신경망은 원래 학습을 위해 레이블이 지정된 데이터가 많이 필요하고, 수동으로 주석을 달기는 힘들다. 그리고 학습된 딥러닝 모델은 학습 데이터와 동일한 데이터 분포에서만 테스트 데이터에서 좋은 성능을 보인다. 이런 문제를 해결하기 위한 방법이 도메인 적응이다.
Key Defenitions
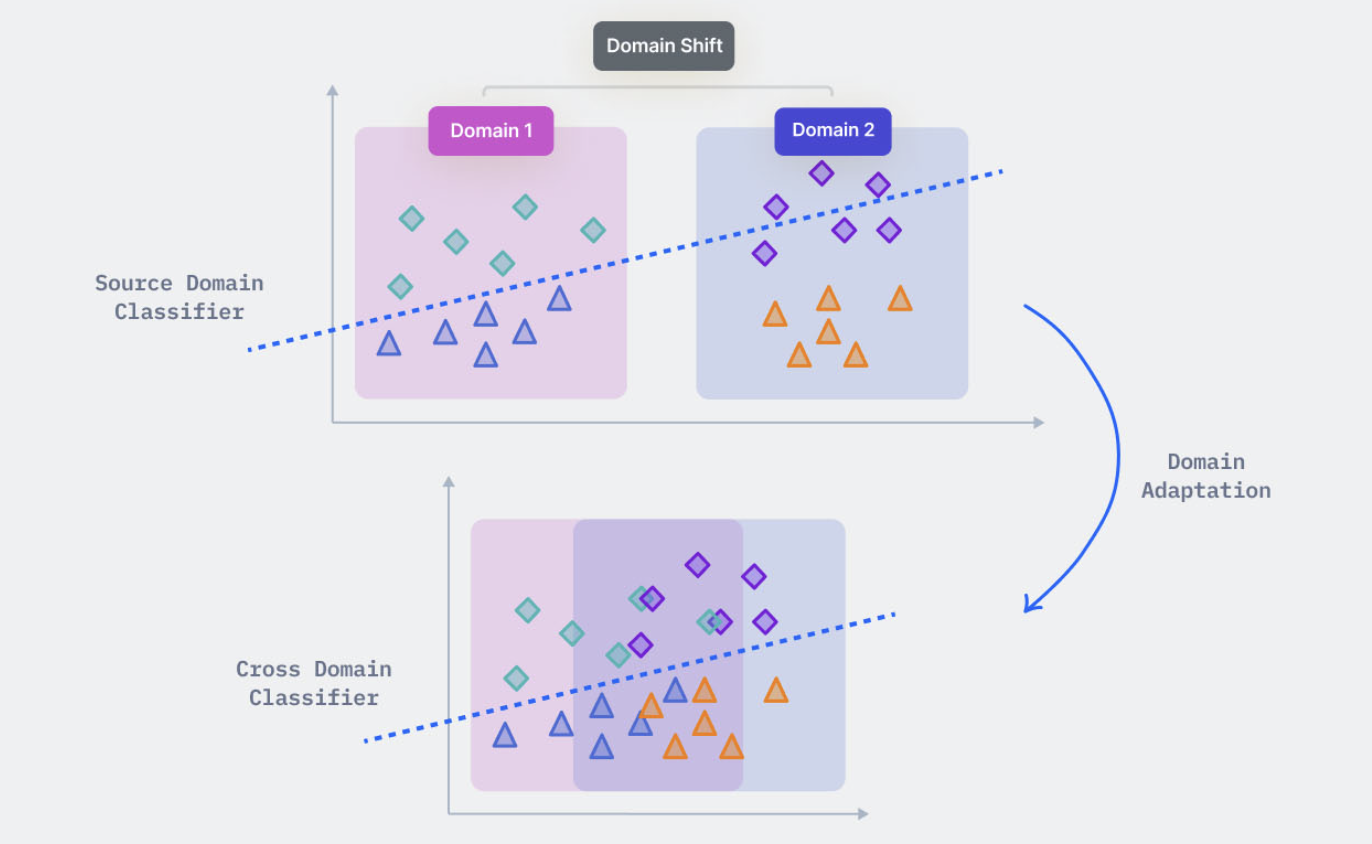
- Source Domain : This is the data distribution on which the model is trained using labeled examples.
- Target Domain :This is the data distribution on which a model pre-trained on a different domain is used to perform a similar task.
- Domain Translation : Domain Translation is the problem of finding a meaningful correspondence between two domains.
- Domain Shift : A domain shift is a change in the statistical distribution of data between the different domains (like the training, validation, and test sets) for a model.
Types of Domain Adaptation
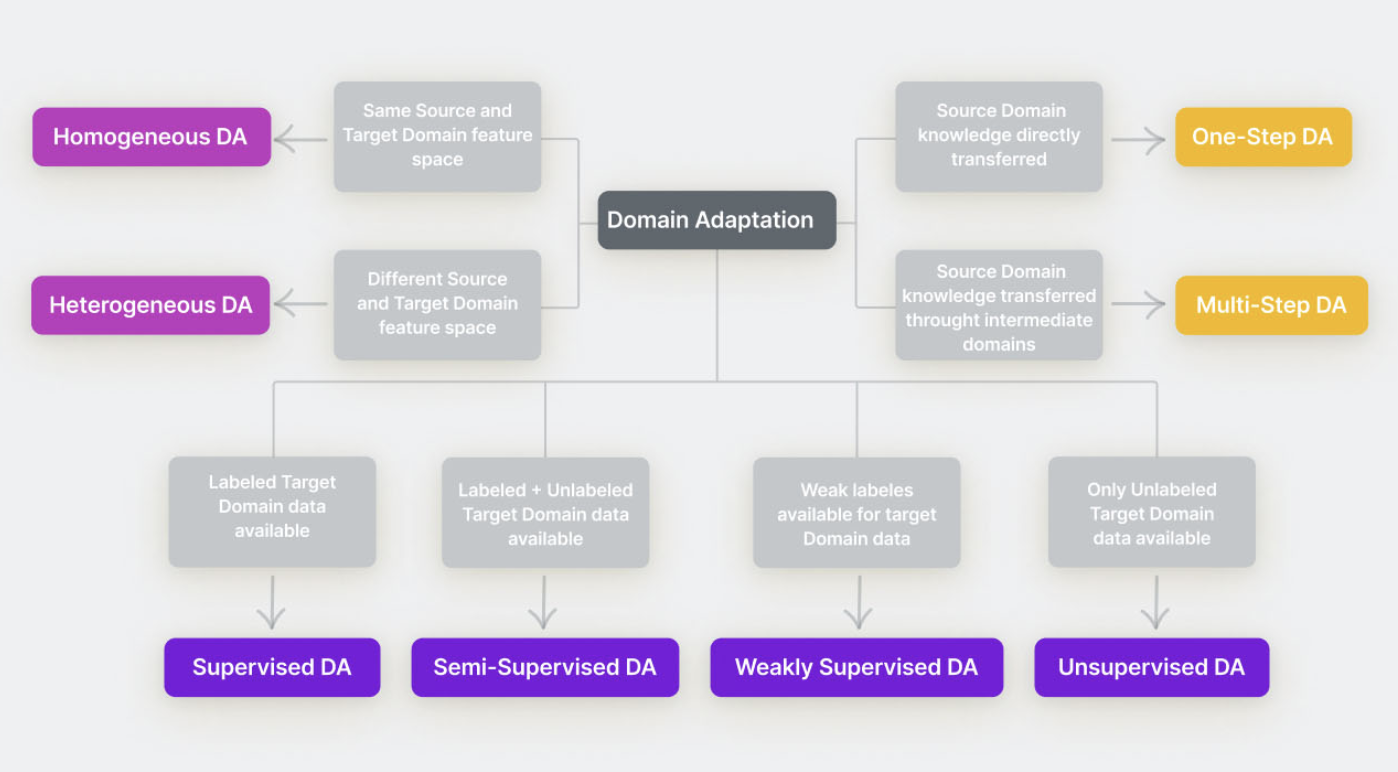
Types of DA based on the labeling of target domain data
