DISN: Deep Implicit Surface Network for High-quality Single-view 3D Reconstruction
ML For 3D Data
🚀 Motivation
-
While many single-view 3D reconstruction methods that learn a shape embedding from a 2D image are able to capture the global shape properties, they have a tendency to ignore details such as holes or thin structures.
-
Methods such as voxels, octrees, points, and primitives are suffered from limited resolution and fixed mesh topology.
➡️ Implicit representations provide an alternative representation to overcome these limitations.
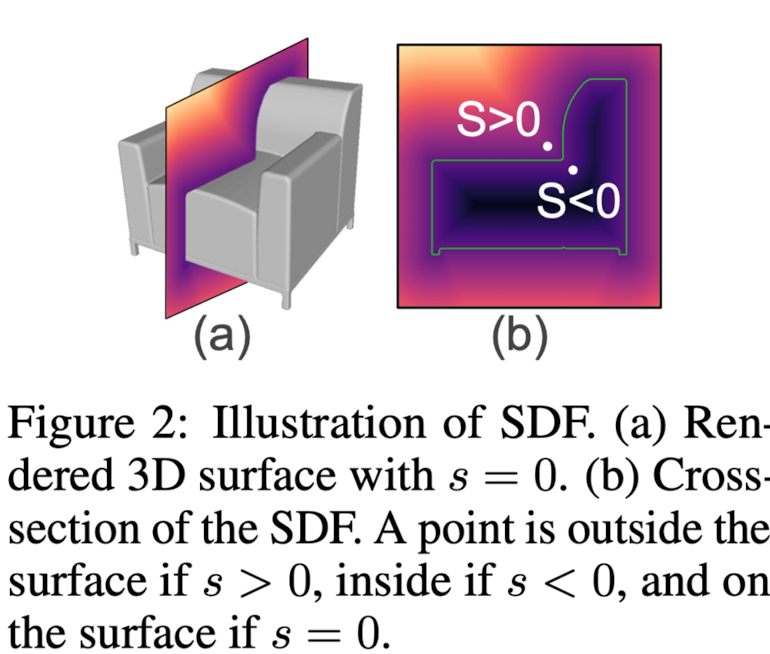
➡️ This paper adopt the Signed Distance Function(SDF), the most popular implicit surface representations.
🔑 Key Contribution
-
This paper presents DISN(Deep Impicit Surface Network), which can generate a high-quality detail-rich 3D mesh from a 2D image by predicting the underlying signed distance fields.
-
DISN predicts the projected location for each 3D point on the 2D image and extracts local feature from the image feature maps.
-
DISN is the first method that constantly capture details such as holes and thin structures present in 3D shapes from single-view images.
- This paper studies an alternative implicit 3D surface representation, Signed Distance Functions (SDF) and present efficient DISN for predicting SDFs from single-view images.

- Given a CNN that encodes the input image into a feature vector, DISN predicts the SDF value of a given 3D point using this feature vector.
- By sampling different 3D point locations, DISN is able to generate an implicit field of the underlying surface with inifinte resolution.
- This paper introduces a local feature extraction module.
- Specifically, estimating viewpoint parameters of the input image.
- Utilize this info to project each query point onto the input image to identify a corresponding local patch.
- Extract local features from such patches and use them in conjunction with global image features to predict the SDF values of the 3D points.
⭐ Methods
- Goal: reconstruct a 3D shape that captures both the over all structure and fine-grained details of the obejct.
- DISN predicts the SDF from an input image. (input: single image, prediction: SDF value for any given point.)
