PIXART-α : Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis
📖Paper
해당 논문은 2023년도 10월에 나온 아주 따끈따끈한 논문이다.
성능이 너무 좋아서 궁금해서 읽어봤는데 computing cost를 저렇게 많이 낮추면서 성능까지 좋다니 점점 더 발전해나가는 것 같다,,
1. INTRODUCTION
최근 T2I 생성 모델의 발전이 사실적인 이미지 합성 시대를 열었다. 이 모델들은 다양한 downstream task에 영향을 미치고 있으나 엄청난 computing cost를 요구한다.
이러한 엄청난 비용은 연구 커뮤니티와 기업가들이 이러한 모델에 접근하는데 장벽이 있고 AIGC 커뮤니티의 중요한 발전을 제한하고 있다.
해당 논문에선 SOTA 이미지 생성 모델과 경쟁력있는 이미지 품질을 유지하면서 훈련 computing cost를 줄인 PIXART-α 를 소개한다.

해당 논문에서의 3가지 핵심 아이디어는 다음과 같다.
1. Training strategy decomposition
각각 pixel dependency, textimage alignment 및 image aesthetic quality을 최적화하기 위한 세 가지 하위 task으로 나눴다.
훈련 효율을 높이는 동시에 이미지 생성 품질을 유지하는 방식으로 복잡한 task에 접근한다.
2. Efficient T2I Transformer
Diffusion Transformer에 cross attention 모듈을 통합하여 text condition을 넣고 계산량이 많은 class condition branch를 간소화하여 효율성 향상시켰다. 또한 class-condition 모델의 매개변수를 직접 불러올 수 있게 하는 reparameterization을 소개했다.
따라서 natural image distribution에 대해 ImageNet에서 학습한 사전 지식을 활용해 T2I Transformer의 initialization을 제공하고 훈련을 가속화할 수 있다.
3. High-informative data
기존 text-image pair 데이터셋의 단점이 2가지가 있다.
1) 텍스트 캡션은 종종 정보가 부족(일반적으로 이미지의 일부만을 설명)
2) 심각한 롱테일 효과가 나타나는 경우(명사가 많지만 극히 낮은 빈도로 나타남)이 단점은 훈련 효율을 저해하고 안정적으로 text-image alignment을 학습하기 위해 수백만 번의 반복이 필요하다.
이를 해결하기 위해서 SOTA vision-lauguage model인 LLaVA에서 자동 레이블 생성 파이프라인을 제안하며 밀집한 fake caption을 자동으로 레이블링하여 text-image alignment learning이 가능하게 했다.
✨text-image alignment
일반적으로 이미지와 텍스트 사이의 관련성 또는 연관성을 찾아내는 일반적으로 CNN 같은 비전 모델로부터 얻은 이미지 특징과, transformer 등의 자연어 처리 모델로부터 얻은 text embedding을 결합하여 이런 alignment를 학습하게 된다.
text-image alignment 값이 커질수록 일반적으로 이미지와 텍스트 사이의 연관성이 더 잘 파악되었다는 것을 의미한다.