- Supervised DA
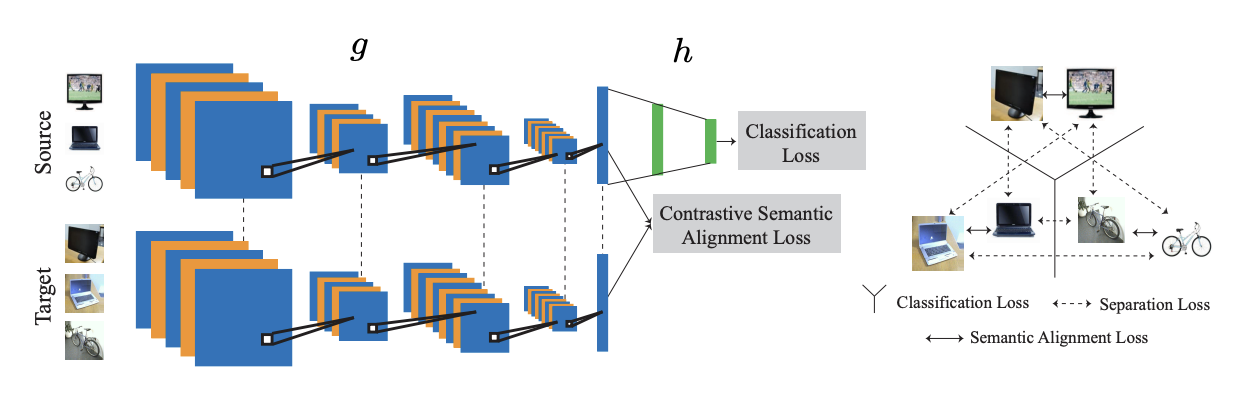
지도 도메인 적응에서는 타겟 도메인 데이터가 완전히 라벨링되어 있다. 타겟 도메인의 훈련 데이터가 그렇게 많지 않더라도 최적의 성능을 발휘할 수 있고, 라벨링 비용도 많이 들지 않는다. 논문 Unified Deep Supervised Domain Adaptation and Generalization에서는 분류 및 대조 의미 정렬(Classification and Constrastive Semantic Alignment, CCSA)손실을 도입한다. 입력 이미지는 딥러닝 모델을 사용하여 임베딩 / 특징 공간으로 매핑되며, 이를 바탕으로 분류 예측이 이루어진다.
- Semi-Supervised DA
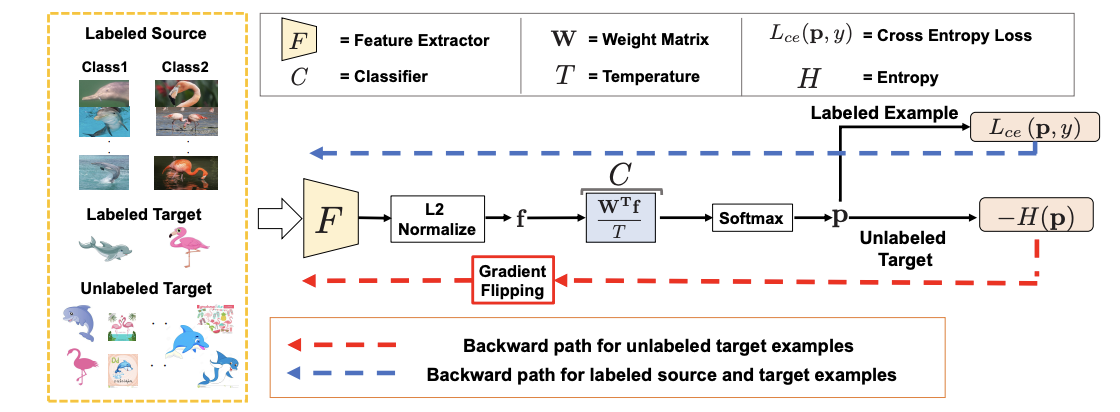
반지도 도메인 적응은 타겟 도메인에서 소수의 데이터 샘플만 라벨링된 상태를 의미한다. 비지도 도메인 적응은 타겟 도메인의 데이터가 소수만 라벨링된 경우 성능이 저조한 것으로 알려져 있다. 논문 Semi-supervised Domain Adaptation via Minimax Entropy에서는 코사인 유사도 기반 분류기 구조를 제안하였고, 이는 특징 추출기의 출력과 K개의 클래스별 가중치 벡터 간의 코사인 유사도를 계산하여 K-방향 클래스 확률 벡터를 예측한 후 소프트맥스 함수를 적용한다. 각 클래스 가중치 벡터는 해당 클래스의 대표 점으로 간주될 수 있는 프로토타입으로 추정된다. 이는 Few-shot learning에서 사용되는 것과 유사하다.
