[2017 MICCAI] Suggestive Annotation: A Deep Active Learning Framework for Biomedical Image Segmentation
Paper Review
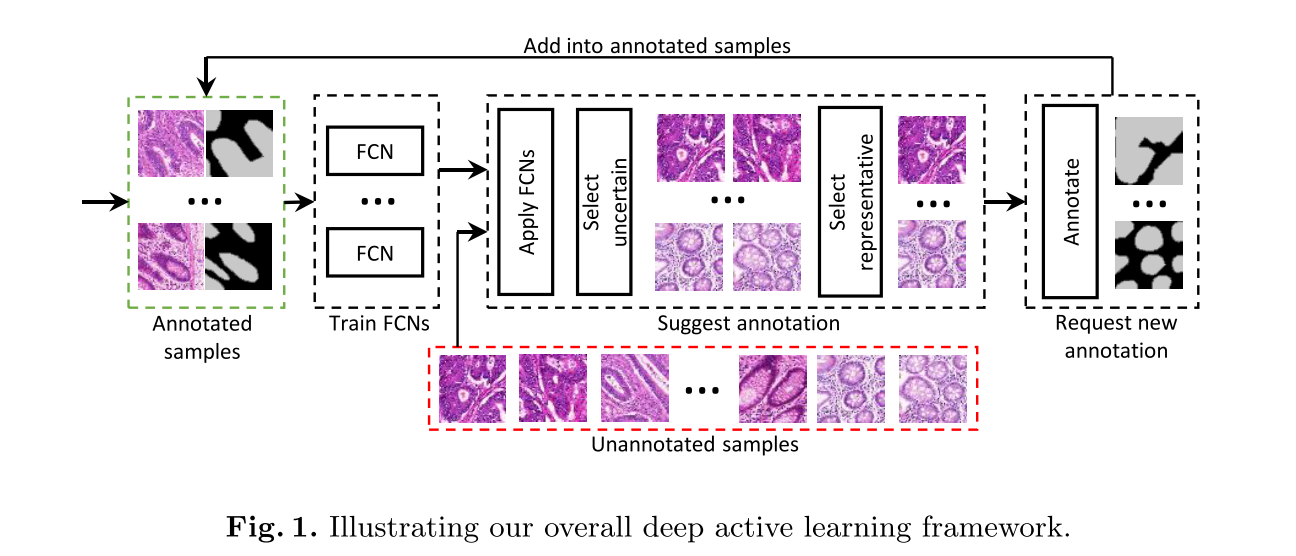
1. Introduction
biomedical image segmentation에서 annotation은 일부 전문가만 할 수 있고, instance가 굉장히 많은 경우도 있는데, annotation에 대한 제한된 effort로 어떤 instance들이 최고 성능을 얻기 위해 annotation되어야하는 가라는 의문점이 생긴다
natural scene과 다른 biomedical application에서의 tranining data 취득이 어려운 점:
1) only 훈련된 biomedical 전문가만 annotation할 수 있어 군중을 활용하기 어려움
2) biomedical image는 때때로 굉장히 많은 instance를 담고 있어 annotation에 대한 extensive manual effort를 발생시킴
관련연구
- Weakly supervised segmentation algorithm -> 높은 성능을 위해 annotation이 필요한 data sample을 고른다는 점을 고려하지 못함
- Active Learning -> 모델이 훈련 데이터를 고르도록 하는 걸로, 더 적은 training data로 SOTA를 찍었는데, 이는 large variation이 존재해서 object detection보단 segmentation이 필요한 biomedical application과는 동떨어짐
실험결과
- random query나 uncertainty query와 같은 흔한 방법들보다 annotation suggestion이 낫다
- 우리 framework가 50%만의 훈련데이터를 사용해 SOTA performance를 찍었다.
