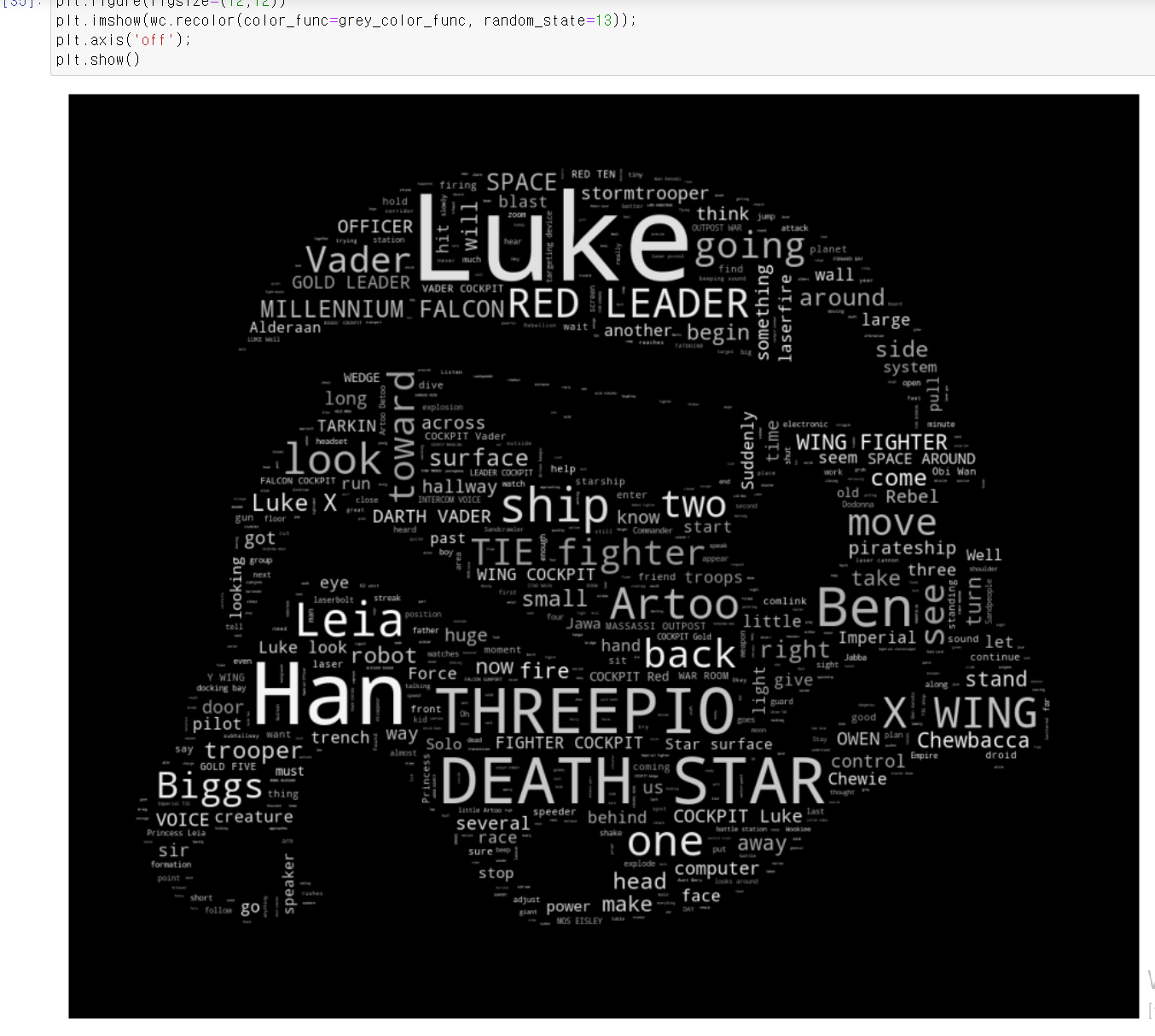
- 해당 데이터를 똑같이 imshow에 매소드에 넣고 실행하면 이렇게 wordcloud가 완성된다.
- 이제 한국어를 통한 wordcloud을 실행해보자
- 먼저 konlpy에서 법령에 대한 데이터 텍스를 불러온다.
