
이번 글에서는 개체명 인식을 소개한다.
개체명 인식은 대표적인 시퀀스 레이블링 태스크에 속하는데,
시퀀스 레이블링이란 [x1, x2, x3, ... ,xn]에 대해서 [y1, y2, y3, ... ,yn]을 각각 부여하는 작업을 말한다.
아래 예제 파일을 미리 가져와보겠다.
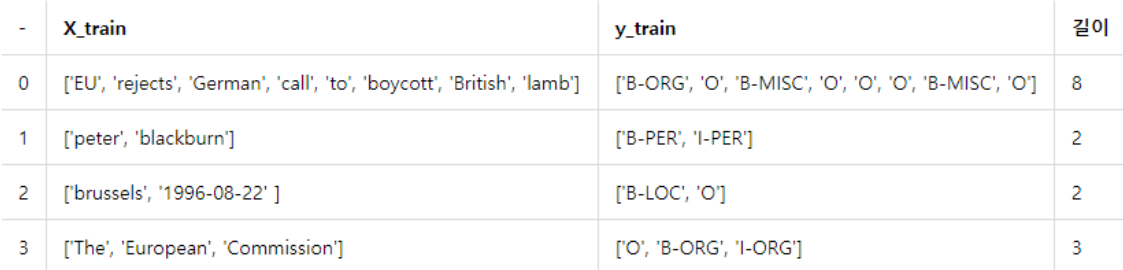
각 단어에 대해 출력값이 있기 때문에
return_sequences = True를 꼭 설정해 주어야 한다.
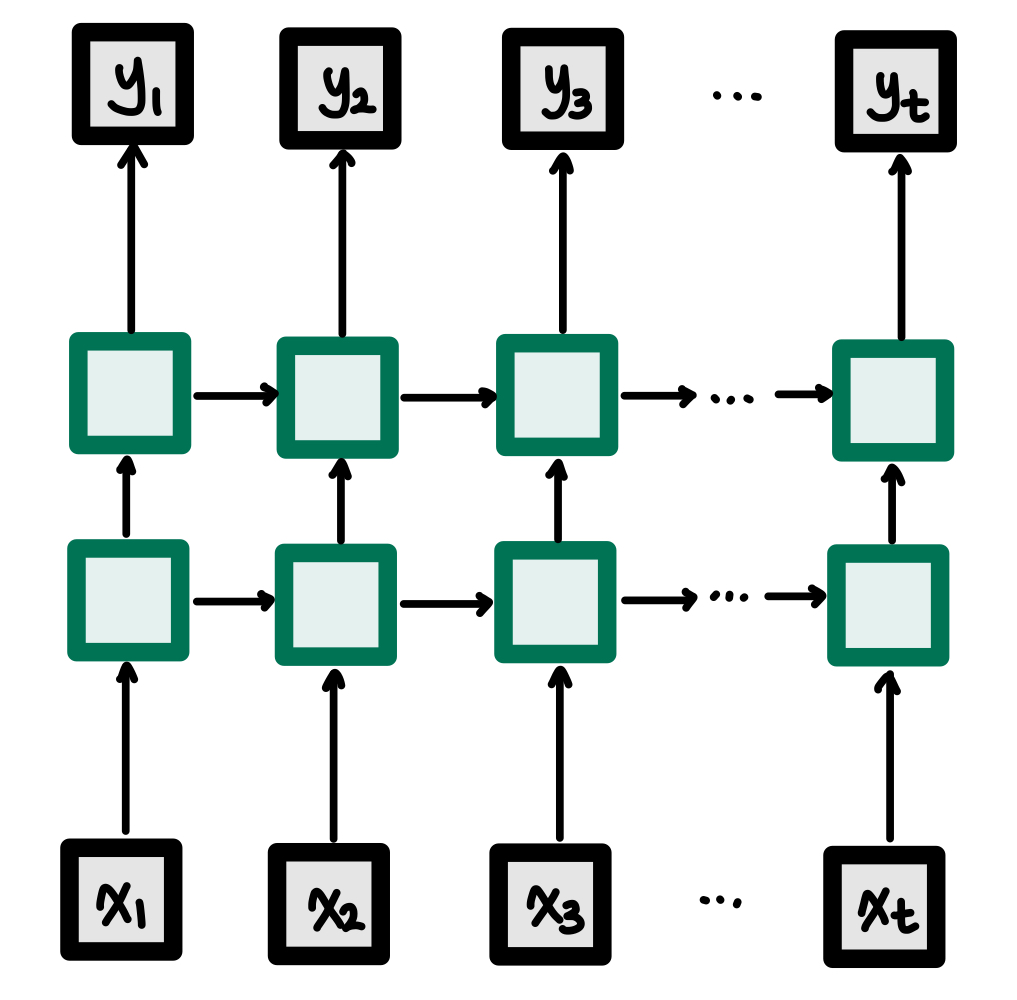
위 그림처럼 매 x값마다 y값을 예측해야 하기 때문이다.
