🚀 Motivations
-
Given the strong belief that object recognition by humans is part-based,
the simplest explanation for a collection of shapes
belonging to the same categroy would be a
combination of universal parts for that category, (e.g., chair backs or airplane wings.) -
✅ Hence, an unsupervised shape co-segmentation would amount to
finding the simplest part representations for a shape collection.
✅ Paper's choice for the representation learning module is a variant of autoencoder -
In principle, autoencoders learn "compact representations" of a set of data
via dimentionality reduction
while minimizing a "self reconstruction loss" -
✅ To learn shape parts,
paper introduce a branched version of autoencoders,
where each branch is tasked to learn a simple representation
for universal part of the input shape coolection. -
✅ Paper's branched autoencoder, BAE-NET for short,
is trained to minimize a shape reconstruction loss,
where shapes are represented using implicit fields.
🔑 Key Contributions
- This paper treat shape co-segmentation
as a representation learning problem
and introduce BAE-NET
⭐ Methods
Abstract
-
BAE-NET is trained with a "collection of un-segmented shapes",
using a shape reconstruction loss, without any GT labels. -
Input: shape (represented using implicit fields)
-
Encoder: produce the feature code for the given shape( encodes shape using a CNN)
-
Decoder: 3-layer fully connected NN
Decoder's input: joint vector of point coordinates and an feature code of the input shape
point coordinate adds spatial awareness to reconstruction process, often lost in the convolutional features from the CNN encoder)
Decoder's output: value in each output branch that indicates
whether the input point is inside a part(1) or not(0). -
Max pooling opeartor: mere parts together and obtain the entire shape.
-
Decoder is branched: each branch learns a "compact representation"
for one commomly recurring part of the shape collection (e.g., airplane wings) -
By complementing the shape reconsturction loss with a label loss,
BAE-NET is easily tuned for one-shot learning.
Architecture
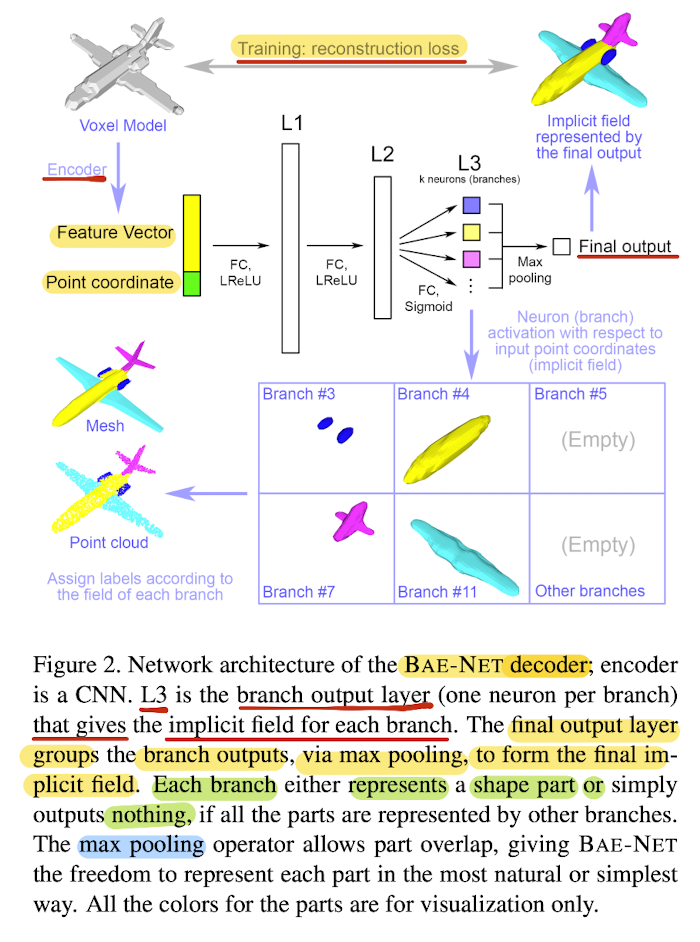
- Each neuron in the L3 is trained to learn the "inside/outside" status of the point
relative to one shape part.
