
이번에는 이전글의 두번째 버전으로 새로운 파일로 실습해보자.
이번글에서 실습으로 사용된 .csv 파일은 여기서 다운받을 수 있다.
코랩이나 주피터에서 사용할 경우 그 파일과 같은 디렉토리에 .csv파일이 위치할 수 있게 하자. 코랩이라면 이 파일을 업로드하면 된다.
Packages
import pandas as pd
import numpy as np
%matplotlib inline
import matplotlib.pyplot as plt
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from sklearn.model_selection import train_test_split
from tensorflow.keras.utils import to_categorical필요한 패키지들을 다운받아준 후,
방금 올린 .csv파일을 unzip해주자.
Import Data
!unzip ner_dataset.csv파일을 불러와 data안에 저장한다.
data = pd.read_csv("ner_dataset.csv", encoding="latin1")Data Preprocessing
어떻게 생겼는지 확인해보자.
data[:5]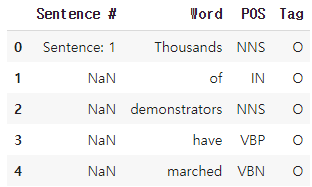
.keys()로 어떤 키값이 있는지 (이미 알긴 하지만) 확인해보자.
이번엔 길이를 확인해보자.
len(data)
이번 실습에서 사용되는 데이터는 조금 특이한 형태이다. 그 중에서 Sentence #행에 Null값이 많다는 것인데, 이 데이터 안에서 Null값이 있는지 없는지 확인해보자.
data.isnull().values.any()
데이터에 Null값이 있다고 뜬다. 어떤 열(keys)에 있는지 확인해보자.
data.isnull().sum()
Sentence #열에서 Null값이 많이 존재한다.
그 이유는 아까 데이터셋을 보면 처음 문장이 시작하는 단어에는 Sentence: 1이라는 표시가 되어있고 그 아래 단어에 대해서는 Null값이 출력된다.
그렇다면 총 몇 문장이 있는지, 중복(여기서는 Null)값을 제거하고 확인해보자.
data['Sentence #'].nunique()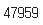
이어서 Word열과 Tag열에서도 중복값을 제외한 값이 얼마나 있는지 확인해보자.
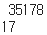
중복값을 제거했으므로, 이 데이터 안에는 35178개의 단어가 존재하고, 총 17개의 태깅 개수를 가지고 있다.
17개의 태그 분포가 어떻게 되어있는지 확인하기 위해서 그래프로 그려보았다.
data['Tag'].value_counts().plot(kind = 'bar')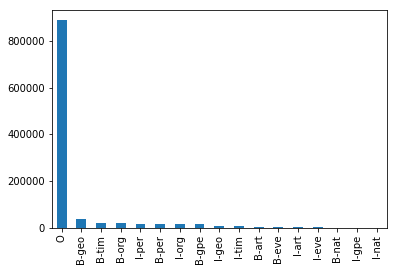
이렇게 봐서는 0으로 태깅되지 않은 것들의 분포를 보기 힘들다.
정확한 숫자로 확인해보자.
data.groupby('Tag').size().reset_index(name='count')
각각의 태그에 대해서 개수를 확인할 수 있다.
태그 0이 신경쓰이니, 이 부분에 대해서 전처리를 해주자.
Sentence:1뒤에 있는 Null태그에 대해 그 앞에있는 태그값을 부여해주자. 이렇게 되면 Null값은 사라질 것이다. 여기서는 .fillna(methond='ffill')을 사용할 것이다. 여기에서 더 자세한 내용을 알 수 있다.
data = data.fillna(method="ffill")이렇게 한 후, 데이터 앞 부분부터 확인해주자.
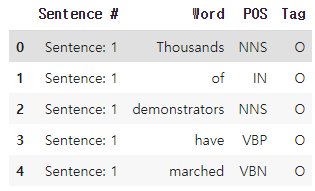
잘 채워진 모습이다.
이제 다시 한번 Null값이 있는지 없는지 확인해보자.

