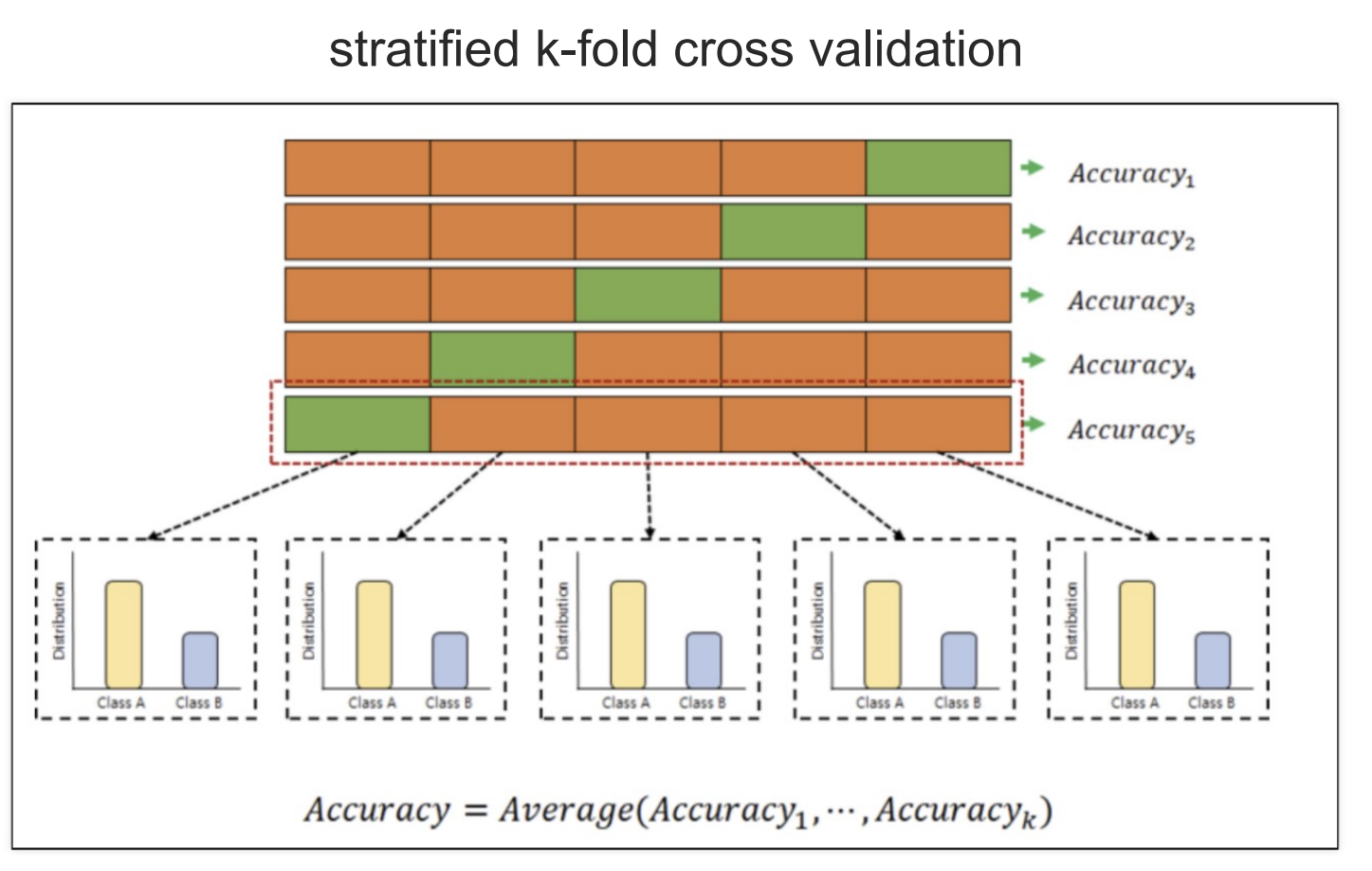
- 머신러닝에서 내가 분석할 때 자료를 검증하기 위해서 주어진 자료를 나눈 후 검증하는 교차검증이 있다.