The parts are learned in a joint space of shape features and point locations.
Network losses for various learning scenarios
Unsupervised
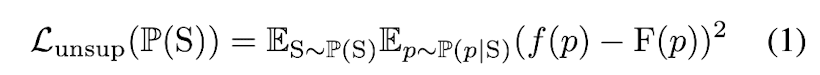
P(S): distribution of training shapes,
P(p|S): distribution of sampled points given shape S,
f(p): output value of decoder for input point p
F(p): GT inside-outside status for point p.
- This loss function allows to reconstruct the target shape
in the output layer. - Segmented parts will be expressed in the branches of L3,
since the final output is taken as
the maximum value over the fields
represented by those branches.
Supervised
- If examples with GT part labels exist,
we can also traing BAE-NET in a supervised way.
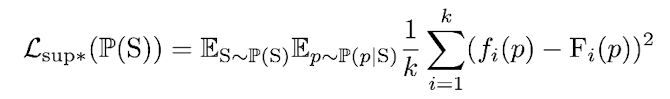
Fm(P): GT status for point p
fm(P): output value of the m-th branch in L3
k: # of branches in L3
-
In the datset such as the ShapeNet part dataset,
shapes are represented by point clouds
sample from their surfaces. -
In such datasets, the inside-outside status of a point can be ambiguous.
However, since paper's sampled points are from voxel grids
and the reconstructed shapes are thicker than the original,
we can assume all points in the ShapeNet part dataset
are inside our reconstructed shapes. -
Paper uses both paper's sampled points from voxel grids
and the point clouds in the ShapeNet part dataset,
by modifying the loss function:
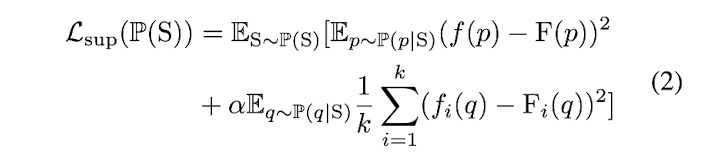
P(p|S): distribution of paper's sampled points from voxel grids,
P(q|S): distribution of points in the ShapeNet part data set.
(Paper set α to 1 in experiments)
One-shot learning
-
Paper's network also supports "one-shot training",
where feed the network 1, 2, or 3, ... , shapes
with GT part labels,
and other shapes without part labels. -
To enable one-shot training, joint loss is defined as:
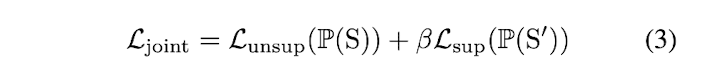
P(S): distribution of all shapes,
P(S'): distribution of the few given shapes with part labels. -
Additionally, paper add a very small L1 regularization term
for the parameters of L3 to prevent unnecessary overlap,
e.g., when the part output by one branch contains
the part output by another branch.
Point label assignment
-
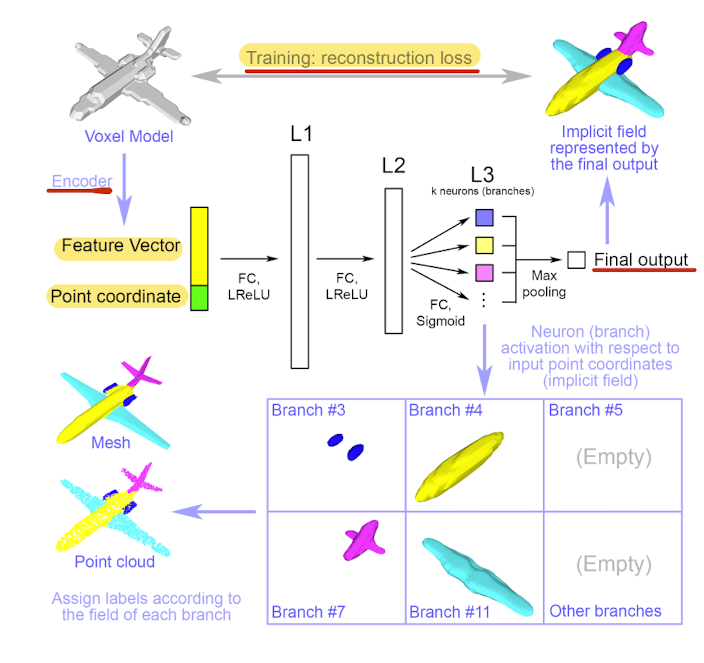
After training, we get an approximate implicit field for the input shape.