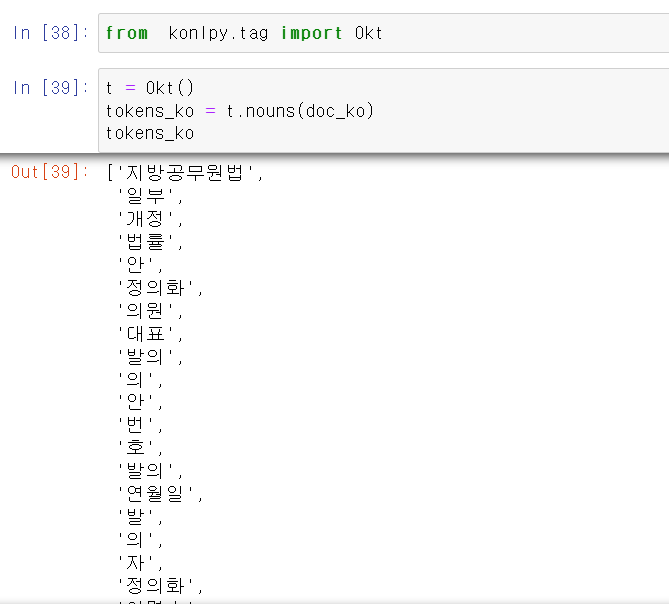
- 불러온 텍스트 데이터를 OKt를 통해 명사별로 구분해서 만들고
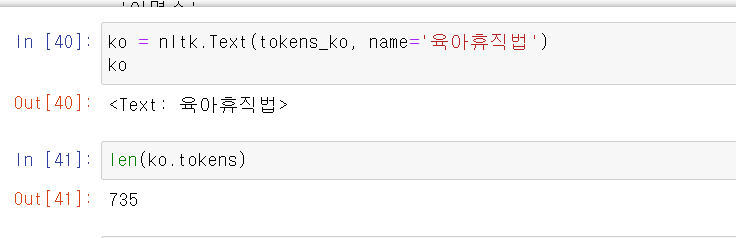
- 구분한 데이터를 가공하기 쉽게 nltk로 변환해준다. 해당 법령의 총 말뭉치는 735개이다.
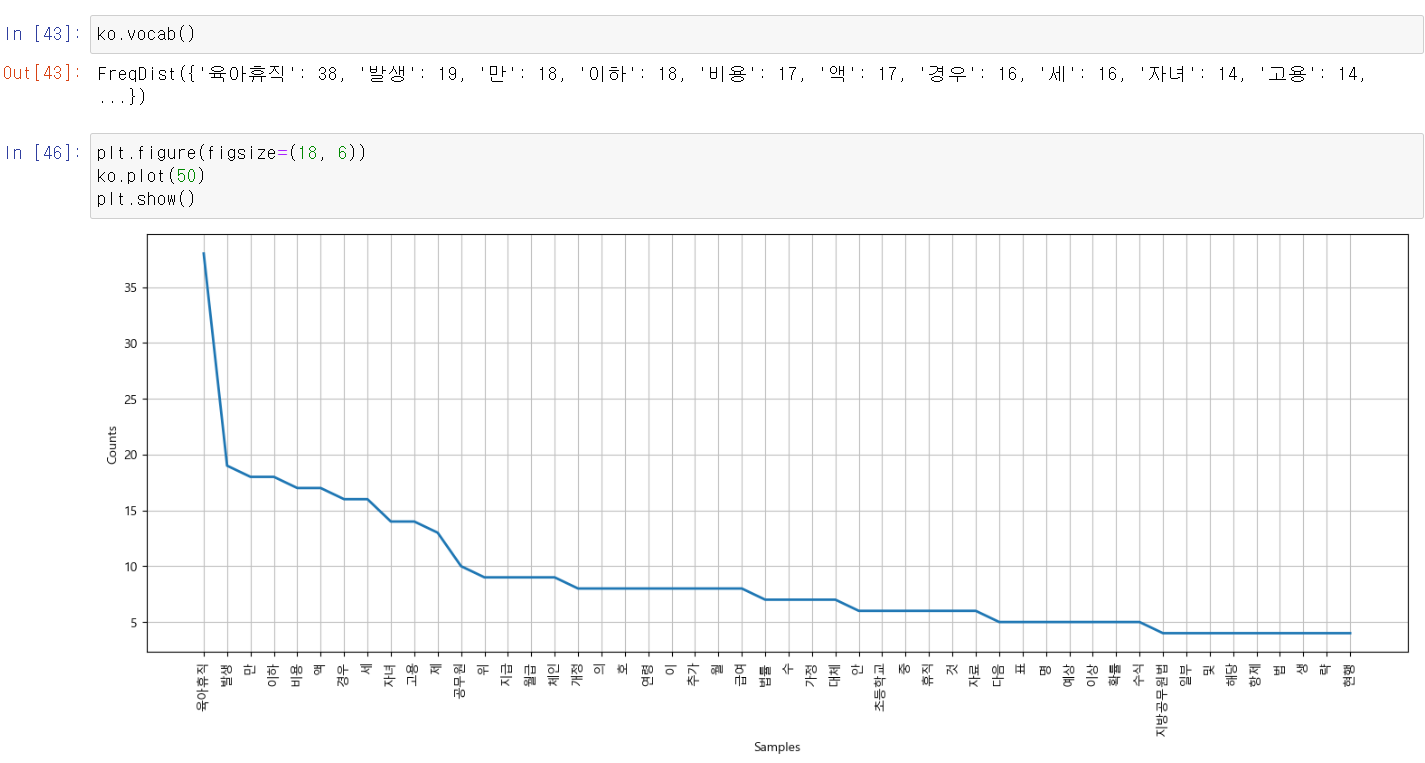
- 그래프를 통해 확인해보니 상위 50개 빈도의 사용된 말뭉치들이다.