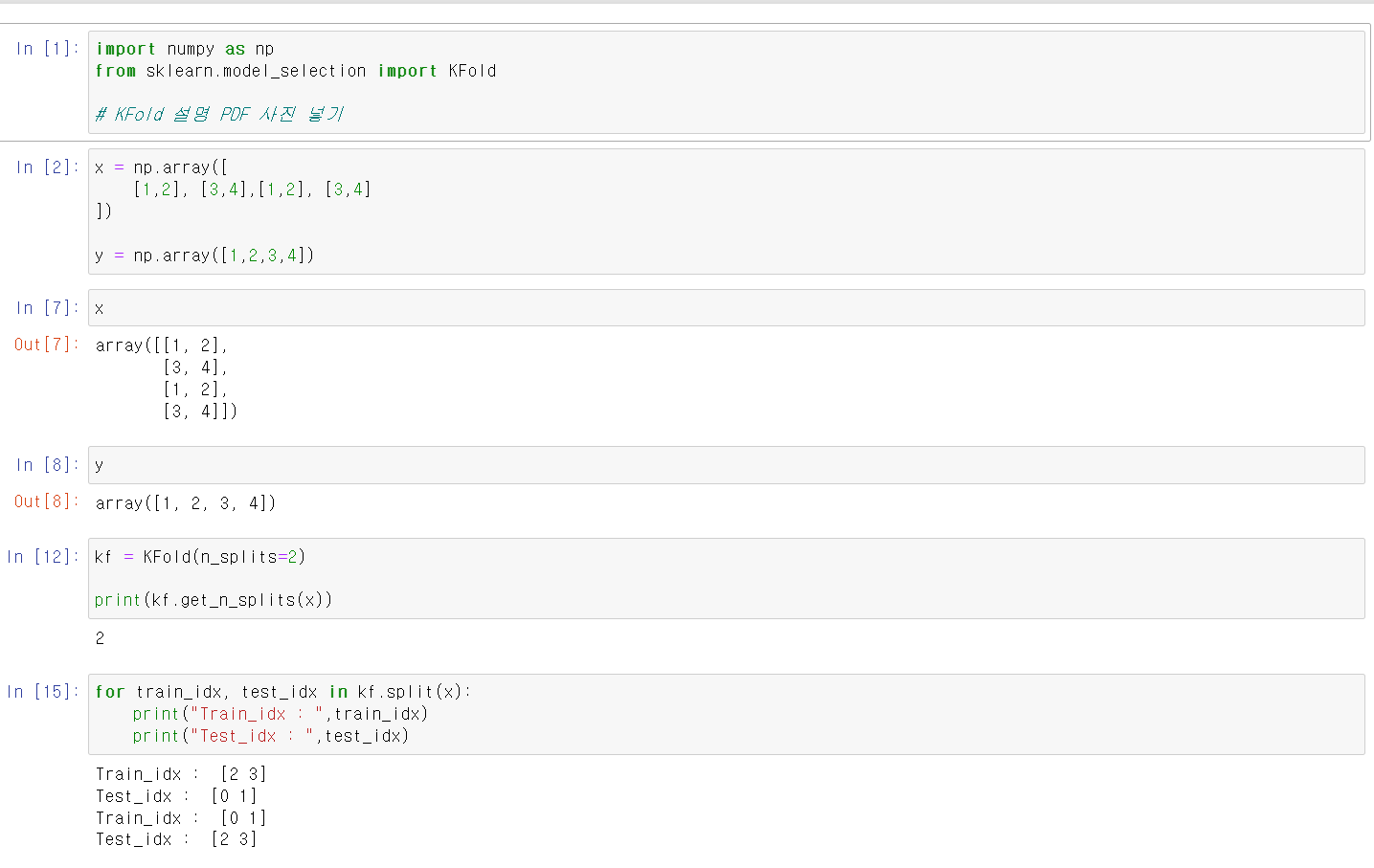
- 사용방법을 간단히 보기 위해 두 개의 변수를 가진 데이터프레임을 생성
- 교차검증을 하는 모듈은 sklearn.model_selection에서 KFold이다.
