[2022 CVPR] Towards Fewer Annotations : Active Learning via Region Impurity and Prediction Uncertainty for Domain Adaptive Semantic Segmentation
Paper Review
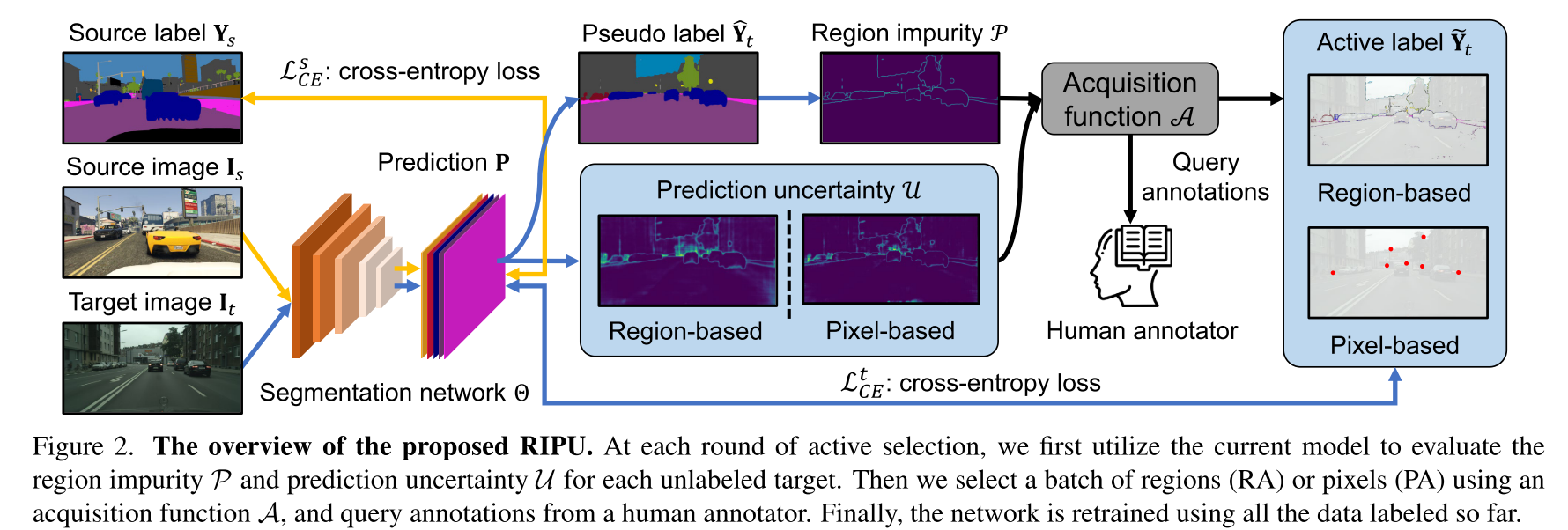
1. Introduction
Background
- Semantic segmentation, pixel-level annotation -> prohibitively expensive
- 최근 self-training이 target domain에 대한 confident prediction으로부터 생성된 pseudo label을 가지고 network를 재훈련하는 방식으로 domain adaptation을 boost해옴
- 여전히 Inherent Challenge를 남기고 있는데, Class unbalance로 self-training에서도 major class를 강조하고 rare class or small object에 대한 성능을 희생시키는 undesired bias를 초래함
Proposal
- Active Learning for domain adaptive semantic segmentation
- Region Impurity and Prediction Uncertainty (RIPU)
1) model prediction으로부터 target pseudo label을 생성하고, k-square-neighbors algorithm으로 모든 가능한 영역을 excavate함
2) 각 영역 (region)의 region impurity에 따라 각 class에 속하는 internal pixel의 percentage로 계산한 entropy을 취함
3) prediction uncertainty의 평균값과 region impurity를 결합하여 pixel prediction의 entropy를 구하고, 이를 통해 diversity와 uncertainty를 jointly하게 포착하는 novel label을 acquisition
2. Related Work
Domain Adaptation (DA)
- well-labeled source domain의 knowledge를 unlabeled target domain에서 prediction이 가능하도록 함
- 처음에는 domain gap을 mitigate하는 방식으로 source domain과 target domain사이의 discrepancy를 최소화하는 관점으로 연구가 진행되었음
- Semantic Segmentation에서는 대부분이 3가지 방식에서의 adversarial learning을 employ했었음
- appearance transfer
- feature matching
- output space alignment
- Self-training은 target domain에 대한 pseudo label로 모델을 훈련시키는 방식으로 competitive alternative로써 발전해왔음
- pseudo label이 noisy하고 good initialization에 크게 영향을 받는데, 이를 해결하기 위해
- weak label을 사용하거나 dense depth information을 이용해 domain adaptation을 수행함
- 또한, annotation을 최소화하여 noise를 방지하는 strategy인 Active Learning 방식
Active Learning (AL)
- 모델 성능을 최대화하면서 labeling effort를 최소화하려고 함
- 보통 uncertainty sampling과 representative sampling을 포함함
- Segmentation과 같은 dense prediction task에서의 AL 연구가 별로 없고, 더욱이 실제로는 많이 발생하는 domain adaptation에서 annotation transfer를 고려한 논문은 더 없다.