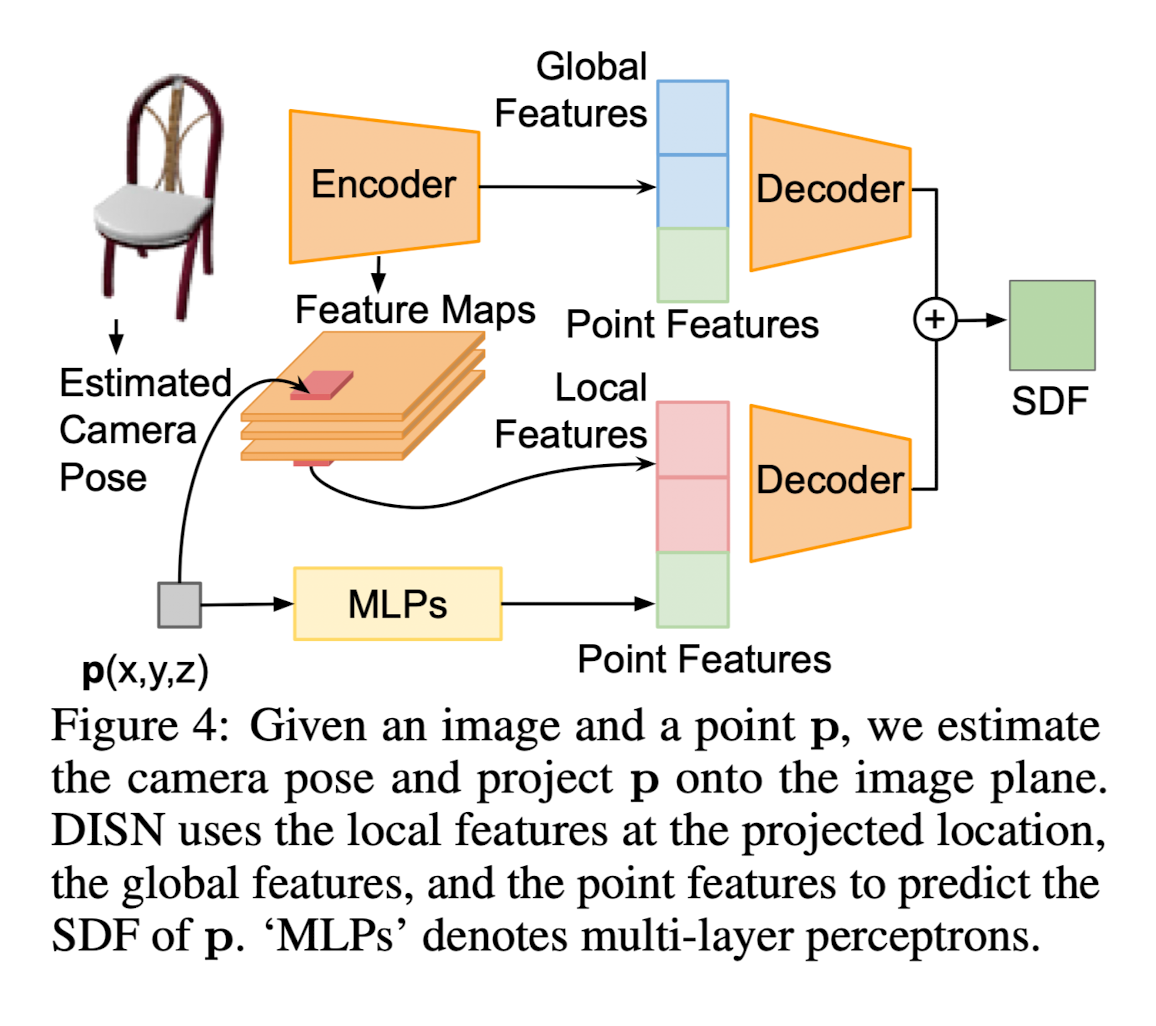
DISN: Deep Implicit Surface Network
- DISN consists of two parts: camera pose estimation and SDF prediction
- DISN first estimates the camera parameters that map an object in world coordinates to the image plaens.
