🚀 Motivations
-
The goal of 3D object detection is to localize and
recognize objects in a 3D scene.
➡️ This paper aims to estimate oriented 3D bounding boxes
as wll as semantic classes of objects from point clouds. -
To avoid processing irregular point clouds,
1️⃣ current 3D object detection methods
heavily rely on 2D-based detectors. -
For example,
1) extend 2D detection frameworks such as Faster/Mask R-CNN to 3D
(Voxelize the irregular point clouds to regular 3D grids
and apply 3D CNN detectors)
🔥 which fails to leverage sparsity in the data
and suffer from high computation cost due to expensive 3D convolutions.
2) project points to regular 2D bird's eye view images
and then apply 2D detectors to localize objects
🔥 which sacrifices geometric details
which may be critical in cluttered indoor environments.
3) two-step pieline by firstly detecting objects in front-view images
and then localizing objects in frustum point cloudss
extruded from the 2D boxes
🔥 which is strictly dependent on the 2D detector
and will miss an object entirely if it is not detected in 2D.
-
✅ This paper introduced a point cloud focused 3D detection framework
that directly processes raw data
and does not depend on any 2D detectors. -
Due to the sparsity of point clouds data
(samples from 2D manifolds in 3D space),
a major challenge exitst
when directly predicting bounding box parameters from scene points:
a 3D object centroid can be far from any surface point
thus hard to regress accurately in one step. -
✅ To address this challenge, VoteNet is based on
3D deep learning models for point clouds
and Hough voting process for object detection.
After passing input point cloud through a backbone network,
sample set of seed points
and generate votes from their features.
Votes are targeted to reach object centers.
As a result, vote clusters emerge near object centers
and in turn can be aggregated through a learn module to genrate box proposals.
🔑 Key Contributions
-
Reformulation of Hough voting
in the context of deep learning
through an end-to-end differentiable architecture, VoteNet -
SOTA 3D object detection performacne on SUN RGB-D and ScanNet
-
In-depth analysis of the importance of
voting for 3D object detection in point clouds.
✋🏻 Deep Hough Voting
-
Interest points
are describe and selected by DNN
instead of depending on hand-crafted features. -
Vote generation
is learned by a network
instead of using a code book(traditional Hough voting's).
Levaraging larger receptive fields,
voting can be made less ambiguous and thus more effective.
In addition, a vote location can be augmented
with a feature vector
allowing for better aggregation. -
Vote aggregation