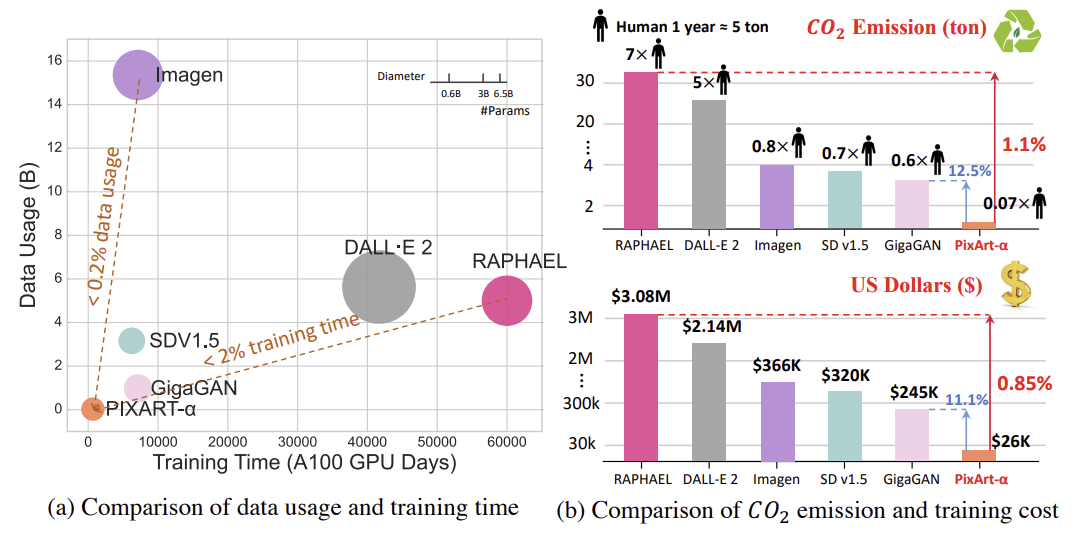
해당 논문의 모델은 모델의 훈련 효율을 현저하게 향상시켰다.
- RAPHAEL에 비해 훈련 시간이 2% 미만으로 소요
- 생성 품질은 user study에서 PIXART-α가 기존 SOTA T2I 모델 (DALL·E 2 Stable Diffusion 등)에 비해 우수한 이미지 품질과 semantic alignment을 제공한다
- T2I-CompBench에서의 성능은 의미적 제어에서 우리의 우위를 입증
T2I 모델을 효율적으로 훈련시키는 시도가 AIGC 커뮤니티에 가치 있는 통찰력을 제공하고, 더 많은 개별 연구자, 스타트업이 더 낮은 비용으로 고품질 T2I 모델을 생성하는 데 도움이 되기를 기대한다.
2. METHOD
2.1. MOTIVATION
훈련이 느린 이유는 train pipeline, 데이터 2가지이다.
T2I 생성은 세 가지 측면으로 나눌 수 있다.
1. Capturing Pixel Dependency
현실적인 이미지를 생성하려면 이미지 내의 복잡한 pixel dependency을 이해하고 그 분포를 포착해야한다.
2. Alignment between Text and Image
정확한 alignment 학습이 필요하기 때문에 text 설명과 정확히 일치하는 이미지를 생성하는 방법을 이해해야 한다.
3. High Aesthetic Quality
정확한 텍스트 설명 외에도, 미학적으로 매력적인 것은 생성된 이미지의 또 다른 중요한 특성이다.
현재의 T2I는 위의 세 가지를 한 번에 처리하기 때문에 얽혀있게 만들고 방대한 양의 데이터를 사용하여 직접 처음부터 훈련하므로, 비효율적인 훈련이 발생한다.
해당 논문에서는 이 문제를 해결하기 위해 3가지 측면으로 나눠서 훈련시킨다.

또 다른 문제는 위의 그림처럼 데이터의 캡션 품질이다.
현재의 text-image pair는 주로 text-image 불일치, 설명 부족, 드문드문하거나 다양한 어휘 사용, 저품질 데이터 포함되어 있다.
➡️ 훈련을 어렵게 만들어서 text와 image 간 안정적인 alignment를 위해 불필요한 수 백만 번의 반복이 필요
2.2. TRAINING STRATEGY DECOMPOSITION
모델이 생성 능력은 훈련을 세 가지 다른 데이터 유형으로 나눠서 최적화시킨다.
Stage 1: Pixel dependency learning
현재 class-guided 방식 : 개별 이미지에서 의미론적으로 일관되는 픽셀을 생성하는데 좋은 성능을 보였다.
ex) text가 “고양이”인 경우 모델은 고양이처럼 보이는 픽셀을 생성하는 방법을 학습

nature image을 위한 class conditional 이미지 생성 모델을 훈련하는건 쉽고 훈련 비용도 적다.
