PIFu: Pixel-Aligned Implicit Function for High-Resolution Clothed Human Digitzation
ML For 3D Data
🚀 Motivations
-
Recent 3D deep learning methods infer general shapes from very few images, even a single input. However, the resulting resolutions and accuracy are limited, due to in effective model representaions.
-
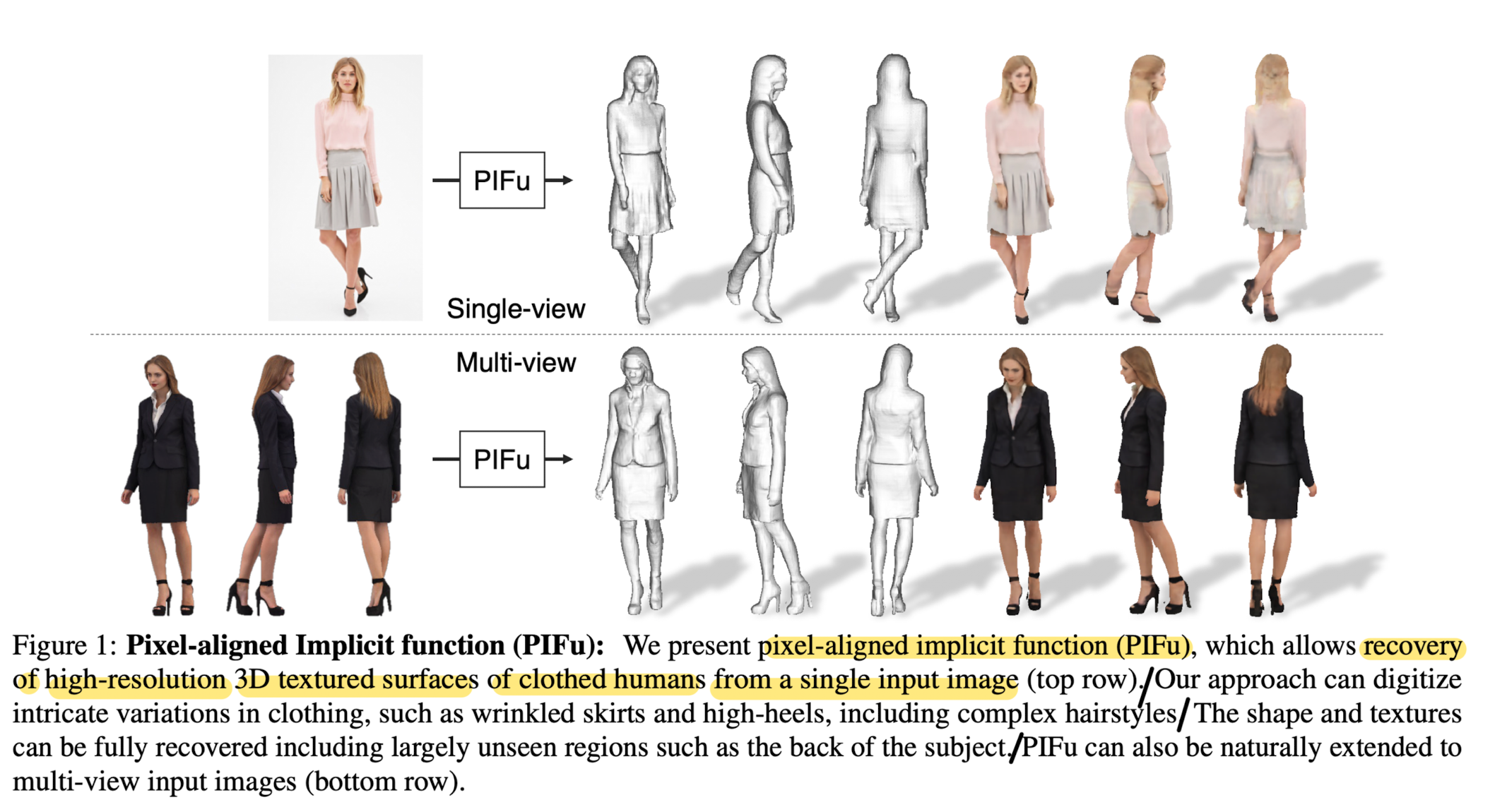
➡️ This paper proposes a new Pixel-aligned Implicit Function (PIFu) representation for 3D deep learning for the challenging problem of textured surface inference of clothed 3D humans from a single or multiple input images.