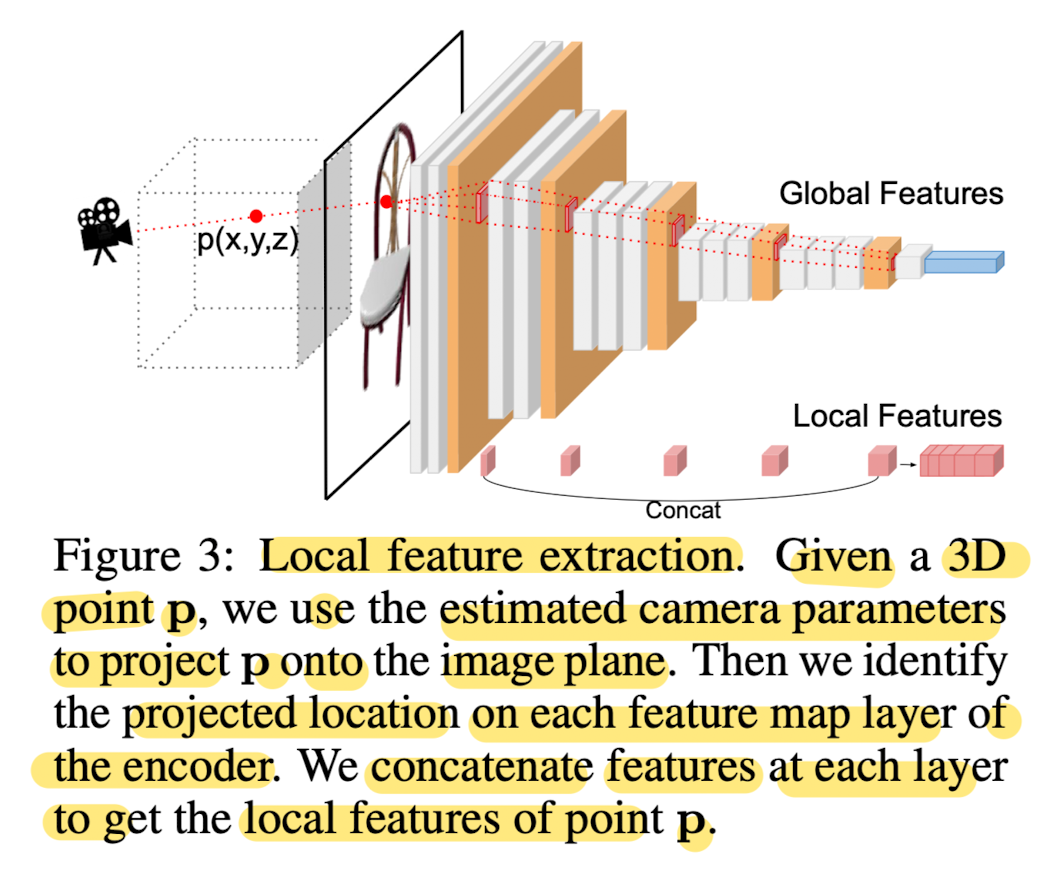
- Given predicted camera parameters, project each 3D query point onto the image plane and collect multi-scale CNN features for the corresponding image patch.
