
아직 이 블로그에선 언급한 적이 없지만, NNLM (Neural Network Language Model)이라는 모델이 있다. 이 모델에 대해서 간략하게 설명하자면, 문장의 단어들 중에서 사용자가 지정한 n개의 단어들만 입력받을 수 있다.
여기서 발생하는 문제점이 있는데, 만약 문장의 길이가 길어지거나 문장의 앞부분에 중요한 정보가 있다면 이를 충분히 반영하기 어려워진다. 이런 문제들을 조금이라도 해결하기 위해서 RNN Language Model이 나왔다.
RNN Language Model
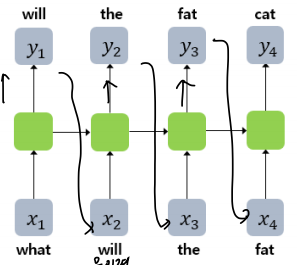
위 그림과 같은 형태를 가지고 있는데, 각각의 단어를 입력받고 다음 단어를 예측하는 모델이다.
특이한 점은, 훈련 시에 예측값을 사용하지 않고 실제값을 사용한다는 것인데, 예측값을 사용하지 않는 이유는 훈련시간이 너무 오래 걸리기 때문이다.
예를들어, What did you do today라는 문장에서 What did you do를 입력하면 did you do today가 예측되도록 훈련시킨다.
이런 모델은 이전 문장을 넣고 다음 문장을 예측하기 때문에, 이전 글에서 설명했던 Bidirectional RNN과 같은 양방향으로는 사용할 수 없다.
조금 더 구체적으로 살펴보자.
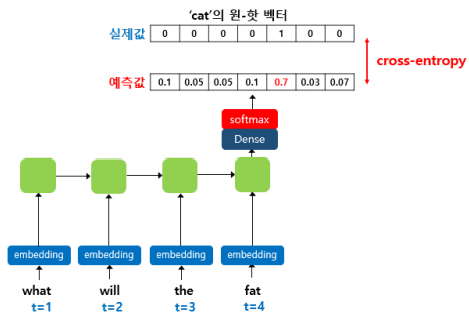
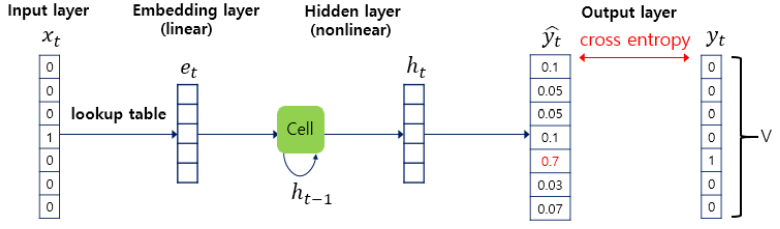
위와 같이 이 RNN Language Model은
- Embedding Layer
- Hidden Layer
- Output Layer
로 구성되어있다.
본격적으로 살펴보도록 하자.
데이터 전처리
import numpy as np
import urllib.request
from tensorflow.keras.utils import to_categorical
urllib.request.urlretrieve("http://www.gutenberg.org/files/11/11-0.txt", filename="11-0.txt")
f = open('11-0.txt', 'rb')
lines = []
for line in f: #데이터를 한줄씩
line = line.strip() #.strip()을 통해 \r, \n을 제거
line = line.lower() #소문자화
line = line.decode('ascii', 'ignore') #바이트 열 제거
if len(line) > 0:
lines.append(line)
f.close()첫번째 전처리를 해 주고 난 후 lines[:5]명령으로 처음 다섯줄을 출력해보자.

우리가 원하는대로 전처리가 잘 되었다.
이제 각 줄을 합쳐서 글자의 개수를 출력해보자.
text = ' '.join(lines)
print(len(text))출력값은 159612가 나온다.
즉, 문자열의 길이, 총 글자의 개수가 159612이다.
여기서 주의해야할 점은 단어가 아니라 글자라는 점이다!
이제 글자 집합의 크기를 확인해보자.
char_vocab = sorted(list(set(text)))
vocab_size = len(char_vocab)
print(vocab_size))출력 결과는 57이다. 즉, 57개의 글자들이 있다는 뜻이다. 각각의 글자의 고유 정수값을 부여해주자.
char_to_index = dict((c,i) for i, c in enumerate(char_vocab))
print(char_to_index){' ': 0, '!': 1, '"': 2, '#': 3, '$': 4, '%': 5, "'": 6, '(': 7, ')': 8, '*': 9, ',': 10, '-': 11, '.': 12, '/': 13, '0': 14, '1': 15, '2': 16, '3': 17, '4': 18, '5': 19, '6': 20, '7': 21, '8': 22, '9': 23, ':': 24, ';': 25, '?': 26, '@': 27, '[': 28, ']': 29, '_': 30, 'a': 31, 'b': 32, 'c': 33, 'd': 34, 'e': 35, 'f': 36, 'g': 37, 'h': 38, 'i': 39, 'j': 40, 'k': 41, 'l': 42, 'm': 43, 'n': 44, 'o': 45, 'p': 46, 'q': 47, 'r': 48, 's': 49, 't': 50, 'u': 51, 'v': 52, 'w': 53, 'x': 54, 'y': 55, 'z': 56}
이런 출력값이 나오게 된다. 앞에서도 말했듯이 우리가 방금 한 일은 단어에게 정수를 준 것이 아닌, 글자에게 정수를 부여한 것이다!