또한 적절한 initialization이 훈련 효율을 크게 향상시킬 수 있다.
➡️ ImageNet으로 사전훈련 시킨 모델을 사용, 모델구조는 사전 훈련된 가중치와 호환되도록 설계
Stage 2: Text-image alignment learning
trained class guided 이미지 생성에서 text-image 생성으로의 주요 task는 이미지와 텍스트 개념 간 정확한 alignment을 어떻게 달성할 것인가에 있다.
해당 논문에서는 효율적으로 처리하기 위해 높은 concept density를 가진 정확한 text-image pair로 구성된 데이터셋을 구축했다. 훈련 과정은 이전 데이터셋에 비해 상당히 더 많은 명사를 각 iteration에서 효과적으로 처리하면서 모호성이 적어졌다.
이러한 접근은 네트워크가 텍스트 설명을 이미지와 효과적으로 align되도록 강화된다.
✨ concept density
concept density란 한 이미지에 대한 텍스트 설명이 다양하고 풍부한 내용을 포함하고 있는 정도를 나타내는 것이다. high concept density이면 문장이나 텍스트가 특정한 의미나 개념에 대해 풍부하게 다루고 있고, 다양한 정보를 담고 있다는 의미이다.
Stage 3: High-resolution and aesthetic image generation
고해상도 이미지 생성을 위해 고품질 미학적인 데이터를 사용해 모델을 fine-tuning한다.
이 단계에서의 adaptation process는 이전 단계에서 확립된 사전 지식 때문에 빠르게 수렴한 것을 알 수 있었다.
훈련 프로세스를 여러 단계로 분리함으로써 훈련 어려움을 크게 완화하고 매우 효율적이다.
해당 훈련 프로세스를 예시로 들어보면,
EX) Generating an image of “A dog playing Frisbee in the park”
1. Pixel dependency learning
”dog”, “park”, “Frisbee”라는 요소들이 이미지에서 어떻게 구성되어야 하는지 이해한다.
2. Text-image alignment learning
기본 이미지를 좀 더 세밀하게 조정하여 “A dog plays Frisbee in the park.”와 밀접하게 align되도록 한다. 예를 들어, 강아지의 위치를 조정해 실제로 “in the park”, “playing Frisbee.” 처럼 보이도록 조절한다.
3. High-resolution and aesthetic image generation
전반적인 심미성을 향상시키기 위해 색상, 질감 및 기타 시각적 요소를 최적화한다.
2.3. EFFICIENT T2I TRANSFORMER
PIXART-α는 기본 아키텍처로 Diffusion Transformer (DiT)를 채택하고 Transformer block을 T2I task를 처리할 수 있도록 조정했다.
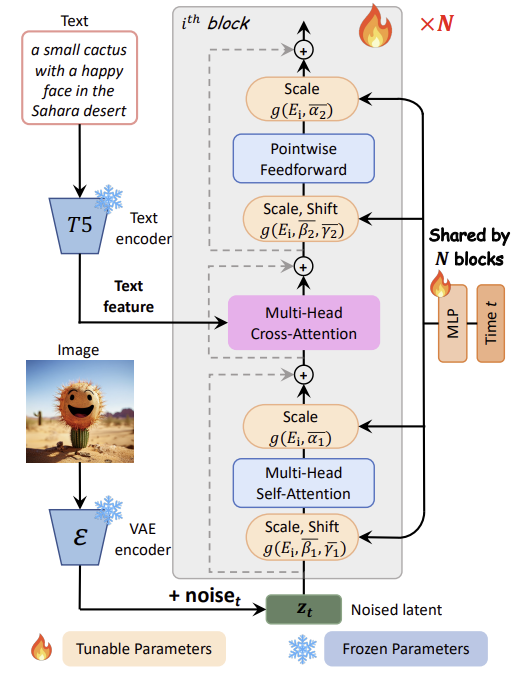
Cross-Attention Layer
DiT block에 multi-head cross-attention layer를 통합했다. self-attention layer와 feed-forward layer사이에 위치해서 언어 모델에서 추출한 text embedding과 유연하게 상호 작용하는 역할을 한다.