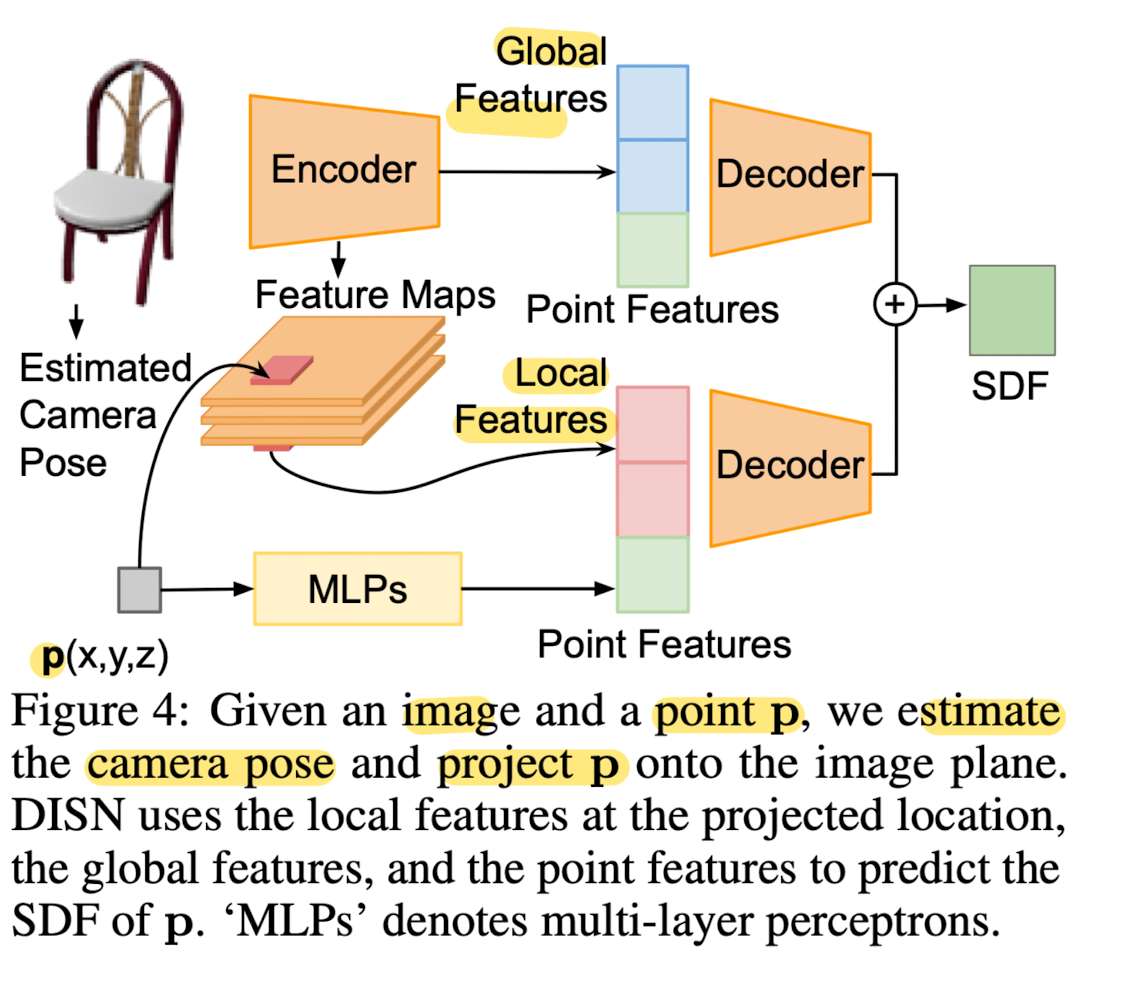
- DISN then decodes the given spatial point to an SDF value using both the multi-scale local image features and the global image features.
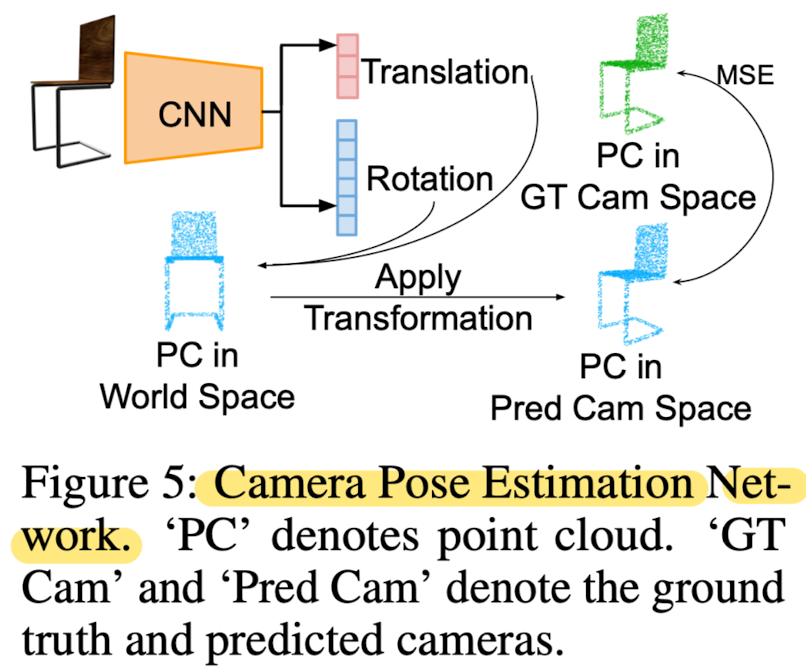
1) Camera Pose Estimation
- Given an input image, goal is to estimate the corresponding viewpoint.
