월요일부터 진행된 네이버 부스트캠프의 competition. 주제는 한 사람 당 7개씩의 사진(마스크를 제대로 쓴 사진 5개, 잘못쓴 사진 1개, 안 쓴 사진 1개)으로 이루어진 2700명의 사진을 학습한 후, 마스크 여부(normal, mask, incorrect), 성별, 나이대를 class로 구분하는 것이다.
여러 팀들이 감사하게 baseline code를 공유해주고 계신데 몇몇 코드의 acc가 99퍼 이상인 것을 확인했다. 보통 이런 경우, overfitting이 발생했거나 train과 validation 사이에 cheating이 발생한 경우가 빈번하다.
해당 문제를 인지하고 어떻게 해결했는지 회고를 작성하고자 한다.
💡 1. 문제인식
현재의 문제는 train, validation과 test set의 성능이 매우 차이가 난다는 것입니다.
base code에서 모델의 성능이 너무 높게 나오거나 너무 낮게 나올 때는 문제가 있는 경우가 대부분입니다.
보통, 이렇게 test와 train 사이에 너무 심한 성능차이가 나타나는 경우, train과 validation set이 제대로 분할되지 못하거나 여러 이유 등으로 train과 validation set에 overfitting이 발생했거나 leakage가 발생했다는 것을 의미하고는 합니다.
✏️ 2. 어디서 문제가 발생했을까?
그렇다면 왜 overfitting이 발생했을까 생각해보면 데이터 자체의 문제 때문인 것 같습니다.
보통 데이터셋에 대해 많은 분들이 train_test_split이나 sampler를 통해 분할해주시고 계실텐데 이렇게 되면 동일한 사람의 데이터가 몇몇개는 train 몇몇개는 validation으로 흘러가게 됩니다.
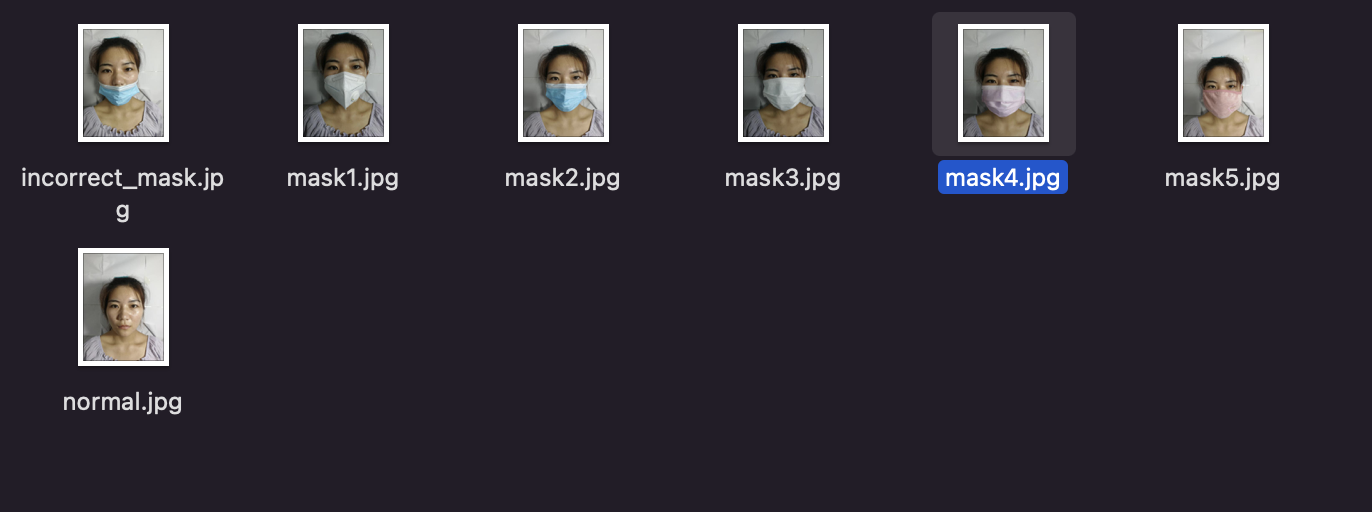
데이터셋에서 알 수 있듯, 동일한 사람이 동일한 장소에서 동일한 의복을 입고 촬영한 사진이 대부분입니다.
예를 들어, 위의 데이터셋의 mask1, 2는 train에 나머지는 validation으로 가게 되면 정답을 cheating하는 문제가 발생할 수 있을 것 같습니다.
😢 3. 그럼 우째?
제가 생각한 방안은 우선 KFold를 할 때에, shuffle을 false로 사용해 순차적으로 Xtrain과 X_val가 분할되게 된 후에, 각각을 DatasetLoader에 넣어주어서 random_sample하면 되지 않을까 생각하고 있습니다.