- 이제 해당 말뭉치들을 wordcloud로 그리기 위해 WordCloud모듈을 사용해서 변환해주고 그려주면 된다.

- 이제 자연어를 머신러닝에 교육해서 감정분석을 해보자
- 먼저 train변수에 교육시킬 4개의 문장을 만들고,
- all_word에 4문장에 사용된 고유 말뭉치를 뽑아준다.
- 해당 코드는 먼저 train의 첫번째 튜플을 뽑고, 첫번째 튜플의 첫번째 인덱스 즉 'i like you'를 각 단어별로 구분해서 word에 담은 후 set를 통해 고유값만 뽑은 것이다.
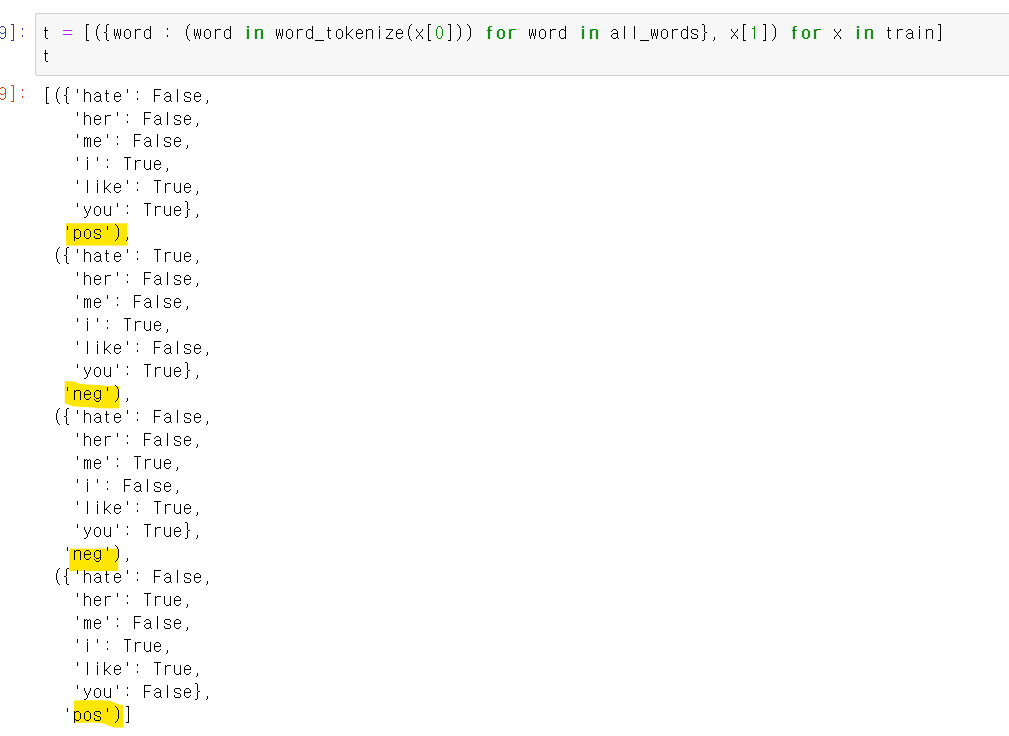
- 이제 train데이터에서 두번 열 즉 pos, neg를 label로 주고, 한 문장의 단어들이 말뭉치 데이터 셋에서 무엇이 있는지 T/F값으로 준다.
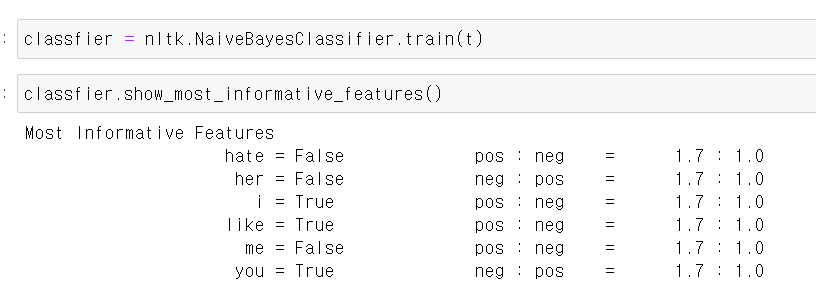
- 이제 해당 자료를 naive bayesd모듈에 넣고 교육시킨 결과
- 각 단어에 따라 pos(positive)인지, neg(negetive)인지 구분하는 결과가 나온다.