- This paper trained network on the ShapeNet Core dataset, where all the models are aligned.
Therefore, use this aligned model space as the world space where camera parameters are with respect to, and assume a fixed set of intrinsic parameters. - This paper presnet a network illustrated in Fig 5.
Rotation - This network employ the 6D rotation representation b = (bx, by),
where b ∈ ℝ^6, bx ∈ ℝ^3, by ∈ ℝ^3.
Given b, where N(⋅) is the normalization function, 'x' indicates cross product,
the rotation matrix R = (Rx, Ry, Rz)^T ∈ ℝ^(3x3) is obtained by
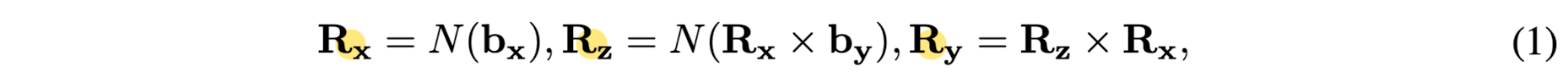
Translation - Translation t ∈ ℝ^3 from world spae to camera space is directly predicted by the network.
Loss function
- Compute the loss Lcam by calculating the mean suqared error between the transformed point cloud and the g.t point cloud in the camera space.

2) SDF Prediction with Deep NN
-
Given an image I,
SDF^I(⋅): ground truth SDF
goal of network f(⋅): estimate SDF^I(⋅) -
This paper uses a MLP to map the given point location to a higher-dimensional feature space.
-
This high dimensional feature is then concatenated with global and local features respectively, and used to regress the SDF value.
Local Feature Extraction
-
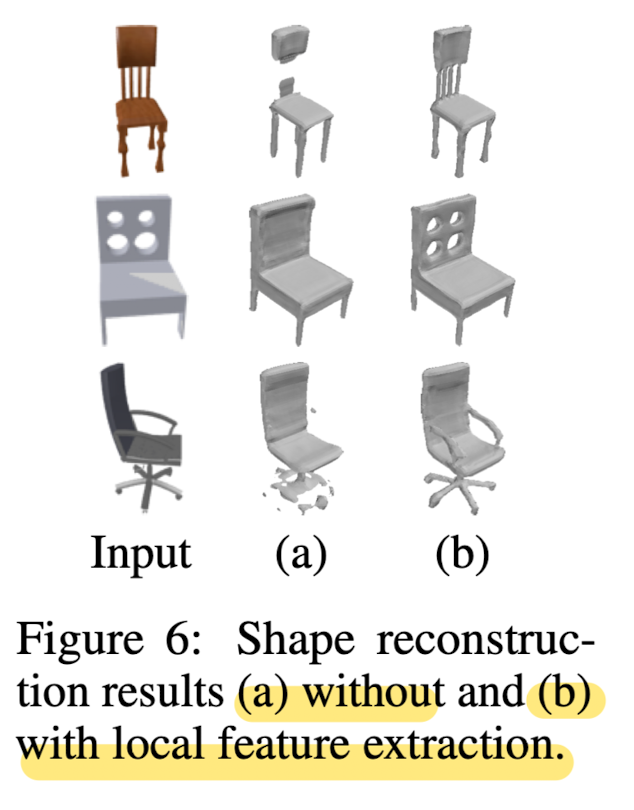
With only global features, predicting overall shape is okay, but fails to produce details.
-
Local feature extraction helps to recover missing details by predicting residual SDF.
