
Image Classification : A core task in CV
📌 Semantic Gap : 컴퓨터와 인간이 이미지를 보는 차이
- 이미지 픽셀을 0~255사이의 숫자로 구성된 격자로 인식한다.
- 각 원소는 R, G, B 의 3개 숫자로 구성
✨ Image Classification의 Challenges
- Viewpoint Variation
: 대상은 바뀌지 않았지만 카메라 각도가 바뀌었을 때 픽셀들은 모두 바뀐다. - Illumination
: 빛의 조명에 따라 픽셀이 바뀐다. - Deformation
: 포즈나, 위치 등이 바뀌는 것. 알고리즘은 다양한 transform에 대해 robust해야함. - Occlusion
: 대상의 어떤 부분만 보일 때. 사람이라면 바로 인식할 수 있지만 알고리즘은 어렵다. - Background Clutter
: 배경색과 비슷한 보호색으로 보여질 때 - Intraclass variation
: 다양한 모양, 사이즈, 색, 나이 등 (다 고양이 인데 다른 종일 때)
따라서, 이미지를 규칙 기반 방법으로 분류하게 된다면 모든 라벨에 대해 규칙을 만들어야한다는 어려움이 있다.
✨ Data-Driven Approach
① 모든 라벨(정답)이 있는 이미지를 수집
② 머신러닝 classifier에 데이터 모두 학습, 기억
③ 새로운 이미지로 classifier 성능 평가
- 안정성 및 확장성(다른 개체에도 적용 가능하다.)
- 사람이 학습하는 것과 비슷하다.
First Classifier: Nearest Neighbor(NN)
- 모든 데이터와 라벨들을 기억한다.
- 테스트 이미지가 들어왔을 때 학습된 사진과 가장 비슷한 라벨을 예측한다.
다음 K-Nearest Neighbor(KNN)
: 새로운 데이터의 라벨을 예측할 때, 가장 비슷한 기존 데이터 k개의 라벨을 majority vote하여 라벨을 예측하는 방법

- k=1인 경우 NN임.
- k가 커질수록 결정경계가 더 부드러워지며, 더 좋은 결과를 보인다.
하지만 KNN은 이미지에서 사용되지 않는다.
이유1. test시간이 오래 소요
이유2. 픽셀에 적용되는 distance metrics가 유용하지 않음(서로 다른 이미지가 같으느 거리를 가질 수 있음)
이유3. 차원의 저주 : KNN이 잘 동작하려면 공간을 충분히 덮는 points(데이터)가 필요한데, 차원이 증가할수록 필요한 데이터가 기하급수적으로 증가함.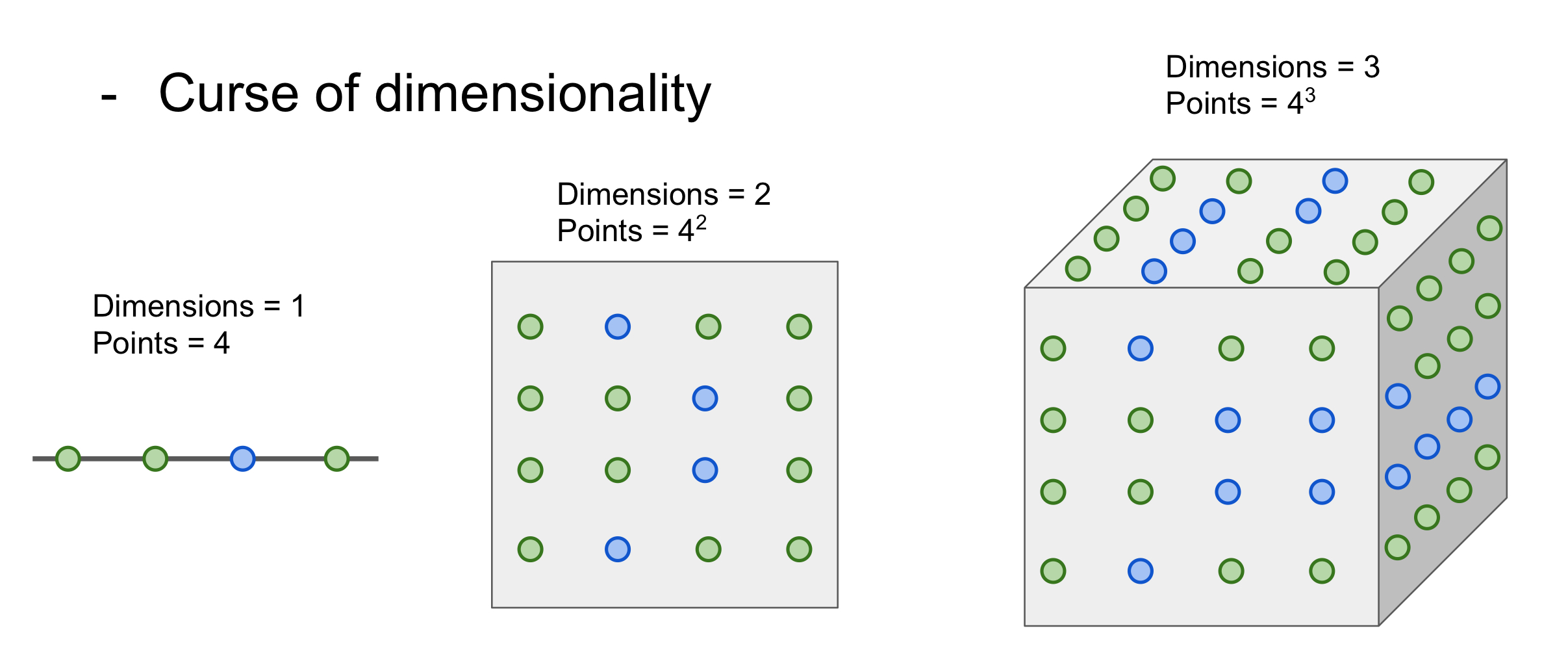
그럼 서로 다른 점을 어떻게 비슷한지 비교할까?