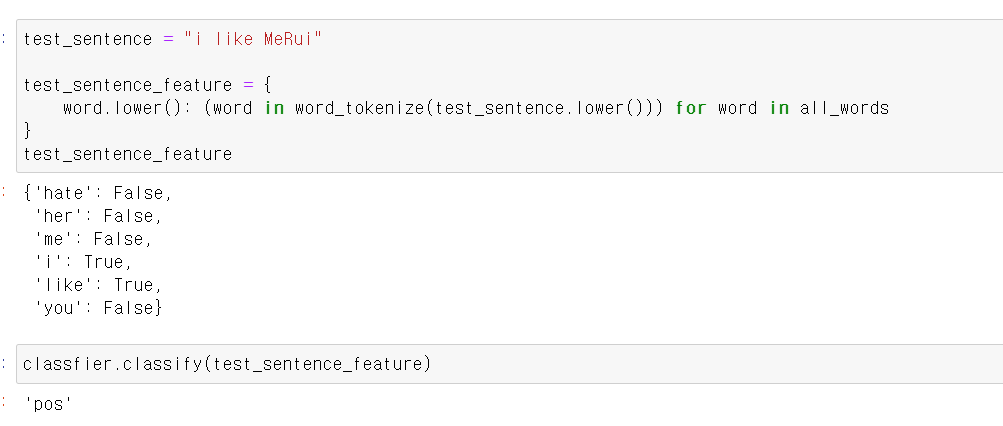
- 이제 모델링일 넣은 테스트 문장을 모델링에 넣을 형태로 만든 후
- 만드는 방법은 심플하다.
- 먼저 all_word에서 각 고유 말뭉치를 for문으로 불러온 후 테스트 문장에서 각 말뭉치를 불러와서 고유 말뭉치에 있는지 없는지를 T/F값으로 변환해준다.
- 이제 모델링에 넣어보니 pos로 원하는 값이 나왔다.
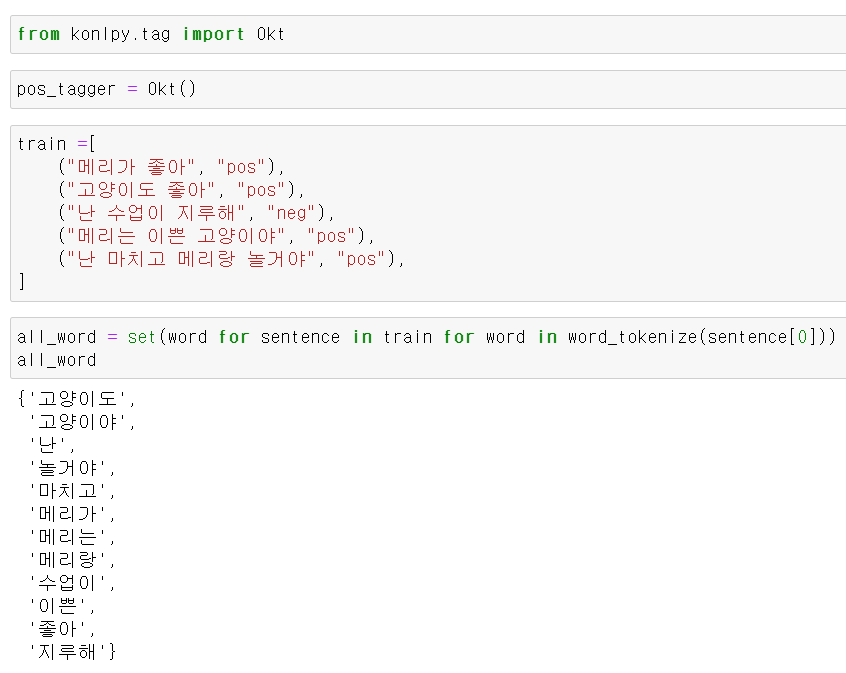
- 이제 한국어로 모델링을 시켜보자
- 먼저 4개의 교육용 문자를 만들고, 문장들의 고유값을 추출했다.