요약
적용분야: 성능 향상에 도움이 될 instance들을 골라서 annotation하자! (for biomedical image segmentation)
방법: FCN (seg)과 active learning을 조합한 Deep Active Learning Framework
2. Method
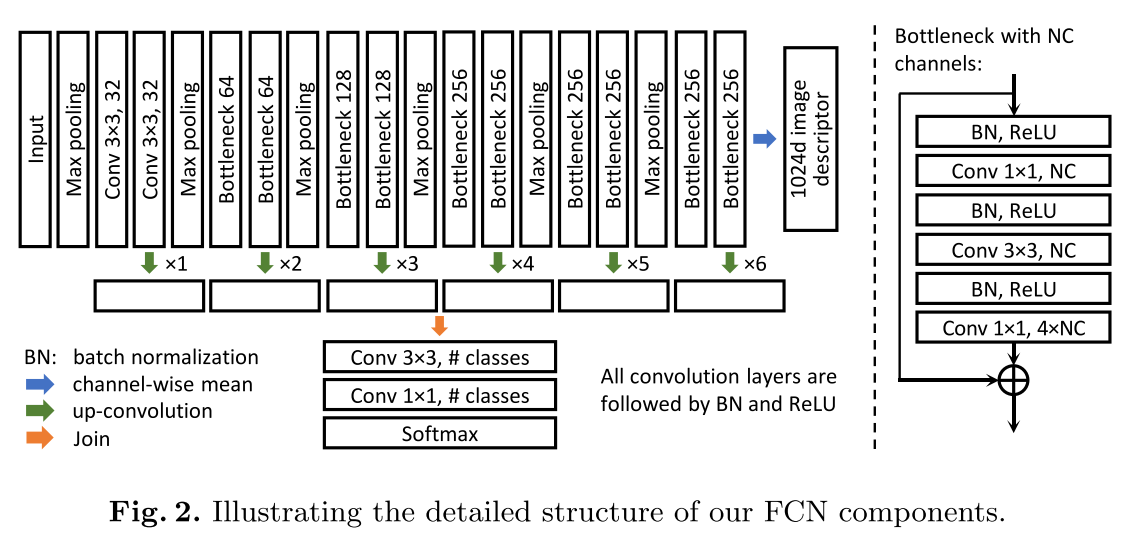
A New FCN
- BN으로 traning speed를 가속화시키고
- 각 encoder 단에서 각 resolution별로 output-level로 residual connection
Uncertainty estimation
- Bootstrapping, 이미지에서 FCN 모델들의 prediction의 variance를 계산하여 uncertainty를 추정하는 대표적인 방법
- 각 FCN별 inner variance는 variance의 overestimation을 초래할 수 있지만, 실제론 uncertainty 추정을 괜찮게 한다
- 각 pixel에 따라 추정된 uncertainty는 testing error와 강한 correlation을 가지고 있어 uncertain한 training sample을 고르는 건 potential error를 correct하는 데에 도움을 줌

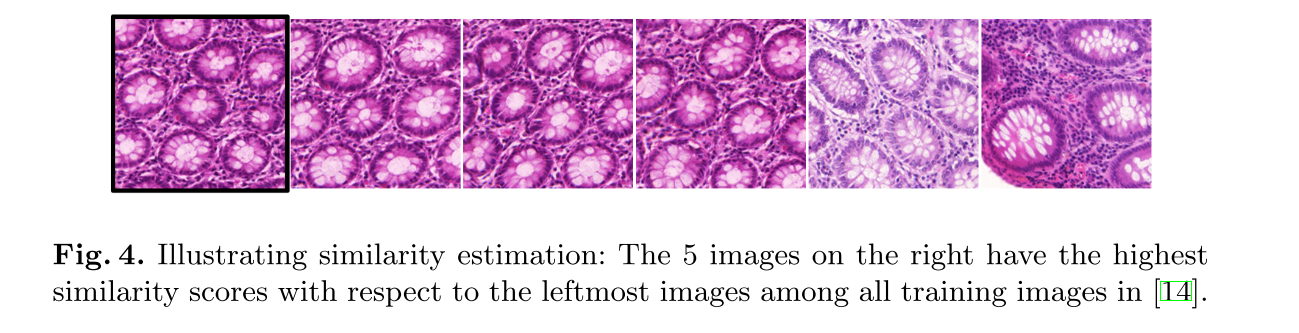
Similarity estimation
- 마지막 convolutional layer output들의 cosine similarity로 추정
Annotation Suggestion
- 모든 unannotated 이미지 S_u 중에 highly uncertain하고 representative한 subset S_a를 고르는 것이 목적
- step 1, top K (K > k) uncertainty score를 가진 이미지를 S_c로 선별
- stpe 2, S_c 중에 가장 대표되는 이미지를 선별하여 S_a를 구성
- Iterative하게 S_c에 이미지가 추가 되면 다른 unannotated sample들과의 similarity가 가장 큰 값을 가지는
S_u: unannotated sample 전체
S_c: S_u 중 uncertained sample (K 개)
S_a: S_c 중 representative sample (k 개)
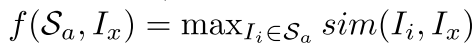
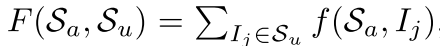
F(S_a, S_u)를 maximize해 S_c 중에 있는 S_a를 찾으면서 unannotated sample들과 유사한 k개의 hub image들을 고르고 diverse case들을 커버하는 S_a를 선별하게 됨
이를 generalized version of the maximum set cover problem으로 수식화할 수 있음
sim( , ) {0, 1}을 따르면
f(S_a, I_x)는 1 (covered) or 0 (not covered)
F(S_a, S_u)는 covered image의 총 갯수가 됨
F(S_a, S_u)가 최대가 되는 S_a에서 k-image를 찾는다는 것은 k subset의 family F 찾는다는 것이고,
maximum set cover problem은 NP-hard이고 것의 가장 가능성있는 polynomial time 근사 알고리즘은 uncovered element 중에서 가장 많은 수를 cover하는 S_i를 iterative하게 선택하는 간단한 greedy 방법임
S_a를 공집합, F(S_a, S_u) = 0으로 초기화해놓고, S_a가 k개의 image를 포함할때까지, S_a에 걸쳐 F(S_a U I_i, S_u)를 최대화하는 I_i (in S_c) 를 interative하게 더해간다.