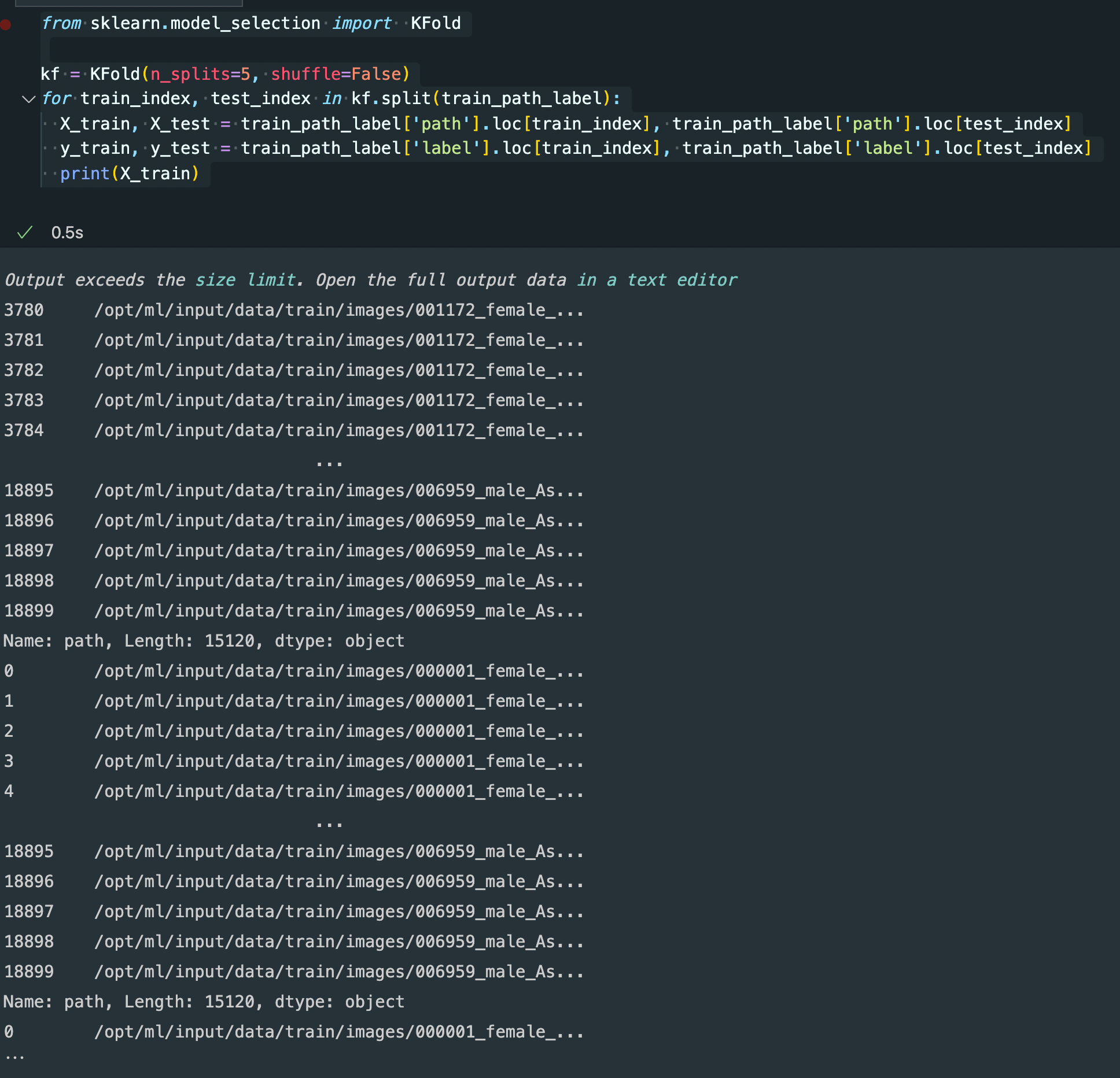
그렇게 되면 동일한 사람의 데이터는 train 혹은 validation 하나에만 속하게 되고 cheating 문제를 보다 해결할 수 있는 방안이 되지 않을까 싶습니다.
✏️ 후기
사실 이 방식 이외에도 다양한 방식으로 이러한 문제를 해결할 수 있다. 내 모델의 성능이 예상보다 너어어어무 높거나 너무 낮으면 무엇인가 잘못되었음을 인지하고 문제정의부터 나아가는 습관이 필요할 것 같다. 아무튼 오늘의 TIL 끝~~😃