-
This paper introduces a local feature extraction method to focus on reconstructing fine-grained detials.
-
3D point p ∈ ℝ^3 is projected to a 2D location q ∈ ℝ^2 on the image plane, with the estimated camera parameters.(Fig 3)
-
Retrieve features on each feature map corresponding to location q and concatenate them to get the local image features.
-
Two decoders then take the global and local image features respectively as input with the point features, and make as SDF prediction.
The final SDF is the sum of these two predictions.
Loss Functions
- Regress continuous SDF values instead of formulating a binary classification problme (e.g. inside or outside of a shape)
- This strategy enables to extract surfaces that correspond to different iso-values.
- To ensure that the network concentrates on recovering the details near and inside the iso-surface S0,
this paper proposes a weighted loss function.
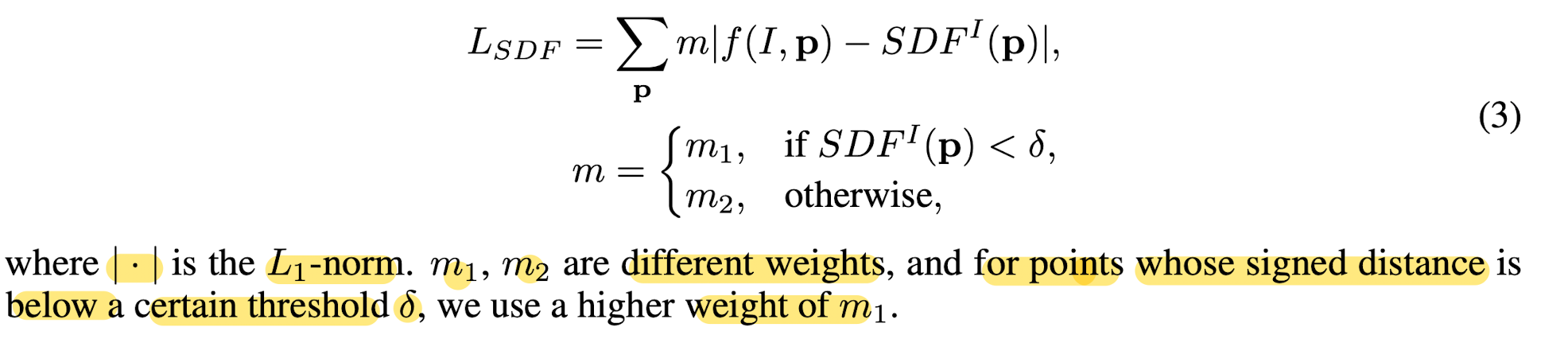
Surface Reconstruction
- To generate a mesh surface, this paper defines a dense 3D grid,
and predict SDF values for each grid point. - Once computing the SDF values for each point in the dense grid, use Marching Cubes to obtain the 3D mesh that corresponds to the iso-surface S0.
