Domain Adaptation
: aimed at enhancing the performance of models when they are applied to different but related domains.
| Target doamin labeled | Target domain unlabeled | |
|---|---|---|
| Source domain labeled | Multi-task Learning | Unsupervised Domain Adaptation |
| Source domain unlabeled | Self-Supervised Learning | Unsupervised Learning |
전이학습에 도메인 적응이 포함되는 건가? 도메인 적응이라는 개념 안에 전이학습이 있는 건가?
Transfer Learning
-
Transductive Transfer Learning
- annotated data only in source domain
- same domain and same task
- Sample Selection Bias / Covariance Shift
- different domains but same task
- Domain Adaptation
-
Unsupervised Transfer Learning
- no annotated data
-
Inductive Transfer Learning
- annotated data in target domain
- annotated data in source domain, source and target tasks are learned simultaneously
- Multi-Task Learning
- no annotated data in source domain
- Self-Taught Learning
위 자료에 따르면 전이학습 내에 도메인 적응이 포함되어 있는 것으로 보인다. 도메인 적응은 작업이 동일하다는 점에서 전이학습에 포함된다고 보는 것 같다. 그렇지만 나는 구분하기보다 그때그때 상황에 맞게 이해하면 될 것 같다.
- 전이학습 : 학습된 모델의 지식을 다른 작업이나 도메인에 적용하는 방법.
- 도메인 적응 : 개념. 소스 도메인과 타겟 도메인의 데이터 분포 차이를 극복하는 데 중점.
Key concepts
Domain shift(도메인 변화) - between source domain and target domain
Covariate shift(공변량 이동)
: 입력 데이터의 특징 분포는 다르지만 각 입력에 대한 출력의 조건부 분포는 도메인 간에 일정하게 유지되는 경우.
- ex) 이미지 분류에서, 소스 도메인은 밝은 날씨의 이미지, 타겟 도메인은 흐린 날씨의 이미지.
Conditional shift(조건부 이동)
: 클래스별 조건부 분포가 다른 경우, 이는 클래스 간에 서로 다른 이동 프로토콜이 있는 경우. 현실적인 상황을 더 잘 반영한다.
- ex) 질병 진단 문제에서, 소스 도메인은 질병이 많이 발생하는 지역의 데이터, 타겟 도메인은 그 질병이 거의 없는 지역의 데이터.
Label shift(레이블 이동)
: 클래스의 샘플 비율이 도메인 간에 다른 경우. 클래스 비율의 차이에 더 중점을 둠. 클래스 불균형 문제를 처리할 때 중요한 고려사항.
- ex) 물체 인식 문제에서, 같은 물체가 소스 도메인에서는 다양한 각도에서 촬영되었고, 타겟 도메인에서는 특정 각도에서만 촬영된 경우.
Concept shift(개념 이동)
: 특징이 주어졌을 때의 조건부 분포가 도메인 간에 다른 경우. 입력이 동일해도 출력이 달라질 때. 모델이 학습한 개념이 타겟 도메인에서 다르게 적용된다.