없다고 나온다.
이번에는 Word열 안에 있는 모든 단어를 소문자화하여 단어의 개수를 줄여보자.
data['Word'] = data['Word'].str.lower()중복을 제거한 단어의 길이를 확인해보자.
data.Word.nunique()
원래 Word열의 개수는 35178개였다. 소문자로 바꾸고 중복을 제거하니 31817로 줄어들었다.
다시 5개를 출력해 소문자화가 되었는지 확인해보자.
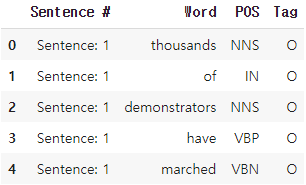
소문자로 바뀌었다.
Pairing
이제 이 테이블에서 중요하게 봐야할 것은 Word열과 Tag열이다. 이 둘을 pair로 묶는 작업을 해야 한다.
우선 Sentence #에 대해서 같은 Sentence를 갖는 문장은 같은 샘플 안에 있어야 한다. 이 작업은 groupby함수를 통해서 이루어진다. 그리고 그 하나의 샘플에 대해서는 Word와 Tag열에 같은 레벨에 있는 단어들을 tolist함수를 사용해 묶어준다.
아래 코드처럼 구현한다.
func = lambda temp: [(w, t) for w, t in zip(temp["Word"].values.tolist(), temp["Tag"].values.tolist())]
tagged_sentences=[t for t in data.groupby("Sentence #").apply(func)]이후에 첫번째 샘플을 출력해보자.
tagged_sentences[0]
Sentence #1에 해당하는 단어들이 같이 모였고, 각각의 단어들에 대해 태그값도 같이 묶여있다.
이번엔 몇개의 샘플이 있는지 확인해보자.
len(tagged_sentences)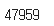
47959개의 문장이 있다.
Split Data
이전 글들에서도 같은 작업을 했지만, 단어와 태그를 따로 분리해야 한다. 여기서는 sentences와 ner_tags에 각각 저장해보자.
먼저 빈 리스트를 만들어준 후,
각각의 샘플에 대해 zip을 사용하여 단어들과 태그들을 분리해준다.
각각을 sentences와 ner_tags안에 저장해주면 된다.
sentences, ner_tags = [], []
for tagged_sentence in tagged_sentences:
sentence, tag_info = zip(*tagged_sentence)
sentences.append(list(sentence))
ner_tags.append(list(tag_info)) 첫번째 문장에 대해 sentences와 ner_tags내용을 확인해보자.
잘 분리되었다.
이제 토크나이저로 정수 인코딩을 해보자.
Encoding
문장 데이터의 모든 단어를 사용하여 정수 인코딩을 해준다.
단어 인덱스 1에는 단어 OOV를 할당해주고,
태그 인덱스에는 대문자를 유지한 채로 저장해준다.
rc_tokenizer = Tokenizer(oov_token='OOV')
src_tokenizer.fit_on_texts(sentences)
tar_tokenizer = Tokenizer(lower=False)
tar_tokenizer.fit_on_texts(ner_tags)이후에 vocab_size와 tag_size안에 각각의 길이를 저장해준 후 출력해서 확인해보자.
vocab_size = len(src_tokenizer.word_index) + 1
tag_size = len(tar_tokenizer.word_index) + 1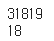
인코딩을 해 주었으므로 단어 집합의 크기는 31819개, 태그의 크기는 18개가 되었다.
이 src_tokenizer.word_index 내용을 확인해보았다.

아까 우리가 1로 설정해 놓았던 OOV와 그 밑에 다른 단어들이 빈도순으로 정리되어있다.
tar_tokenizer.word_index도 확인해보자.

여기서 정리된 표를 가지고 정수 인코딩을 한다.
이 단어들을 숫자로 변환해준다.
X_data = src_tokenizer.texts_to_sequences(sentences)
y_data = tar_tokenizer.texts_to_sequences(ner_tags)X_data[0]과 y_data[0]을 출력해서 확인해보자.

단어들이 해당하는 숫자로 바뀌었다.
Decoding
이 작업은 훈련이 끝난 후 결과 확인을 위해 인덱스로부터 다시 단어를 리턴하는 index_to_word를 만드는 작업이다. 태깅도 다시 바꿔줘야 하므로 index_to_ner도 만들어주자.
word_to_index = src_tokenizer.word_index
index_to_word = src_tokenizer.index_word
ner_to_index = tar_tokenizer.word_index
index_to_ner = tar_tokenizer.index_word
index_to_ner[0] = 'PAD'마지막 줄은 0인 인덱스를 PAD로 바꿔서 출력한다.
시험삼아 index_to_ner내용을 확인해보자.