이제 각각의 값이 어떤 것을 의미하는지 확인해보자.
James is working at Disney in London이라는 문장을 개체명 인식을 통해 출력값을 뽑아보면
[('James', 'NNP'), ('is', 'VBZ'), ('working', 'VBG'), ('at', 'IN'), ('Disney', 'NNP'), ('in', 'IN'), ('London', 'NNP')]이라는 값이 나온다.
이처럼 매 텍스트를 인명, 단체, 장소, 수치 등 이미 정의된 태그들로 분류하는 작업이다. 이런 태깅 방식을 BIO Tagging이라고 한다.
- B는 Begin의 약자로 개체명이 시작되는 부분을 의미한다.
- I는 Inside의 약자로 개체명의 내부 부분을 의미한다.
- O는 Outside의 약자로 개체명이 아닌 부분을 의미한다.
예를들어, 아이패드 갖고싶다라는 문장에서 각각의 단어는
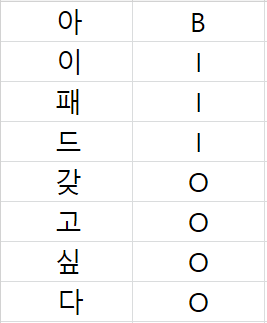
이런식으로 태깅될 것이다.
이 뒤에 그 단어가 사람이라면 -Per이라는 태그가, 조직이라면 -Org라는 태그가 붙게 된다.
BIO Tagging에 대한 더 자세한 내용은 여기에서 확인할 수 있다.
이제 예제로 직접 확인해보자.
Practice
Packages
import urllib.request
import re
%matplotlib inline
import matplotlib.pyplot as plt
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.utils import to_categorical
from sklearn.model_selection import train_test_split
import numpy as npData Preprocessing
urllib.request.urlretrieve("https://raw.githubusercontent.com/Franck-Dernoncourt/NeuroNER/master/neuroner/data/conll2003/en/train.txt", filename="train.txt")위 파일을 다운받아주면

train.txt파일을 확인할 수 있다. 파일을 읽어서f에 저장해주자.
f = open('train.txt', 'r')이대로 파일을 열수는 없다.
길이가 0이거나 필요없는 줄은 출력하지 않고, 9번째 줄이 되면 for문을 탈출하는 코드를 작성해서 내용을 확인해 보았다.
i = 0
for line in f:
if len(line) == 0 or line.startswith('-DOCSTART'):
continue
i = i + 1
if i == 1:
continue
print(line, end='')
if i == 9:
break
단어 바로 옆에 붙어있는 태그는 품사 태깅이다. British옆에 붙어있는 JJ는 Adjective, scientists옆에 있는 NNS는 Noun, plural을 의미한다. 여기에서 더 자세한 내용을 확인할 수 있다.
그 옆에 있는 태그는 위에서 언급했던 개체명 태깅이다. NP는 noun phrase, VP는 verb phrase, 등등 아래와 같은 뜻을 가지고 있다.