- ex) 음성 인식 문제에서 소스 도메인과 타겟 도메인이 각각 다른 언어의 발음을 포함.(언어적, 문화적, 산업적 차이가 존재할 수 있음)
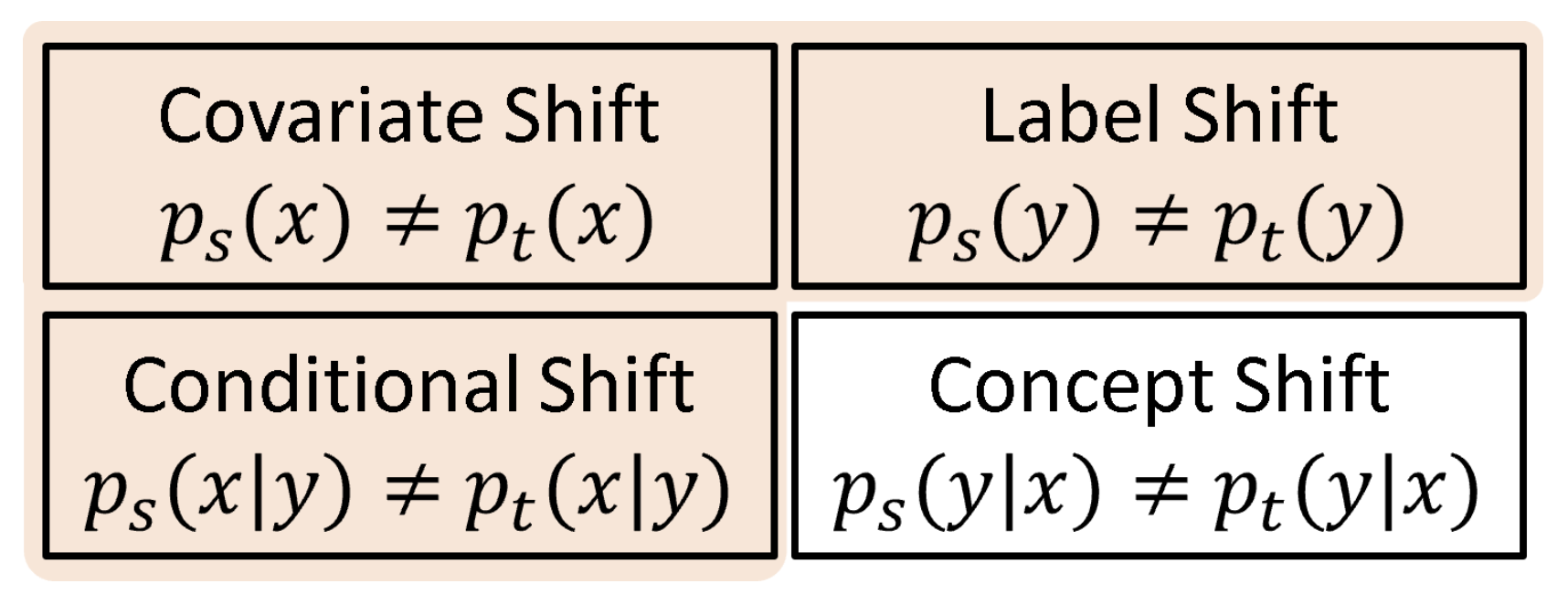
####요약
공변량 이동 : 입력 데이터의 분포가 다르지만 조건부 분포는 동일함.
레이블 이동 : 클래스 비율이 도메인마다 다름.
조건부 이동 : 특정 클래스에 대한 특징의 분포가 다름.
개념 이동 : 동일한 입력에 대한 출력의 조건부 확률이 다름.Domain shift에 따른 Domain adaptation 기법
Covariate Shift(공변량 이동)
- Importance Weighting: 소스 도메인의 샘플에 타겟 도메인의 분포에 맞춰 가중치를 부여하여 학습.
- Feature Transformation: 소스와 타겟 도메인의 특징 공간을 일치시키기 위해 특징을 변환.
- PCA 또는 T-SNE를 사용하여 특징을 저차원 공간으로 변환.
- Kernel Mean Matching (KMM): 소스 도메인의 특징 분포를 타겟 도메인에 맞추기 위해 특징 공간을 매칭.
- Domain-Adversarial Training: 분류기와 도메인 판별기를 동시에 학습하여 특징을 도메인 불변하게 만듦.
- Domain-Adversarial Neural Network (DANN): 특징 추출기가 소스와 타겟 도메인에서 동일한 분포를 갖도록 학습.
Conditional Shift(조건부 이동)
- Class-wise Domain Adaptation: 클래스별로 도메인 적응을 수행하여 클래스 간의 차이를 줄임.
- Conditional Adversarial Domain Adaptation (CDAN): 조건부 분포를 맞추기 위해 클래스 정보를 사용하는 적대적 학습.
- Instance Reweighting: 클래스별로 가중치를 부여하여 타겟 도메인의 분포를 맞춤.
- Balanced Weighting: 클래스 불균형을 줄이기 위해 소스 도메인의 샘플에 가중치를 부여.
Label Shift(레이블 이동)
- Prior Shift Adaptation: 소스 도메인과 타겟 도메인의 클래스 비율 차이를 조정.
- Target Shift Estimation: 타겟 도메인의 클래스 비율을 추정하여 모델의 예측을 조정.
- Reweighting Techniques: 클래스 비율을 맞추기 위해 샘플 가중치를 조정.
- EM Algorithm: 기대-최대화 알고리즘을 사용하여 클래스 비율을 추정하고 조정.
- Class Balancing Methods: 샘플을 재샘플링하거나 가중치를 부여하여 클래스 비율을 맞춤.
- SMOTE: 소수 클래스의 샘플을 증가시켜 클래스 불균형을 해결.
Concept Shift(개념 이동)
- Fine-Tuning: 타겟 도메인의 데이터를 사용하여 소스 도메인에서 학습된 모델을 미세 조정.
- Transfer Learning: 소스 도메인에서 학습된 모델을 타겟 도메인에 맞게 재학습.
- Ensemble Methods: 여러 모델을 조합하여 도메인 간의 개념 차이를 줄임.
- Domain Ensembles: 소스 도메인과 타겟 도메인의 데이터로 각각 학습된 모델을 조합하여 예측.
- Conditional Adversarial Networks: 조건부 분포 차이를 줄이기 위해 적대적 학습을 사용.
- Adversarial Discriminative Domain Adaptation (ADDA): 소스 도메인의 특징 추출기를 타겟 도메인에 맞추기 위해 적대적 학습.