is realized through point cloud processing layers
with trainable parameters.
Utilizing the vote features,
the network can potentially filter out low quality votes
and generate improved proposals. -
Object proposals
in the form of: location, dimensions, orientation and even semantic classes
can be directly generated from the aggregated features,
mitigating the need to trace back vote's origins.
⭐ Methods
VoteNet Architecture
-
Fig2. illustrates VoteNet.
-
Entire network can be split into two parts:
1) part that processes existing points to generate votes
2) part that operates on virtual points - the votes - to propose and classify objects.
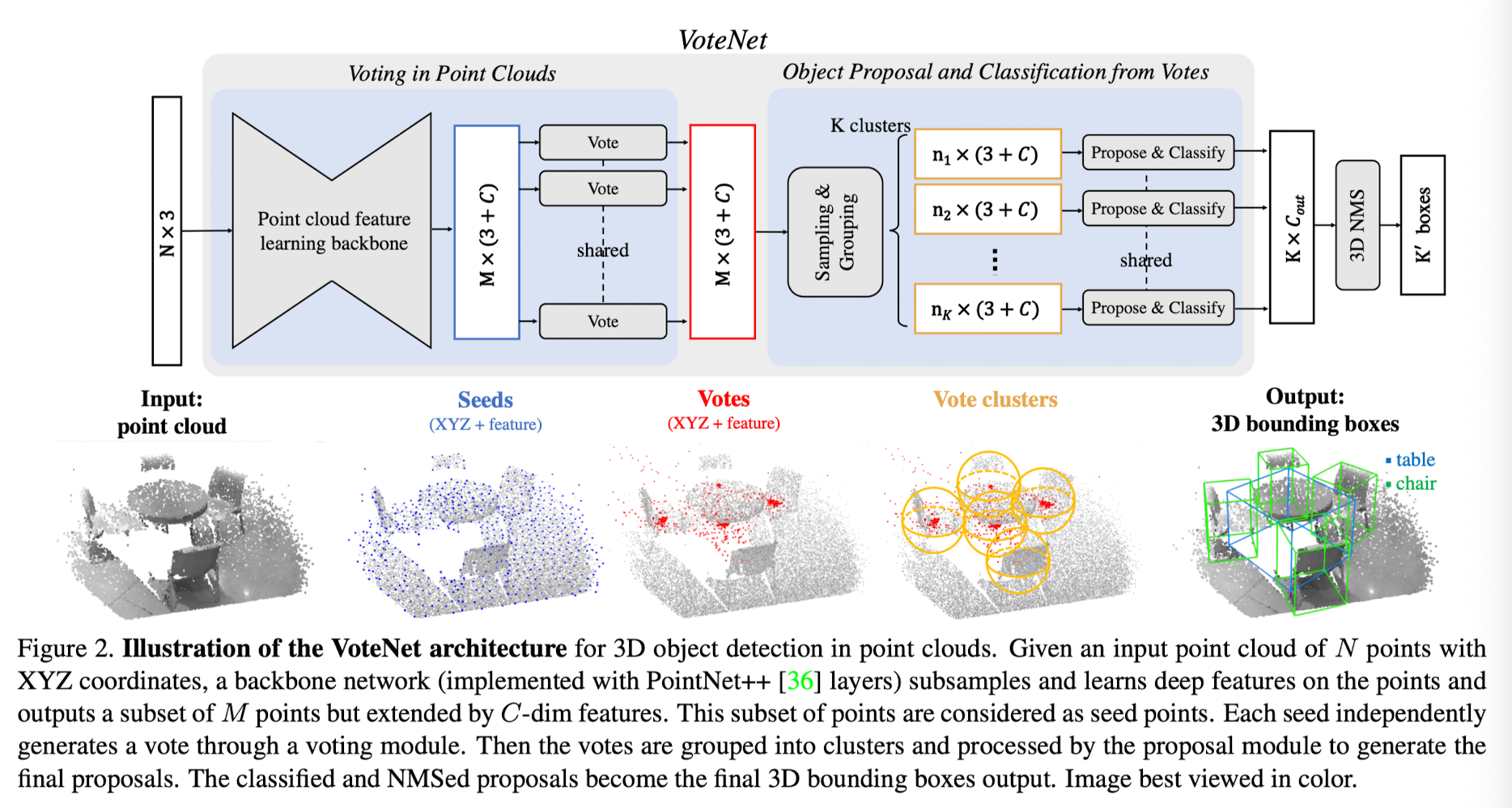
Learning to Vote in Point Clouds
-
From a input: point cloud of size N x 3, with a 3D coordinate for each of the N points,
paper aims to generate M votes,
where each vote has both a 3D coordinate and a high dimensional feature vector. -
Tow major steps:
-
1) point cloud feature learning through a backbone network
-
paper leverages recently proposed deep networks on point clodus
for point feature learning. -
papaer adopts PointNet++ as backbone network
-
The backbone network has several set-abstraction layers
and feature propagation (upsampling) layers with skip connections,
which outputs a subset of the input points with XYZ
and an enriched C-dimensional feature vector.
➡️ Output: M seed points of dimension (3 + C),
each seed point generates one vote.
-
2) learned Hough voting from seed points.
-
compared to traditional Hough voting
where the votes (offsets from local key points)
are determined by look ups in a pre-computed code-book, -
paper generated votes with a deep network based voting module,
which is bot more efficient and more accurate
as it is trained jointly with thre rest of the pieliine. -
Given: a set of seed points
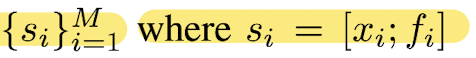
with xi ∈ ℝ^3, fi ∈ ℝ^C,
shared voting module generates votes from each seed independently. -
voting module: MLP network.
input: seed feature fi
output: Euclidean space offset Δxi ∈ ℝ^3 and feature offset Δfi ∈ ℝ^C
such that the vote vi = [yi;gi] generated from the seed si
has yi = xi + Δxi and gi = fi + Δfi -
Predicted 3D offset Δxi is supervised by a regression loss
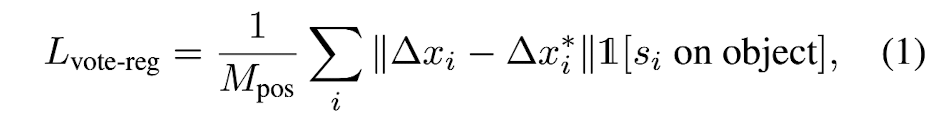
1[si on object]: wheter a seed point si is on an object surface
Mpos: count of total number of seeds on object surface
Δxi*: GT displacement from the seed position xi
to the bounding box center of the object it belongs to. -
Votes generated from seed on the same object
are now closer to each other than the seeds are,
which makes it easier
to combine cues from different parts of the object.