이 때, cross-attention layer의 output projection layer를 0으로 초기화시켜 identity mapping 역할을 하고 입력을 subsequent layers에 보존한다. 즉, 사전 훈련된 가중치를 쉽게 적용하기 위해 cross-attention layer에서의 변환을 없애고 입력을 그대로 subsequent layer에 보존한다는 의미이다.
✨ Cross-Attention Layer
self attention은 같은 문장 내에서 연관성을 고려하여 단어들관긔 관계를 계산하는 방법으로 입력 시퀀스의 각 위치에서 다른 위치들의 정보와의 관계를 참조한다.
하지만 cross attention은 오른쪽과 같이 두 개의 서로 다른 시퀀스 간에 정보를 교환한다. 즉, key, value로 같은 값을 사용하지만 query로 다른 값을 사용하게 된다.

AdaLN-single
AdaLN 모듈의 linear projection은 DiT의 매우 큰 부분을 차지한다.
그러나 많은 수의 매개변수는 PIXART-α에서 class condition이 사용되지 않기 때문에 필요가 없다.
➡️ 따라서 첫 번째 블록에서만 time embedding을 입력으로 사용하는 adaLN-single을 제안한다.
AdaLN은 블록에서 는 모든 scale 및 shfit parameter의 튜플이며 DiT에서 는 블록 별 MLP 를 통해 얻어진다. 이 때, 는 각각 class condition과 time embedding을 의미한다.
AdaLN-single은 하나의 전역 shift 및 scale 세트인 가 첫 번째 블록에서만 계산되어 모든 블록에서 공유되고 이 때, 는 또는 로 얻어진다. 는 와 동일한 모양을 가진 layer별 학습 가능한 embedding이고 다른 블록에서 scale 및 shift parameters를 적응적으로 조정된다.
✨ time embedding
time embedding이란 모델에 시간 정보를 주입하기 위한 것으로 모델이 데이터의 순서나 시간에 따른 변화를 더 잘 이해하고 학습하게 한다.
Re-parameterization
사전 훈련된 가중치를 활용하기 위해 모든 들은 가 없는 DiT 즉, class condition이 없는 DiT에서 선택된 에 대해 동일한 를 생성하는 값으로 초기화된다.( 사용)
이것은 사전 훈련된 가중치와의 호환성을 유지하면서 layer 별 MLPs를 global MLP와 layer 별 학습 가능한 embedding으로 효과적으로 대체한다.
2.4. DATASET CONSTRUCTION
Image-text pair auto-labeling

- LAION : 쇼핑 웹사이트에서 가져온 제품 사진이 포함되어 있으며, 의류, 신발, 가방과 같은 제품이 포함
- SAM: 차량, 사람, 동물, 건물 등 다양한 물체가 포함된 장면 사진
- Internal : 풍경, 초상화, 예술 작품과 같은 고품질이면서 아름다운 이미지가 포함
해당 논문에서는 High-informative density의 캡션을 생성을 위해 SOTA vision-langauge 모델 LLaVA 활용했다.
LAION 데이터셋은 다양성을 추구하는 text-image 생성하는 task에는 적합하지 않다고 판단해서 해당 논문에서는 원래 segmentation task에 사용되는 SAM 데이터 셋을 활용하기로 했다.
따라서 SOTA vision-langauge 모델 LLaVA를 SAM에 적용하면서 concept density가 높은 고품질의 text-image pair를 얻었다.