Active Domain Adaptation (ADA)
- 지금까지는 image classification에 주로 집중적으로 연구가 수행되어왔고, 최근들어 Ning et al.과 Shin et al.이 처음으로 semantic segmentation에 적용했음
- Ning et al.은 image의 subset을 고르지만 entire image를 annotation해야하고 Shin et al.은 adaptive pixel selector로 point-based annotation을 제시하지만, 이는 이미지의 contextual structure와 영역 내에 pixel spatial contiguity를 무시하게 됨
- 이 연구에서는 spatial adjacency 특성을 무시하면 안되고 region-based selection strategy이 essential하다고 주장하고 있으며
- 이미지의 공간적 일관성 (spatial coherency)을 탐구하고 diverse하면서도 uncertain한 image region의 선별하여 높은 정보 content와 낮은 labeling cost를 약속함
3. Approach
3.1. Preliminaries and Motivation
- 더 적은 annotation으로 target domain에서 좋은 성능을 낼 수 있도록 function h: I -> Y (Segmentation Network parameterized by )를 학습하는 게 목표
- pseudo label로 knowledge를 transfer하는 self-training을 할건데, pseudo label이 noisy하다고 보고 theshold 이상을 넘긴 high confident pixel만 retraining에 사용함
- 이 방법은 target domain에 훈련되는 모델이 스스로 확신하는 pixel들에 boostrap되는 꼴
- 이를 address하기 위해 image에서 informative한 적은 영역을 골라 domain adaptation을 assist하는 RIPU의 active learning approach를 제안함
3.2. Region Generation
- (2k+1, 2k+1) 크기의 정사각형 region에 대한 center로 한 pixel의 k-square-neighbors를 수행함
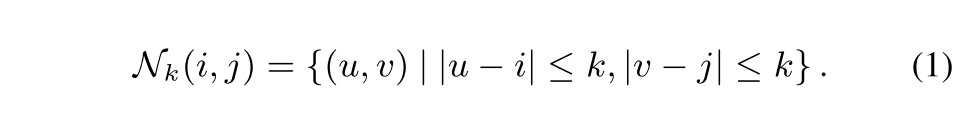
3.3. Region Impurity and Prediction Uncertainty
- Region-based Annotating (RA)와 Pixel-based Annotating (PA)의 두 가지 labeling 메카니즘을 사용함
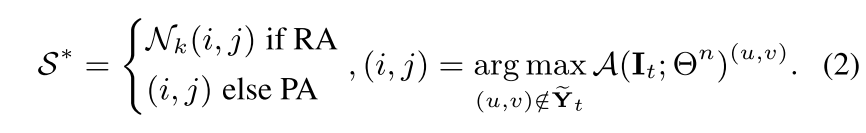
- RA면 k-sqaure-neighbors해서 중심 point (u, v)를 받고, PA면 (i, j)를 그대로 받고
- target active label 에 없는 (u, v) 중에서 A(를 최대화하는 (u, v)를 얻는다.