🔑 Key Contributions
-
This paper introduced PIFu(Pixel-aligned Implicit Function), an implicit representation that locally alligns pixels of 2D images with the global context of their corresponding 3D object.
-
This paper proposes an end-to-end deep learning method for digitizing highly detailed clothed humans that can infer both 3D surface and texture from a single image, and optionally, multiple input images.
-
Highly intricate shpaes, such as hairstyles, clothing, as well as their variations and deformations can be digitized in a unified way.
-
PIFu produces high-resolution surfaces including largely unseen regions such as the back of a person.
-
PIFu is memory efficient, can handle arbritrary topology, and the resulting surface is spatially aligned with the input image.
-
This paper shows the combination of local features and 3D-aware implicit surface representation makes a siginificant differenece inicluding highly detailed reconstruction even from a single view.
-
Paper's algorithm can handle a wide range of complex clothing, such as skirts, scarfs, and even high-heels while capturing high frequency details such as wrinkles that match the input image at the pixel level.
⭐ Methods: PIFu(Pixel-Aligned Implicit Function)
-
Goal: Given a single or multi-view images, reconstruct the underlining 3D geometry and texture of clothed human,
while preserving the detail present in the image. -
An implicit function defines a surface as a level set of a function f, e.g. f(X) = 0
-
The propsed pixel-aligned implicit function consists of a fully convolutional image encoder g,
and a continuous implicit function f represented by MLP,
where the surface is defined as a level set of

-