Object Proposal and Classification from Votes
-
The votes create canonical "meeting points"
for context aggregation
from different parts of the objects. -
After clustring these votese
we aggregate their features
to generate object proposals and classify them.
Vote clustering through sampling and grouping
- From a set of votes
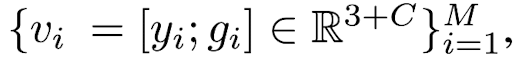
paper sample a subset of K votes
using farthest point sampling
based on {yi} in 3D Euclidean space,
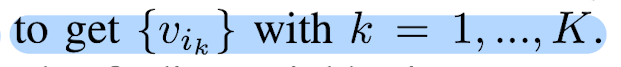
Then, form K clusters
by finding neighboring votes to each of the vik's 3D location:
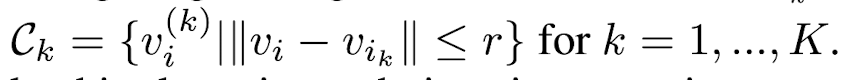
Proposal and classification from vote clusters
-
Paper used a shared PointNet
for vote aggregation and proposal in clusters. -
Given: a vote cluster C = {wi} with i = 1, ..., n
wi: cluster center, where wi = [zi; hi]
zi: vote location ∈ ℝ^3
hi: vote feature ∈ ℝ^C -
To enable usage of local vote geometry,
transformed vote locations to a local normalized coordinate system by
zi' = (zi - zj) / r -
Then an object proposal for this cluster p(C) is generated by
passing the set input through a PointNet-like module:
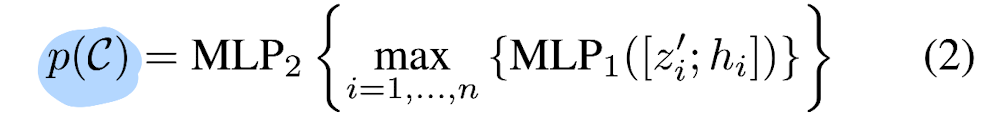
-
