competition 대회를 진행하면서 loss의 설정에 대한 부분을 신경을 많이 쓰게 되었는데 label smoothing과 focal loss를 많이 다루게 되었다.
그냥 좋다니까 가져다 쓰는 것 보다는 이해가 선행되는 것이 좋을 것 같아 TIL로 다루고자 한다. 그 다음에는 Optimizer에 대한 내용을 다루려고 한다.

💡 Label Smoothing
정규화의 가장 많이 사용되는 것은 레이블 스무딩(Label Smoothing)은 데이터 정규화(regularization) 테크닉이며 모델의 일반화 성능을 높여주는 경향이 있다. 위의 그래프에서 알 수 있듯이 drop out 다음으로 regularization에서 많이 사용되는 기법 중 하나이다.
그러나 그러한 사용과는 다르게 내부 작동 원리나 이론이 확실한 것은 아니다. 제프리 힌튼 교수 연구팀이 2019 NeuraIPS에 제출했던 논문인 When Does Label Smoothing Help? (https://arxiv.org/pdf/1906.02629)의 논문을 참고해 label smoothing에 대해 다뤄보고자 한다.
🎯 Label Smoothing은 무엇인가?
label smoothing이란, 레이블을 그대로 사용하는 것이 아니라 조금 smooth하게 만들어서 정규화를 시키는 것이다. one-hot vector는 단일한 하나의 값만 1이고 나머지는 0으로 나타나는데 그것을 soft target으로 바꾸어주는 것이다.
𝐾 개 class에 대해서 레이블 스무딩 벡터의 𝑘번째 스칼라 값은 다음 수식과 같다 (𝛼는 hyperparameter).
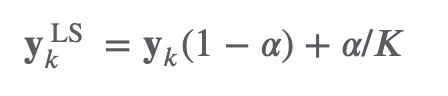
이렇게 되면 각각의 정답이 one-hot vector가 아닌 조금 다른 모습을 보이게 된다.

👀 Label Smoothing을 시각화해보면 어떨까?
논문의 저자들은 Label smoothing을 해석하기 위해 logit-소프트맥스 노드에 주목했다. 𝐱 는 이 노드의 입력 벡터 혹은, 직전 레이어의 출력 벡터, 𝐰𝑙 은 이 노드의 𝑙 번째 가중치(weight) 벡터에 해당한다. 저자들은 후자를 템플릿(the template)이라고 부르고 있다.
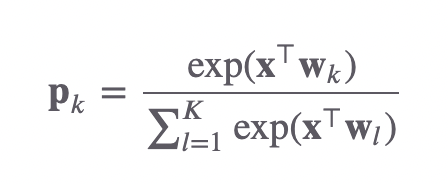
𝑘 번째 class가 해당 input 𝐱의 정답이라면 𝐱⊤𝐰𝑘 내적 값이 크도록 만들어 정답에 근접하게 해야 한다. 벡터의 내적는 코사인 유사도와 밀접한 관련이 있는데 모델이 제대로 학습되고 있다면 𝐱는 정답 class에 해당하는 𝐰와 벡터공간 상 가까이에 위치하게 된다. 그렇게 되면 내적값이 당연히 커질 것이기 때문이다.
저자들에 따르면 기존의 one-hot vecotr를 맞추는 방식은 𝐱를 정답 템플릿과 가깝게 하는 데에만 관심을 둔다고 말한다. softmax - cross entropy를 통해 나타나는 loss를 미분하며 역전파를 진행하면 오직 정답에만 근접하려 하기 때문이다.
그러나 레이블 스무딩을 실시하게 되면 진행이 조금 달라진다. 𝐱를 정답 템플릿과 가깝게 하면서도, 𝐱를 오답의 w와는 동일한 거리에 있도록 만들어서 거리를 갖게 만드는 효과를 낸다고 말한다. 즉, 오답과는 일정 거리를 유지하며 정답에 근접하게 되는 것이다.