- for문을 통해 해당 기능을 살펴보니 x의 4개 인덱스를 0, 1로 묶고 2, 3으로 묶어서 train, test테스르 자료로 바꿔가면 출력한다.
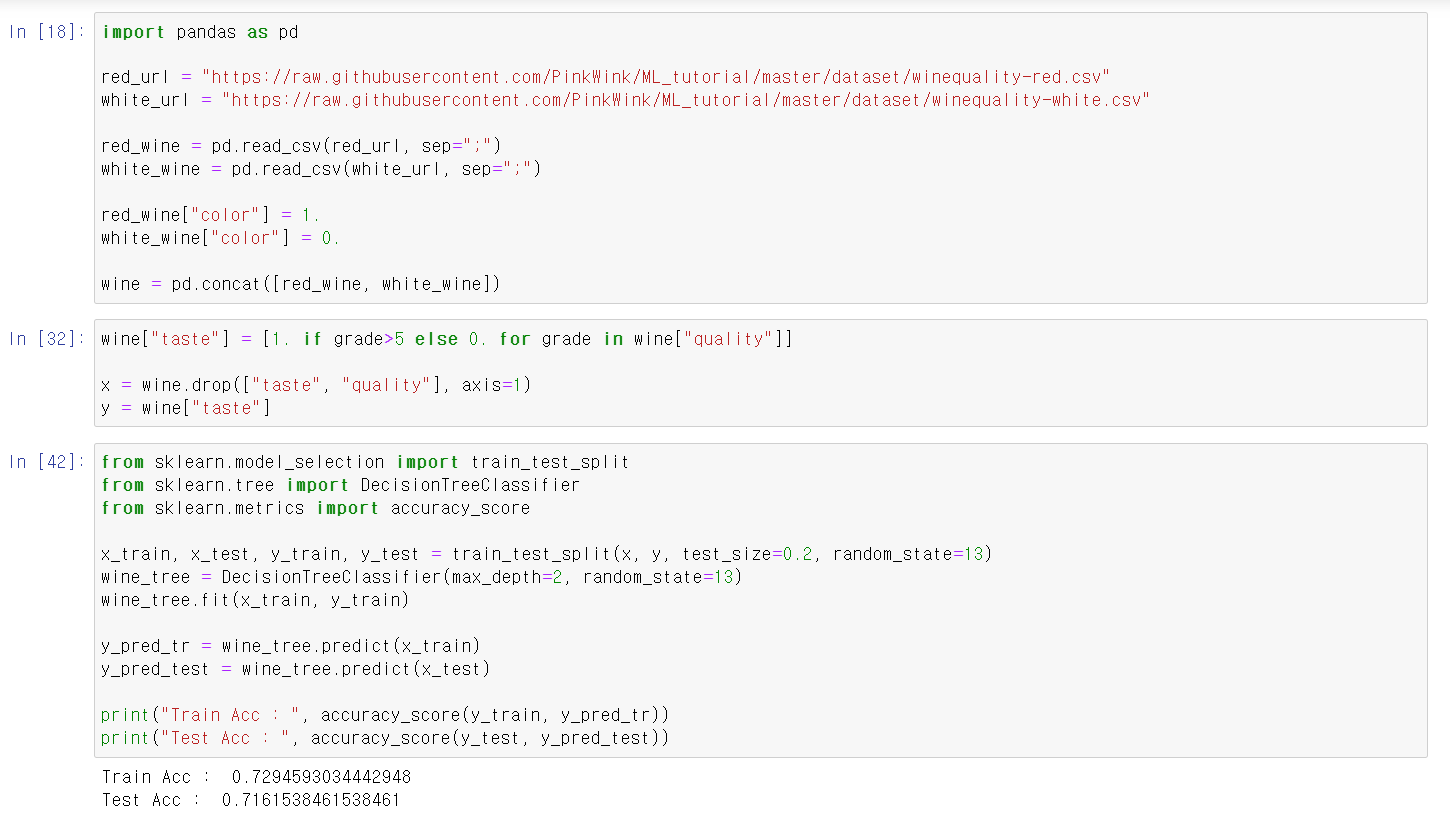
- 해당 기능을 보기 위해 이전에 사용했던 와인 데이터를 다시 불러옴