where votes from each clusters are
independently processed by a MLP1
before being max-pooled to a single feature vector -
and passed to MLP2
where information from different votes are further combined. -
Paper presents the proposal p as a multidimensional vector
with an objectness score, bounding box parameters and semantic classification scores.
👨🏻🔬 Experimental Results
- Dataset
SUN RGB-D: a single-view RGB-D dataset for 3D scene understanding
ScanNetV2: richly annotated dataset of 3D reconstructed meshes of indoor scenes.
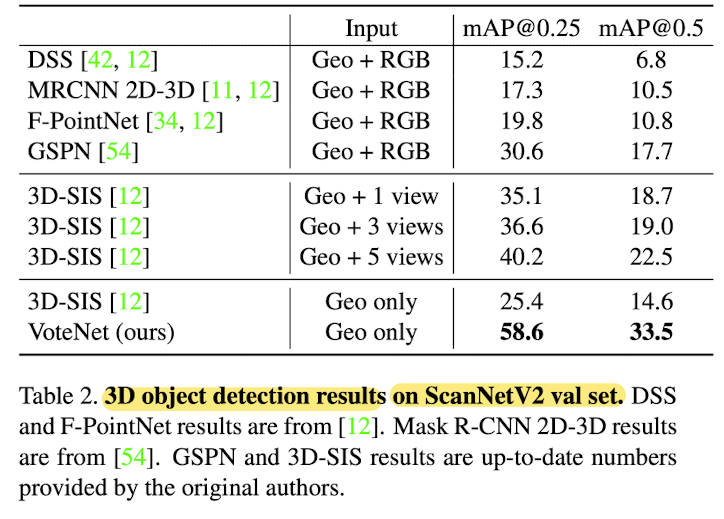
Comparison with SOTA methods
- Compared 3D CNN based detectors:
DSS(Deep sliding shpares)
3D-SIS
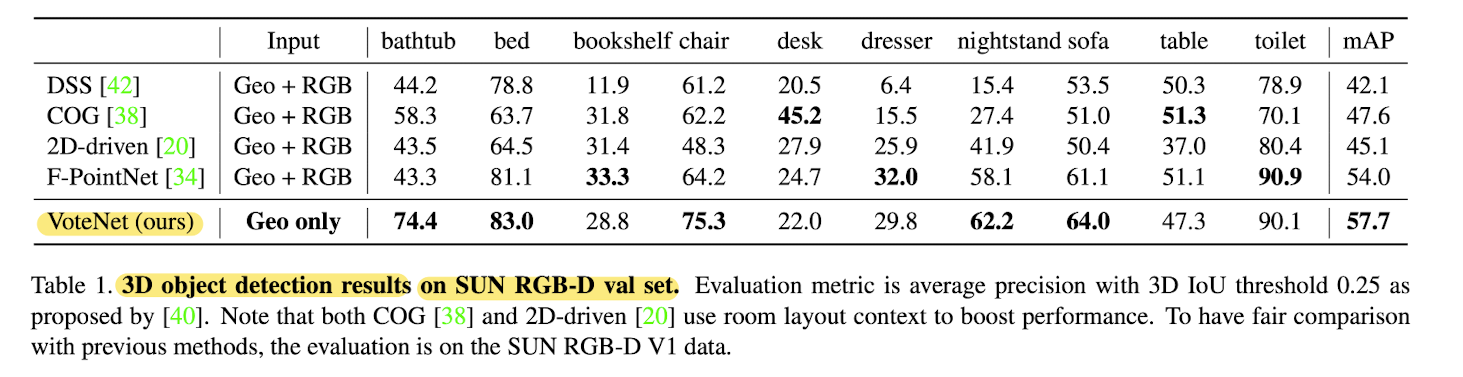
Effectivenetss of Vote
-
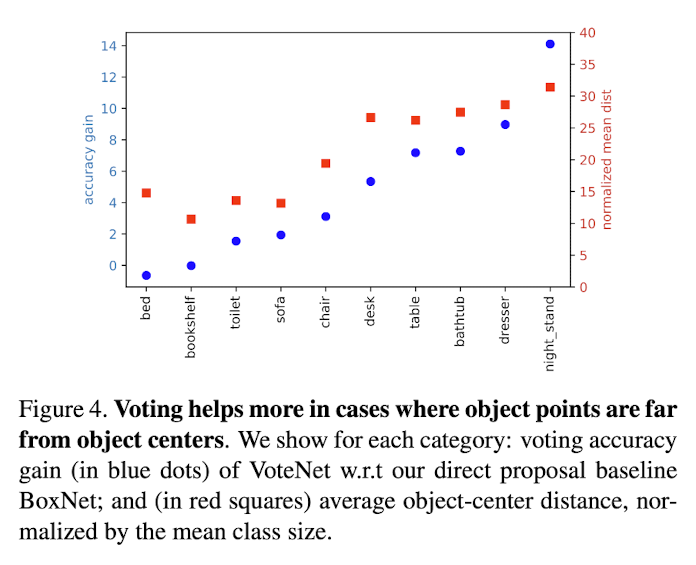
Paper argues that since in sparese 3D point clodus,
existing scene points are often far from object centroids,
a direct proposal may have lower confidence and inaccurate amodal boxes. -
Voting, instead, brings closer toghether
these lower confidenct points
and allows to reinforce their hypothesis though aggreagtion. -
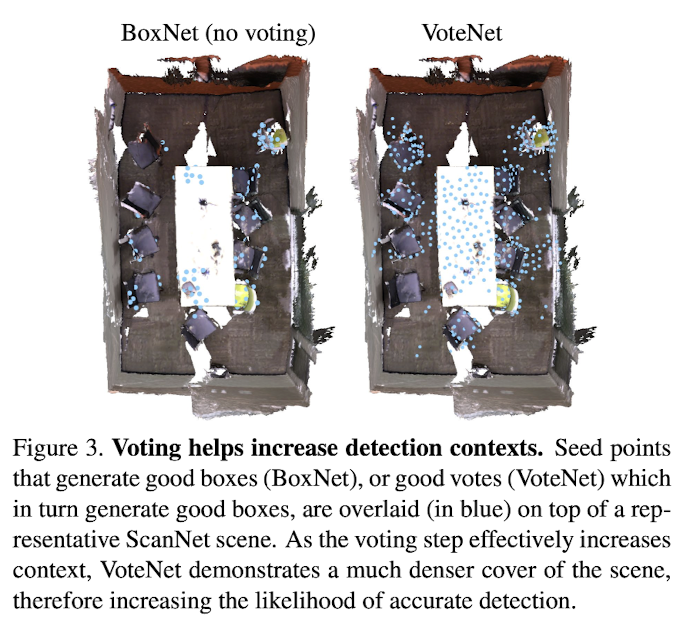
Paper demonstrated this phenomenon in Fig 3 on a typical ScanNetV2 scene.