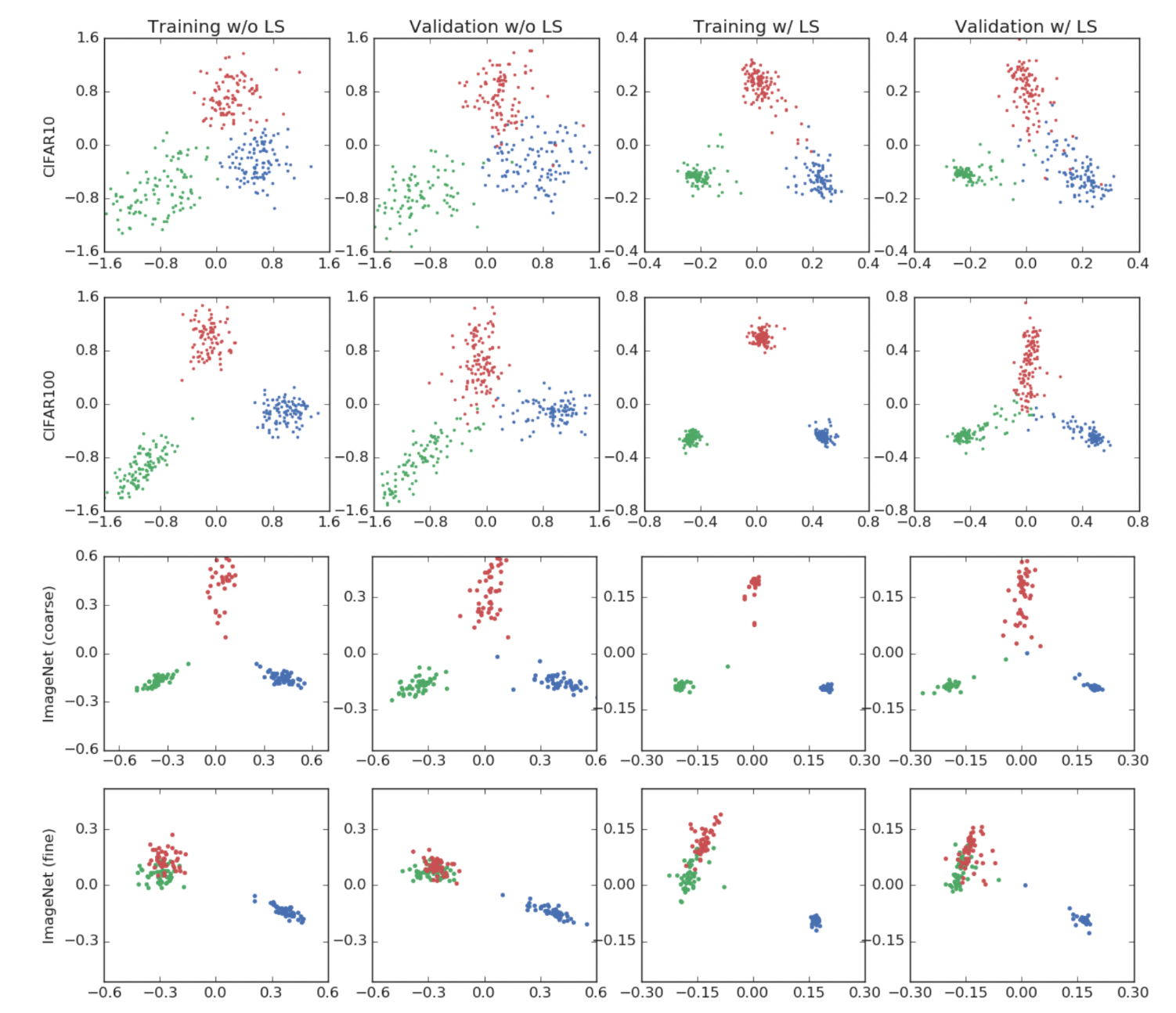
실험의 결과는 위와 같은데 label smoothing을 사용했을 때에 각 label들의 거리가 더 생기는 것을 알 수 있다.