- 이전에 사용했던 코드를 그대로 가져와서 성능을 확인
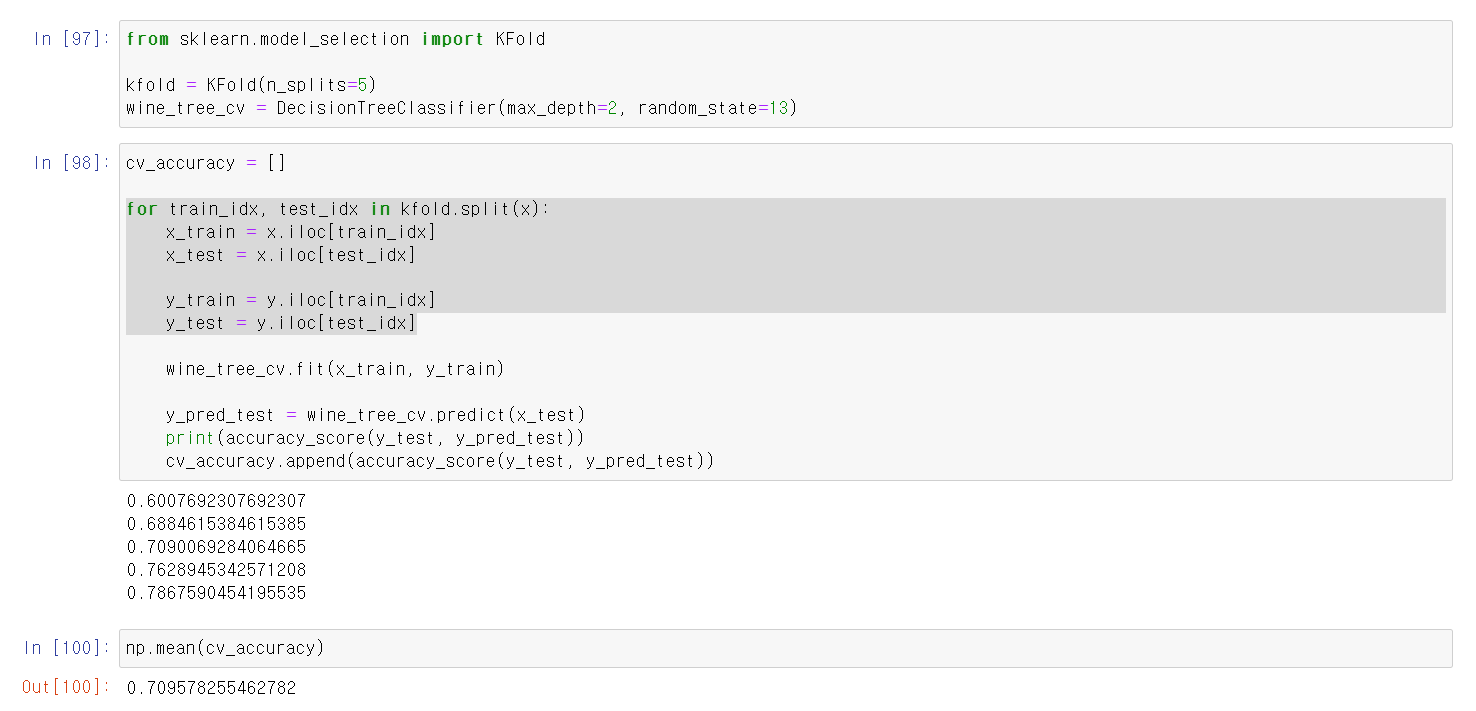
- 이제 해당 자료를 통해 교차검증을 실시
- KFold의 매소드 n_split에 넣은 값에 따라 교차검증을 할 자료가 나누어지는데 보통 3이나 5로 한다.