👨🏻🔬 Experimental Results
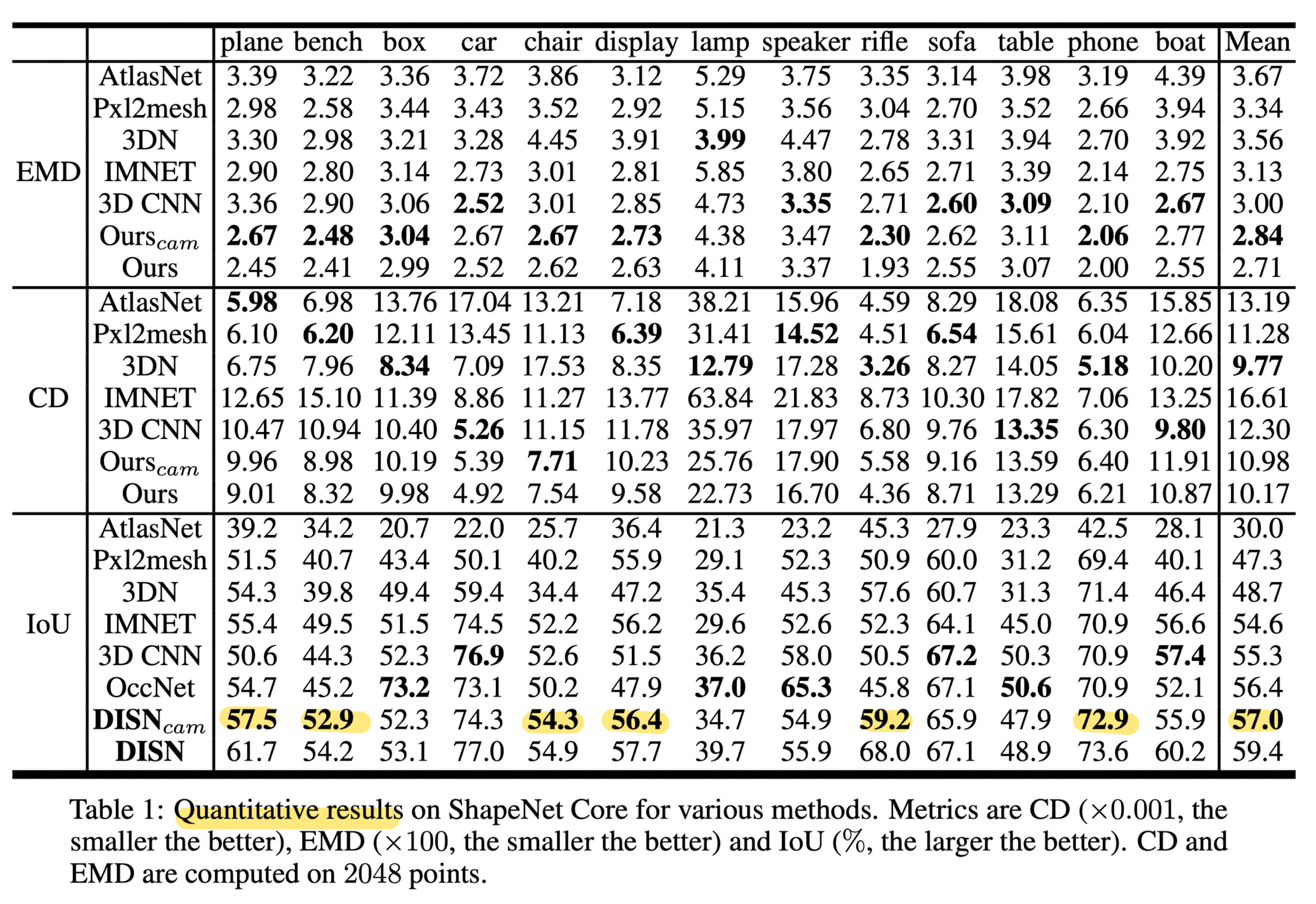
Single-view Reconstruction Comparison With State-of-the-art Methods.
