[23.06] OWQ: Outlier-Aware Weight Q for Efficient Fine-Tuning and Inference of LLM
LLM-W-only-Q

Problem Definition and Motivation
Background and Related Works
Quantizatoin and LLMs
QAT는 Q error를 최소화 하기 위해서 extremely low-bit precision에서 선호돼왔다.
하지만, LLM Q는 training cost가 높아 PTQ를 중심으로 연구되고 있다.
두 가지 접근이 주를 이룬다.
[1] activation과 weight를 INT8로 Q
LLM.int8(), Dettmers(2022)
SmoothQuant, Xiao(2022)
[2] weight quantization을 4 bit 이하로 Q.
Optimal Brain Compression, Frantar(2023)
OWQ는 2번째 접근을 취한다.
INT8 Q for Act and W
LLM.int8()과 SmoothQuant는 LLM의 activation을 Q함에 있어 unique한 challenge를 보였다.
바로, LLM은 intermediate activations에서 few outlier가 존재한다는 점이다.
이 outlier들의 값은 상대적으로 매우 크며, 특정 feature dimensions에 집중되어 있다.
이 outlier들의 값을 보존하는 것이 act Q 이후의 accuracy를 유지하는데 crucial하다.
OWQ는 weight Q만 적용하지만, activation outlier를 고려하는 것이 정확한 weight Q를 위해 필요함을 증명했다.
OPTQ: Weight Q for LLMs
OPTQ는 LLM weight Q 연구의 SOTA이다.
Optimal Brain Compression(OBC)을 기반으로, layer-wise Q error의 Hessian 기반 metric을 사용해, element-wise Q와 compensation을 한다.
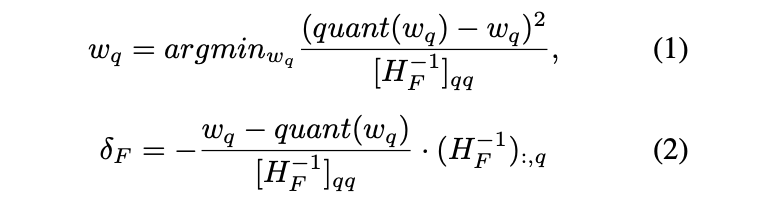
이 접근 방식은 이전 연구들이 STE 또는 rounding-to-nearest mechanism을 기반으로 gradient descent를 통해 Q하는 방식과는 다르다.
OPTQ는 OBC를 optimize했는데, output channel dimension의 각 element Q를 parallelize하여 rapid Q를 가능케 했다.
LLM의 4-bit 이하 Q 가능성을 보였지만, model size를 줄이거나 문제의 복잡도를 증가시켜 FP16 Baseline에 비해 accuracy가 감소했다.
OWQ 연구에선, 다음을 제안한다.
1. activation outlier들에 의해 Q에 vulnerable한 weight들에 high-precision을 선택적으로 적용
2. 나머지 weight들에 대해선 추가적으로 error를 줄이기 위한 Q configuration tuning 기반의 modified OPTQ를 적용
Parameter-Efficient Fine-Tuning(PEFT)
LLM을 특정 작업에 맞게 Fine-Tuning하면 성능을 향상시킬 수 있지만, paramter 수가 많아 매우 높은 비용이 발생한다. 이 문제를 해결하기 위해 PEFT 기법이 도입됐다.
LoRA(2022)는 pre-trained weights를 freeze하고, low-rank decomposition을 통해 학습 가능한 parameter를 소량만 추가해 업데이트 하기 때문에, 매우 적은 memory만을 사용한다.
QLoRA(2023)는 dense weights를 quantize하여, memory 사용량을 더 줄임으로써 fine-tuning 과정을 더 가볍게 만들었다.
fine-tuning이 Q error를 줄일 수 있기 때문에, LLM의 practical하고 task-specific한 deployment의 optimization 방법으로 널리 사용되고 있다.
본 연구에서는 OWQ와 호환되는 PEFT 기법을 소개한다. OWQ의 우수한 representation quality는 QLoRA보다 적은 resource로도 PEFT 후 뛰어난 성능을 발휘한다.