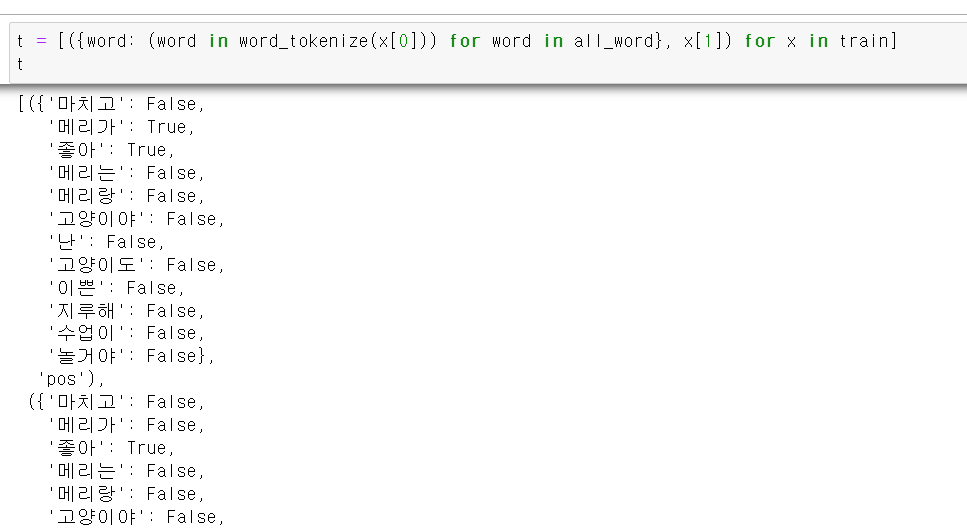
- 이제 교육시키기 위해 각 pos, neg에 구분하는 말뭉치의 T/F을 만들고
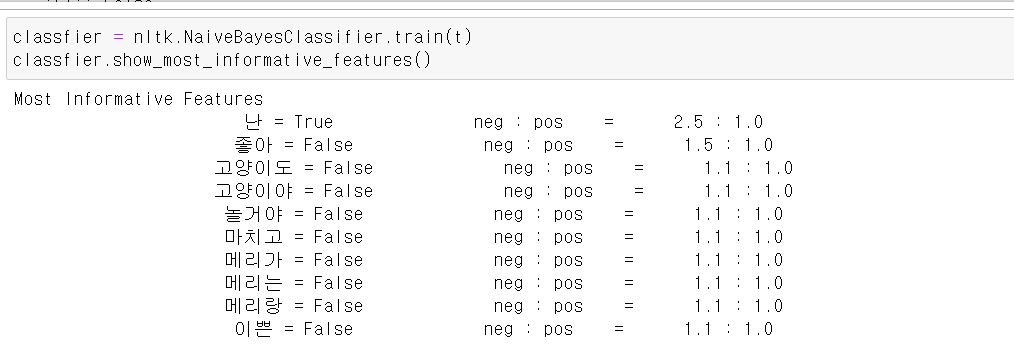
- 교육시키고 결과를 확인하니 각 말뭉치에 따라 pos, neg값을 출력해준다.
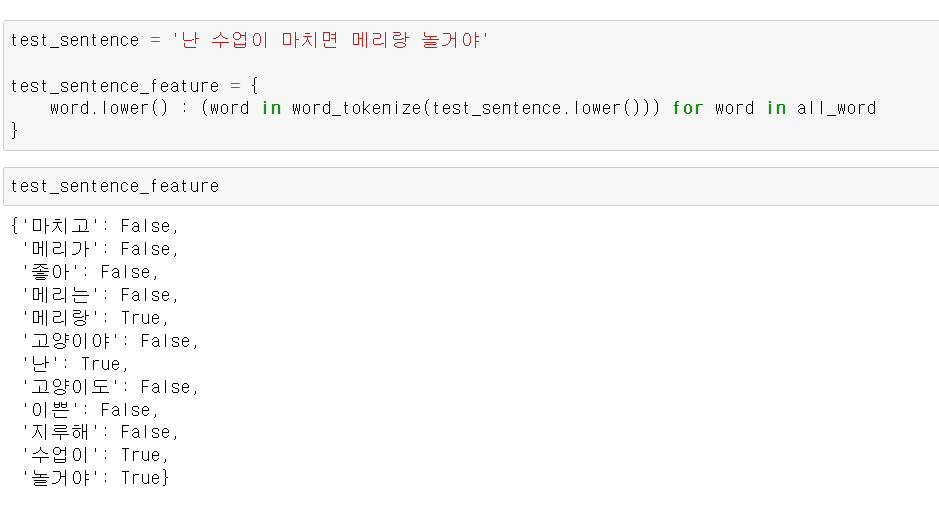
- 이제 모델링에 테스를 문자를 넣어보자
- 모델에 넣기 위해 위와 같은 방법으로 데이터 형태를 바꾼 후

- 결과를 확인해보니 긍정문을 바라고 쓴 문장이, 부정문으로 나왔다.
- 한국어의 경우 형태소 분석 과정이 없으면, 모델링이 정확성이 현저히 떨어진다.