🔥 Label smoothing과 유사한 temperature scaling
Temperature Scaling은 Guo et al이 17년에 제안한 기법으로, 신경망 학습은 보통 예측 과정에서 서로 다른 data에 대해서도 이미 학습된 파라미터를 그대로 사용하는 over-confident의 경향이 강해 이를 완화하는 방식이다. 학습된 신경망과 validation set 입력에 대해 소프트맥스 확률을 구하고, 같은 validation set 레이블에 대해 크로스 엔트로피를 최소화하는 temperature 𝑇 를 찾는 것이 목적입니다.
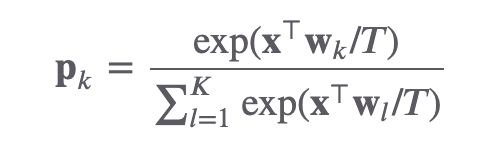
즉, T를 통해 모델의 기대 accuracy보다 confidence가 높은 over-confident 상황을 방지해주는 것이다.
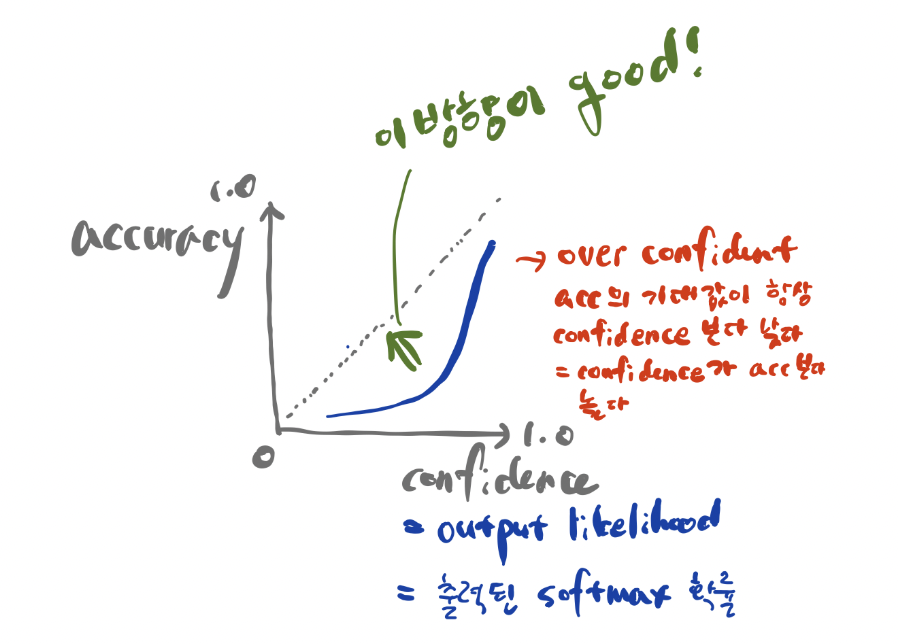
Label Smoothing 역시 이러한 효과를 나타낸다고 말한다.
🔥 Knowledge Distillation에서의 사용에서의 Temperature Scaling과 Label Smoothing
label smoothing은 충분히 효과적인 방식이지만 그렇지 못한 경우가 있다. Knowledge Distillation은 방대한 teacher network로부터 핵심적인 지식을 전수받은 경량화된 student network를 만들기 위해 제안됐다. 그런데 student network는 teacher network의 출력 소프트맥스 확률을 정답 삼아 학습을 하게 된다.
여기서 발생하는 문제는 Label smoothing이 소프트 맥스 확률 자체를 변경시켜버린다는 것이다. TS의 경우 T를 통해 보완을 해주는 것이라면 Label Smoothing은 출력 소프트 맥스 확률 자체를 다른 방향으로 이끌게 된다.
이는 논문 저자인 힌튼이 "정보손실"이 발생했다고 말한다. 로짓 벡터에 스케일을 하는 TS와는 달리, 레이블 스무딩은 기존 hard target에 인위적인 조작을 가해 정보량이 줄어들 수 있다는 것이다.