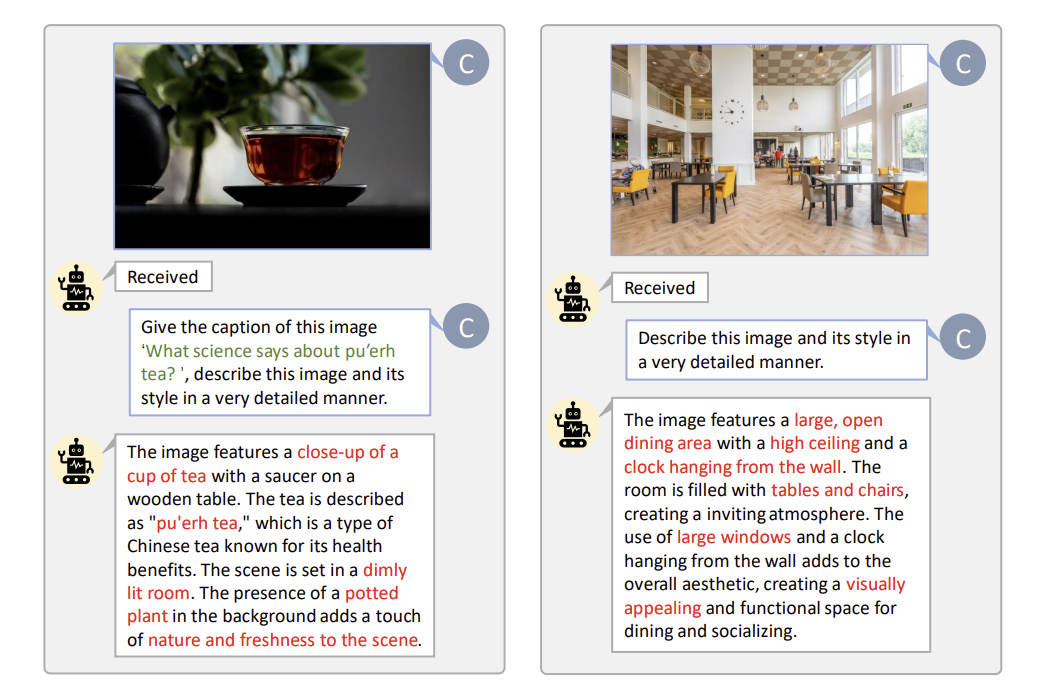
“Describe this image and its style in a very detailed manner”. 라는 프롬프트를 사용해서 캡션의 품질을 크게 향상시켰다.
해당 논문의 세 번째 훈련 단계인 High Aesthetic Quality에서 생성된 이미지의 미학적 품질을 realistic 사진을 넘어서도록 향상시키기 위해 JourneyDB 및 10M 내부 데이터셋을 훈련 데이터셋으로 구성했다.
해당 표는 어휘 분석의 결과이다.
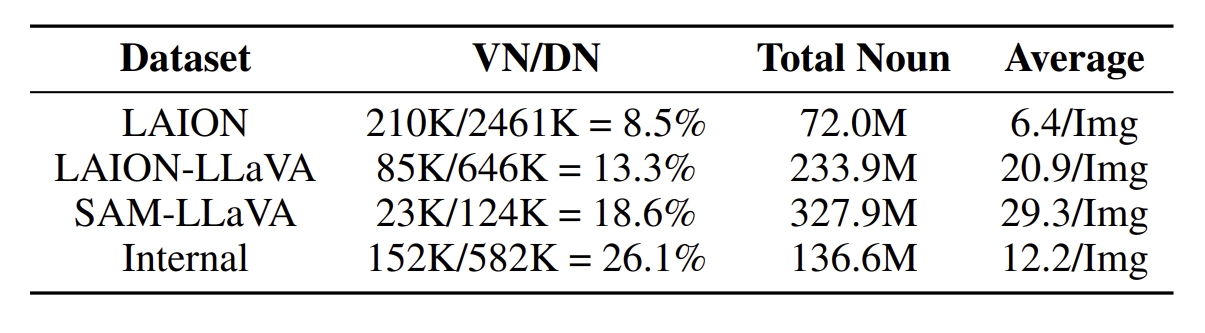
**VN** : 데이터셋에서 **10회 이상 나타난 유효**하게 구별된 명사
**DN** : 데이터셋 전체에서 나타나는 명사 (중복O)
**Total Noun :** DN에서 중복 제외한 명사
**Average** : 이미지 당 평균 명사의 수
해당 논문에서 LAION 데이터셋에 LLAVA 모델을 사용해 captioning한 데이터셋을 LAIONLLaVA라 불렀다.