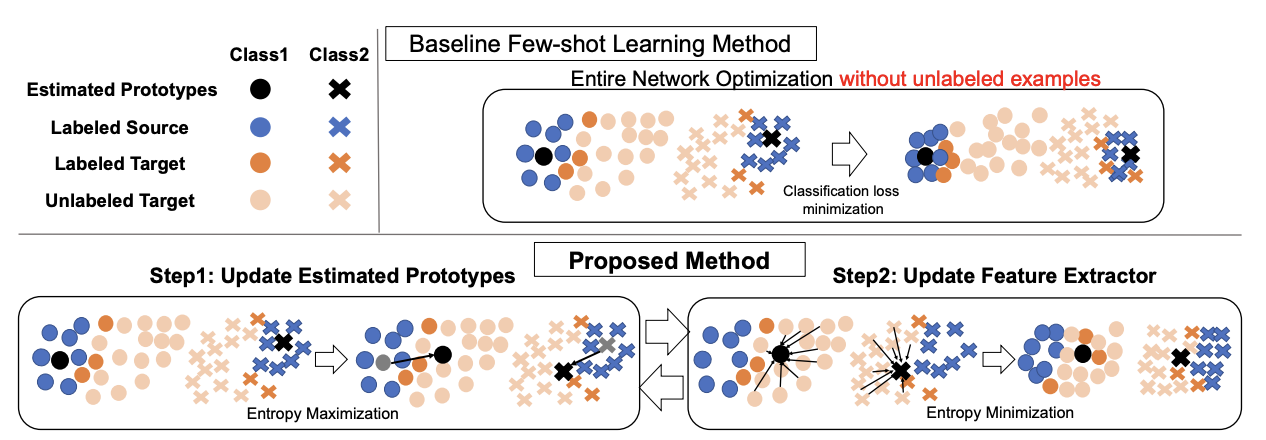
첫 번째 적대적 단계에서 레이블이 없는 타겟 예제의 엔트로피를 최대화하여 가중치 벡터를 타겟 쪽으로 이동시킨다. 이후 특징 추출기를 업데이트하여 레이블이 없는 예제의 엔트로피를 최소화하여 이들이 프로토타입 주위에 더 잘 클러스터링되도록 한다. 이 과정은 가중치 벡터와 특징 추출기 간의 미니맥스 게임으로 공식화되며 레이블이 없는 타겟 예제에 적용된다. 이 접근 방식의 개요는 아래 그림과 같다.
- Weakly Supervised DA
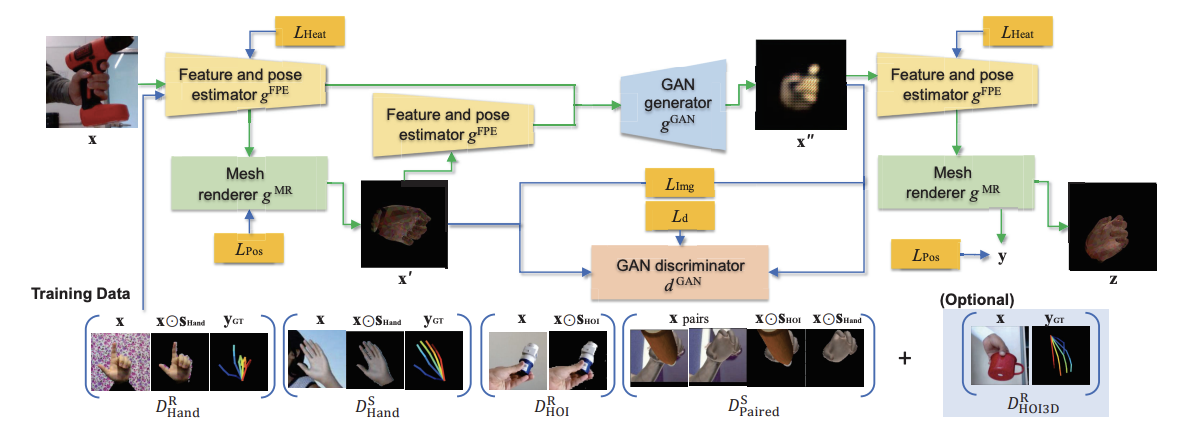
약한 지도 도메인 적응은 타겟 도메인에서 '약한 레이블'만 이용할 수 있는 문제 설정을 의미한다. 예를 들어, 의미적 분할 도메인 적응 문제에서, 타겟 도메인에서 실제 마스크를 사용할 수 없지만, 분할할 객체의 카테고리는 제공될 수 있다. 여기서 카테고리 레이블이 weak label이고, 실제 분할 마스크는 hard label이라고 부른다. 논문 Weakly-supervised Domain Adaptation via GAN and Mesh Model for Estimating 3D Hand Poses Interacting Objects는 이미지 공간에서 두 가지 지침을 사용하여 도메인 적응을 달성했다. 생성적 적대 신경망(GAN)과예측된 3D mesh와 텍스처를 사용하는 mesh renderer. 결과적으로 입력된 HOI 이미지는 분할되고 가려지지 않은 손만 포함된 이미지로 변환되어 HPE 정확도가 효과적으로 향상된다.
- Unsupervised DA
비지도 도메인 적응은 타겟 도메인 데이터에 대한 어떤 종류의 레이블도 없는 상태를 의미한다. 소스 도메인 데이터로 훈련된 모델이 타겟 도메인에 독립적으로 적응해야 한다. Unsupervised Domain Adaptation with Residual Transfer Networks는 UDA 방법 중 하나로 새로운 Residual Transfer Network(RTN) 접근 방식을 제안한다. 심층 네트워크에서 적응형 분류기와 전이 가능한 특징을 동시에 학습할 수 있다. 이전 방법들이 공유 분류기 가정을 했던 것과 달리, 이 방법에서는 소스와 타겟 분류기가 작은 잔여 함수로 다르다고 가정한다.

이 방법에서는 여러 계층을 심층 네트워크에 삽입하여 타겟 도메인 분류기와의 참조를 통해 함수를 명시적으로 학습함으로써 분류기 적응을 가능하게 한다. 이를 통해 소스 도메인 분류기와 타겟 도메인 분류기가 역전파 과정에서 밀접하게 연결할 수 있다. 이 외에도 여기저기 찾아보니, 소스 도메인과 타겟 도메인의 분류기를 연결하는 여러 방법들이 있었던 것 같다.
Homogenous DA vs Heterogeneous DA
- Homogenous DA
동질 도메인 적응은 소스 도메인과 타겟 도메인의 특징 공간이 동일하고 차원도 동일하지만, 데이터 분포에만 차이가 있는 문제를 말한다. 소스와 타겟 도메인 데이터가 동일한 유형의 특징을 사용하여 수집된다고 가정하는데, 교차 도메인 데이터는 동일한 특징 공간에서 관찰되지만 다른 분포를 보인다는 것이다. 이를 distribution-shift 유형의 도메인 적응 문제라고도 한다.
- Heterogeneous DA
이질 도메인 적응은 소스 도메인과 타겟 도메인이 동등하지 않으며 다른 특징 공간 차원을 가질 수 있다. 이질 도메인 적응에서는 서로 다른 특징으로 설명되기 때문에 서로 다른 분포를 보인다.(다른 해상도의 훈련 및 테스트 이미지 데이터, 혹은 다른 코드북으로 인코딩된 데이터) 따라서 이를 feature space difference 유형의 도메인 적응 문제라고도 하며, 동질 도메인 적응보다 훨씬 더 어려운 문제이다. Learning Cross-Domain Landmarks for Heterogeneous Domain Adaptation에서는 Cross-Domain Landmark Selection(CDLS)의 학습 알고리즘을 제안한다.