출처는 여기.
위에서 더 확인할 수 있다.
처음에 설명했다시피, B가 붙으면 개체명의 시작 부분이라는 뜻이다. 맨 처음 글자인 British에서 B-NP는 개체명의 시작 부분이면서 명사라는 뜻을 가진 태그가 붙는다. 아직 단어가 끝나지 않고 뒤에 lamb라는 단어가 이어지면서 I-NP라는 태그가 다시 붙는다. 이 두 단어는 하나의 개체명인 것이다. 이제 개체명 인식이 종료되었고 뒤에 B-SBAR라는 태그가 붙은 until 단어가 다시 등장하게 된다.
이제 유효한 문장들에 대해서만 전처리를 해 주고 tagged_sentences에 저장하여 정리해보자.
f = open('train.txt', 'r')
tagged_sentences = []
sentence = []
for line in f:
if len(line)==0 or line.startswith('-DOCSTART') or line[0]=="\n":
if len(sentence) > 0:
tagged_sentences.append(sentence)
sentence = []
continue
splits = line.split(' ') # 공백을 기준으로 속성을 구분한다.
splits[-1] = re.sub(r'\n', '', splits[-1]) # 줄바꿈 표시 \n을 제거한다.
word = splits[0].lower() # 단어들은 소문자로 바꿔서 저장한다.
sentence.append([word, splits[-1]]) # 단어와 개체명 태깅만 기록한다.tagged_sentences의 길이를 확인해보자.
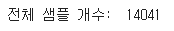
14041개의 문장이 있다.
첫번째 샘플을 출력해서 확인해보자.

데이터와 레이블이 한꺼번에 출력된다.
따로따로 sentences와 ner_tags안에 저장해줘야 한다.
Split Data
데이터와 레이블을 분리해주자.
먼저 전체 샘플 (14041개) 중에서 각 문장에 대해, zip함수를 이용하여 단어들은 sentences에, 레이블은 ner_tags안에 저장한다.
sentences, ner_tags = [], []
for tagged_sentence in tagged_sentences:
sentence, tag_info = zip(*tagged_sentence)
sentences.append(list(sentence))
ner_tags.append(list(tag_info)) 이후에 sentence[0]과 ner_tags[0]를 출력해보자.
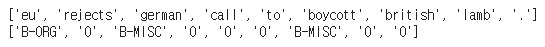
정상적으로 분리되었다.
여기서 각 태그 목록에 대해 어떤 태그가 가장 많이 사용되었는지 확인해보려고 코드를 돌렸는데,
이런 결과가 나왔다. 아마 한 차원에 각각의 태그가 합쳐져 있어서 그런 것 같다.
토큰화를 통해서 단어 집합을 만들어주자.
Tokenization
최대 단어수는 높은 빈도수를 가진 단어 4000개로 제한하고 토큰화를 진행한다.
그 이외의 단어에 대해서는 OOV로 채워준다.
max_words = 4000
src_tokenizer = Tokenizer(num_words=max_words, oov_token='OOV')
src_tokenizer.fit_on_texts(sentences)이번에는 태깅 목록에도 토큰화를 해 주자.
tar_tokenizer = Tokenizer()
tar_tokenizer.fit_on_texts(ner_tags)토큰화 한 결과를 가지고 단어집합의 크기와 태깅 정보 집합의 크기를 각각 구해보자.
vocab_size = max_words + 1
tag_size = len(tar_tokenizer.word_index) + 1
print('단어 집합의 크기 : {}'.format(vocab_size))
print('개체명 태깅 정보 집합의 크기 : {}'.format(tag_size))
아까 설정한대로 단어집합은 4001개, 개체명 태깅 정보는 10개이다.
Encoding
texts_to_sequences를 사용하여 정수 인코딩을 해주자.
X_train = src_tokenizer.texts_to_sequences(sentences)
y_train = tar_tokenizer.texts_to_sequences(ner_tags)X_train과 y_train의 첫번째 샘플을 각각 출력한 결과다.
