
ELMo는 Embeddings from Language Model의 약자이다. 직역하면 "언어 모델로부터 얻는 임베딩" 이라고 해석할 수 있다.
이전에 배웠던 GloVe같은 경우는 play의 벡터값과 비슷한 것들에는 단순히 playing, game, played, players 이런 단어들이 있었는데 엘모는 다의어를 모델링 할 수 있게 되었다. 무슨 말이냐 하면,
play라는 단어는 경기라는 단어도 있고, 연극이라는 단어가 있다. 엘모는 글자는 같지만 뜻이 다른 이 두 단어의 벡터를 다르게 표시 할 수 있다는 뜻이다. 각 단어의 벡터값은 문장의 문맥을 보고 결정된다.
엘모의 특징을 살펴보자.
-
엘모에서 사용하는 벡터들은 Bidirectional LSTM에서 가지고 오는데, 여기서 BiLM은 기본적으로 은닉층이 2개 이상인 깊은 신경망을 가정한다.
-
ELMo Representation은 기본적으로 BiLM의 모든 내부 층들로부터 결정된다.
-
특정 토큰 위의 모든 내부 층들의 벡터가 선형 결합을 통해 표현을 얻는다.
-
위방법은 Top Layer의 LSTM의 표현만을 사용한 것보다 높은 성능을 보여준다.
-
각 층은 가지고 있는 의미가 다른데, 낮은 층에서는 구문분석(Syntax analysis)에 유리한 정보를 갖고 있으며, 윗 층에서는 자연어(NLU)에 가까운 정보를 가지고 있다. 이를 가중치로 조정한다.
엘모는 순방향과 역방향으로 언어 모델을 따로 학습시키는데,
Play라는 단어로 임베딩을 얻는다고 해 보자.
아래에서의 순방향 언어 모델에서 한번,
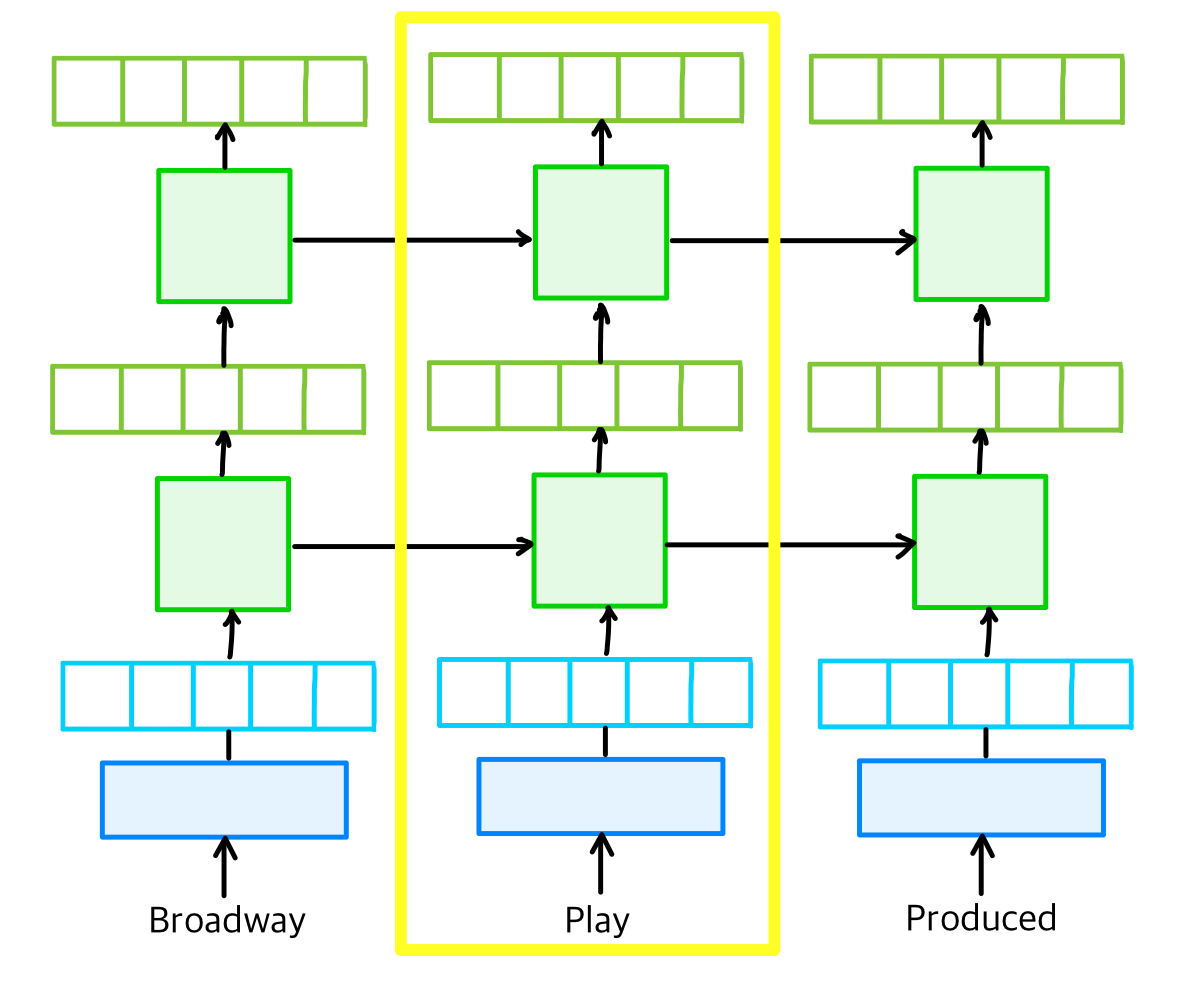
아래의 역방향 모델에서 한 번 학습시킨다.
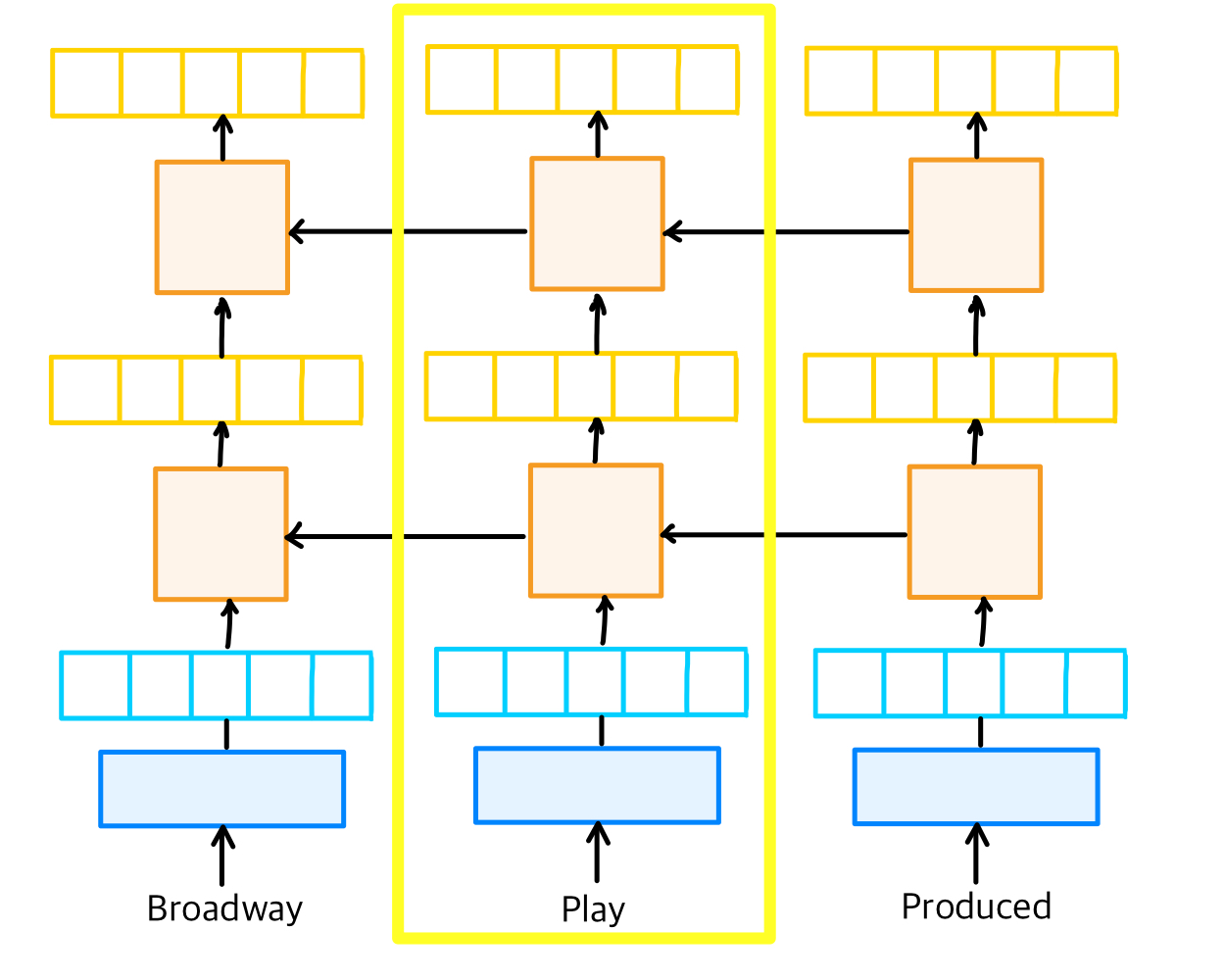
각각 play에서 나온 결과값을 재료로 사용하게된다.