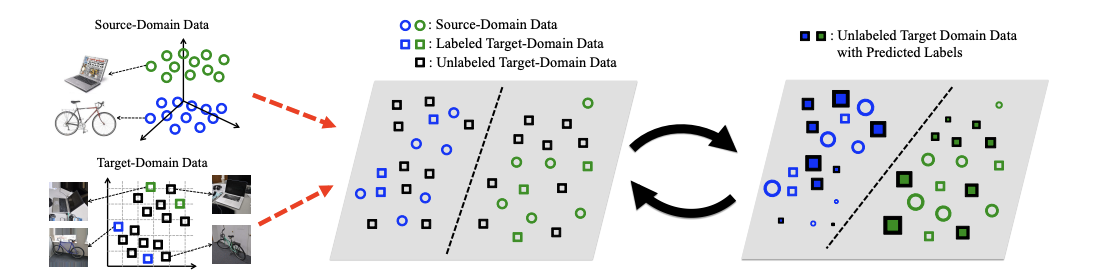
CDLS 모델은 적응 과정에서 모든 교차 도메인 데이터를 동등하게 중요하다고 보는 대신, 이질적 특징 변환을 도출하여 교차 도메인 데이터를 연결하기 위한 도메인 불변 부분 공간을 생성한다. 또한 소스 도메인과 타겟 도메인의 대표 데이터를 공동으로 활용하여 CDLS의 적응 능력을 향상시킨다. 적응 과정이 완료되면, 인식을 수행하기 위해 교차 도메인 레이블이 지정되고 지정되지 않은 타겟 도메인 데이터를 도출된 부분 공간 위에 투영할 수 있다.
One-Step DA vs Multi-Step DA
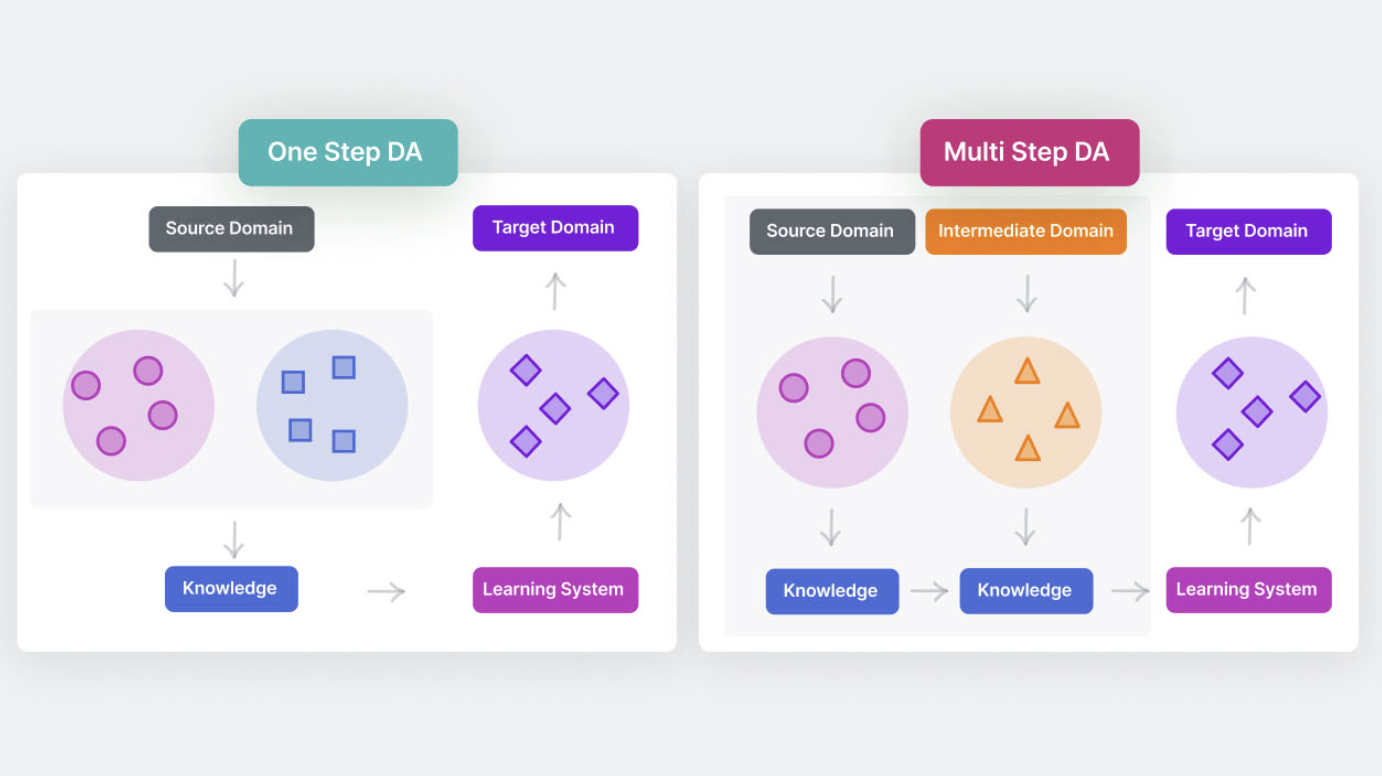
- One-Step DA
One-Step 도메인 적응은 소스 도메인과 타겟 도메인이 직접적으로 연결된 경우에 해당한다. 이 경우 지식 전이는 한 단계로 이루어진다. 두 도메인이 충분히 유사하여 한 번의 적응으로도 효과적인 지식 전이가 가능한 상황에서 사용된다.
- Multi-Step DA
그러나 현실에서는 소스 도메인과 타겟 도메인의 겹침이 거의 없어 One-Step DA가 효과적이지 않을 수 있다. 다행히, 소스와 타겟 도메인을 원래 거리보다 가깝게 할 수 있는 중간 도메인이 존재하는 경우가 있다. 따라서 일련의 중간 다리를 사용하여 관련이 없어 보이는 두 도메인을 연결한 다음, 이 브릿지를 이용해 One-Step DA를 수행하는 방법을 Multi-Step DA라고 한다.
예를 들어, 얼굴 이미지와 차량 이미지는 모양이나 기타 측면에서 매우 달라 One-Step DA는 실패할 수 있으나, 럭비 헬멧과 같은 중간 이미지를 도입하여 중간 도메인으로 사용하면 원활한 지식 전이가 가능할 수 있다.
Four algorithmic Domain Adaptation principles
- Reweighting Algorithms / Instance-based Adaptation
Reweighting 알고리즘은 소스 데이터의 분포 차이를 최소화하기 위해 소스 데이터를 reweight한 다음, reweight된 소스 데이터로 분류기를 훈련한다. 이는 소스 도메인에만 속하는 데이터의 중요성을 감소시킨다. 타겟 도메인 데이터와 재가중치된 소스 도메인 데이터는 분포를 정렬하기 위해 적대적 훈련이나 커널 평균 매칭을 통해 특징 추출기를 훈련하는 데 사용된다. 이런 방법을 Instance-based Adaptation이라고도 한다.