Distance Metric을 이용한다!
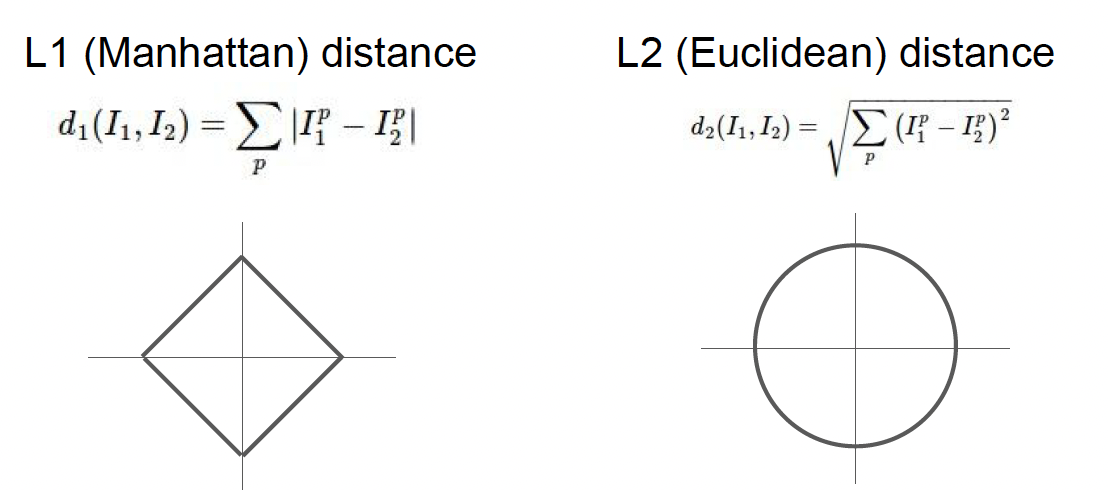
L1 distance : 숫자가 비슷하면(차이가 0이면) 비슷한 이미지 라고 판단. (test-train 픽셀 간 차이 절댓값의 합)
- 기존 좌표계 변환시 변함. 좌표계 영향을 받음
- 특징 벡터의 각각 요소들이 개별적인 의미를 가지고 있다면 잘 어울린다(ex. 키, 몸무게)
- 원점을 기준으로하는 사각형
- 계단식 형식, 완만해서 outlier 대응에 강하고 변화에 둔감하다.
- Regularization, Regression에 쓰인다.
- Perceptual loss를 위한 VGG network에서 Feature간의 거리 차이를 계산하는데 쓰인다. -> 공부필요
- 짧고 간결하지만, train시엔 시간 복잡도가 O(1) << predict시엔 O(N)
=> 학습 능률을 올리기 위해 train을 오래하는 건 괜찮으나 test시엔 짧은 시간에 결과를 내야함. 따라서 별로임.
L2 distance : 제곱합의 제곱근
- 원 그래프로 나타내짐
- 좌표계와 상관없음
- 특징 벡터가 일반적, 요소들간 실질적인 의미를 잘 모르는 경우 잘 어울림
- Outlier에 민감하다.
- x가 변할 때 그 기울기가 정답에 가까울수록 완만해진다.
- Regression에서 사용되는 mean square error에 쓰인다. -> 공부필요
L1은 outlier에 강하고, L2는 정답에 가까울수록 변화율이 완만하다는 장점이 있어 둘을 융합한 smooth L1 loss 방식이 있다.
Hyperparameter
: train time에서 학습하는 것이 아니라, 학습 전, 지정해주는 것.
다양한 값을 시도해서 가장 적절한 것으로 학습해야함.

CSE