-
To label a given point of an input shape,
simply feed the point into the network together
with the code encoding the feature of the input shape,
and label the point by looking
at which branch in L3 gives the highest value. -
If the training has exemplar shapes as guidance,
each bracnch will be assigned a label automatically
w.r.t exemplars.-If training is unsupervised,
need to look at the branch outputs
and give a lable for each branch by hand.
For example in Fig2, we can label bracn #3 as "jet engine",
and each point having the highest value in this branch
will be labeled as "jet engine".
-
To label a mesh model,
subdivide the surfaces
to obtain fine-grained triangels,
and assigan a label fo each triangle. -
To label a triangle,
feed its three vertices into network
and sum their output values in each branch,
and assign the label
whose associated branch gives the highest value
👨🏻🔬 Experimental Results
Network design choices and insights
-
Train BAE-NET with 4 branches on the two datasets.
-
Successfully separated the shape patterns,
even when two patterns overlap. -
Each of the output branches
only outputs
one specific shape pattern,
thus we also obtain a shape correspondence from the co-seg process.
-
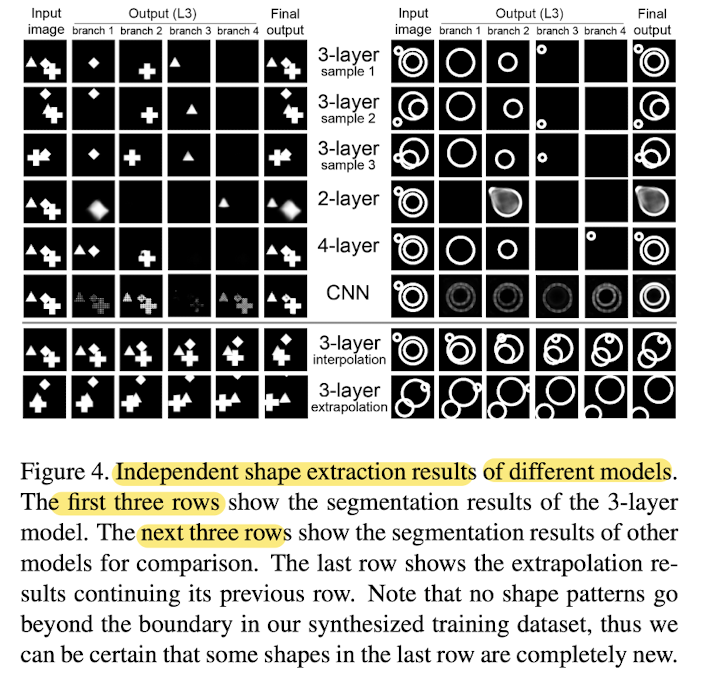
Compared the segmentation results of current 3-layer model with a 2-layer model, a 4-layer model, and a CNN model in Fig 4.
-
2-layer model: hard to reconstruct the rings,
since L2 is better at representing convex shapes -
4-layer model: can separate parts,
but since most shapes can already be represented in L3,
extra layer does not necessrily output separated parts. -
CNN model: not sensitive to parts
and outputs basically everything or nothing in each branch,
since there is no bias towards sparsity or segmentation. -
Overall, the 3-layer network is the best choice
for independent shape extraction,
making it a suitable candidate for unsupervised anand weakly supervised shape segmentation.
