
1. Introduction
기존의 parametric segmentation (softmax, query) 는 한계가 있어
non-parametric segmentation을 제안할게!
현재 semantic segmentation에 널리 쓰이는 모델 design의 parametric segmentation에 대해서 새로 생각해보는 기회가 되었으면 좋겠다!
keywords: parametric/non-parametric, prototype learning, intra-class variance
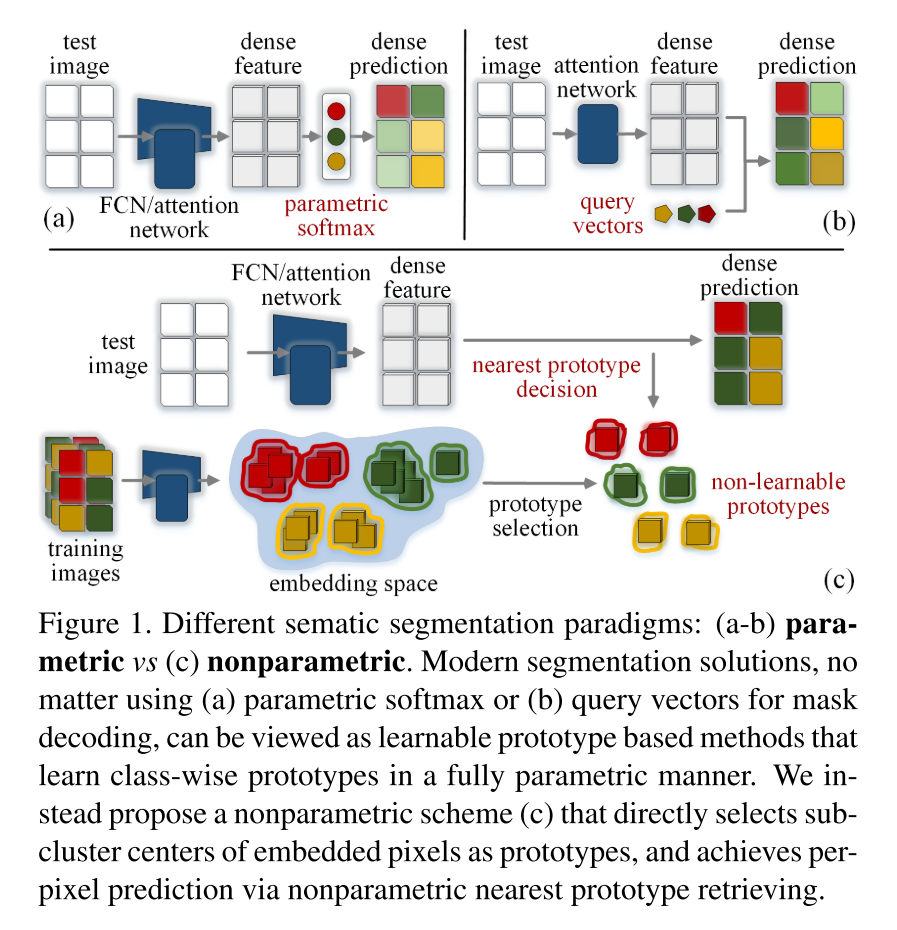
기존의 parametric segmentation (FCN-based/attention-based)은 class-wise prototype들을 학습하는 learnable prototype (softmax weights/query vectors) 기반 방법으로 볼 수 있다
parametric paradigm의 한계
1) class 당 one single prototype을 학습하는 걸로는 intra-class variance를 묘사하기에 불충분하다
2) image feature vector HxWxD에서 semanctic mask HxWxC로 mapping할 때 적어도 DxC 크기의 parameter들이 prototype learning에 필요한데, 이는 large-vocab. case의 경우 generalizability를 해친다. (예를 들어, 800개의 클래스에 D가 512면 0.4M 크기의 learnable prototype parameter가 필요..)