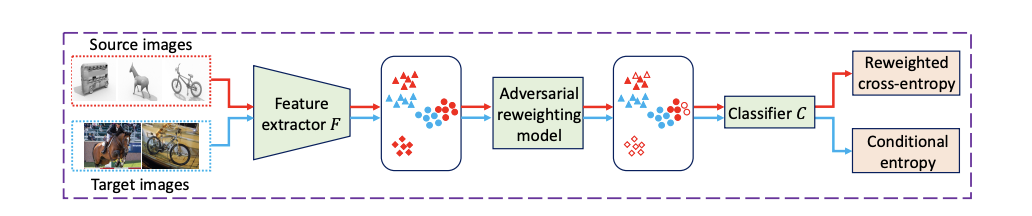
Adversarial Reweighting for Partial Domain Adaptation에서는 소스 도메인 데이터를 적대적으로 재가중치하여 소스 도메인과 타겟 도메인의 분포를 맞추는 적대적 가중치(Adversarial Reweighting, AR) 접근 방식을 제안한다. 이 접근 방식은 소스 도메인 데이터의 가중치를 학습하여 재가중치된 소스 도메인과 타겟 도메인 분포 간의 Wasserstein 거리를 최소화한다.
- Iterative Algorithms
반복적 적응은 이름에서 알 수 있듯 타겟 도메인 데이터를 반복적으로 '자동 라벨링'하는 것을 목표로 한다. 그러나 이러한 방법은 일반적으로 라벨링된 타겟 샘플을 필요로 하므로, 지도 학습 및 반지도 도메인 적응 설정에 적합하다. 여기서 딥러닝 모델은 소스 도메인의 라벨링된 데이터로 훈련되고, 레이블이 없는 타겟 샘플을 주석 처리한다. 그런 다음, 새로운 타겟 도메인의 라벨링된 샘플로 새로운 모델을 학습한다.
Co-Training for Domain Adaptation에서는 소스 도메인에서 타겟 도메인으로 훈련 세트를 천천히 적응시키는 알고리즘을 제시한다. 먼저, 라운드별로 자신들의 출력을 훈련시키고, 각 라운드마다 가장 신뢰할 수 있는 타겟 인스턴스를 훈련 데이터에 포함시킨다. 그 후, 훈련 세트와 레이블이없는 세트를 통해 측정된 호환성에 기반하여 소스와 타겟 데이터의 공통 피처를 선택한다. 더 많은 타겟 인스턴스가 훈련 세트에 추가됨에 따라, 타겟 특유의 특징이 두 세트 간에 호환 가능하게 되어 예측기에 포함된다.
-
Feature-based Adaptation
특징 기반 적응 기술은 도메인 간에 불변 특징을 추출하는 변환을 학습하여 소스 데이터를 타겟 데이터로 매핑하는 것을 목표로 한다. 이러한 기술은 일반적으로 원본 특징을 새로운 특징 공간으로 변환한 다음, 최적화 절차에서 도메인 간의 격차를 최소화하면서 원본 데이터의 기본 구조를 유지한다. 특징 기반 적응 방법은 다음과 같이 더 세분화될 수 있다.
-
Subspace-based Adaptation : 도메인 간에 공유되는 공통적인 중간 표현을 발견하는 것을 목표로 한다.
-
Transformation-based Adaptation : 특성 변환은 원본 특징을 새로운 특징 표현으로 변환하여, 원본 데이터의 기본 구조와 특성을 유지하면서 주변 분포(marginal distributions)와 조건부 분포(conditional distribution) 간의 불일치를 최소화한다.
-
Reconstruction-based Adaptation : 재구성 기반 방법은 중간 특징 표현에서 샘플 재구성을 사용하여 도메인 분포 간의 차이를 줄이는 것을 목표로 한다.
- Hierarchical Bayesian Model
계층적 베이지안 모델은 계층적 베이지안 사전(hierarchical Bayesian prior)을 사용하여 도메인 별 매개변수를 연결한다. 이러한 모델은 도메인에 따라 달라지는 잠재 표현(domain-dependent latent representations)을 도출하여 도메인 별 특성과 전역적으로 공유되는 잠재 요소를 모두 포함할 수 있게 한다.
계층적 베이지안 사전은 도메인 간의 특징이 유사한 가중치를 갖도록 하며, 반대 증거가 없는 한 이러한 유사성을 유지한다. 계층적 베이지안 프레임워크는 각 작업/분포의 매개변수를 독립적으로 학습하고 정보가 많은 작업의 매개변수를 더 거친 작업으로 매끄럽게 하는 접근방식에 비해 전이학습을 위한 더 원칙적인 접근 방법을 제공한다.
Domain Adaptation Techniques
- Domain Invariant Feature Learning
최신 도메인 적응 방법들은 일반적으로 특칭 추출기 신경망(feature extractor neural network)의 형태로 도메인 불변 특징 표현(feature representation)을 생성하여 소스 도메인과 타겟 도메인을 정렬한다. 특징 표현이 도메인 불변이라는 것은 입력 데이터가 소스 도메인에서 왔는지 타겟 도메인에서 왔는지에 관계없이 특징이 동일한 분포를 따른다는 것이다. 만약 도메인 불변 특징을 사용하여 소스 데이터에서 좋은 성능을 내는 분류기를 훈련할 수 있다면, 타겟 데이터의 특징이 분류기를 훈련한 특징과 일치하기 때문에 타겟 도메인에서도 잘 일반화될 수 있다.
이러한 방법들의 일반적인 훈련 및 테스트 설정은 아래와 같이 설명된다. 앞으로 나오는 방법들은 도메인을 정렬하는 방식이 다르다. 일부는 발산을 최소화하고, 일부는 재구성을 수행하고, 일부는 적대적 훈련을 사용한다. 또한 가중치 공유 선택이 다른데, 자세한 내용은 아래에서 설명한다.