-
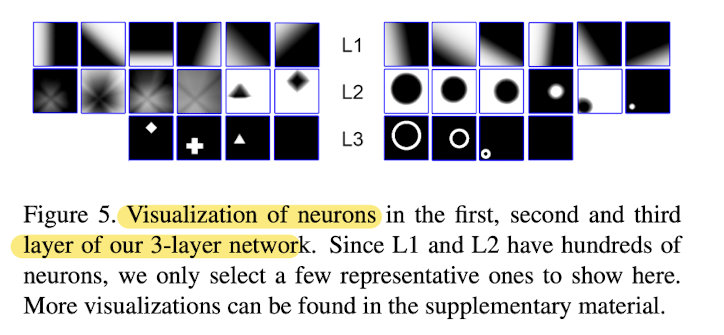
In L1: point coordinates and shape feature code
have gone through a "linear transform" and a "leaky ReLU activation",
therefore the activation maps in L1 are linear "space dividers" with gradients. -
In L2: each neuron linearly combines the fields in L1
to form basic shapes.
L2 represents higher level shapes than L1. -
L3 neurons combine the shapes in L2
to form output parts in network,
and final output combines all L3 outputs via max pooling.
Evaluation of unsupervised learning
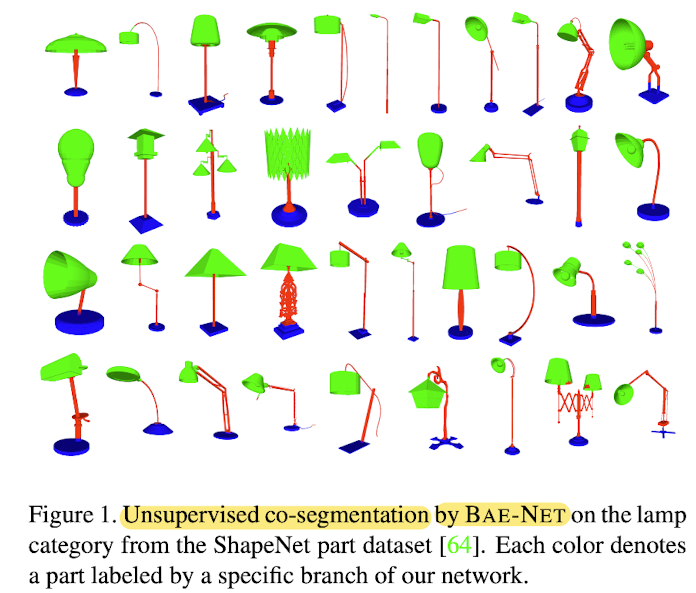
- Fig 1 and 6 show visual results.
- Reasonable parts are obtained,
and each branch only outputs a specific part
with a designated color,
giving natural part correspondence.

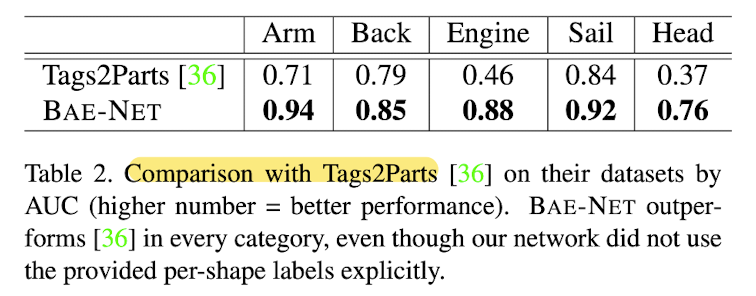
Comparison with SOTA network
- SOTA weakliy supervised part labeling network: Tags2Parts
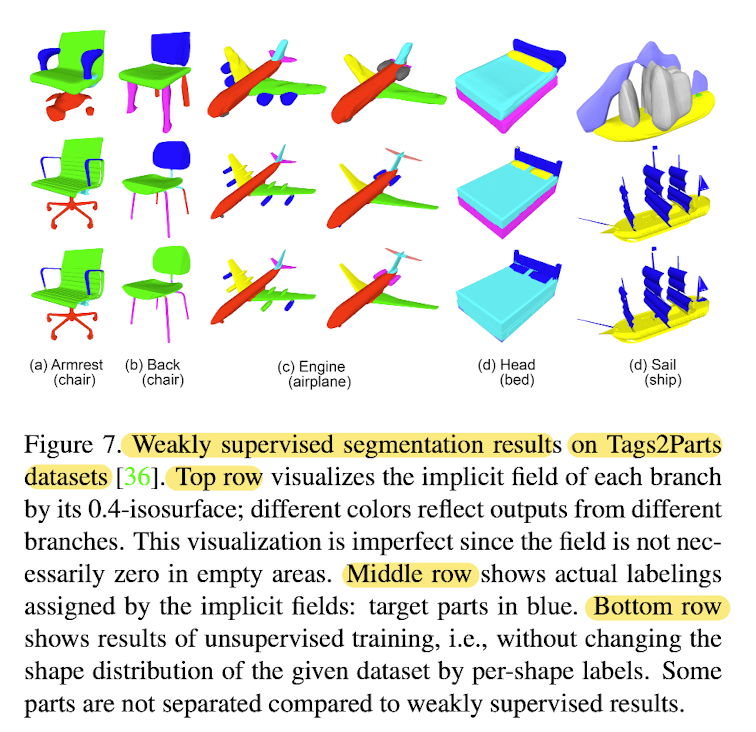