3) cross-entropy loss는 intra-class and inter-class distance간의 관계만 따지는데, pixel과 prototype간의 실제 거리인 intra-class compactness를 ignore..
2. Existing Semantic Segmentation Models as Parametric Prototype Learning
parametric softmax projection
Almost all FCN-like and many attention-based segmentation models adopt this strategy
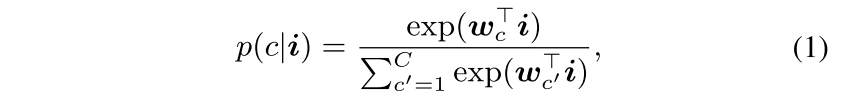
parametric pixel-query
A few attention-based segmentation networks work in a more 'Transformer-like' manner
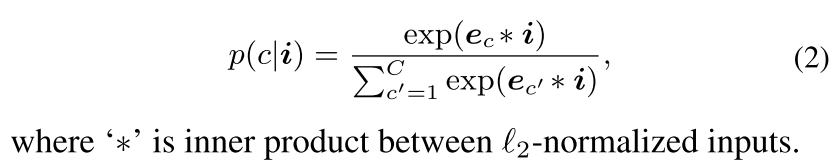
prototype-based classification
prototype-based classification은 기계학습에서의 최근접 이웃 알고리즘과 인지과학의 prototype 이론으로 거슬러 올라가 오랫동안 연구되어 온 분야,, class를 대표하는 prototype을 찾아 classification에 사용하는 게 아이디어
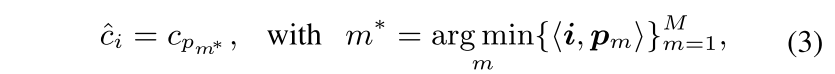
각 class를 대표하는 p1...pm..pM M개의 prototype set이 있을때, data sample i와 가장 거리가 적은 prototype을 통해 class를 추정하게 됨
위의 parametric softmax projection & pixel-query를 prototype-based classification의 formula로 변형하면 다음과 같음
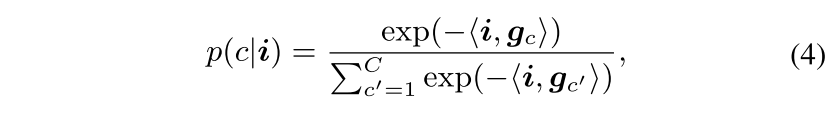
하지만, 그 방법들은 클래스당 하나의 prototype인 gc를 학습하게 됨 (gc는 wc, ec로 표현될 수 있는 parametric prototype이고, <,> 연산은 inner product vs cosine similarity를 표현)
softmax layer에서 학습된 class weight만을 leveraging하는 softmax projection에 비해 pixel-query based 방법은 query들을 cross-attention decoder layer에 feed해주면서 cross-class context exchanging을 도모할 수 있음
prototype selection의 관점에서 기존 방법들이 간과했던 부분들이 드러남 (앞에서도 한 말)
1) prototype은 해당 클래스에서 typical해야한다. 근데, 기존 방법들은 한 개의 prototype만으로 각 class를 묘사하고 intra-class variation을 무시한다. 게다가 prototype들이 representative ability를 고려하지 않은 채로 fully parametric manner로 바로 학습된다
2) learnable prototype parameter (DxC)의 양이 클래스의 수에 따라 증가하는데, 한 개의 클래스당 10개의 프로토타입을 고려한다면 훨씬 많은 파라미터를 학습해야한다.
3) cross entropy loss와 같이 pixel-wise prediction의 정확도를 바로 최적화함으로써 dense segmentation representation을 supervise하는데, 이는 feature 분포에 관한 intra-class compactness와 같은 inductive bias들을 무시한다.