위에서 확인한 tar_tokenizer.word_index과 반대되는 모습이다. 이번엔 숫자를 글자로 바꿔주었다.
이 내용은 훈련이 끝난 후 확인해보도록 하자.
Padding
패딩을 위해 샘플의 최대 길이와 평균 길이를 확인해보자.
print('샘플의 최대 길이 : %d' % max(len(l) for l in sentences))
print('샘플의 평균 길이 : %f' % (sum(map(len, sentences))/len(sentences)))
plt.hist([len(s) for s in sentences], bins=50, color='green')
plt.xlabel('length of samples')
plt.ylabel('number of samples')
plt.show()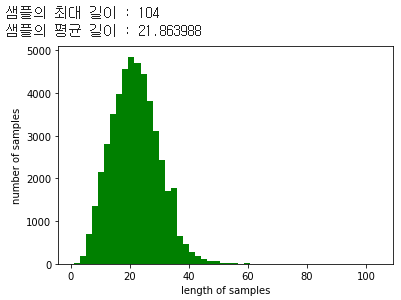
max_len의 길이를 70정도로 정하면 괜찮을 것 같다.
70으로 정해주고 패딩해주자.
max_len = 70
X_data = pad_sequences(X_data, padding='post', maxlen=max_len)
y_data = pad_sequences(y_data, padding='post', maxlen=max_len)Split Data
이제 데이터를 훈련 데이터와 테스트 데이터로 분리해준다. 여기서는 8:2 비율로 분리해보자.
X_train, X_test, y_train, y_test = train_test_split(X_data, y_data, test_size=.2, random_state=777)One-Hot Encoding
태깅 정보들에 대해 원-핫 인코딩을 해준다.
test와 train파일에 모두 해줘야 한다.
y_train = to_categorical(y_train, num_classes=tag_size)
y_test = to_categorical(y_test, num_classes=tag_size)이제 학습을 시켜주자.
Build Model
Packages
from keras.models import Sequential
from keras.layers import Dense, LSTM, InputLayer, Bidirectional, TimeDistributed, Embedding
from tensorflow.keras.optimizers import AdamAdd Layer
model = Sequential()
model.add(Embedding(vocab_size, 128, mask_zero=True))
model.add(Bidirectional(LSTM(256, return_sequences=True)))
model.add(Dense(tag_size, activation=('softmax')))
model.compile(loss='categorical_crossentropy', optimizer=Adam(0.001), metrics=['accuracy'])history = model.fit(X_train, y_train, batch_size=128, epochs=10, validation_split=0.1)그래프로 나타내 보았다.
epochs = range(1, len(history.history['val_loss']) + 1)
plt.plot(epochs, history.history['loss'])
plt.plot(epochs, history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'val'], loc='upper left')
plt.show()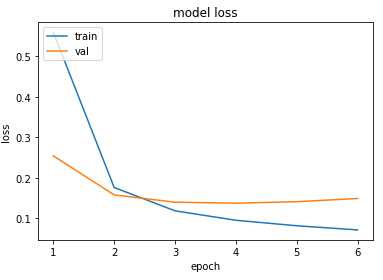
여기서 정확도를 구하려고 하면 아주 높은 수치가 나올 것이다. 그 이유는 이전 글에 마지막 부분에서도 소개해 놓았다.
따라서 여기서는 F1-Score방식을 사용해서 정확도를 구해보자.
F1-Score
F1-Score를 사용하기 위해 먼저 seqeval을 다운받아준다.
!pip install seqeval그리고 예측값을 index_to_ner를 사용하여 태깅 정보로 변경하는 함수를 만들어준다. 이 함수 안에서는 전체 시퀀스로부터 시퀀스를 하나씩 꺼낸 후, 각 시퀀스로부터 예측값을 하나씩 꺼낸다. 아까 0을 PAD로 바꿔주었지만 여기서는 반대로 PAD를 0으로 변경해준다.
def sequences_to_tag(sequences): # 예측값을 index_to_ner를 사용하여 태깅 정보로 변경하는 함수.
result = []
for sequence in sequences: # 전체 시퀀스로부터 시퀀스를 하나씩 꺼낸다.
temp = []
for pred in sequence: # 시퀀스로부터 예측값을 하나씩 꺼낸다.
pred_index = np.argmax(pred) # 예를 들어 [0, 0, 1, 0 ,0]라면 1의 인덱스인 2를 리턴한다.
temp.append(index_to_ner[pred_index].replace("PAD", "O")) # 'PAD'는 'O'로 변경
result.append(temp)
return result위함수를 y_predicted와 y_test에 적용해준다.
y_predicted = model.predict([X_test])
pred_tags = sequences_to_tag(y_predicted)
test_tags = sequences_to_tag(y_test)그리고 리포트를 리턴해보자.
from seqeval.metrics import precision_score, recall_score, f1_score, classification_report
print(classification_report(test_tags, pred_tags))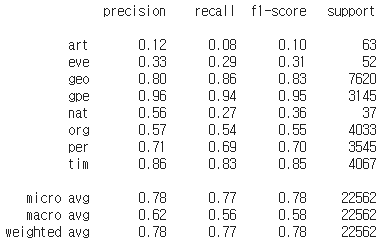
이와 같은 결과를 얻는다.
마지막으로 정확도를 반환해주면 된다.
print("F1-score: {:.1%}".format(f1_score(test_tags, pred_tags)))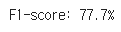
이 모델의 정확도는 77.7%정도가 나온다.
여기서 설명을 마치겠다.