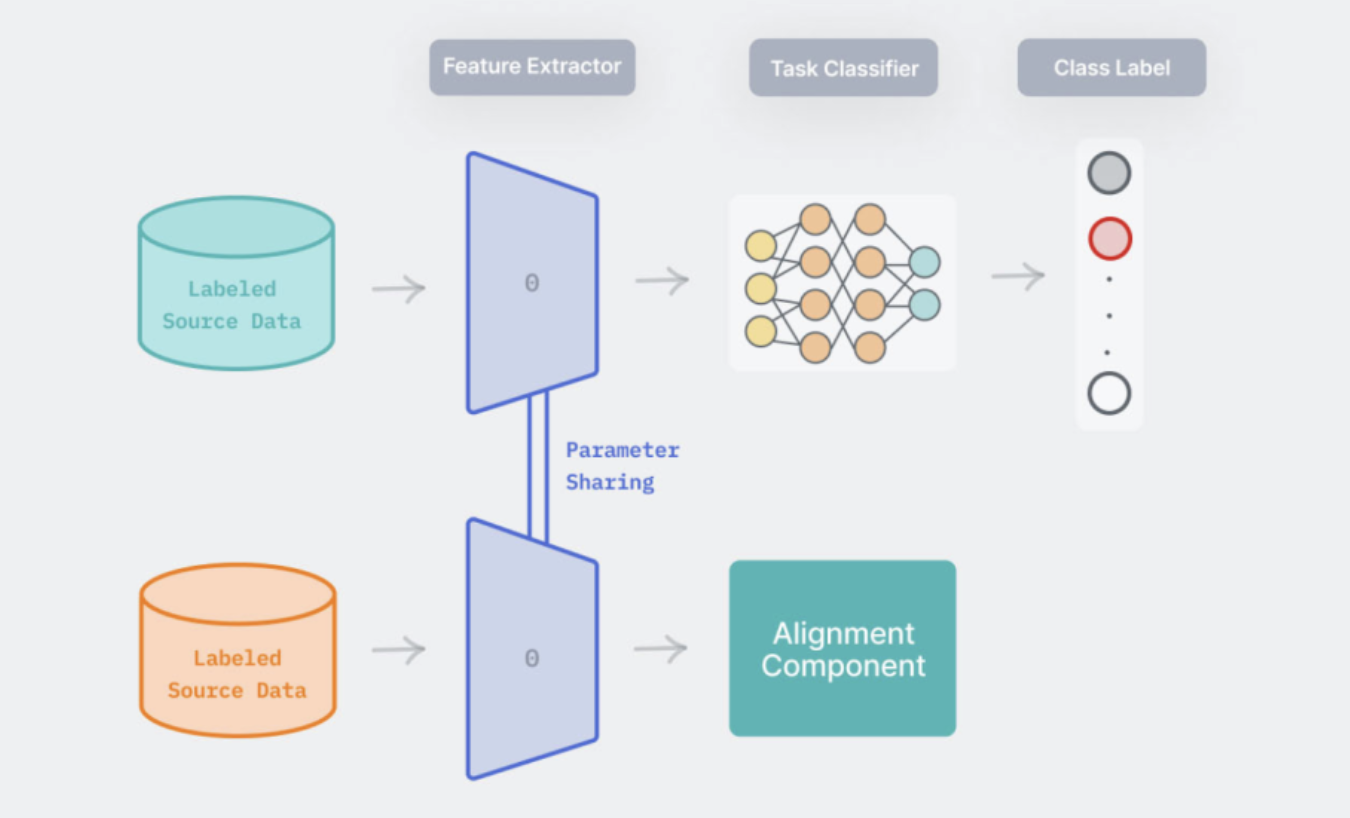
-
Divergence-based Domain Adaptation
- 발산 기반 도메인 적응 기술은 소스 도메인과 타겟 도메인 데이터 분포 간의 발산 기준을 최소화하는 것을 목표로 한다. 다양한 도메인 적응 접근 방식에서 사용되는 네가지 선택지는 최대 평균 차이(maximum mean discrepancy), 상관 정렬(correlation alignment), 대조 도메인 불일치(contrastive domain discrepancy), 그리고 Wasserstein metric이다.
- Aligning Infinite-Dimensional Covariance Matrices in Reproducing Kernel Hilbert Spaces for Domain Adaptation에서 제안된 프레임워크는 무한 차원의 공분산 행렬을 도메인 간에 정렬함으로써 도메인 적응을 수행한다. 구체적으로, 원본 특징을 재생 힐버트 커널 공간(Reproducing Kernel Hilbert Splace, RKHS)으로 매핑한 다음, 결과 공간에서 선형 연산자를 사용하여 변환된 데이터와 타겟 데이터의 RKHS 공분산 설명자가 가까워지도록 소스 데이터를 타겟 도메인으로 "이동"한다. 변환된 샘플과 타겟 샘플로 쌍별 내적을 계산하여 닫힌 형태의 새로운 도메인 불변 커널 행렬을 얻는다. 이 커널 행렬은 어떤 커널 기반 학습 머신에서도 사용할 수 있다.
-
Reconstruction-based Domain Adaptation
- 레이블이 지정된 소스 도메인 데이터를 잘 분류하고 타겟 도메인 데이터 또는 소스와 타겟 도메인 데이터 모두를 재구성할 수 있는 표현을 학습함으로써 도메인 적응을 달성할 수 있다. 이러한 설정에서 정렬 구성 요소는 재구성 네트워크다. 이는 피처 추출기 출력을 가져와 피처 추출기의 입력을 재생성한다.
- Deep Reconstruction-Classification Networks for Unsupervised Domain Adaptation에서는 두 가지 작업을 공동으로 학습하는 DRCN(Deep Reconstruction Classification Networks)을 제안한다 : (i) 지도 소스 레이블 예측 및 (ii) 지도되지 않은 타겟 데이터 재구성. 목표는 학습된 레이블 예측 함수가 타겟 도메인의 이미지 분류에서 좋은 성능을 낼 수 있도록 하는 것이다. 데이터 재구성은 레이블 예측의 적응을 지원하는 보조 작업으로 볼 수 있다. DRCN의 네트워크 학습 매커니즘은 비지도 학습과 지도 학습을 번갈아 가며 진행하는데, 이는 표준 사전 학습-미세 조정 전략과 다르다.
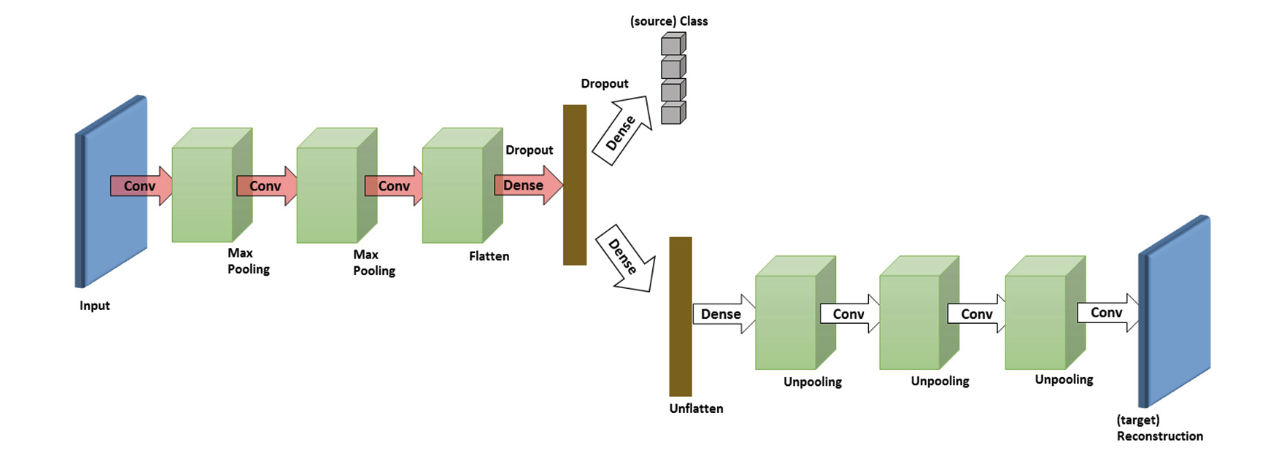
-
Adversarial-based Domain Adaptation
-
적대적 적응 방법은 도메인 판별자(domain discriminator)와 관련된 적대적 목적을 통해 도메인 불일치 거리를 최소화하려는 접근 방식으로 점점 인기를 얻고 있다. 이러한 방법은 생성적 적대 학습(GAN)과 밀접한 관련이 있으며 여기서는 생성자와 판별자 두 네트워크가 서로 경쟁한다. 적대적 도메인 적응 접근 방식은 도메인 간의 분포 불일치를 최소화하여 전이 가능하고 도메인 불변 특징을 얻는 데 중점을 둔다.