3. Non-Learnable Prototype based Nonparametric Semantic Segmentation
Non-Learnable Prototype based Pixel Classification
각 class는 총 K 개의 prototype으로 표현된다 (represented)
prototype p_c,k 는 class c에 속하는 훈련 pixel sample들의 k번째 sub-cluster의 center
winner-take-all classification으로써 각 픽셀 i의 category prediction이 다음과 같이 쓸 수 있고
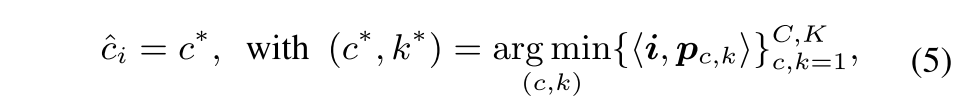
negative cosine similarity <i, p> = -i^T*p
pixel i가 C 클래스들에 대한 확률분포를 정의하면 다음과 같고
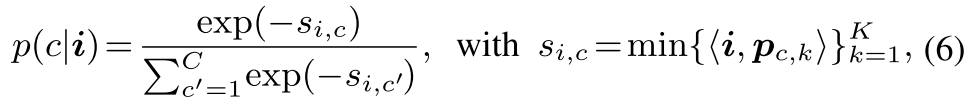
s_i,c 는 클래스 c의 가장 가까운 prototype로의 거리를 나타내는 pixel-class distance
주어진 i의 ground truth인 ci를 가지고 CE loss는 훈련에 다음과 같이 사용될 수 있음
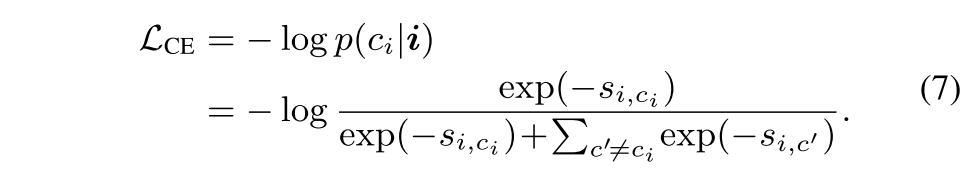
이는 pixel i를 ci에 가장 가가운 prototype으로 밀면서 관련없는 클래스들에 가까운 prototype에서 멀리 떨어뜨리는 것으로 볼 수 있음
하지만 이것으론 부족하다.
1) 이는 class pixel-prototype relation을 고려하지 않은 채 pixel-class distance만 고려한 것으로 pixel은 해당 클래스 ci에서 좀 더 특별히 적합한 pattern을 가진 prototype과 가까워야하고 클래스 ci에서 within-class pattern을 가지면서 관련없는 prototype들과 멀어져야하는 데, 그런 특성은 담고 있지 못하다.
2) pixel-class distance들이 모든 class에 걸쳐 normalized되기 때문에, Eq. 7은 pixel들과 class간의 cosine distance를 직접 regularizing하는 대신에 intra-class distance (s_i,ci)와 inter-class distance ({s_i, c'}c'=/= ci)간의 relative relation만을 최적화하게 됨
Within-Class Online Clustering
주어진 훈련배치에서 pixel embedding간의 similarity를 극대화함으로써 pixel-to-prototype mapping L^c = 을 구할 수 있음
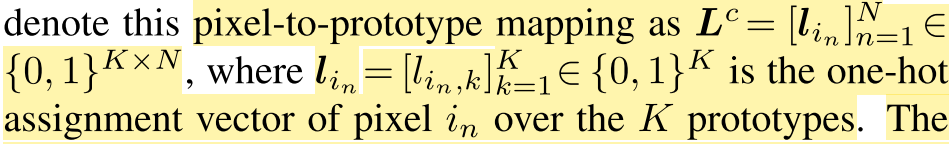