- for을 통해 각 단계별로 데이터를 머신러닝으로 성능을 확인하고 각 값을 빈 리스트에 넣은 후 값들의 평균을 확인
- 5단계 교차검증의 결과 평균 70%의 성능임을 확인
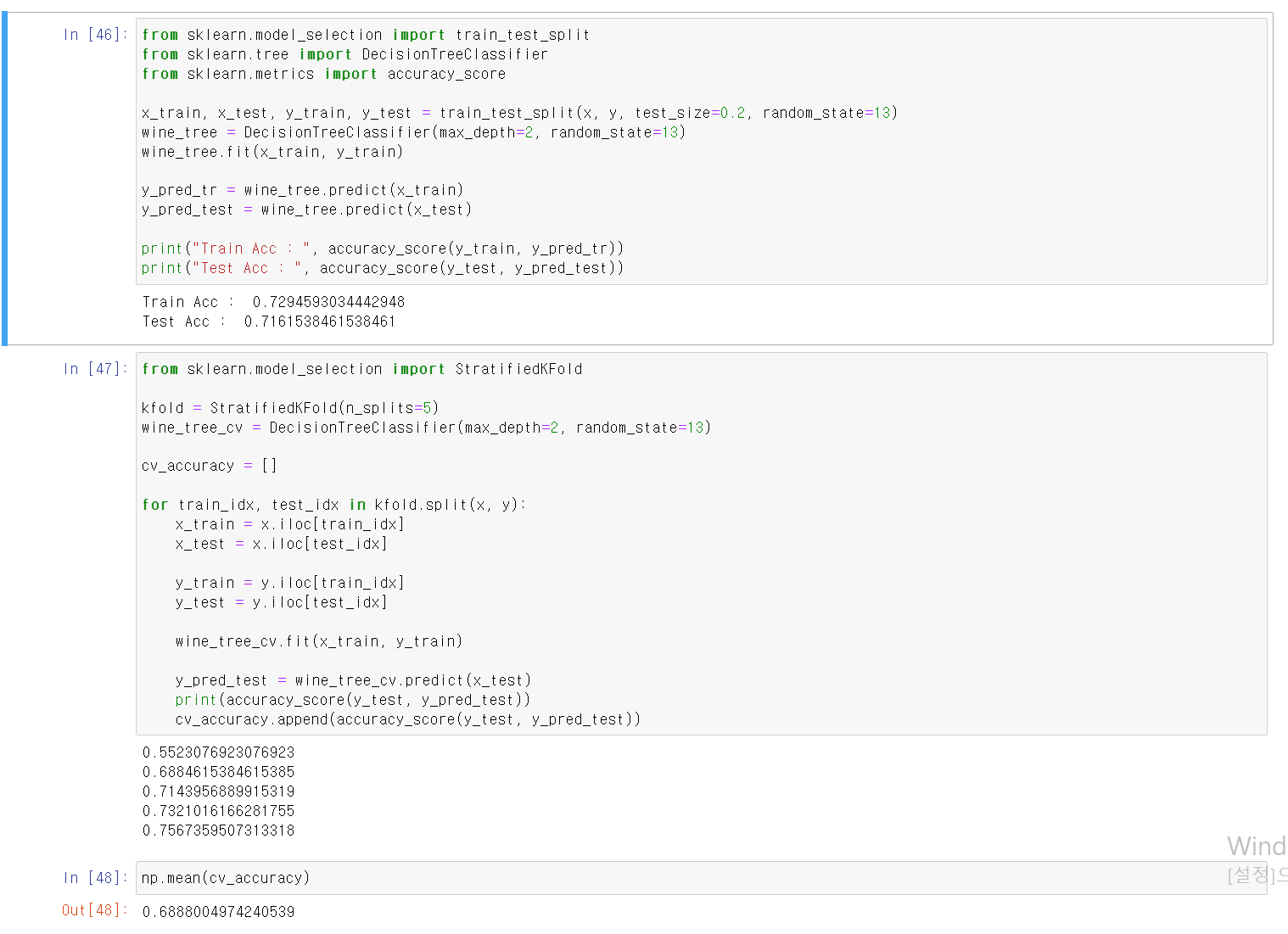
- 이번에는 데이터의 자료를 정규화된 비율로 검증하는 Stratified KFold로 교차검증을 실시
- 일반적인 KFold는 랜덤으로 교차검증을 하지만, Stratified KFold는 일정한 규칙의 비율로 자료를 검증하기 때문에 밸런스가 맞지 않는 데이터set에 사용하기 좋다.
