PatchCore는 주로 산업 제조 분야에서 비정상 탐지(anomaly detection)를 위해 사용되는 딥러닝 기반 방법론이다.
Towards Total Recall in Industrial Anomaly Detection
https://arxiv.org/pdf/2106.08265v2
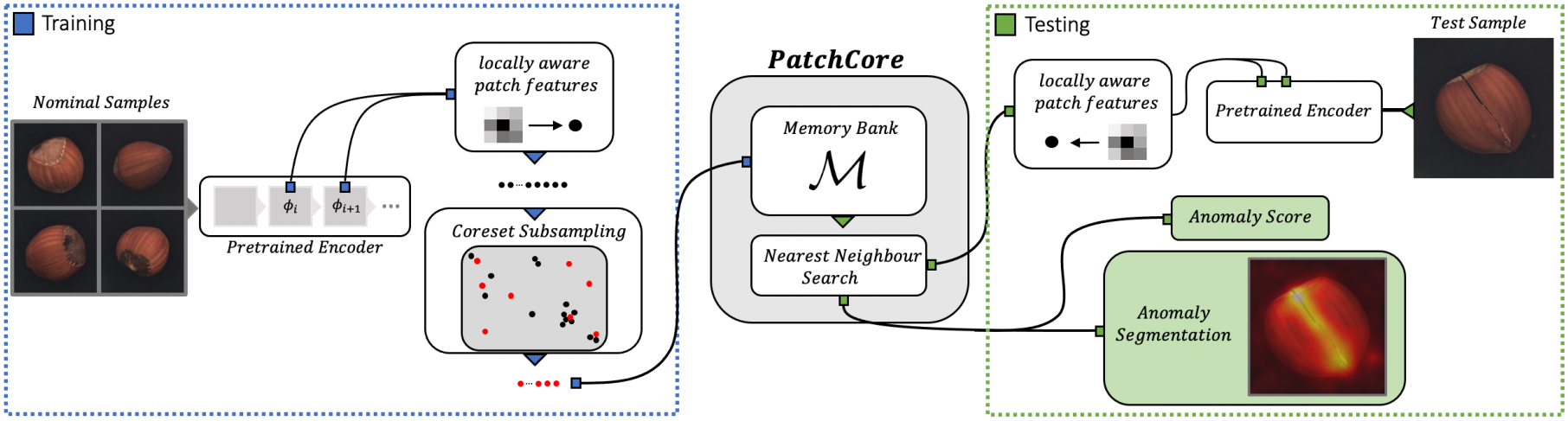
왼쪽은 training 과정, 오른쪽은 testing 과정이다.
PatchCore가 강조하는 점
- 산업용 Anomaly Detection
- Total Recall
결함이 없는 이미지로만 모델을 학습시키는 콜드 스타트 문제를 다룬다.
PaDiM과 SPADE의 단점을 보완하고 이 둘의 장점을 취한 모델이다.
PatchCore의 목표
- Pretrained network 사용, 추출한 feature의 정보력 향상
- ImageNet으로 학습한 모델의 bias 감소
- inference 속도 향상
PatchCore의 한계점
산업 분야 특화 이상 탐지 모델이기 때문에 다른 분야에서 사용하려면 Adaptation이 필요하다.
PatchCore의 원리
초기 단계에서 입력 이미지 또는 데이터에서 패치를 나누어 특징을 추출함. 일반적으로 사전 학습된 컨볼루션 신경망(CNN) 사용.
Local Patch Features :
Mid-Level features를 Local Patch Features로 사용함.
→ 네트워크의 마지막 레이어 대신 중간 레벨의 특징 표현을 사용하여 ImageNet 클래스에 대한 편향을 피함.
- High-Level Features는 공간적 정보의 손실이 큼
- Image Classification Task에 대한 Bias가 많이 존재함
각 Patch에는 Adaptive Average Pooling을 적용해 주변 정보를 포함시킴. 이 과정에서 얻어진 Patch Features를 scoring에 사용함.
Coreset Subsampling :
Patch Feature 중, 핵심(Coreset)만 추출해 분석에 사용함.
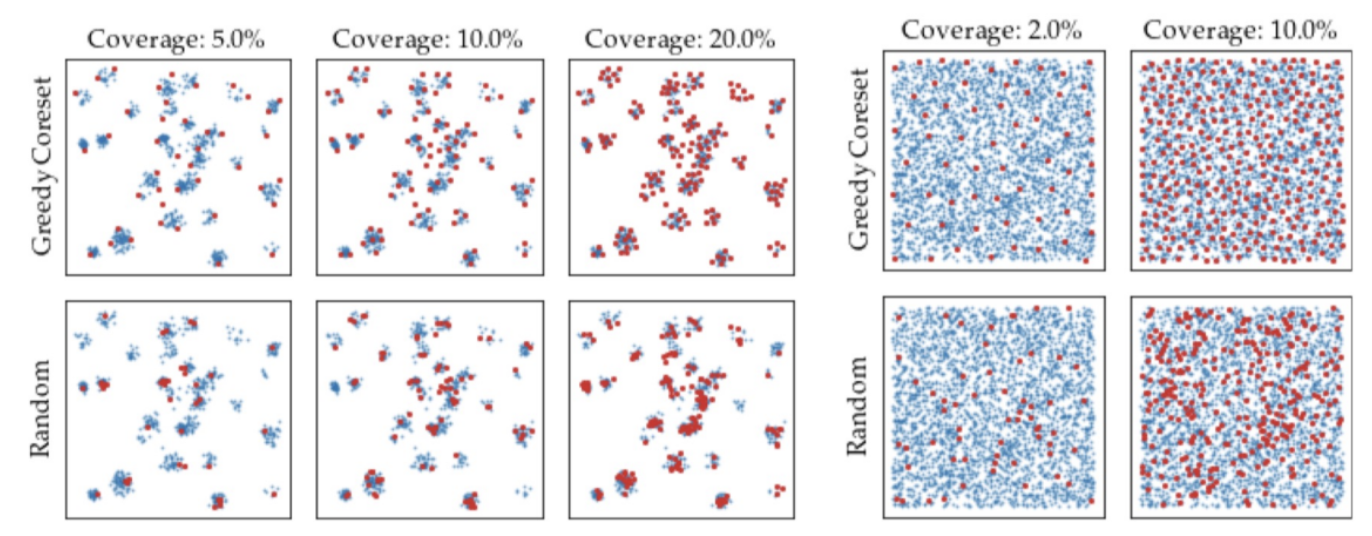
특정 Patch Features가 Coreset임을 판단하는 기준으로 Greedy Search 알고리즘 사용. (Random Subsampling에 비해 정상 features가 고르게 선택됨)
Detection and Localization :
추출된 Coreset Patch의 features를 기준으로 이미지의 Anomaly Scoring하는 단계.
- 테스트 이미지에 Local Patch Features를 추출해 각 Patch Features를 Coreset Features와 비교. 비교 방법은 거리 계산으로.(유클리디안 거리)
- K-NN을 수행해 가장 가까운 거리를 Anomaly Score로 간주함.
새로운 데이터가 들어오면, 해당 데이터의 패치 특징을 정상 패치들의 대표적인 특징 벡터들을 저장한 데이터베이스와 비교하여 유사도를 계산함.
전체 이미지 또는 데이터의 비정상 점수를 계산하여 점수가 높을수록 해당 데이터가 비정상일 가능성이 높은 것.