결과를 보면,
-
LAION : 2.46M개의 명사가 있지만 그 중 8.5%만 유효
-
LAIONLLaVA : 유효한 명사 비율은 8.5%에서 13.3%로 크게 증가
- LAION의 원래 캡션에는 210K 개의 구별되는 명사가 포함 그러나 총 명사수는 겨우 72M이다.
- LAION-LLaVA에는 234M의 명사 수와 85K의 구별되는 명사가 포함되어 있으며, 각 이미지 당 평균 명사 수가 6.4에서 21로 증가
➡️ 원래 LAION caption의 불완전성을 나타낸다.
-
SAM-LLaVA : 총 명사 수가 328M
- 이미지 당 평균 명사 수가 30인 LAION-LLaVA를 능가
- 이미지 당 더 풍부한 객체와 우수한 informative density를 나타냄
- 즉, 다양하고 유용한 정보가 많아 높은 품질의 결과물을 생성 O
-
Internal : fine-tuning에 대한 충분한 유효한 명사와 평균 정보 밀도를 보장
-
LaVA로 레이블링된 캡션: 유효한 비율과 이미지 당 평균 명사 수를
➡️ concept density 향상
-
3. EXPERIMENT
3.1. IMPLEMENTATION DETAILS
Training Details
base arichtecture로는 DiT-XL/2를 사용했다.
text encoder로는 conditional feature extraction에 적용하기 위해 T5-large 모델을 사용했다. 이전 연구들에서는 고정된 77개 텍스트 토큰들을 추출했지만 해당 논문에서는 detail을 더 많이 제공하기 위해 추출된 텍스트 토큰의 길이를 120으로 조절하여 추출했다고 한다.
반면 Image encoder로는 입력 이미지의 latent feature을 캡쳐하기 위해 LDM에서 사전 훈련되어 고정된 VAE를 사용했다고 한다. 이 때, VAE에 입력하기 전에 동일한 크기를 가지도록 resize 후 중앙으로 crop하는 과정을 거쳤고 multi-aspect augmentation을 사용해 임의의 측면 이미지 생성을 가능하게 했다.
✨ multi-aspect augmentation
multi-aspect augmentation란 data augmentation의 한 형태로 여러 가지 측면에서 데이터를 다양하게 변형시켜 모델의 성능을 향상시키기 위한 기술이다.
다양한 측면에서의 변형은 모델이 더 강건하게 학습되고 다양한 상황에서 더 좋은 성능을 보이도록 돕는 효과가 있다.
Evaluation Metrics
FID, compositionality, human-preference rate 3가지 metric을 사용했다.
- FID : 생성된 이미지의 품질을 평가한다.
- compositionality란 이미지의 생성된 부분이 텍스트에 얼마나 잘 부합하고 텍스트의 각 부분이 이미지에서 어떻게 표현되는지를 확인한다. 모델이 텍스트에 대한 이해와 이미지 생성 간의 일관성을 평가하는 데 도움이 된다.
3.2. PERFORMANCE COMPARISONS AND ANALYSIS
Fidelity Assessment
아래의 표는 COCO데이터셋에서 zero-shot 성능을 비교한 결과이다.