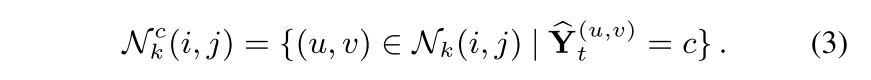
- 는 각 pixel에 대해서 최대확률값을 가지는 class로 argmax한 Target pseudo label임
- target domain image 에서 인 (u, v)를 추출해 각 class에 해당하는 region을 나눔
Region Impurity
- 각 pixel (i, j)에 대한 Region Impurity는 (i, j)를 center로 하는 (2k+1, 2k+1) 크기의 square region N_k 중에 특정 class c에 속하는 region의 비율을 P로 뒀을 때, 모든 class C에 대한 -PlogP의 SUM인 entropy의 형태로 구함
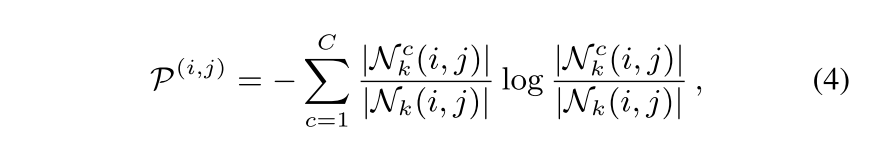
Prediction Uncertainty
- 각 pixel (i, j)에 대한 uncertainty는 (i, j)가 center인 (2k+1, 2k+1) 크기의 square region N_k 모든 pixel (u, v)에 대하여 predictive entropy의 합으로 계산됨
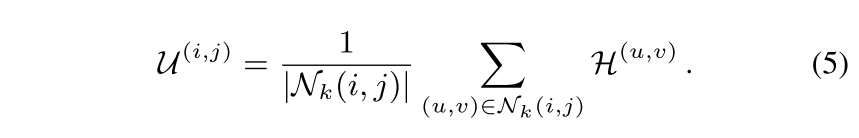
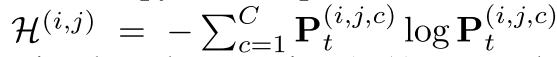
Acquisition Function
- Region Impurity와 Prediction Uncertainty를 element-wise matrix matmul하여 acquisition function을 구함
- N_k를 통해 주변 pixel을 고려하게 되면서 spatial adjacency를 고려하여 diverse하고 uncertain한 영역을 acquisition하는 기능을 하게 됨