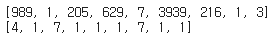
글자가 숫자로 변환되었다.
현재는 문장 데이터 중 빈도수가 4000번째 이상의 글자에 대해서는 OOV로 대체가 되었다. 이를 확인하기 위해 다시 Decoding을 해보자. 디코딩은 인코딩의 반댓말로, 숫자를 다시 단어로 리턴하는 것이다.
index_to_word = src_tokenizer.index_word
index_to_ner = tar_tokenizer.index_word첫번째 샘플 안의 인덱스들에 대해 디코딩 결과를 확인해보자.
decoded = []
for index in X_train[0] :
decoded.append(index_to_word[index]) 출력해보자.
print('기존 문장 : {}'.format(sentences[0]))
print('빈도수가 낮은 단어가 OOV 처리된 문장 : {}'.format(decoded))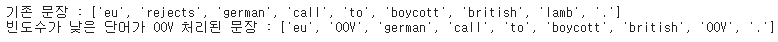
여기서는 rejects라는 단어와 lamb라는 단어가 OOV로 대체되었다.
다음으로 패딩을 위해 샘플의 최대 길이와 평균 길이를 확인해보자.
Padding
print('샘플의 최대 길이 : %d' % max(len(l) for l in X_train))
print('샘플의 평균 길이 : %f' % (sum(map(len, X_train))/len(X_train)))
plt.hist([len(s) for s in X_train], bins=50)
plt.xlabel('length of samples')
plt.ylabel('number of samples')
plt.show()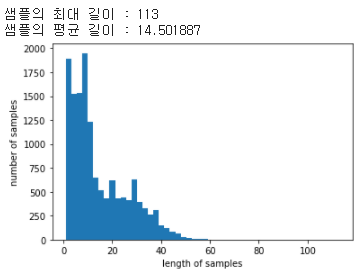
최대 길이는 113, 평균 길이는 14.5이다.
패딩을 위한 최대 길이는 90으로 정해보자.
max_len = 90
X_train = pad_sequences(X_train, padding='post', maxlen=max_len)
y_train = pad_sequences(y_train, padding='post', maxlen=max_len)90보다 모자란 샘플에 대해서는 0으로 채워주고 90보다 긴 샘플에 대해서는 길이를 잘라준다. 이전에는 X_train에 대해서만 패딩을 해 주었지만, 여기서는 레이블도 같은 길이를 가지고 있기 때문에 X_train과 y_train 둘다에게 같은 작업을 해준다.
print(X_train.shape)
print(y_train.shape)각각의 .shape를 출력해주면

길이가 맞춰진 모습이다.
Split Data
오버피팅을 방지하기 위해val데이터와 train데이터를 2:8 비율로 분리해주자.
X_train, X_test, y_train, y_test = train_test_split(X_train, y_train, test_size=.2, random_state=777)레이블에 대해서 원-핫 인코딩을 아직 안해줬다.
One-hot Encoding
y_train = to_categorical(y_train, num_classes=tag_size)
y_test = to_categorical(y_test, num_classes=tag_size)y_train[0]을 출력해 보았다.

위 모습에서

이 모습으로 바뀌었다.
이제 모델을 구축해보자.
Build Model
Packages
from keras.models import Sequential
from keras.layers import Dense, Embedding, LSTM, Bidirectional, TimeDistributed
from tensorflow.keras.optimizers import AdamBi LSTM을 만들어주자.
model = Sequential()
model.add(Embedding(input_dim=vocab_size, output_dim=128, input_length=max_len, mask_zero=True))
model.add(Bidirectional(LSTM(256, return_sequences=True)))
model.add(Dense(tag_size, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer=Adam(0.001), metrics=['accuracy'])훈련시켜준다.
history = model.fit(X_train, y_train, batch_size = 256, epochs = 20, validation_data=(X_test, y_test))
트레이닝 세트에 대한 정확도는 99%가 나왔는데 검증 세트에 대해서는 95%의 정확도가 나왔다.
max_len을 너무 크게 잡은거 아닌가? max_len이 크면 클수록 성능이 좋아져야 하는거 아닌지 궁금하다.