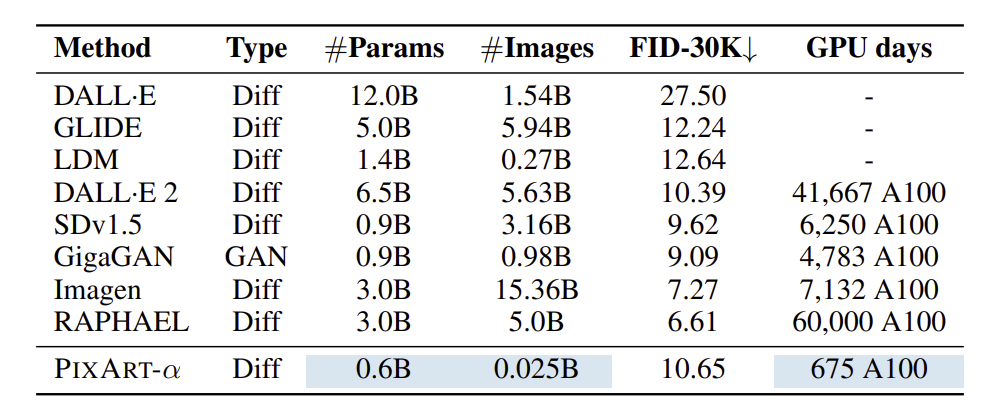
- PIXART-α : FID 10.65
- 상당한 리소스를 사용하는 SOTA와 비교할 때 FID는 비슷하나 훈련 리소스의 약 2%만 소모
- RAPHEAL : 더 낮은 FID(성능 좋음), 그러나 훈련 샘플 200배, 훈련 시간 88배, 매개변수 5배 → 훨씬 높은 리소스 필요
그러나 ImageNet 데이터셋에서 사전 훈련되었기에 text에서 image 생성 데이터와 제한적인 overlap 있으므로 FID는 생성 능력을 평가하는데 적절한 메트릭이 아닐 수 있다.
따라서 더 적절한 평가를 위해 human evaluator를 도입해 user study를 수행했다.
Alignment Assessment
생성된 이미지와 텍스트 조건 간의 alignment를 T2I-Compbench를 사용해 평가한다.
T2I-Compbench는 합성적인 텍스트에서 이미지를 생성하는 능력을 평가하기 위한 포괄적인 벤치마크이다.
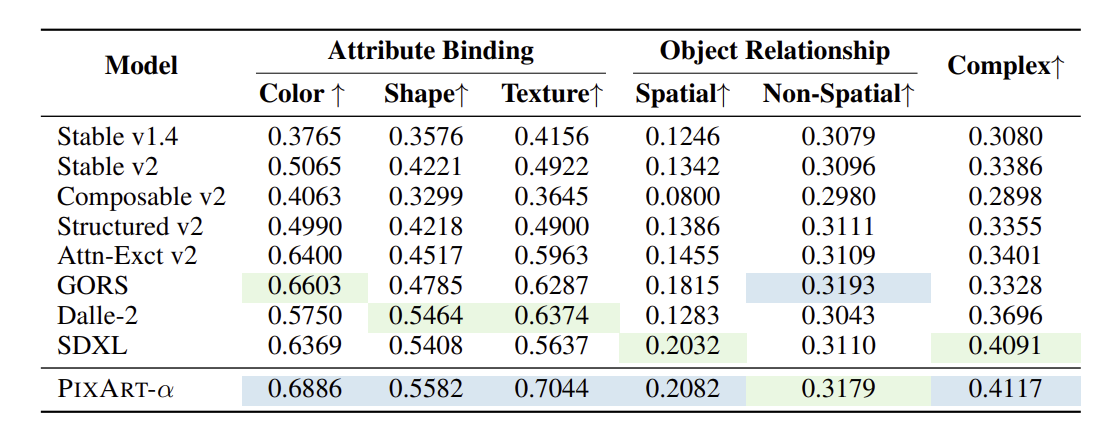
attribute binding, object relationships, and complex composition를 측정했다.
PIXART-α는 6개 중 5개 항목에서 뛰어난 성능을 보여줬다.