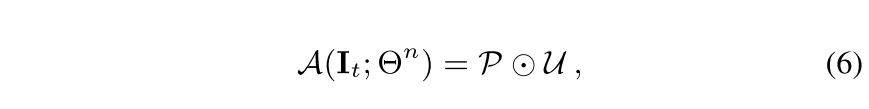
3.4. Training Objectives
Standard Supervised Loss
- : target active label
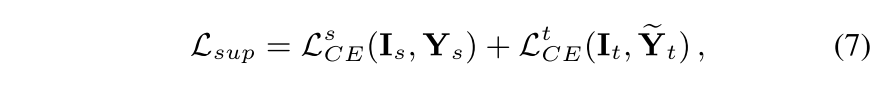
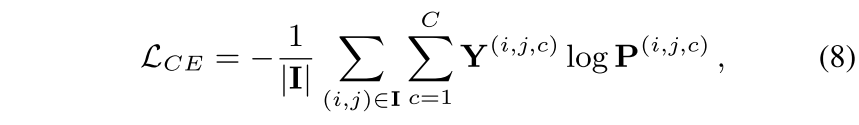
Consistency Regularization Loss
- pixel과 그 주변 pixel간의 prediction의 일관성을 강화시키는 Loss
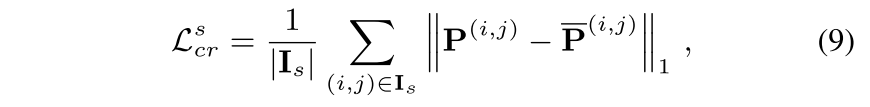

Negative Learning Loss
- noisy한 pseudo label에 negative pseudo label을 적용함, 보다 작으면 1, 크면 0으로 해서 label을 사용해 CE loss에 적용하면 이와 같은 식이 나옴
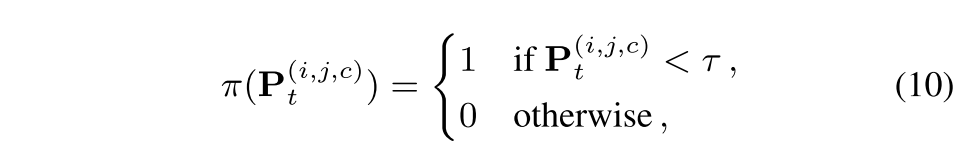
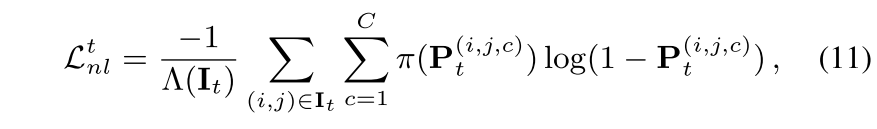
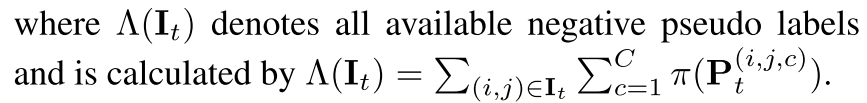
Total Loss
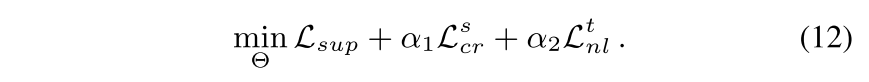
Algorithm
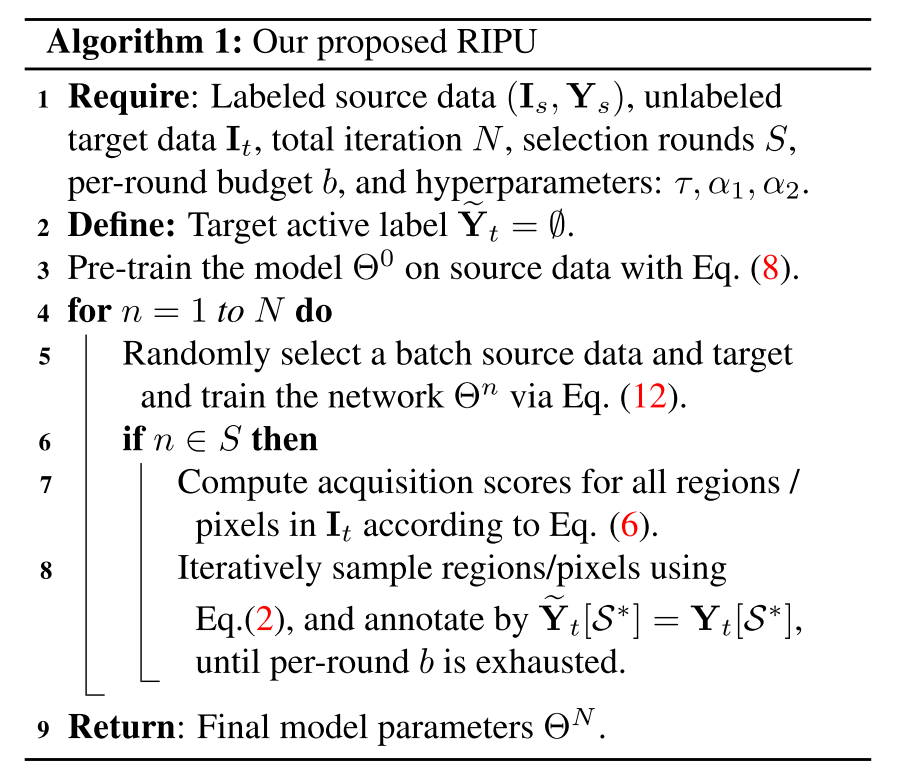
- CE loss, Eq. (8) 로 source data에 사전 훈련된 network 가 있고
- Iteration에 따라 Total Loss Eq. (12)로 network를 훈련하고