- 하이퍼파라미터 튜닝은 모델링의 성능이 낮을 때 하는 것으로 다양한 값을 조절하면서 모델링의 성능을 높인다.

- 해당 기능을 살펴보기 위해 역시 이전에 사용한 wine_data를 불러옴
- 먼저 params 변수에 max_depth로 사용할 값을 저장하고
- wine_tree에 DecistionTree를 저장함
- 이후 GridSearCV(하이퍼파라미터 튜닝에 CV는 교차검증)에 결정나무트리, params를 넣고 저장
- 해당 변수에 자료와 정답을 넣고 교육시킴
- 확인 결과 정상적으로 5단계 교차검증에 2 4 7 10의 max_depth의 모델링으로 교육이 됨
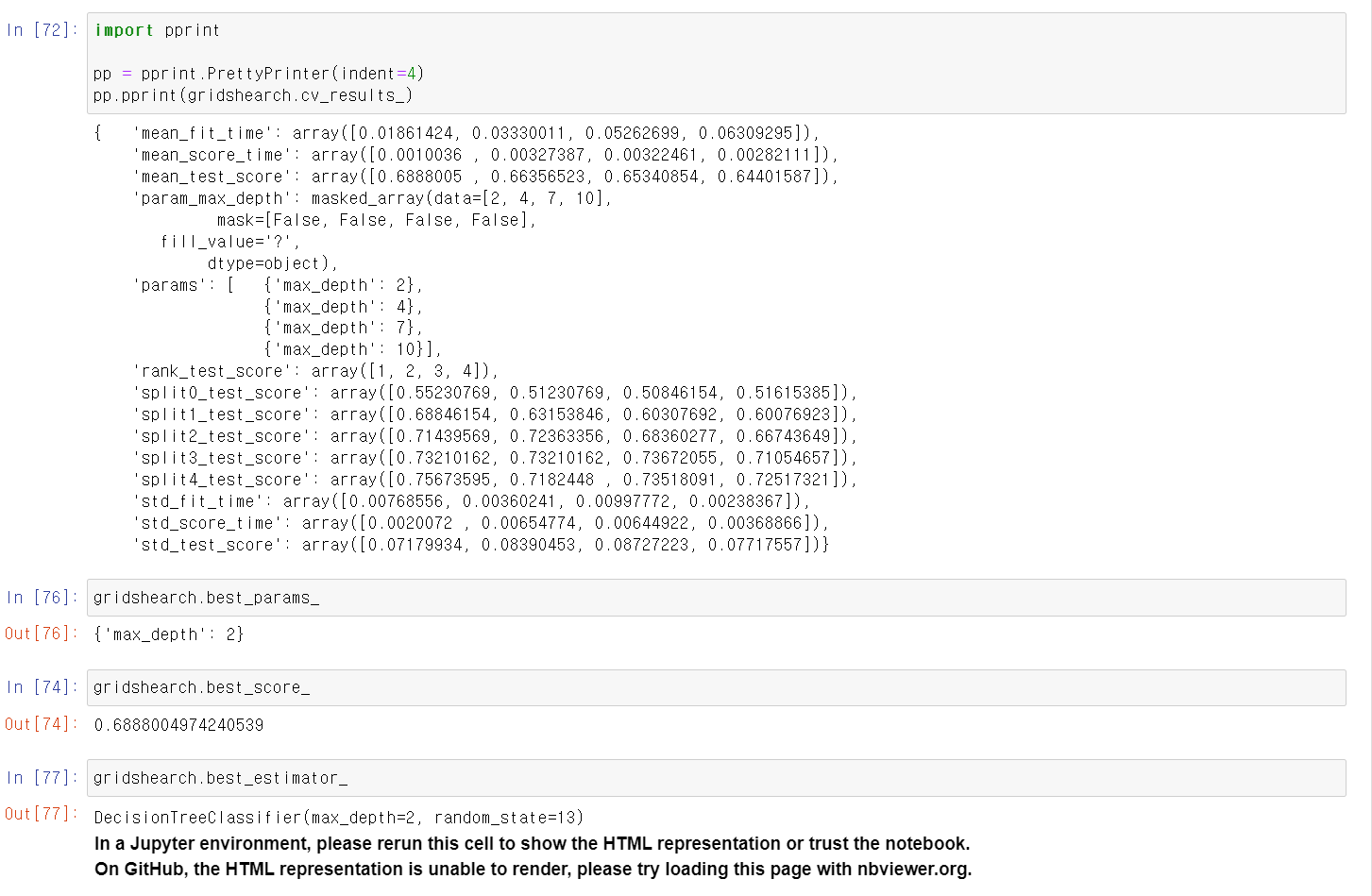
- pprint로 확인 결과 2~10까지 1 2 3 4등의 성능을 가졌으며, max_depth 2가 최고 성능을 가짐
- 최고 성능의 모델링은 69% 정도임