The key observation is that method learn an implicit function over the 3D space with pixel-aligned image features, rather than global features, whcih allows the learned functions to preserve the local detail present in the image.
-
Unlkike existing methods, which synthesize the back regions based on frontal views in an image space, paper's approach can predict colors in unseen, concave and side regions directly on the surface.
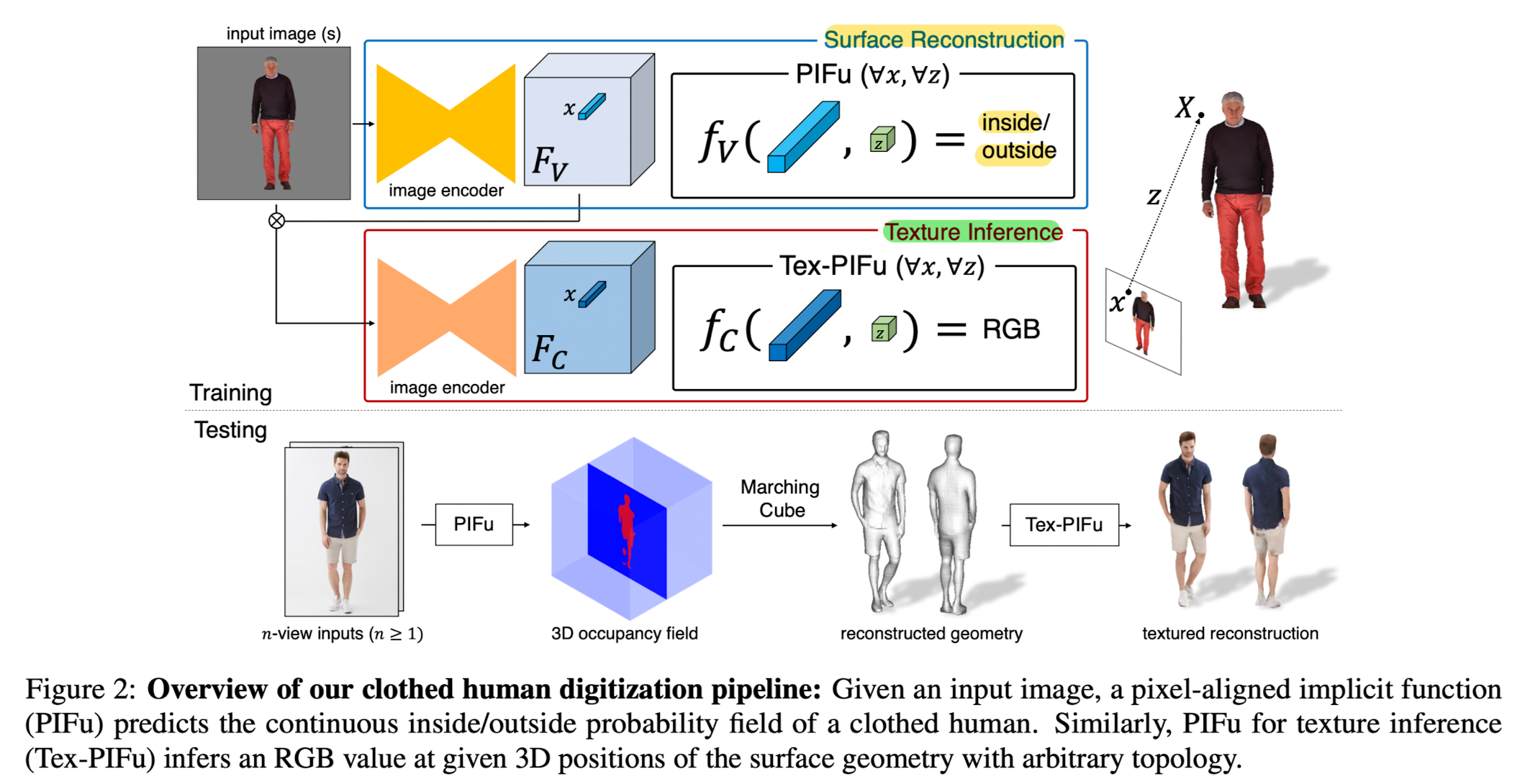
Digitization Pipeline
-
Given an input image, PIFu for surface reconstruction predicts the continuous inside/outside probaility field of a clothed human, in which iso-surface can be easily extracted.
-
PIFu for texture inference outputs an RGB value at 3D positions of the surface geometry,
enabling texture inference in self-occluded surface regions and shapes of arbitrary topology. -
Proposed approach can handle single-view and multi-view input naturally, which produce even higher fidelity results when more views are available.
Single-view Surface Reconstruction
- For surface reconstruction, this paper represents the ground truth surface as a 0.5 level-set of a continuous 3D occupancy field:

- This paper trains a PIFu fv by minimizing the average of mean squared error:
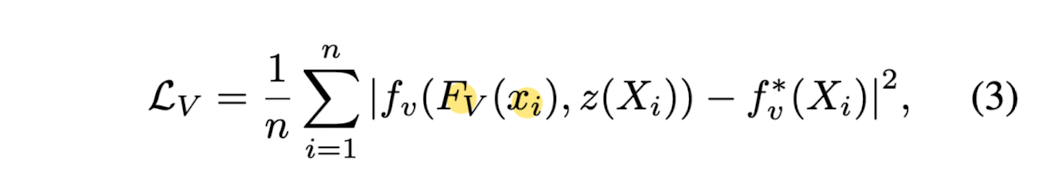
where - Xi ∈ ℝ^3,
- Fv(x) = g(I(x)) is the image feature from the image encoder g at x = π(X) (x: its 2D projection)
- n: number of sampled points.
- Given a pair of an input image and the corresponding 3D mesh tha is spatially aligned with the input image, the parameters of the image encoder g and PIFu fv are jointly updated by minimizing above Loss Equation.
Spatial Sampling
- This paper develops a spatial sampling strategy that is critical for achieving high-fidelity inference.