- Selection round 주기가 되면 target image 에 대한 acquisition score를 계산하고 Acquisition이 최대화하는 Eq. (2)에 대해서 regions(RA)/pixels(PA)을 sampling해줌
- argmax해서 가장 큰 값의 index를 받아 target active label 를 생성 (RA는 전체 이미지에서 2.2%, 5%를 budget으로 뽑고 PA는 40 pixel 정도 뽑았음)
4. Experiments
Dataset
- Source (GTAV, SYNTHIA) -> Target (Cityscapes)
- GTAV(GTA5), Computer Game, https://paperswithcode.com/dataset/gta5
- SYNTHIA, Synthesized Urban Scenes, https://paperswithcode.com/dataset/synthia
Implementation Details
- backbone: Deeplab-v2 and Deeplab-v3+ with ResNet-101 pre-trained on ImageNet
- training
- SGD optim (momentum = 0.9, weight decay = 5 x 10^-4)
- Poly learning rate scheduler (inital LR = 2.5 x 10^-4)
- batch size = 2, 40K iterations
- source data are resized into (1280, 720) / target data are resized into (1280, 640)
- k = 1 for RA (Region-based Annotating), k = 25 for PA (Pixel-based Annotating)
- = 0.05, = 0.1, = 1.0
4.1. Comparisons with the state-of-the-arts
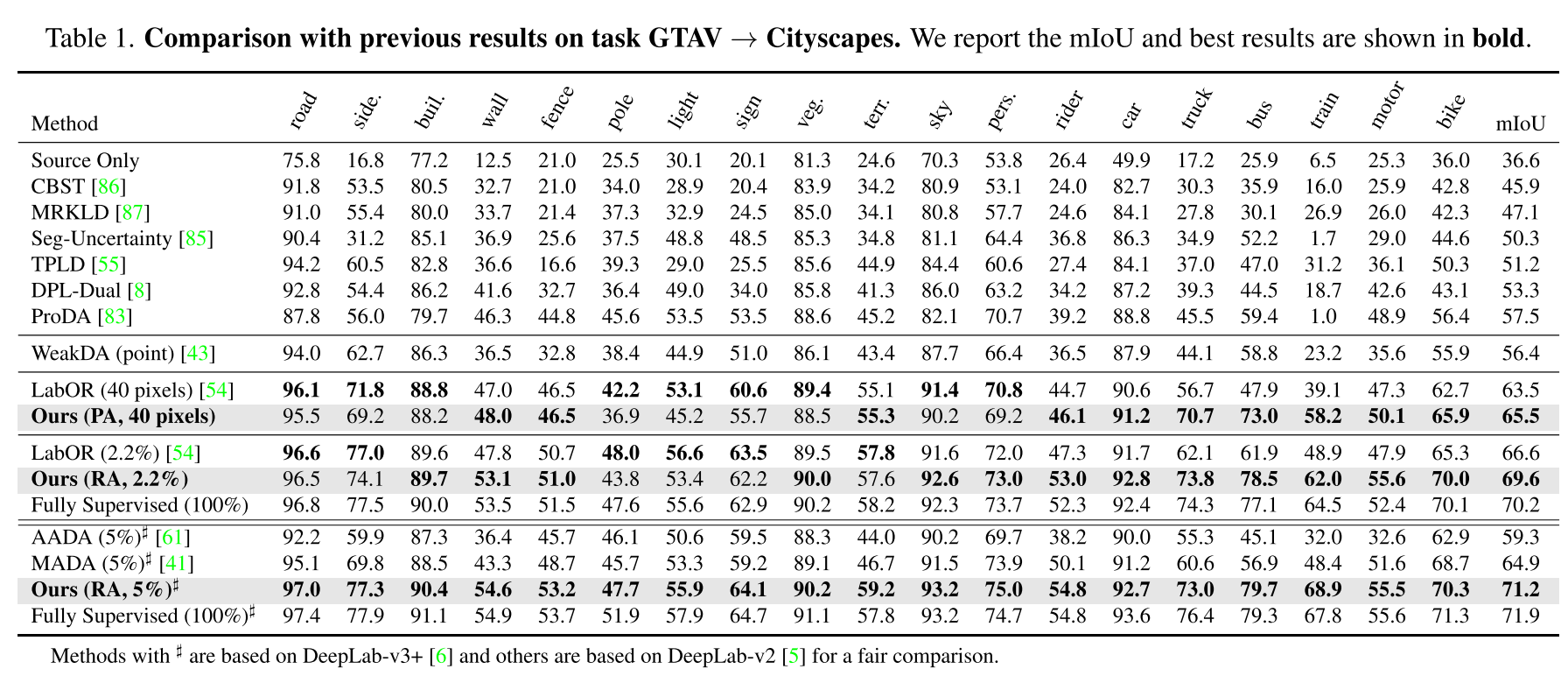
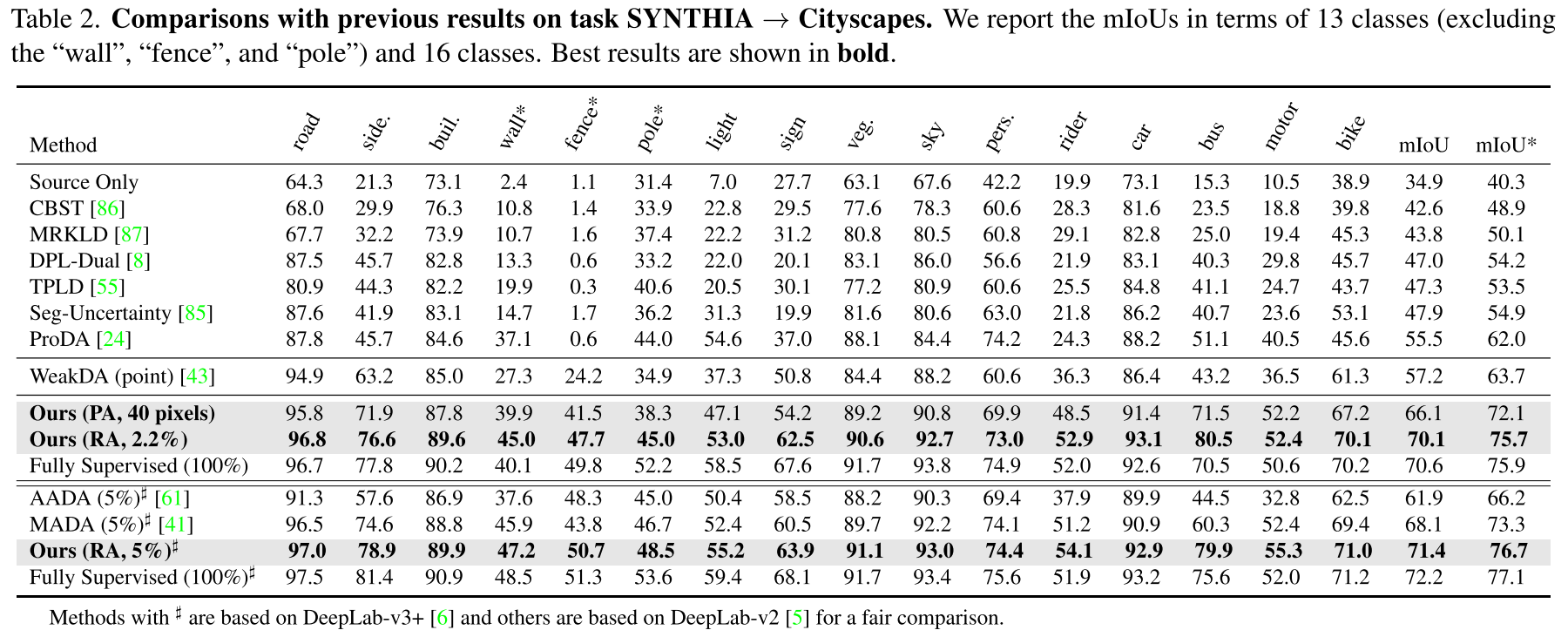

- 같은 backbone을 쓴 AADA, MADA를 같은 budget (5%)에서 이겼고, Fully Supervised과 근접한 성능을 성취하여 제안하는 알고리즘이 효과적이고 효율적임을 확인함.
4.2. Qualitative Results

- "However, uncertainty only tends to lump regions that are nearby together and Impurity Only focuses on regions gathered many categories."
- "Ours (RA) is also shown to pick diverse regions and not be grounded to a certain region of the image"
- 확 와닿지는 않는다
4.3. Ablation Study
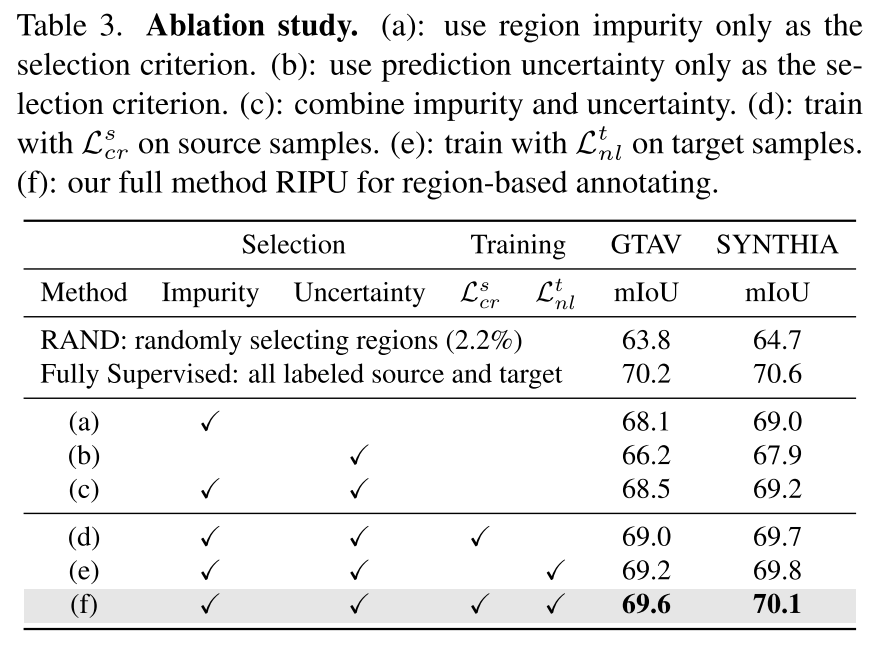
-
RIPU 중에 Region Impurity가 더 효과적이이었는데, 이미지 내의 spatial adjcency property는 class imbalance를 완화시키기 때문이다?
-
두 개 다 쓰면 most diverse하고 uncertain한 region을 sampling하는 관점에서 성능을 더 나아지더라?