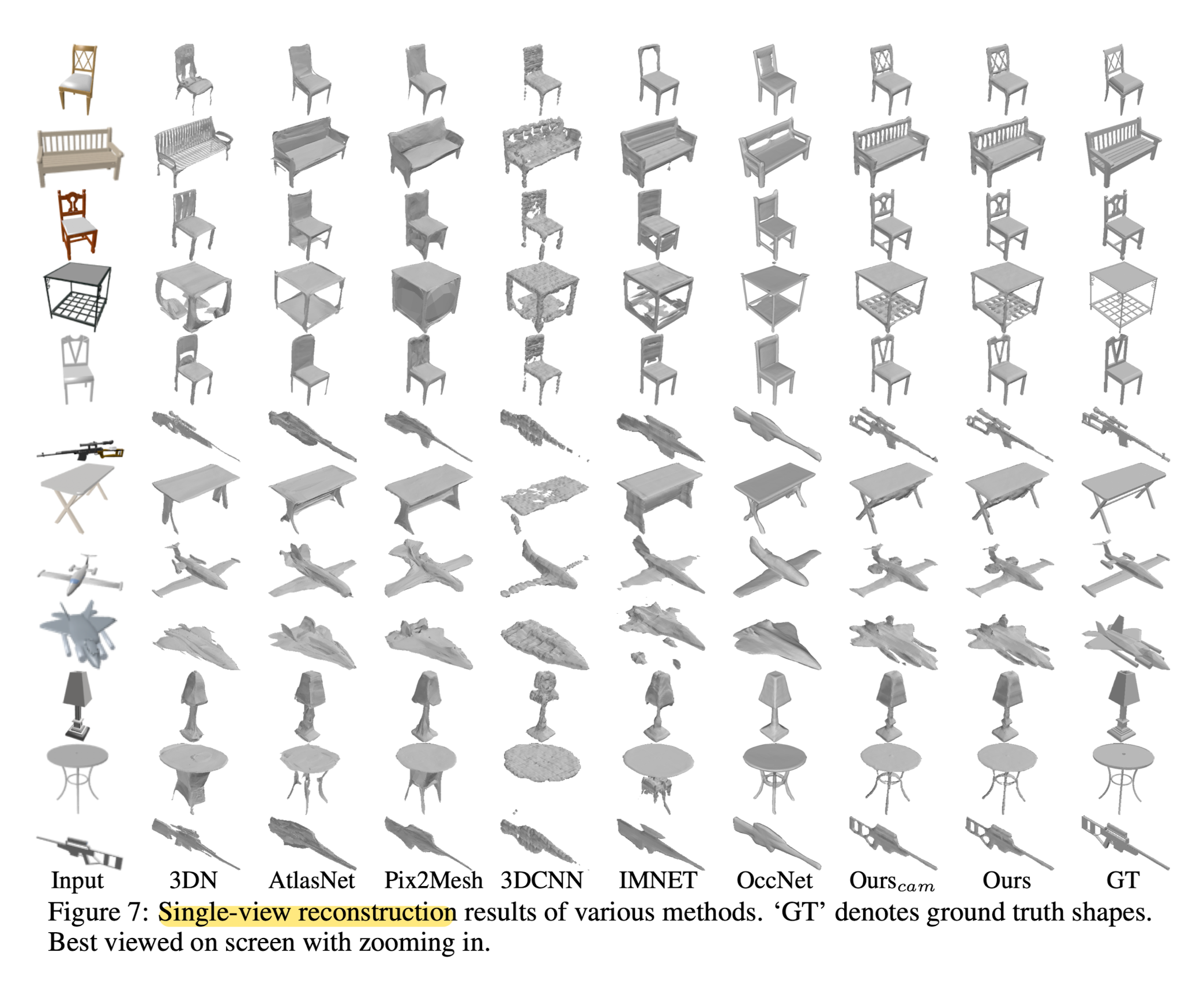
- DISN outperforms all other models in EMD and IoU.
- Implicit surface representation provides a flexible method of generating topology-variant 3D meshes.
- Local feature extraction enables method to generate different patterns of the chair backs in the first three rows, while other methods fail to capture such details.
Camera Pose Estimation
- This paper compares method's camera pose estimation.
- Given a point cloud PC2 in world coordinates for an input image,
- transform PC2 using the predicted camera pose, and
compute the mean distance d3D between transformed PC and the g.t PC in camera space. - also compute the 2D reprojection error d2d of the transformed PC after project it onto the input image.
- With the help of the 6D rotation representation, paper's method outperforms in terms of 2D reprojection error.
✏️ Limitations
- Paper's method is only able to handle objects with a clear background since it's trained with rendered images.
- To address this limitation, future work includes extednding SDF generation with texture prediction using a differentiable renderer.
✅ Conclusion
- This paper presents DISN, a deep implicit surface network for single-view reconstruction.
- Given a 3D point & input image, DISN predicts the SDF value for the point.
- This paper introduce a 'local feature extraction module' by projecting the 3D point onth the image plane with an estimated camera pose.
- With the help of such local features, DISN is able to capture fine-grained detals and generate high-quality 3D models.