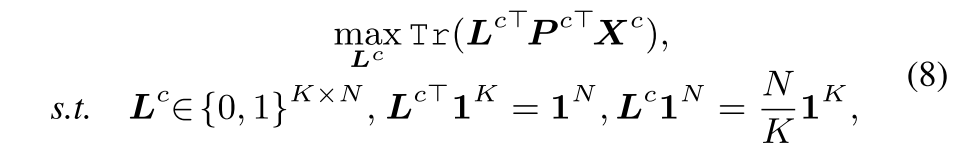
L^cT 1^K는 각 pixel당 하나의 prototype에만 할당되도록 하는 unique assignment constraint고 L^c 1^N은 배치에서 평균적으로 각 prototype이 적어도 N/K배 선택되도록 하는 equipartition constraint
L^c를 transportation polytope의 한 element가 되도록 relax하기 위해 entropy를 regularization term으로 두면 다음과 같음. k (>0) 로 분포의 smoothness를 control
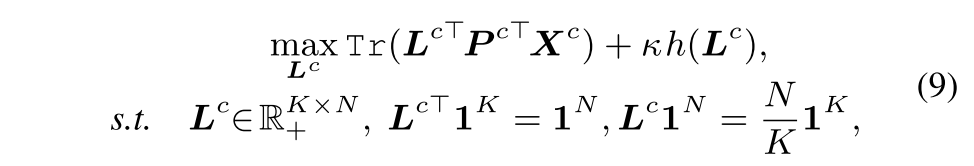
이를 solver (Sinkhorn-Knopp iteration)로 풀면 다음과 같이 L^c가 구해짐.
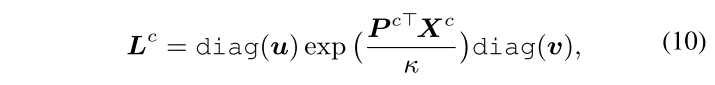
여기서 제안하는 batch별 online clustering은 GPU에서 굉장히 효율적인데, 두 개의 matrix 곱만 해주면 되고 실제로 10k pixel을 10개의 prototype에 clustering하는데 2.5 ms가 걸림
Pixel-Prototype Contrastive Learning
assignment probability matrix L^c를 가지고 training pixel들을 K개의 prototype으로 온라인 그룹화시킨다.
pixel prototype posterior probability를 최대화시키는 prototype assignment prediction에 대한 objective도 유도해야지. 이건 pixel-prototype contrastive learning 전략으로 볼 수 있고, Eq 7의 첫번째 한계를 해결할 수 있음
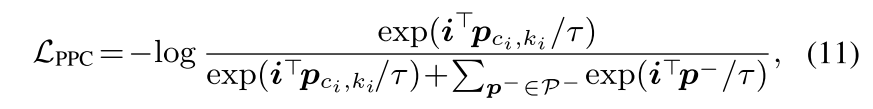
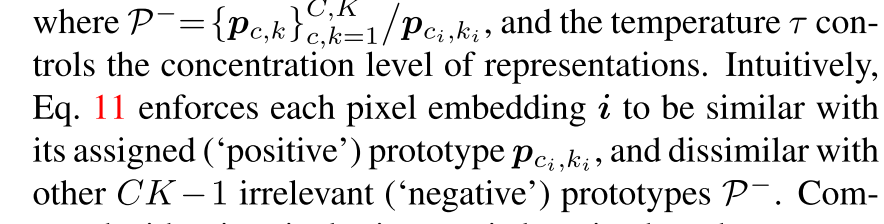
이는 굉장히 많은 수의 negative pixel sample이 소요되는 prior pixel-wise metric learning-based segmentation과 비교하여 pixel-prototype contrast 계산을 위한 CK prototype만 있으면 되므로 large memory cost나 heavy pixel pair-wise comparison을 요구하지 않음
Pixel-Prototype Distance Optimization
위의 것으로 inter-class/-cluster discriminativeness를 고취시켰지만 intra-cluster variation을 줄이는 건 덜 고려함.