- This paper proposes to combine uniform sampling and adaptive sampling based on the surface geometry.
- Please refer to papers for the details.
Texture Inference
-
PIFu enables to directly predict the RGB colors on the surface geometry by defining s in Eq.1 as an RGB vector field instead of a scalar field.
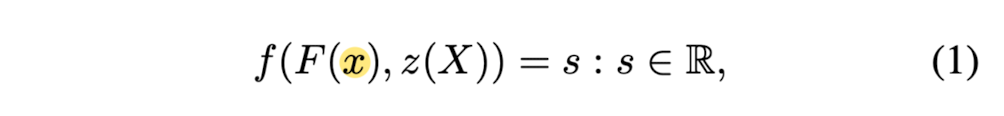
-
However, extending PIFu to color prediction is a non-trivial task as RGB colors are defined only on the surface while 3D occupancy field is defined over the entire 3D space.
-
This paper highlights the modification of PIFu in terms of training procedure and a network architecture.
-

🔥 Problems
- This paper found that naively training fc with the loss function above severely suffers from overfitting.
- The problem is that fc is expected to learn not only RGB color on the surface,
but also the underlining 3D surfaces of the object so that fc can infer texture of unseen surface with different pose and shape during inference.
💧 Modification
-
Condition the image encoder for texture inference with the image features learned for the surface reconsturction Fv.
➡️ This way, the image encoder can focus on color inference of a given geometry even if unseen objects have different shape, pose, or topology. -
Introduce an offset ε ~ N(0, d) to the surface points along the surface normal N
➡️ so that the color can be defined not only on the exact surface bit also on the 3D space around it. -
With the modifications above, the training objective function can be rewritten as:
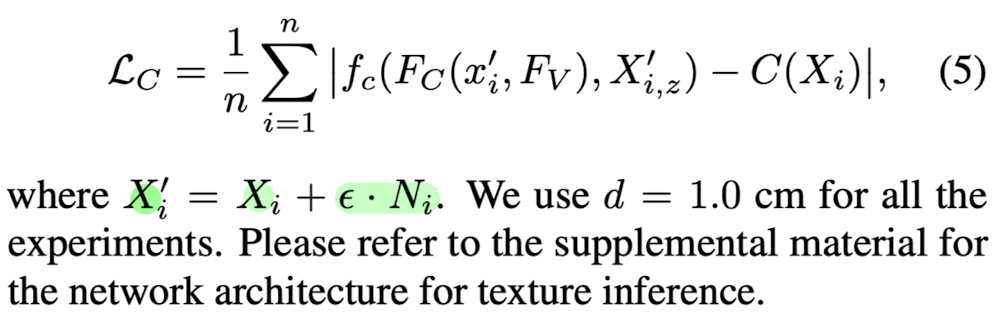
Multi-View Stereo
-
Additional views provide more coverage about the person and improve the digitization accuracy.
-
Formulation of PIFu provides the option to incorporate info from more views for both surface reconstruction and texture inference.
-
This paper achieve this by using PIFu to learn a feature embedding for every 3D point in space.
-
Output domain of Eq.1 is a n-dimensional vector space s ∈ ℝ^n that represents the latent feature embedding associated with the specified 3D coordinate and the image feature from each view.
-
Since this embedding is defined in the 3D world coordinate space, aggregating the embedding from all available views that share the same 3D point is possible.
-
The aggregated feature vector can be used to make a more confident prediction of the surface and the texture.