-
컴퓨터 비전 문헌에는 여러가지 유형의 피처에 대한 적대적 도메인 적응 방법이 소개되었다. 대부분의 경우 정렬 구성 요소는 도메인 분류기(domain classifier)로 구성된다. 도메인 분류기는 특징 표현이 소스 데이터에서 생성된 것인지, 타겟 데이터에서 생성된 것인지를 출력하는 분류기이다. 예를 들어, 이 정렬 구성 요소는 대략적인 Wasserstein 거리를 학습하는 네트워크로 표현될 수도 있고, GAN 모델일 수도 있다.
-
CyCADA: Cycle-Consistent Adversarial Domain Adaptation에서는 의미적 일관성을 강화하는 동시에 픽셀 수준과 피처 수준에서 표현을 적응시키는 CyCADA 모델을 제안했다. 사이클 일관성 손실(소스가 타겟으로 매핑되고 다시 소스로 매핑될 때 일치해야 함)과 특정 시각 인식 작업에 기반한 의미적 손실을 사용하여 구조적 일관성과 의미적 일관성을 모두 강화한다. 의미적 손실은 전체 표현이 차별적이게 되도록 안내하고 도메인 간 매핑 전후에 의미적 일관성을 강화한다.
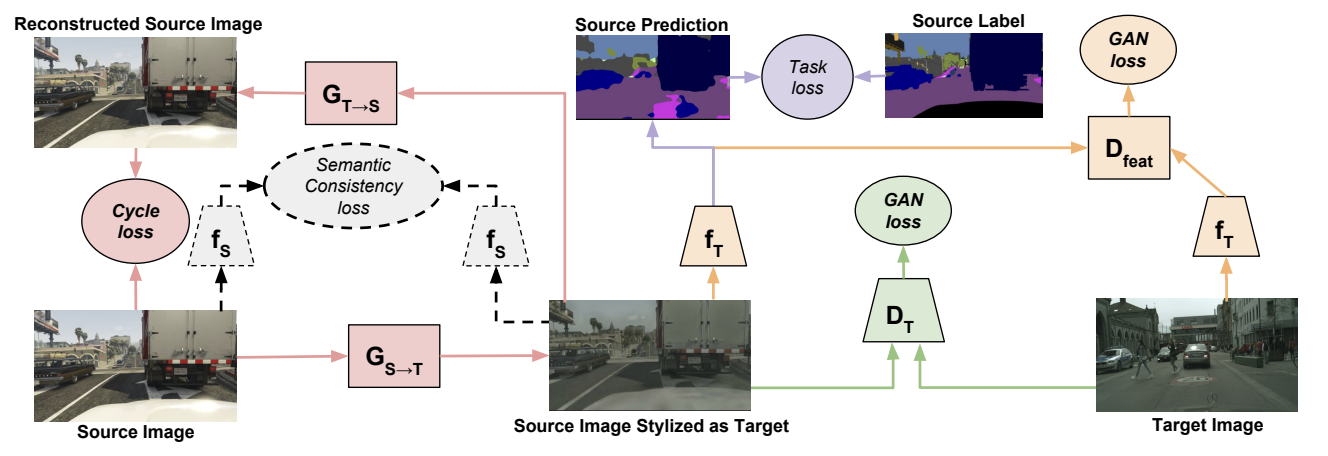
-
-
Domain Mapping
도메인 매핑은 도메인 불변 특징을 표현하는 또 다른 방법이다. 이 매핑은 일반적으로 적대적으로 생성되며 픽셀 수준에서 이루어진다.(즉, 픽셀 수준의 적대적 도메인 적응). 이 매핑은 조건부 GAN으로 수행할 수 있다. 생성기는 소스 입력 이미지를 타겟 분포와 매우 유사한 이미지로 변환하여 픽셀 수준에서 적응을 수행한다. 예를 들어, GAN은 합성 차량 운전 이미지를 현실적으로 보이는 이미지로 변환할 수 있다.

StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation 논문에서는 여러 도메인 간의 매핑을 학습할 수 있는 생성적 적대 신경망인 StarGAN 모델을 제안했다. 기존의 다중 도메인 변환 접근 방식은 도메인 간 변환을 위해 여러 개의 독립된 생성자 및 판별자 네트워크를 사용하는 것과 달리, StarGAN 모델은 여러 도메인의 학습 데이터를 가져와 단 하나의 생성기를 사용하여 사용 가능한 모든 도메인 간의 매핑을 학습한다.
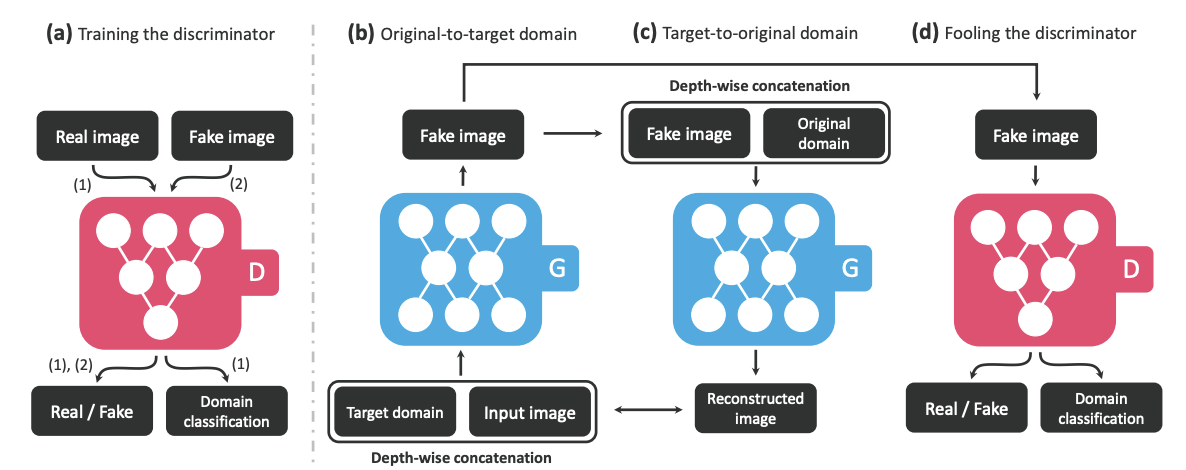
고정된 변환을 학습하는 대신, 이미지와 도메인 정보를 모두 입력으로 받아 입력 이미지를 해당 도메인으로 유연하게 변환하는 방법을 학습한다. StarGAN은 레이블(예를 들면 이진 또는 원-핫 인코딩 벡터)을 사용한다. 훈련 중에는 타겟 도메인 레이블이 무작위로 생성되고, 모델은 입력 이미지를 타겟 도메인으로 유연하게 변환하도록 학습되며, 이를 통해 도메인 레이블을 제어하고 테스트 단계에서 이미지를 원하는 도메인으로 변환할 수 있다.