각 층의 출력값을 연결한 후,
출력값 별로 가중치를 둔다. 이게 아까 언급했던, 각 층별로 갖고있는 정보가 다르기 때문에 어떤 정보가 더 중요한지 정해야 한다는 부분이다.
그리고 각 층의 출력값을 모두 더한다.
더한 값에 벡터의 크기를 결정하는 스칼라 매개변수를 곱해준다.
이 내용을 가지고 실습을 해 보자.
Practice
스팸 메일을 분류해 볼 것이다.
ELMo는 아직 텐서플로우 2.x 버전에서는 사용이 불가능하다. 그래서 1.x대 버전으로 낮추고 코드를 실행해야 한다.
아래 코드를 실행해주자.
%tensorflow_version 1.x!pip install tensorflow-hubPackages
import tensorflow_hub as hub
import tensorflow as tf
from keras import backend as K
import urllib.request
import pandas as pd
import numpy as npELMo를 허브로부터 다운로드 해 주자. 객체를 생성하는 아래 코드까지 돌려주자.
elmo = hub.Module("https://tfhub.dev/google/elmo/1", trainable=True)
sess = tf.Session()
K.set_session(sess)
sess.run(tf.global_variables_initializer())
sess.run(tf.tables_initializer())스팸 메일 데이터를 가져와주자.
urllib.request.urlretrieve("https://raw.githubusercontent.com/mohitgupta-omg/Kaggle-SMS-Spam-Collection-Dataset-/master/spam.csv", filename="spam.csv")
data = pd.read_csv('spam.csv',encoding='latin-1')내용을 확인해보자.
data[:5]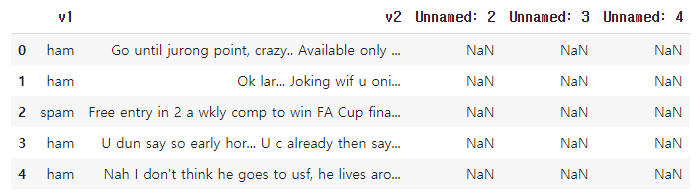
확인해보니 필요없는 열들이 있는 것 같다. Unnamed2,3,4행을 지워주자.
del data['Unnamed: 2']
del data['Unnamed: 3']
del data['Unnamed: 4']다시 확인해보면 사라져있다.
data.keys()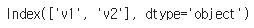
data.info()명령을 이용하여 문서 내용을 확인해보자.

그 중 비어있는 문서가 있는지 확인해보자.
data.isnull().values.any()
비어있는 문서는 없다.
중복되는 문서가 있는지 확인해보자.
data['v2'].nunique(), data['v1'].nunique()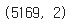
중복되는 문서를 제외하면 5169의 파일이 있다. 뒤에 2는 스팸 메일을 분류하는 태그인 0과 1을 가르킨다.
그렇다면 중복되는 문서는 5672-5169=403개인데, 403개의 문서를 지우고 다시 문서 개수를 확인해보자.
data.drop_duplicates(subset=['v2'], inplace=True)
len(data)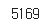
잘 지워진 모습이다.