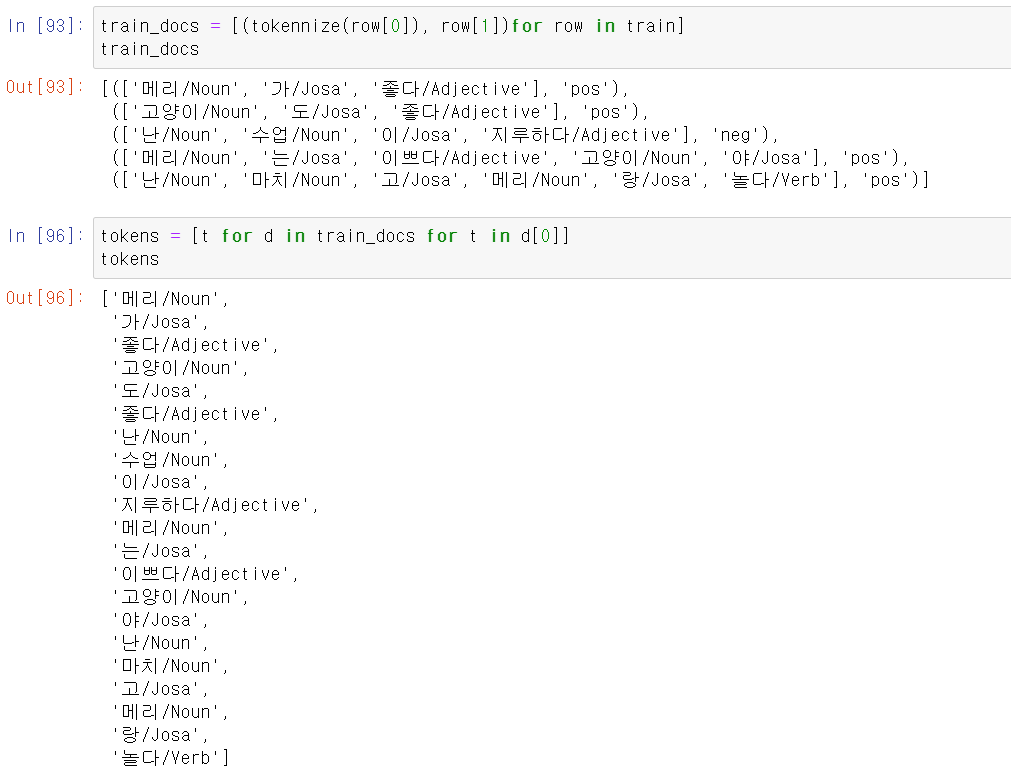
- 이제 train문장을 말뭉치별로 형태소와 함께 구분하고
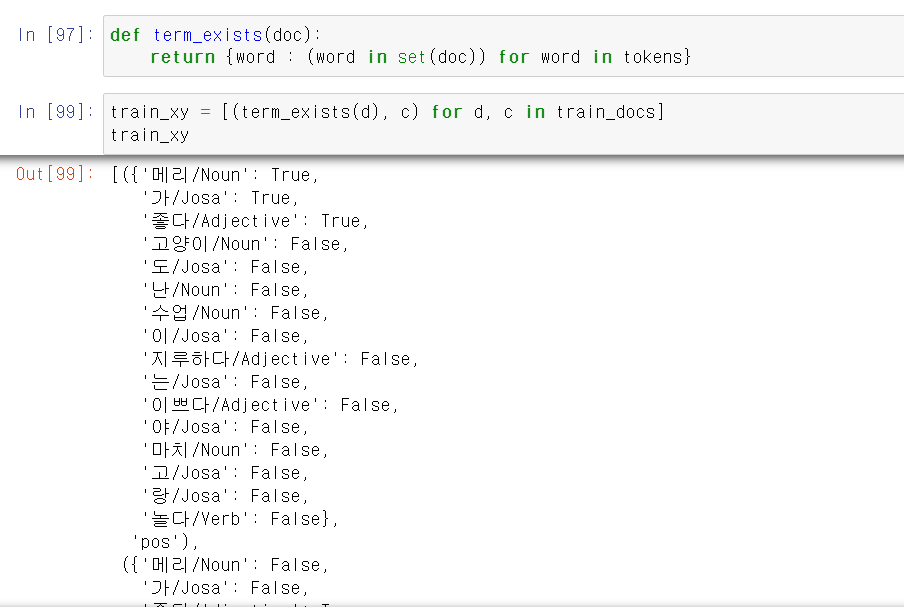
- 번거로우니까 T/F값을 반환하는 함수를 만든 후 모델링 시키기 위한 데이터 형태로 바꿔준다.