-
RAND (GTAV)가 Table 1.의 LabOR (mIOU = 65.3)보다 조금 덜 나오는데..? 왜 잘 나옴?
-
RAND (SYNTHIA)가 5% budget 사용한 AADA (mIOU = 61.9)보다 더 잘 나오는데..?
4.4. Further Analysis
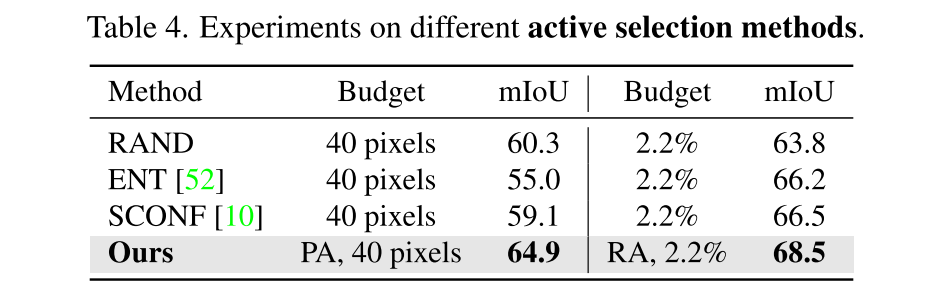
- common selection methods: Random Selection (RAND), Entropy (ENT), and softmax confidence (SCONF)
- 이게 RA를 적용하면 다른 얘들로도 잘 나오는데, Region-based Annotating이 훨씬 더 효과적으로 성능을 개선할 수 있음을 시사하기도 하는 느낌?
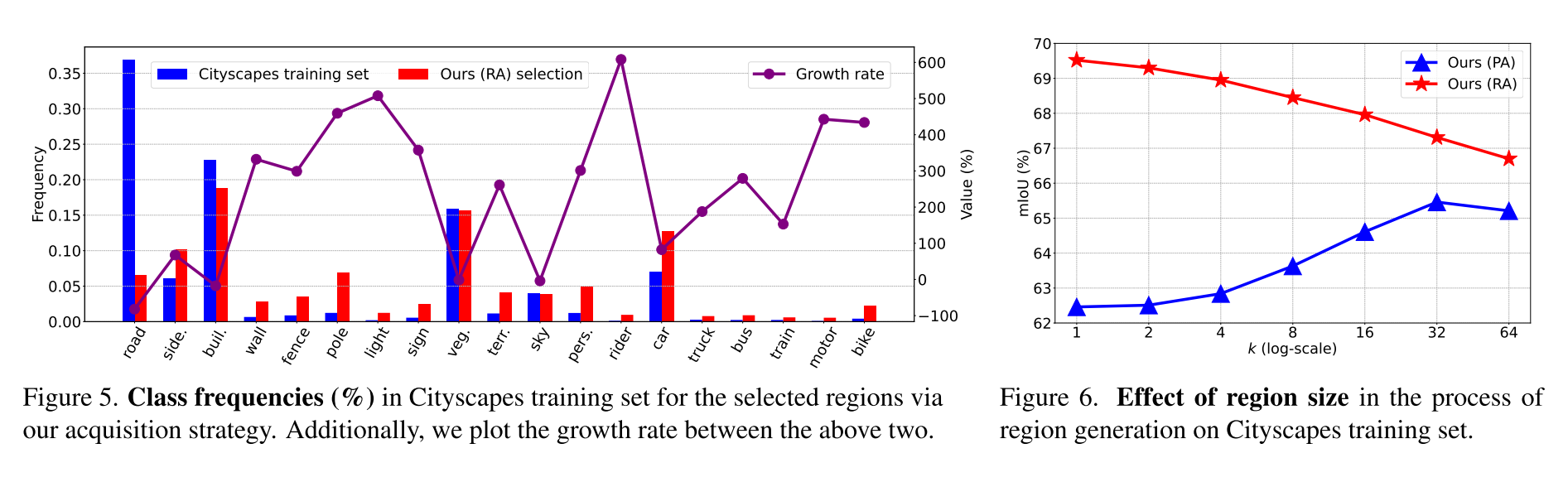
- Growth rate는 training set 대비 selection이 해당 class에 대해 얼마나 증가했는지
- 모델이 rare class를 더 뽑을려고 했다 -> data imbalance를 완화했다?