compactness-aware loss는 좀 더 representation을 regularizing하려고 사용되는데, 각 embedded pixel과 그 pixel이 할당된 prototype간의 거리를 최소화함으로써 달성할 수 있음
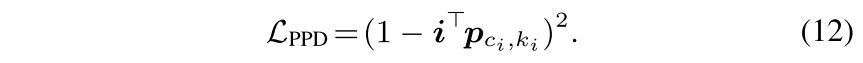
이걸로 pixel-prototype distance를 최적화함
Network Learning and Prototype Update
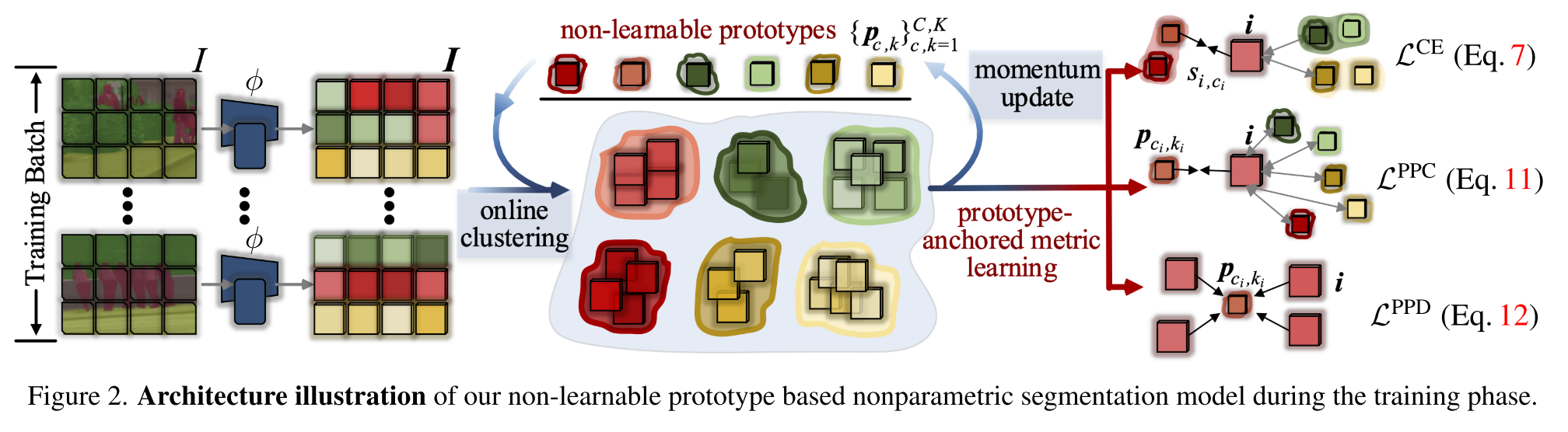
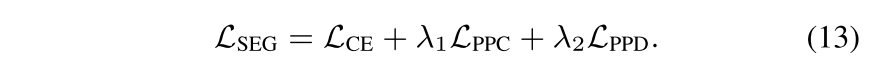
prototype은 non-learnable하기 때문에 다음과 같이 따로 업데이트 해줬음
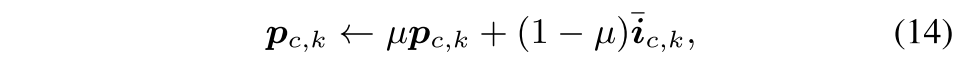

이건 person과 car에 대해서 K=3 prototype으로 retrieval result임. 각 pixel이 더 가까운 prototype에 해당 prototype color로 시각화한 것으로 보시다시피 각 prototype이 클래스에 따라 meaningful pattern을 잘 대표함 (top/middle/bottom?)