Traditional Domain Adaptation
- Metric Learning(거리 학습) : 데이터 포인트 간의 유사성이나 비유사성을 측정하는 거리 함수를 학습하는 기계 학습 → 유사한 인스턴스는 더 가깝게, 비유사한 인스턴스는 더 멀리 두는 거리 측정 학습
- Siamese Networks : 두 개의 입력 데이터를 사용하여 유사한 쌍의 거리 최소화, 비유사한 쌍의 거리 최대화
- Triplet Networks : 삼중 항목 데이터를 사용하여 더 구별력 있는 거리 학습
- Contrastive Loss : 유사한 쌍에 대해 거리가 큰 경우와 비유사한 쌍에 대해 거리가 작은 경우를 페널티하는 손실 함수
- Triplet Loss : 앵커와 긍정적 샘플 간의 거리가 앵커와 부정적 샘플간의 거리보다 작도록 하는 손실 함수
- Subspace Representation(부분 공간 표현) : 고차원 데이터를 저차원 부분 공간으로 투영하여 데이터의 중요한 구조와 관계를 유지하는 방법 → 데이터의 본질적인 구조를 유지하면서 저차원 공간 찾기
- PCA(Principal Component Analysis) : 데이터의 분산을 최대화하는 방향을 찾는 선형 기법
- LDA(Linear Discriminant Analysis) : 서로 다른 클래스를 가장 잘 분리하는 선형 조합을 찾음
- Kernel PCA : 커널 함수를 사용하여 비선형 변환을 수행하는 PCA
- Manifold Learning : t-SNE, Isomap 등 데이터의 비선형 구조를 포착하는 기법
- Matching Distribution(분포 정렬) : 소스 도메인과 타겟 도메인의 데이터 분포를 정렬하여 도메인 이동을 최소화하는 방법. 두 도메인의 특징 분포를 유사하게 만들어 모델이 타겟 도메인에서도 잘 작동하도록 함. → 분포 차이 줄이기
- MMD(Maximum Mean Discrepancy) : 재현 커널 힐베르트 공간(RKHS)에서 소스와 타겟 분포의 평균 차이를 측정
- Wasserstein Distance : 최적 수송 문제를 기반으로 분포 간 거리 측정
- Adversarial Training : 도메인 적대적 신경망(DANN)을 사용하여 소스와 타겟 특징 분포를 유사하게 만듦
- CORAL : 소스와 타겟 도메인의 공분산 행렬을 정렬하여 도메인 이동을 줄임
Types of Domain adaptation - '데이터 라벨링 유무'기준
- Supervised domain adaptation : labeled data is available in both source and target domains
- Unsupervised domain adaptation : labeled data is available only in the source domain, and the target domain has no labels
- Semi-supervised domain adaptation : both labeled and unlabeled data are available in the target domain
Approaches to Domain Adaptation(UDA)
- Instance-based adaptation(인스턴스 기반 적용) : 소스 도메인 인스턴스의 가중치를 조정하여 타겟 도메인에 더 잘 맞게 만드는 방법. 대표적인 방법으로 중요도 가중치 조정(importance weighting)
- ex) 마케팅 데이터에서 고객의 구매 패턴이 지역마다 다를 때, 소스 도메인의 데이터를 타겟 도메인에 맞게 가중치 조정하여 모델 학습
- Feature-based adaptation(특징 기반 적용) : 도메인 불변 특징을 학습하여 소스와 타겟 도메인의 분포를 특징 공간에서 정렬하는 것을 목표로 함.
- Maximum Mean Discrepancy (MMD) : 최대 평균 차이
- Correlation Alignment (CORAL) : 소스와 타겟 특징 분포의 공분산 정렬
- Adversarial Training: Using generative adversarial networks (GANs) to align feature distributions : 적대적 네트워크를 사용하여 특징 분포를 도메인 간에 구분할 수 없도록 함.
- ex) 이미지 분류 문제에서 밝은 날씨의 소스 도메인 이미지와 흐린 날씨의 타겟 도메인 이미지를 특징 공간에서 정렬하여 모델 성능 향상
- Model-based adaptation(모델 기반 적용) : 모델 매개변수를 조정하여 도메인 간의 차이를 줄이는 방법.
- Domain-Adversarial Neural Networks (DANN) : 도메인 분류기를 도입하여 적대적 훈련을 통해 도메인 불변 특징을 학습.
- Domain-Specific Batch Normalization : 도메인 특화 통계를 반영하도록 정규화 계층을 조정.
- ex) 의료 데이터 분석에서 서로 다른 병원 간의 진단 기준 차이를 줄이기 위해 도메인 적대적 신경망 사용
- Hybrid approaches(혼합 접근) : combining techniques for more robust adaptation

KU ICTM