위의 결과값이 조금 불편하다.
' ':0 대신 0:' '으로 바꿔주기 위해 아래 코드를 돌리자.
index_to_char={}
for key, value in char_to_index.items():
index_to_char[value] = key그러면
{0: ' ', 1: '!', 2: '"', 3: '#', 4: '$', 5: '%', 6: "'", 7: '(',...이런식으로 뒤바뀌게 된다.
위 그림을 다시 한번 살펴보자.
예를 들어, 샘플의 길이(t)가 4라면 4개의 입력 글자 시퀀스로부터 4개의 출력 글자 시퀀스를 예측하게 된다.
appl을 입력하면 pple을 출력하는 형식이다.
여기서 appl은 train_X(입력 글자 시퀀스), pple은 train_y(예측해야 하는 시퀀스)에 저장된다.
seq_length = 60 #문장의 길이를 60으로
n_samples = int(np.floor((len(text)-1) / seq_length)) #문자열 60등분. 즉, 총 샘플의 개수가 됨
print('문장 샘플의 수 : {}'.format(n_samples))문장 샘플의 수 : 2658
train_X = []
train_y = []
for i in range(n_samples):
X_sample = text[i * seq_length: (i+1) * seq_length]
#0:60 -> 60:120 -> 120:180로 loop를 돌면서 문장 샘플을 1개씩 가져온다.
X_encoded = [char_to_index[c] for c in X_sample]
train_X.append(X_encoded)
y_sample = text[i * seq_length + 1 : (i+1) * seq_length +1] #오른쪽으로 한칸 옮긴다
y_encoded = [char_to_index[c] for c in y_sample]
train_y.append(y_encoded)전체 문장을 X_sample에 입력하고, 하나의 문장 샘플에 대해서 정수 인코딩 한 값을 X_encoded안에 넣어준다. 그리고 각 문장의 값을 train_X라는 공간에 한 문장씩 넣어준다.
y도 마찬가지로 넣어준다. 이때 여기서 한칸 옮겨주는(i * seq_length + 1 : (i+1) * seq_length +1)이유는 위에서도 봤다시피 다음 글자를 예측하기 위함인데, 실제로 우리가 X_sample과 y_sample을 출력해보면 명확하게 알 수 있다.
X_sample:
the project gutenberg ebook of alices adventures in wonderla
y_sample
he project gutenberg ebook of alices adventures in wonderlan
오른쪽으로 한칸 옮긴 모습이다.
마지막 출력값인 train_X[0]과 train_y[0]을 출력해봐도 같은 결과를 얻을 수 있다.
train_X[0]
[50, 38, 35, 0, 46, 48, 45, 40, 35, 33, 50, 0, 37, 51, 50, 35,
train_y[0]
[38, 35, 0, 46, 48, 45, 40, 35, 33, 50, 0, 37, 51, 50, 35,
오른쪽으로 한 칸 옮긴 모습이다.
이제 One-hot 인코딩을 해주자.
train_X = to_categorical(train_X)
train_y = to_categorical(train_y)
print('train_X의 크기(shape) : {}'.format(train_X.shape))
print('train_y의 크기(shape) : {}'.format(train_y.shape))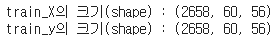
이는 샘플의 수가 2658개, 입력 시퀀스(input_length)가 60, 각 벡터의 차원(input_dim)이 56임을 의미한다.
모델 설계하기
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM, TimeDistributed
model = Sequential()
model.add(LSTM(256, input_shape=(None, train_X.shape[2]), return_sequences=True))
model.add(LSTM(256, return_sequences=True))
model.add(TimeDistributed(Dense(vocab_size, activation='softmax')))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(train_X, train_y, epochs=80, verbose=2)이제 다음 글자를 예측하는 함수를 만들어보자.
def sentence_generation(model, length):
ix = [np.random.radint(vocab_size)]
y_char = [index_to_char[ix[-1]]]
print(ix[-1],'번 글자',y_char[-1],'로 예측을 시작!')
X = np.zeros((1, length, vocab_size)) # (1, length, 55) 크기의 X 생성. 즉, LSTM의 입력 시퀀스 생성
for i in tf.range(length):
i = tf.cast(i, tf.int64)
X[0][i][ix[-1]] = 1 # X[0][i][예측한 글자의 인덱스] = 1, 즉, 예측 글자를 다음 입력 시퀀스에 추가
print(index_to_char[ix[-1]], end="")
ix = np.argmax(model.predict(X[:, :i+1, :])[0], 1)
y_char.append(index_to_char[ix[-1]])
return ('').join(y_char)우선 글자에 대한 랜덤 인덱스 ix를 생성한다. 그리고 ix로부터 글자를 생성한다. 해당 정보를 가지고 나중에 출력에 사용될 문장을 입력한다.
마지막에 length길이의 글자를 출력하게 될 텐데, 그 공간을 X로 정의해준다.
그리고 length에 대해서 반복문에 위에서 만들었던 모델을 넣어 실행시킨다.
sentence_generation(model, 100)그럼 결과가 나온다.
35 번 글자 e 로 예측을 시작! e to say out of the way is. station. what extled its all asked ays. as she said the last word with s'e to say out of the way is. station. what extled its all asked ays. as she said the last word with su'
이렇게 캐릭터 단위의 RNN언어모델을 설게해보았다.