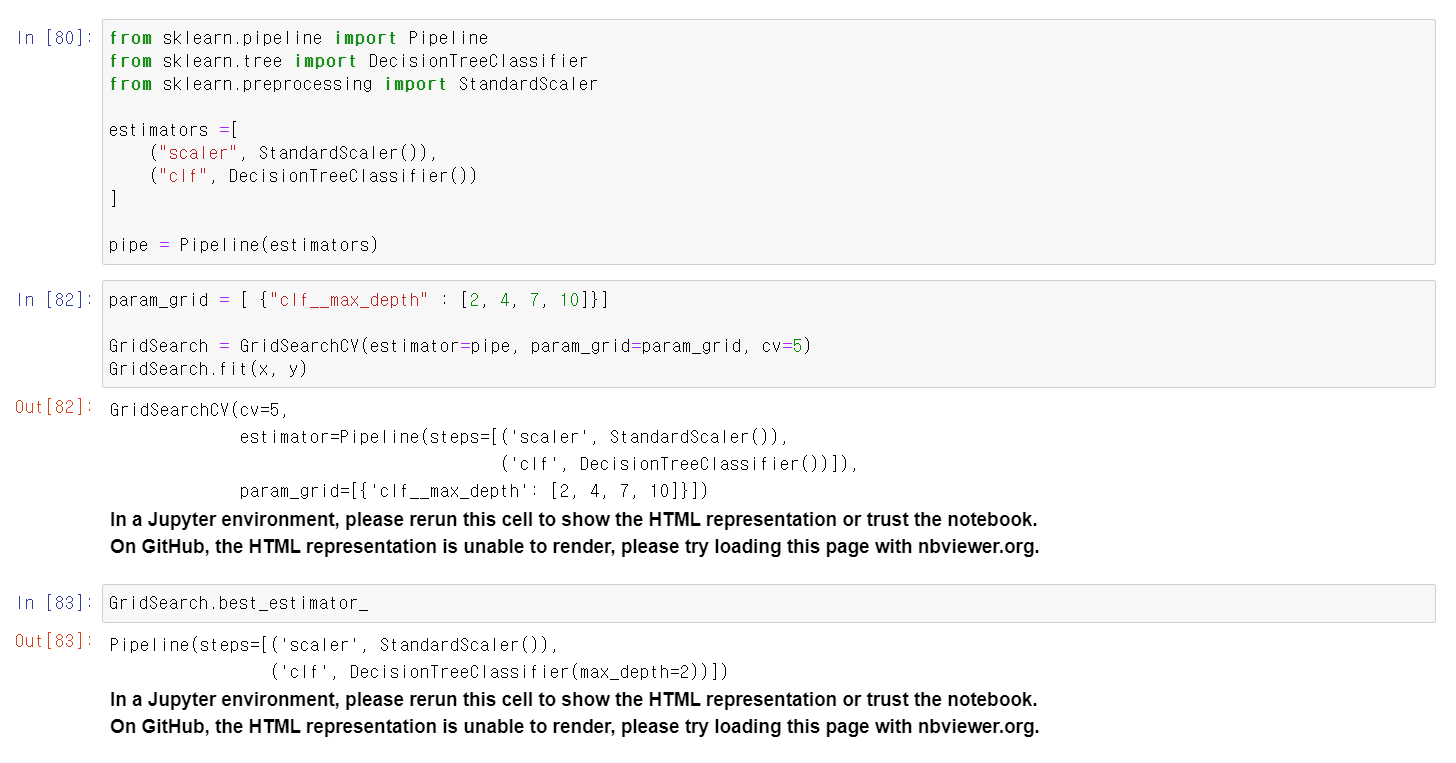
- 이번에는 PipeLine에 StandardScaler와 DecisionTree로 저장 후 해당 pipe로 하이퍼파라미터 튜닝을 실시
- 위와 같이 max_depth값이 2인 경우 최고 성능을 보임
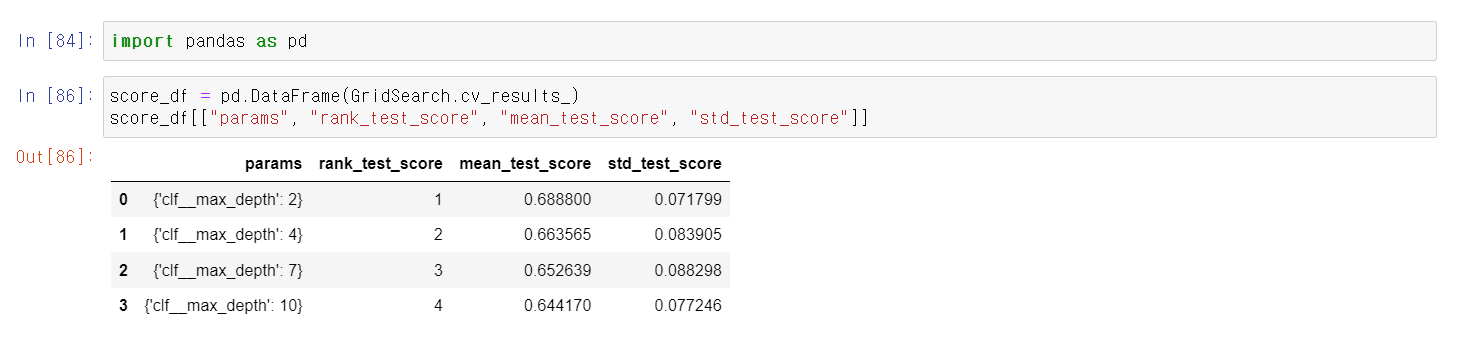
- 결과를 데이터프레임으로 보기 좋기 정리

상황을 바꿀 수 없다면, 나를 바꾸자