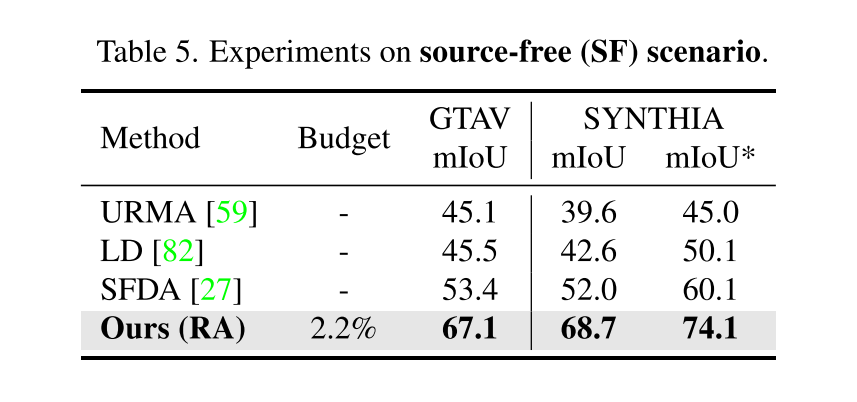
- Source-free Scenario라는 게 Unsupervised Domain Adaptation (UDA) 에서 Source에 대한 정보를 target data에서 learning할 때는 안 쓰는 것으로 하는 것 같은데
- URMA, LD, SFDA 등은 아예 annotation 없이 UDA를 한 것 같고,이 논문에서는 Source data 관련 loss를 제거하고 성능을 본 거라고 생각하면 될 것 같다.
- Source 관련 loss를 사용한 TABLE 1, 2에 비해 소폭 성능이 떨어졌으나 여전히 성능이 잘 나온다

- Fixed rectangle (아마도 grid 형태로 나눈 게 아닐까?), Superpixels
- k-square-neighbors는 (i,j)가 center라고 k만큼 근접한 정사각형 region N_k(i,j)을 기준으로 Region Impurity와 Prediction Uncertainty를 추출함
superpixel (SLIC) 예시

5. Conclusion
- Region Impurity and Prediction Uncertainty (RIPU)의 active learning 알고리즘으로 domain adaptive semantic segmentation의 한계를 개선하였다.
- spatial contiguity 안에서 diverse하면서도 uncertain한 한정된 target region을 선별하는 a novel region-based acquisition strategy를 제안한다.
- domain adaptive semantic segmentation (GTAV,SYNTHIA->cityscapes)에서 SOTA를 달성했다.
6. Further Discussion
code: https://github.com/BIT-DA/RIPU
Self-training using pseudo label
- domain adaptation 방식 중에서도 pseudo label을 사용해서 target에 대해서 model이 잘 훈련시키도록 하는 방식인 self-training을 사용하였음
Spatial adjacency/contiguity
- pixel-level classification 방식의 semantic segmentation에서 간과되는 spatial adjacency/contiguity를 domain adaptation에서 고려함으로써 큰 성능 개선을 이룬 것을 실험적으로 입증함
- pixel 하나당 (2k+1, 2k+1)의 정사각형에 대한 계산량이 생기는 k-square-neighbors를 제안하는 데, circle이나 좀 더 로 해보는 게 계산량이 조금은 더 줄지 않을까
- 애초에 Region-based loss (Dice Loss 등)를 활용해보는 건 별로인가
Learning Patterns
- <-> : source data에서 ground truth 를 가지고 pixel-level class를 예측하는 pattern을 학습하는 CE loss
- <-> : target data에서 target active label 를 가지고 pixel-level active class를 예측하는 pattern을 학습하는 CE loss
- <-> : target data에서 pseudo label의 noisy함을 제거한 negative pseudo label에 대해서 pixel-level negative pseudo label을 예측하는 pattern을 negative방향으로 학습하는 CE loss, Negative learning loss
Consistency Regularization Loss
- source data에서 각 pixel에 대한 prediction probability가 주변 (3x3) pixel에서의 prediction prob과 일관되도록 regularizing하는 loss
- source image에서의 각 pixel에 대한 예측이 주변 pixel (3x3)과 일관되게 할 수 있도록 하는 consistency regularization loss로 0.5 mIOU가 올랐음
- domain adaptation 말고 그냥 source만을 학습시킬 때도 쓰면 좋지 않을까?
Active Learning to only source dataset?
- source를 annotated sample, target을 unannotated sample이라고 하고 source dataset에 대해서만 active learning하는 쪽으로도 적용하면 좋게 나올 것 같은데..?
- 기존의 annotated sample에 overfitting되지 않으면서 unannotated sample에 대해서 Region-based annotating, Pixel-based annotating을 해서 진행하면 practical할까