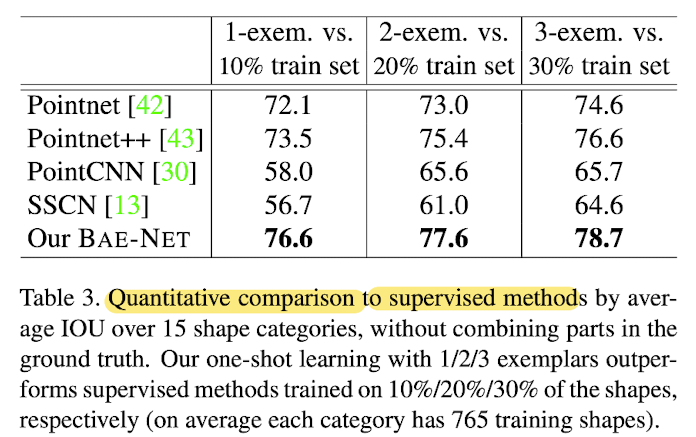
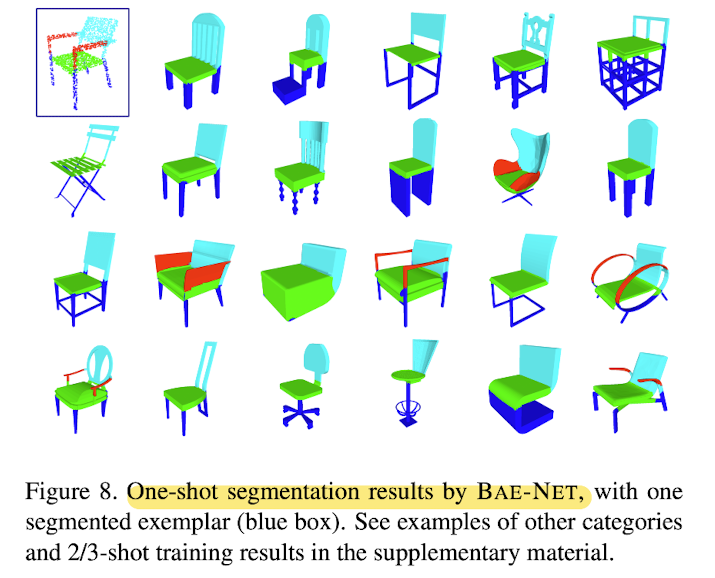
One-shot training vs supervised methods
🤔 Limitations
-
For unsupervised segmentation,
There is no easy way to predict
which branch will output which part,
since we initialize the network parameters randomly and
optimize a reconstruction
while treating each branch eqaully. -
Paper's network groups similar and close-by parts in different shapes for correspondence.
This is reasonable in most cases,
but for some categories e.ge., lamps or tables,
where the similar and close-by parts may be assigned different labels,
paper's netowrk can be confused. -
BAE-NET is much shallower and thinner compared to IM-NET,
since paper cares more about segmentation (not reconstruction) quality.
However, the limited depth and width of the network
make it difficult
to train on high-resolution models,
which hinders us from obtaining fine-grained segmentations.