이제 태그1과 태그0에 각각 몇개의 메일이 있는지 확인해보자.
data['v1'].value_counts().plot(kind='bar')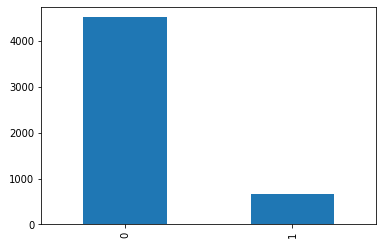
data.groupby('v1').size().reset_index(name='count')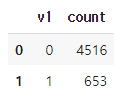
0으로 분류(스팸x)된 메일은 4516개가 있고 1로 분류(스팸o)된 메일은 653개가 있다.
이번엔 메일 내용을 봐보자.
데이터에서 'v2'의 내용을 확인해보려고 한다.
X_data = data['v2']
X_data[:5]위 명령을 실행했을 때,
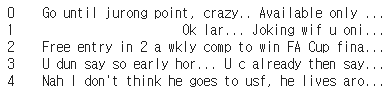
위처럼 왼쪽에 숫자 태그가 함께 붙는다. 이걸 없애주기 위해서 리스트로 묶어주자.
X_data=list(data['v2'])
X_data[:5]
리스트로 정리가 된 모습이다.
v1도 똑같이 해주자.
y_data=list(data['v1'])
y_data[:5]
이전과 다르게 이 데이터에서는 테스트 파일과 트레이닝 파일을 따로 나눠주지 않았다. 8:2의 비율로 나눠주자.
n_of_train = int(len(X_data)*0.8)
n_of_test = int(len(X_data)-n_of_train)
print(n_of_train)
print(n_of_test)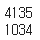
X_train = np.asarray(X_data[:n_of_train])
y_train = np.asarray(y_data[:n_of_train])
X_test = np.asarray(X_data[n_of_train:])
y_test = np.asarray(y_data[n_of_train:])4135개의 트레이닝 파일과 1034개의 테스트 파일로 나누었다.
이제 본격적으로 모델을 만들어보자.
Build Model
먼저 데이터의 이동이 케라스 → 텐서플로우 → 케라스가 되도록 하는 ELMo함수를 정의해준다.
def ELMoEmbedding(x):
return elmo(tf.squeeze(tf.cast(x, tf.string)), as_dict=True, signature="default")["default"]필요한 패키지를 불러와준다.
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Dense, Lambda, Input모델을 만들어준다.
input_text = Input(shape=(1,), dtype=tf.string)
embedding_layer=Lambda(ELMoEmbedding, output_shape=(1024, ))(input_text)
hidden_layer=Dense(256, activation='relu')(embedding_layer)
output_layer=Dense(1, activation='sigmoid')(hidden_layer)
model= Model(inputs=[input_text], outputs=output_layer)
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['acc'])epochs=1로 학습시켜준다.
history=model.fit(X_train, y_train, epochs=1, batch_size=64)
model.evaluate(X_test,y_test)[1]정확도 98.065%가 나왔다.
이번에는 epochs=20으로 학습시켜보자.
정확도는 98.1624%로 조금 더 높았다.
loss와 acc를 각각 그래프로 나타내 보았다.
acc= history2.history['acc']
loss = history2.history['loss']
%matplotlib inline
import matplotlib.pyplot as plt
X_len = np.arange(len(loss))
plt.plot(X_len, loss, marker='.', c="red", label='loss')
plt.plot(X_len, acc, marker='.', c="blue", label='acc')
plt.legend(loc='upper right')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss/acc')
plt.show()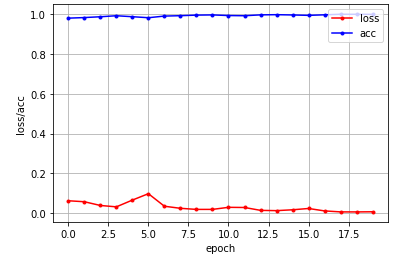
이번 예시에서 그래프로 나타내는 건 사실 의미가 없어 보인다.
그렇지만 궁금해서 한번 해 보았다.
여기서 ELMo에 대한 설명을 마친다.