4. Experiments & Results
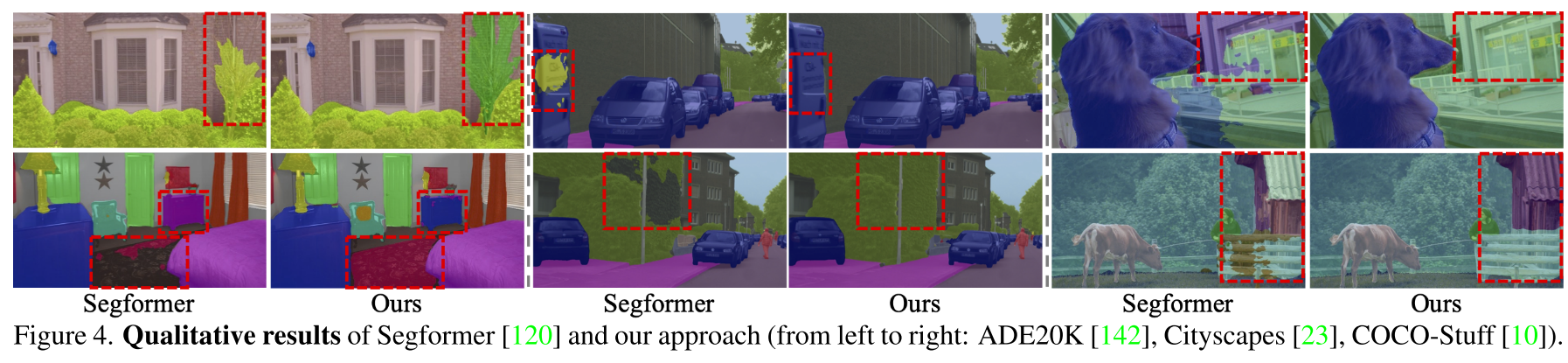
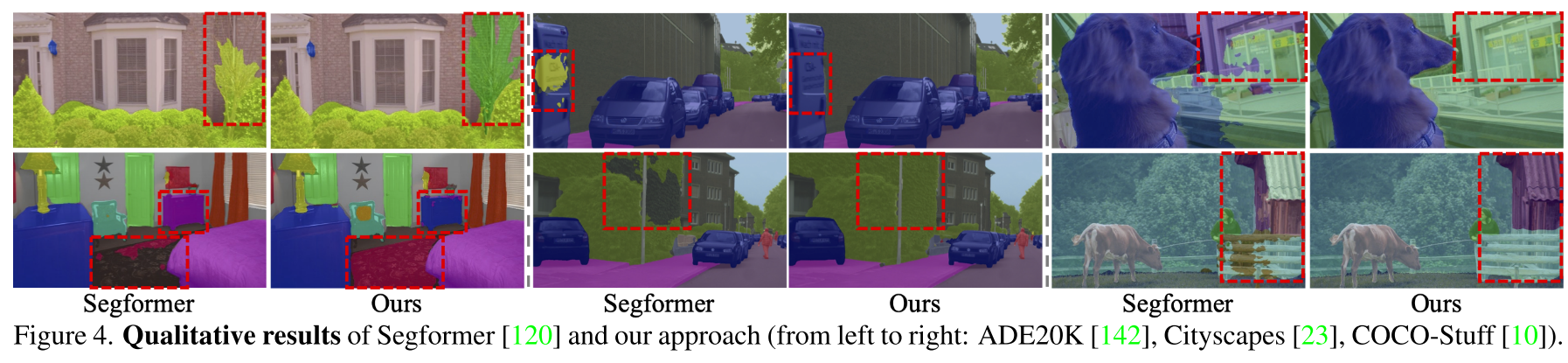
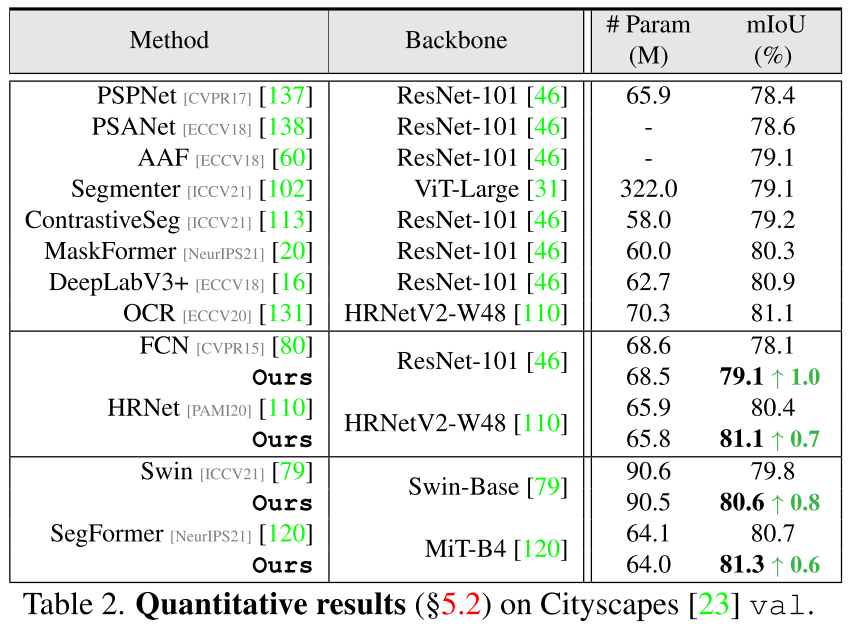
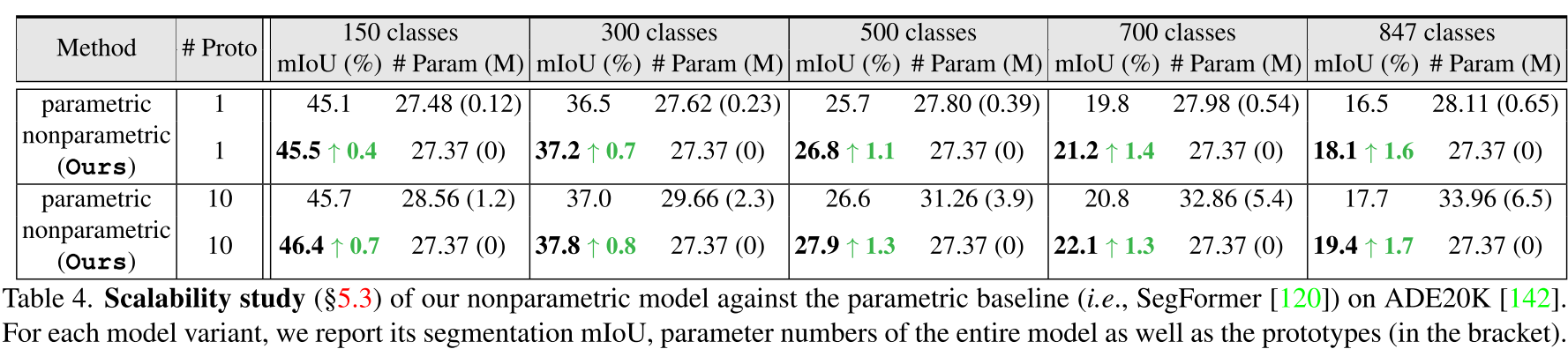





5. Conclusion
prototype 기반으로 class를 표현할 수 있는 prototype을 여러 개 만들어내면서 각 pixel이 좀 더 적합한 pattern을 지닌 prototype에 가까워지게 하고 within-class pattern은 지녔지만 관계없는 prototype과는 멀어지는 inter-cluster discriminativeness를 contrastive learning 전략을 통해 만들어내고 intra-cluster variation을 줄이기 위해 compactness aware loss를 sub-cluster (prototype)의 pattern을 좀 더 compact하게 배우도록 했음
기존 fully parametric manner의 segmentation 방법들이 간과한 부분 (intra-class variance 등)을 꼬집으면서 non-parametric manner로 각 pixel과 class간의 representation은 좀 더 설명력있게 배우면서 연산에서도 효율적인 prototype 기반 방법으로 제안한 논문!