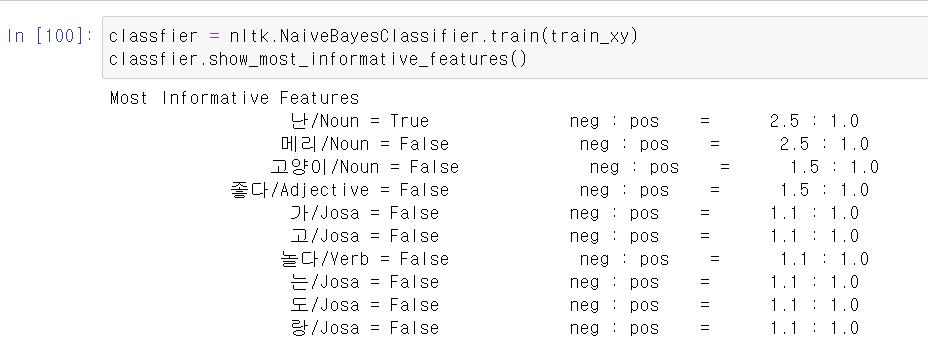
- 이제 해당 데이터를 위와 같이 교육시키고
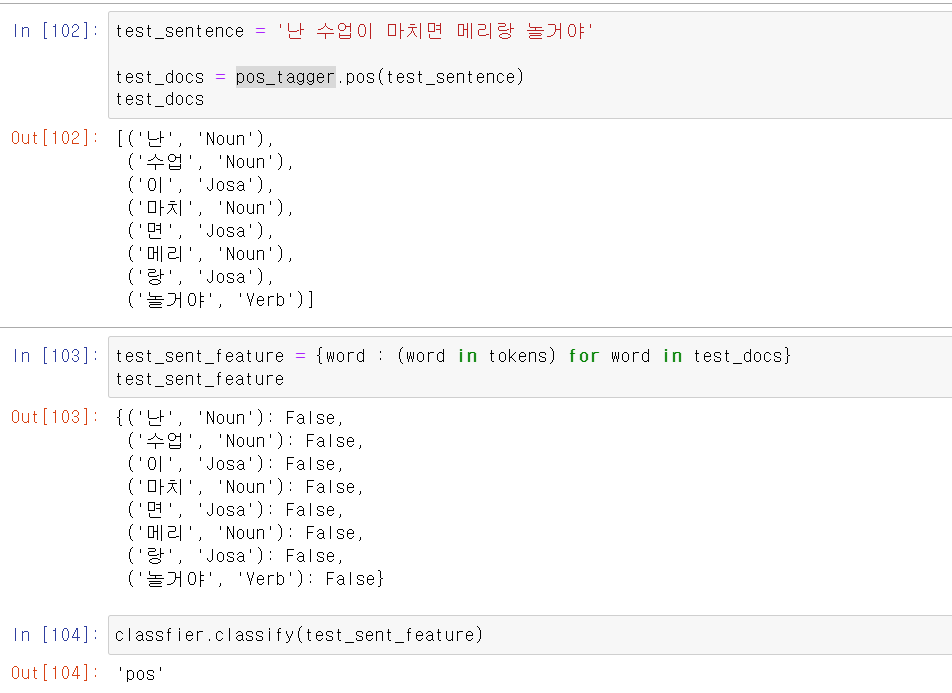
- 테스트할 문장도 형태소에 따른 말뭉치로 구분한 후, 데이터 모델링을 하기 위한 형태로 바꾼다.
- 바꾼 데이터를 모델에 넣어보니 이제는 정상적으로 분석을 한다.
- 이번에는 문장의 유사도를 측정하는 모델링을 해보자
- 사실 모델링이라고 하기 애매한 것이 해당 방법은 fit과정이 없다.
- 형식적으로 fit과정이 있지만, 딱히 교육시키는 것은 아니고 문장의 형태를 array형태로 바꿔주고 행렬의 거리에 따른 거리로 유사도를 측정한다.
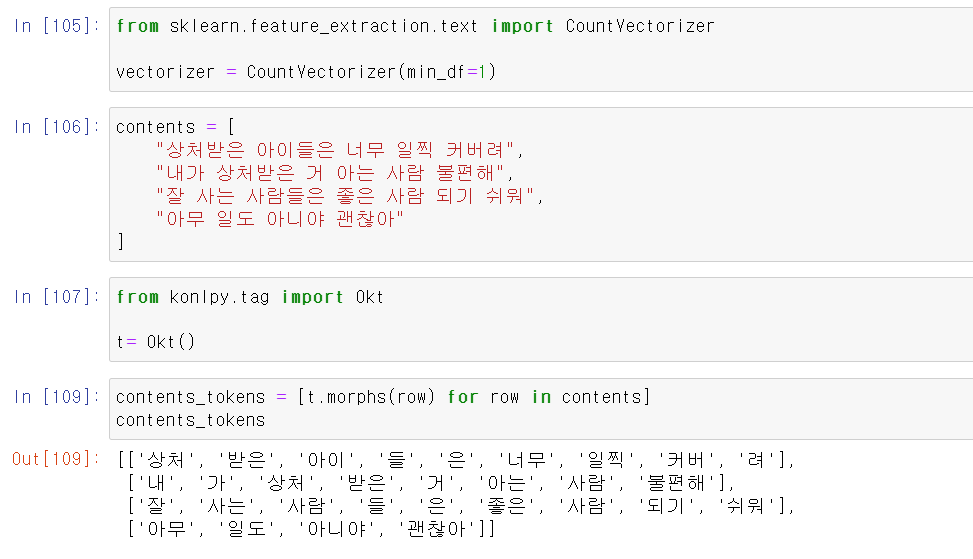
- 먼저 문장을 형태소별로 구분하고
- 구분한 형태소를 각 문장별로 string형태로 바꿔준다.