이 알고리즘은 1-1/e의 근사 비율을 달성한다.
3. Experiments and Results
Datasets
- 2015 MICCAI Gland Challenge dataset
- 85 training images
- 80 testing images (60 in Part A; 20 in Part B)
- lymph node ultrasound image segmentation dataset
- 37 training images
- 37 testing images
Parameters and Networks
- k = 8, K = 16, 2000 training iterations, and 4 FCNs
Waiting Time
- 두 annotation suggestion stage 사이의 대기 시간은 10분 정도 (4 NVIDIA Tesla P100 GPU)
- K=16, k=8로 S_a를 선별하는 과정 1번이 10분 걸린다는 소리인가.
Annotation Suggestion
- annotation cost는 관련 pixel들의 수로 계산되고, budget을 두고 비교하였음
- random query: budget에 맞춰 random하게 annotation을 부탁하는 것
- uncertainty query: K 개의 uncertain sample (S_c)에서 uncertain한 영역만 annotation 부탁하는 거

- Table 1은 full training data를 사용한 a new FCN의 성능을 당시 해당 benchmark 최고성능 알고리즘과 비교한 것으로 SOTA를 찍음
- Table 2는 annotation suggestion method를 평가한 것으로 Uncertainty query만 사용해도 성능향상이 잘 이뤄졌고, 50% 훈련데이터만 사용했는데도 SOTA를 찍었다.
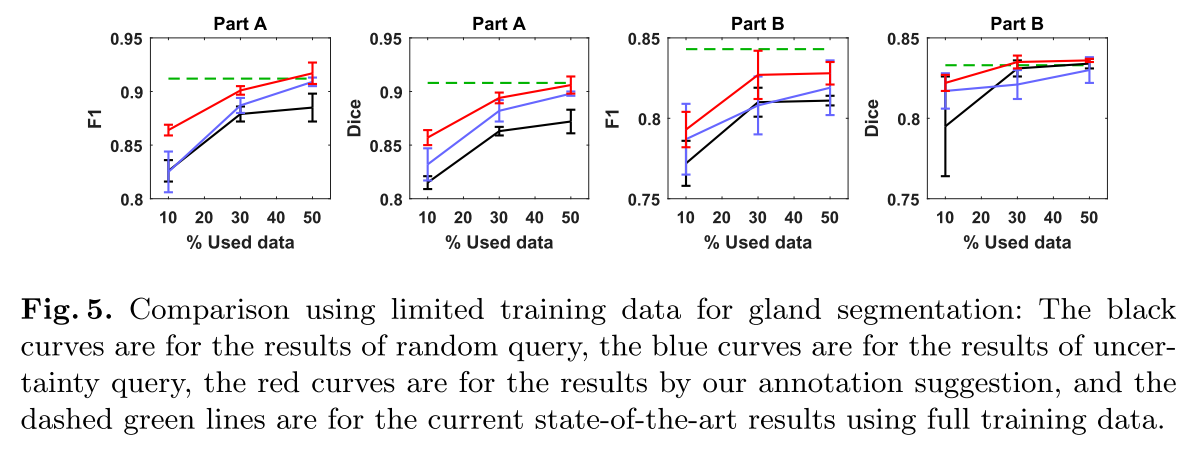
점선이 full training data, 빨간 선이 Suggestive Annotation, 파란 선이 Uncetainty Query, 검은 선이 Random Query로 budget에 따른 성능향상을 봤는데, 50 %만 사용해도 SOTA를 찍었다.
4. Conclusions
논문이 말하는 two main contribution
(1) SOTA segmentation performance를 달성한 A new FCN model
(2) 가장 효과적인 annotation 영역으로 manual annotation effort를 direct할 수 있는 annotation suggestion approach
5. Further Discussion
주어진 task의 pattern learning에 더 유의미한 sample
annotation 비용과 무관하게 생각하더라도 learning에 있어서 더 유의미한 data가 존재한다는 맥락에서 이 논문은 uncertain하면서도 representative한 sample들을 골라 annotation을 부탁하는 active learning 관점을 biomedical segmentation에 적용해서 빠른 성능 달성과 성능 향상 (전체 training data를 사용하는 것보다도) 실험결과로 입증하였음
Implementation Detail
Framework가 training - suggestion - annotation 요렇게 과정이 분리가 되어있는데,
initial annotated training sample (S_u) 의 수가 어느 정도로 설정되어있고, 어떤 시점(주기)에 S_a를 선별해 annotated training sample (S_u)에 추가하는 지에 대한 설명이 없어서 아쉬움
첫 initial annotated training sample을 선별하는 것조차도 의미가 클 거임 (그 데이터로 학습한 pattern으로 uncertain한 걸 고르면 initial training data의 패턴이 점차 누적
오히려 조금씩 annotation을 자주 부탁하면 suggestion과 annotation사이의 delay가 누적될 수 있음을 경계해야한다. 총 annotation cost를 annotation한 pixel수만 따지면 그를 간과할 수 있음