- Ensemble Methods
기본 모델로서 딥 뉴럴 네트워크와 같은 모델이 사용될 경우, 여러 모델로 구성된 앙상블이 모델의 출력을 평균화하거나(ex. 회귀) 투표(ex. 분류)를 통해 단일 모델보다 좋은 성능을 보일 수 있다. 모델들이 다양하면 각 개별 모델이 서로 다른 실수를 할 가능성이 높기 때문이다. 그러나 이러한 성능 향상은 각 앙상블 예측에 대해 평가할 모델 수가 많아 계산 비용을 증가시킬 수 있다.
여러 개의 기본 모델을 앙상블로 사용하는 대안으로 단일 모델만을 사용하되, 훈련 중 여러 시점에서 앙상블 내의 모델을 평가하는 방법이 있다. 이를 셀프 앙상블링(self-ensembling)이라고 한다. 이 방법은 각 예제에 대한 과거 예측을 평균화(이전 예측 기록)하거나 과거 네트워크 가중치를 평균화(이동 평균 유지)하여 수행할 수 있다. 이는 계산 과정을 몇 배로 줄일 수 있다.
Self-ensembling for visual domain adaptation에서는 그러한 방법 중 하나를 제안했는데, 비지도 도메인 적응을 위해 셀프 앙상블을 사용한다. 학생 네트워크와 교사 네트워크라는 두 개의 네트워크를 사용하는데, 입력 이미지는 두 네트워크에 입력되기 전에 먼저 확률적 데이터 증강(Gaussian noise, translations, horizontal flips, affine transforms 등)을 거친다. 이 방법은 확률적이기 때문에, 네트워크에 공급되는 증강된 이미지가 다르다. 학생 네트워크는 경사 하강법으로 훈련되며, 교사 네트워크의 가중치는 학생 네트워크 가중치의 지수 이동 평균(EMA)이다.
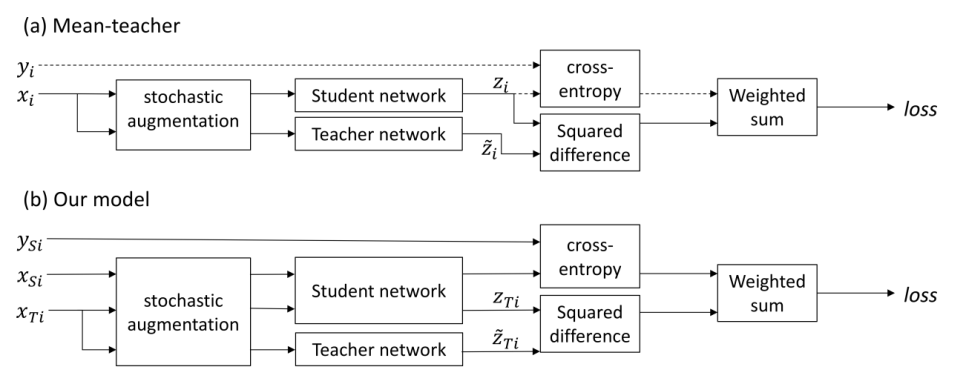
- Target Discriminative Methods
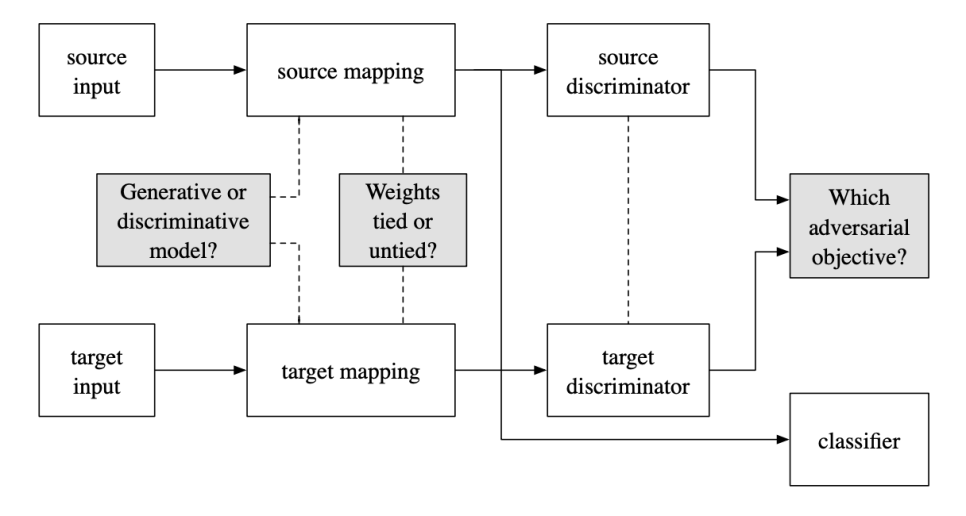
반지도 학습 알고리즘에서 성공을 이끈 한 가지 가정은 클러스터 가정(cluster assumption)이다. 이는 데이터 포인트가 별도의 클러스터에 분포되어 있으며 각 클러스터의 샘플에 공통 레이블이 있다는 것이다. 이러한 경우, 결정 결계는 저밀도 영역에 위치해야 한다.(즉, 데이터 포인트가 많은 영역을 통과해서는 안된다)
다양한 도메인 적응 방법이 결정 경계를 밀도가 낮은 밀도 영역으로 옮기기 위해 탐구되었고, 일반적으로 적대적으로 훈련된다. Adversarial Discriminative Domain Adaptation에서는 제목과 같은 ADDA라고 하는 비지도 DA 방법을 제안한다. 먼저 소스 도메인의 레이블을 사용하여 판별적 표현을 학습하고, 도메인-적대적 손실(domain-adversarial loss)을 통해 학습한 비대칭 매핑을 사용하여 타겟 데이터를 동일한 공간에 매핑하는 별도의 인코딩을 학습한다.