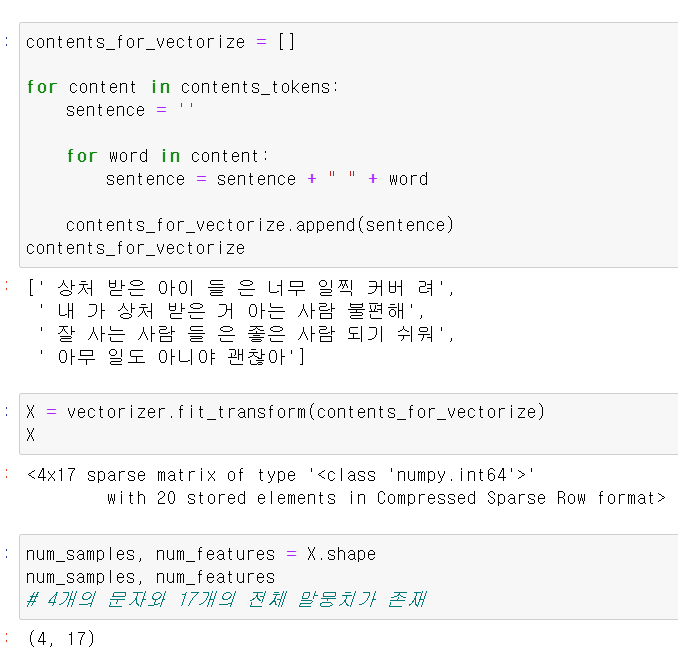
- 그리고 해당 데이터를 vector형태로 바꿔준다.
- 여기서 (4, 17)은 4개의 문장이 17개의 말뭉치로 이뤄졌다고 말해준다.
[0, 0, 1, 0] 좋은
[0, 0, 2, 0] 사람
[1, 1, 0, 0] 상처 - 위와 같이 말뭉치의 카운터를 행렬형태로 바꿔준다.
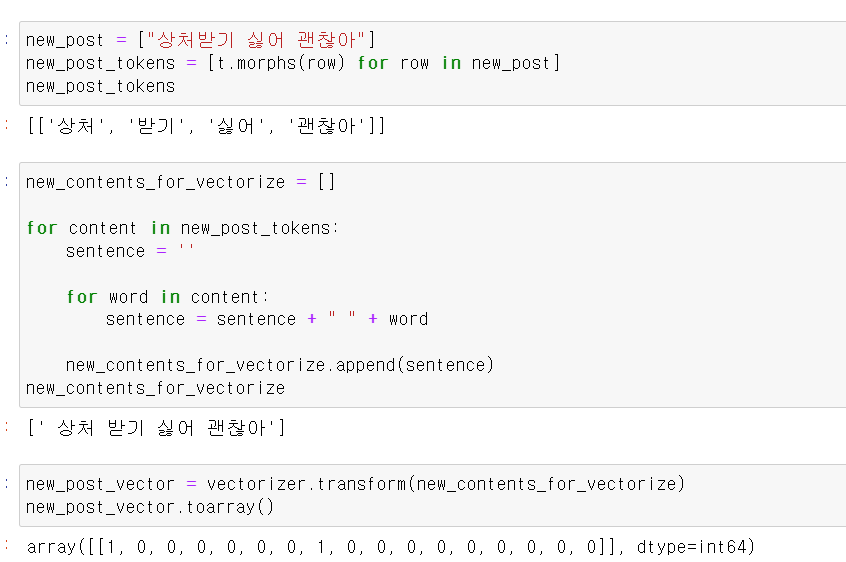
- 이제 테스트 문장을 형태소별로 구분, string 형태로 바꾸고, 마지막으로 벡터로 바꾼 후 array형태로 바꿔준다.
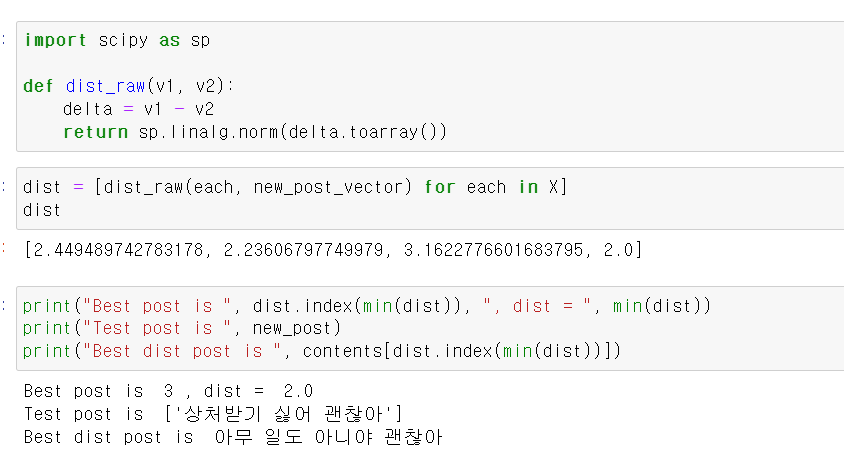
- 이제 각 문장과 테스트 데이터의 문장 차이를 계산하고, 가장 작은 값을 가진 3번쨰 문장이 테스트 문장과 비슷한 유사도를 가진다.

상황을 바꿀 수 없다면, 나를 바꾸자