그래프로 확인해 보았다.
epochs = range(1, len(history.history['accuracy']) + 1)
plt.plot(epochs, history.history['accuracy'])
plt.plot(epochs, history.history['val_accuracy'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epochs')
plt.legend(['train', 'test'], loc='lower right')
plt.show()
epochs = range(1, len(history.history['loss']) + 1)
plt.plot(epochs, history.history['loss'])
plt.plot(epochs, history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epochs')
plt.legend(['train', 'test'], loc='upper right')
plt.show()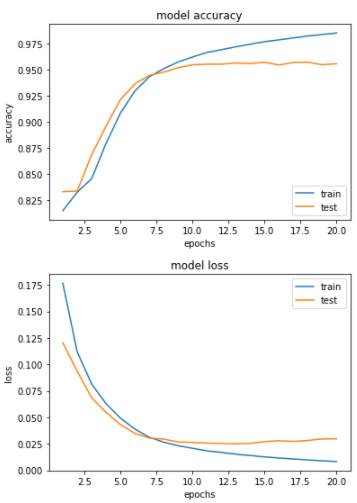
Evaluate
실제로 맞추고 있는지 테스트 데이터와 실제값을 비교해보자.
i=10 # 확인하고 싶은 테스트용 샘플의 인덱스.
y_predicted = model.predict(np.array([X_test[i]])) # 입력한 테스트용 샘플에 대해서 예측 y를 리턴
y_predicted = np.argmax(y_predicted, axis=-1) # 원-핫 인코딩을 다시 정수 인코딩으로 변경함.
true = np.argmax(y_test[i], -1) # 원-핫 인코딩을 다시 정수 인코딩으로 변경함.
print("{:15}|{:5}|{}".format("단어", "실제값", "예측값"))
print(35 * "-")
for w, t, pred in zip(X_test[i], true, y_predicted[0]):
if w != 0: # PAD값은 제외함.
print("{:17}: {:7} {}".format(index_to_word[w], index_to_ner[t].upper(), index_to_ner[pred].upper()))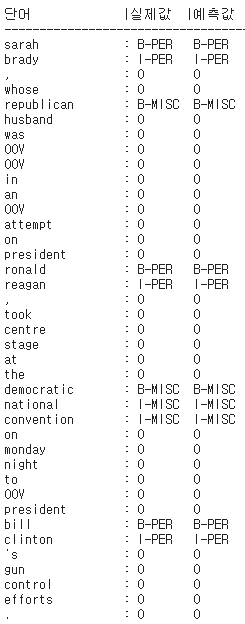
다 맞춘 모습이다.
하지만 여기서 사용된 측정 방법이 적절하지는 않았다. 대부분의 데이터가 개체명이 아니라는 O로 태깅되었기 때문에 예측의 정확도가 O만 맞아도 확 올라가버리는 상황이다.
예를 들어,
코로나 검사를 하는데 정확도를 99%라고 하자. 여기서 양성은 사실 몇명 되지 않고 음성이 많은 상황에서 코로나 진단 키트는 아마 많은 음성 사람들에 대해 음성이라는 결과를 도출할 것이고, 중요한 양성 사람들을 양성이라고 도출하는 부분에서 이 코로나 키트의 정확성이 판단된다.
총 100명 중, 양성 세명 중에서 두명을 양성이라고 판단하고 한명을 음성이라고 판단했다고 했을 때, 이 키트의 정확도는 99%가 된다. 사실상 이 키트는 3명중 1명을 정확하게 판단하지 못한 건데 음성 사람 97명을 맞췄기 때문에 99%라는 정확도가 나온 것이다.
이런 예시의 정확도를 판단하기 위해서는 F1-score를 도입하는 것이다. 이에 대해서는 다음에 설명하도록 한다.