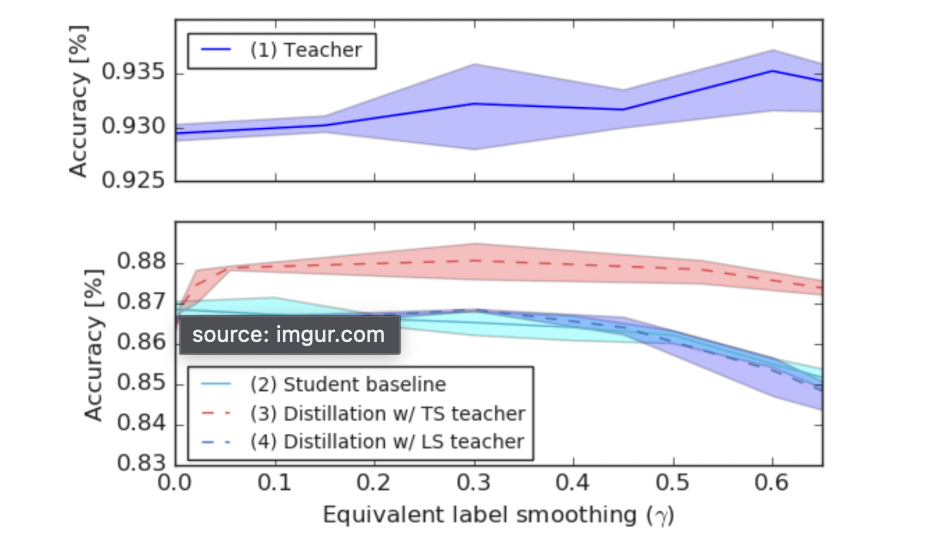
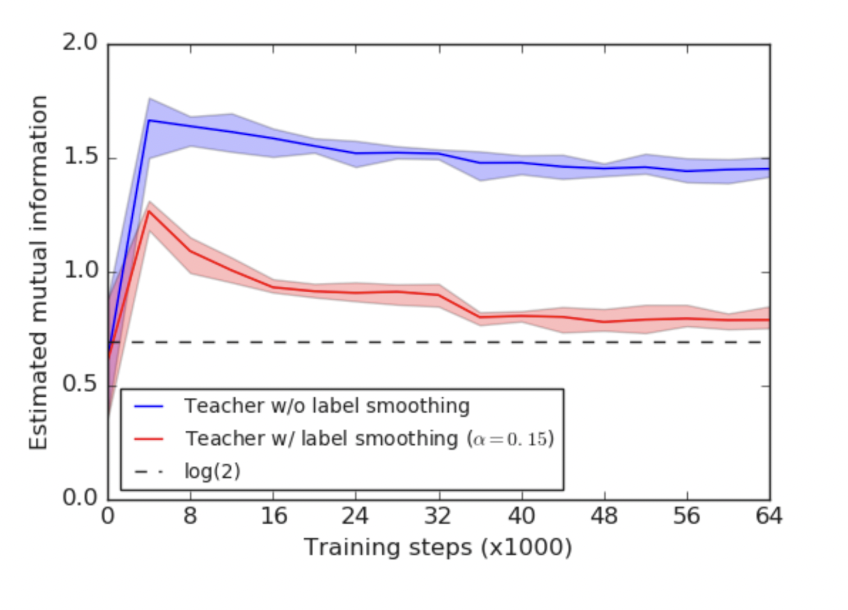
레이블 스무딩으로 teacher network의 일반화 성능을 높일 수 있다 하더라도, KD에 있어서는 이렇게 학습 과정에서 손실이 발생한 그대로 따라하는 student network의 성능이 떨어질 수 있음을 보여준 것이다.
✏️ 후기
생각보다 내용이 길어져서 Focal은 다음 post에서 다루고자 한다. Label smoothing을 공부하면서 하나의 방식이 무조건 모든 성능을 오르게 하는 마스터키가 될 수 없음을 다시 한 번 느꼈다. 그러니 방식을 공부하면서도 그러한 태도를 경계해야겠다는 생각이 많이 들었다.
참고 : https://ratsgo.github.io/insight-notes/docs/interpretable/smoothing