➡️ stage2에서 text-image alignment 학습에 기인하며 여기서 고품질 text-image pair가 우수한 alignment 능력을 달성하는데 활용했다.
User study
quantitative 평가 메트릭은 두 이미지 셋의 전반적인 분포는 측정하지만 품질은 체계적으로 평가하지 못할 수 있다. 따라서 PIXART-α의 성능을 더 직관적으로 평가하기 위해 user study를 수행했다.
User study는 DALLE-2, SDv2, SDXL, DeepFloyd 등과 같이 API를 통해 접근 가능하고 이미지를 생성가능한 모델을 선택하여 human evaluator들이 수행했다.
각 모델에 대해 300개의 prompt로 일관된 데이터셋을 사용해 이미지를 생성했고 각각 50명의 evaluator들이 평가했다. 평가할 때, 생성된 이미지의 지각적 품질과 text prompt와 해당 이미지 간의 alignment 정확도를 기반으로 각 모델을 순위 매기도록 요청되었다고 한다.
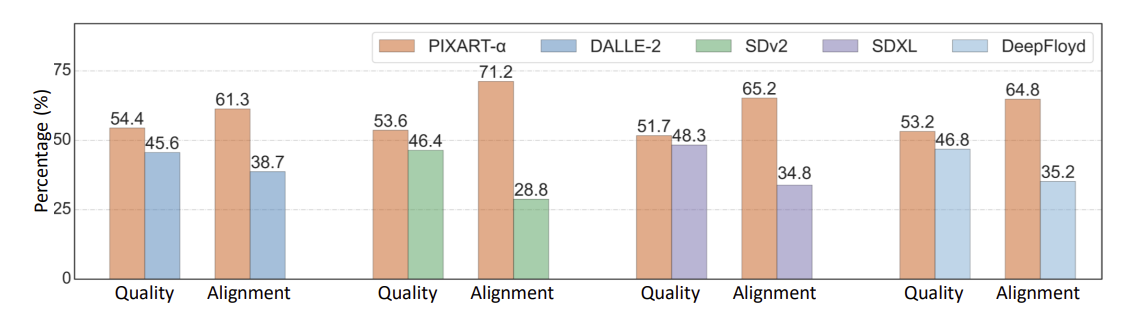
실험 결과
- PIXART-α가 높은 fidelity와 alignment에서 뛰어났다.
- SDv2와 비교할 때 이미지 품질에서 7.2% 향상 되었고 alignment에서는 42.4% 향상되었다.
3.3. ABLATION STUDY
구조 수정 및 re-parameterization에 대한 ablation study를 진행했다.
아래는 SAM 테스트 세트에서 무작위로 8개의 prompt를 선택하고 SAM 데이터셋에서 zero-shot FID-5K 점수를 계산한 결과이다.

실험 결과, adaLN은 FID 낮지만 visual result는 adaLN-single와 비슷했다.
adaLN은 GPU 메모리가 29GB 소비되었고 매개변수가 833M개인 반면, 해당 논문 방법론인 adaLN-single은 GPU 메모리가 23GB 소비하여 약 21% 절약했고 매겨변수도 611M개를 사용해 26% 감소했다.
결과적으로 visual result는 비슷하나 해당 논문의 방법론이 연산량을 훨씬 많이 절약했다.
5. CONCLUSION
PIXART-α라는 Transformer 기반 T2I diffusion model을 소개했다.
- 우수한 이미지 생성 품질 달성하면서 훈련 비용과 배출량 크게 줄였다
- 훈련 방법을 나누고 효율적인 T2I Transformer, high-informative data와 같은 세 가지 핵심 디자인은 성공에 기여했다.
- 실험을 통해 이미지 생성 품질에서 상업 응용 프로그램 표준에 근접한다는 것을 입증했다
결론적으로, 고품질이면서도 훈련 비용이 적은 T2I 모델을 구축했다.