VoteNet(right) offers a much broader coverage of "good" seed points compared to BoxNet(left),
showing its robustness brought by voting. -

-
-
-
please refer to the paper for the rest of details.
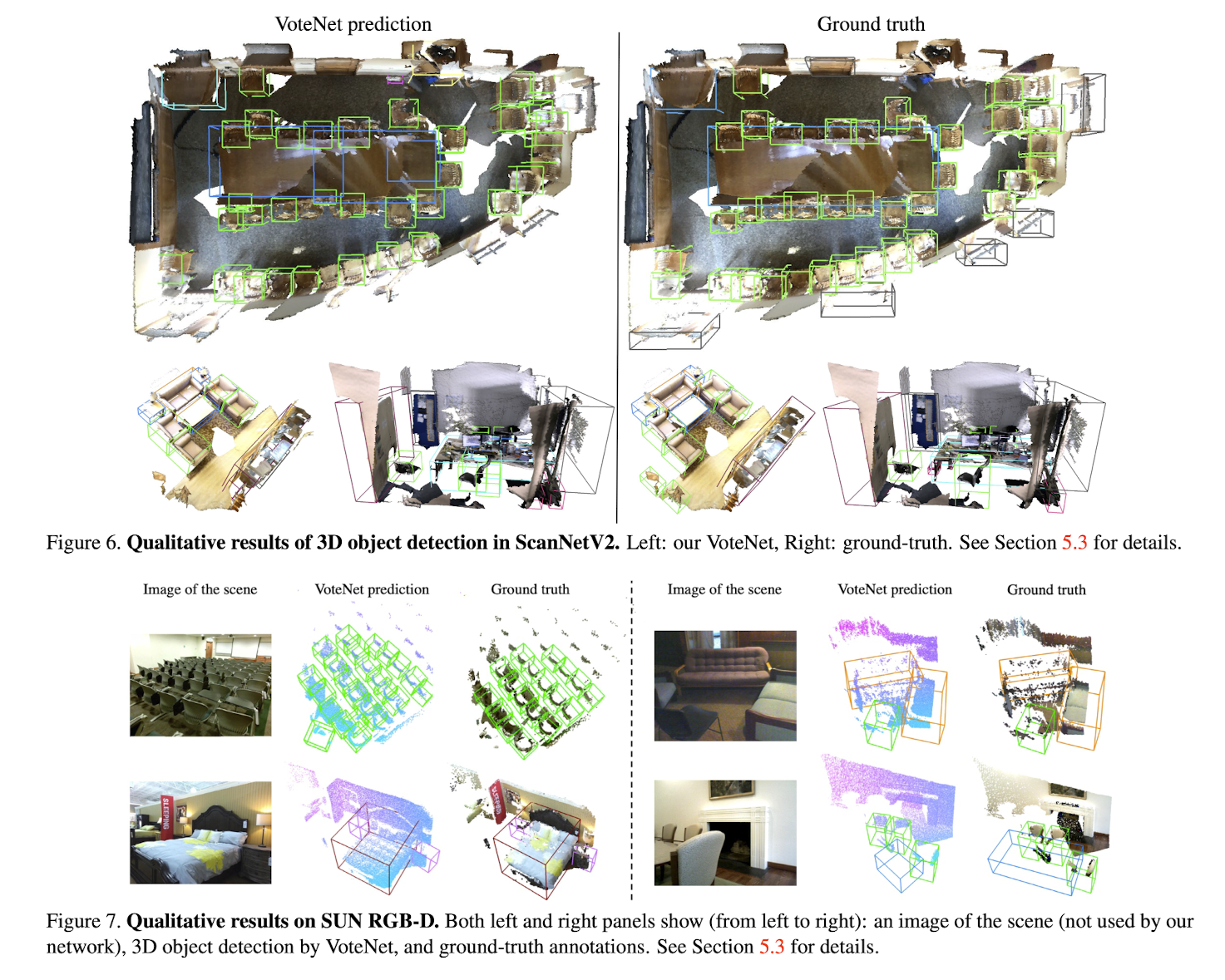
Qualitative Results
✅ Conclusion
-
Paper have introduced VoteNet:
a simple, yet powerful 3D object detection model inspired by Hough voting -
Network learns to vote to object centroids directly from point clouds
and learns to aggregate votes through their features and local geometry
to generate high-quality object proposals.