-
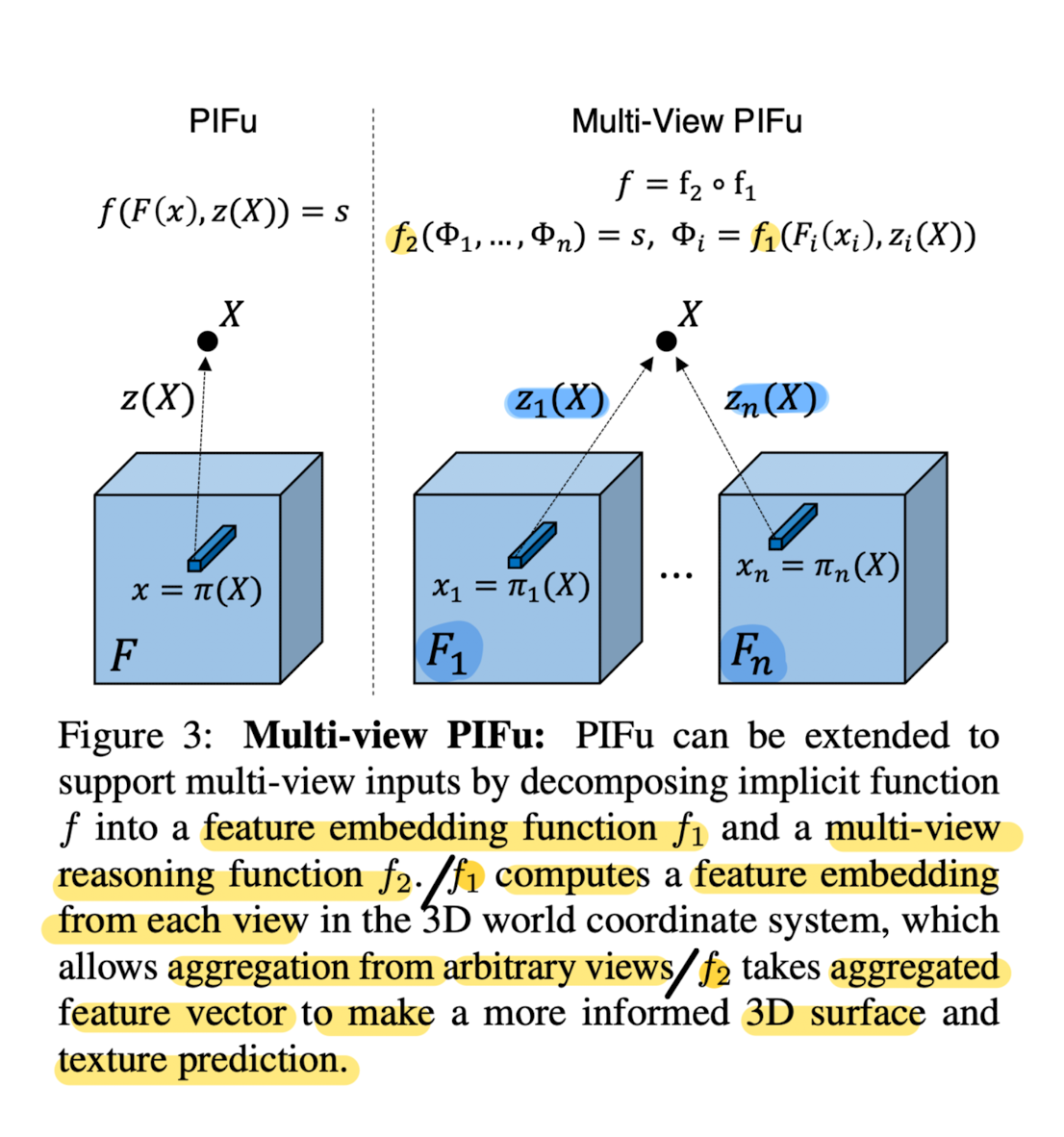
This paper decomposes the pixel-aligned function f into a
feature embedding network f1 and
multi-view reasoning network f2
as f := f2 ∘ f1. -
f1: encodes the image feature and depth value from each view point i into latent feature embedding Φi by average pooling operation,
and obtain the fused embedding
-
f2: maps from the aggregated embedding Φ to target impicit field s
(i.e., inside/outside probability for surface reconstruction and RGB value for texure inference.)
👨🏻🔬 Experimental Results
Quantitative Results
Single-View Reconstruction
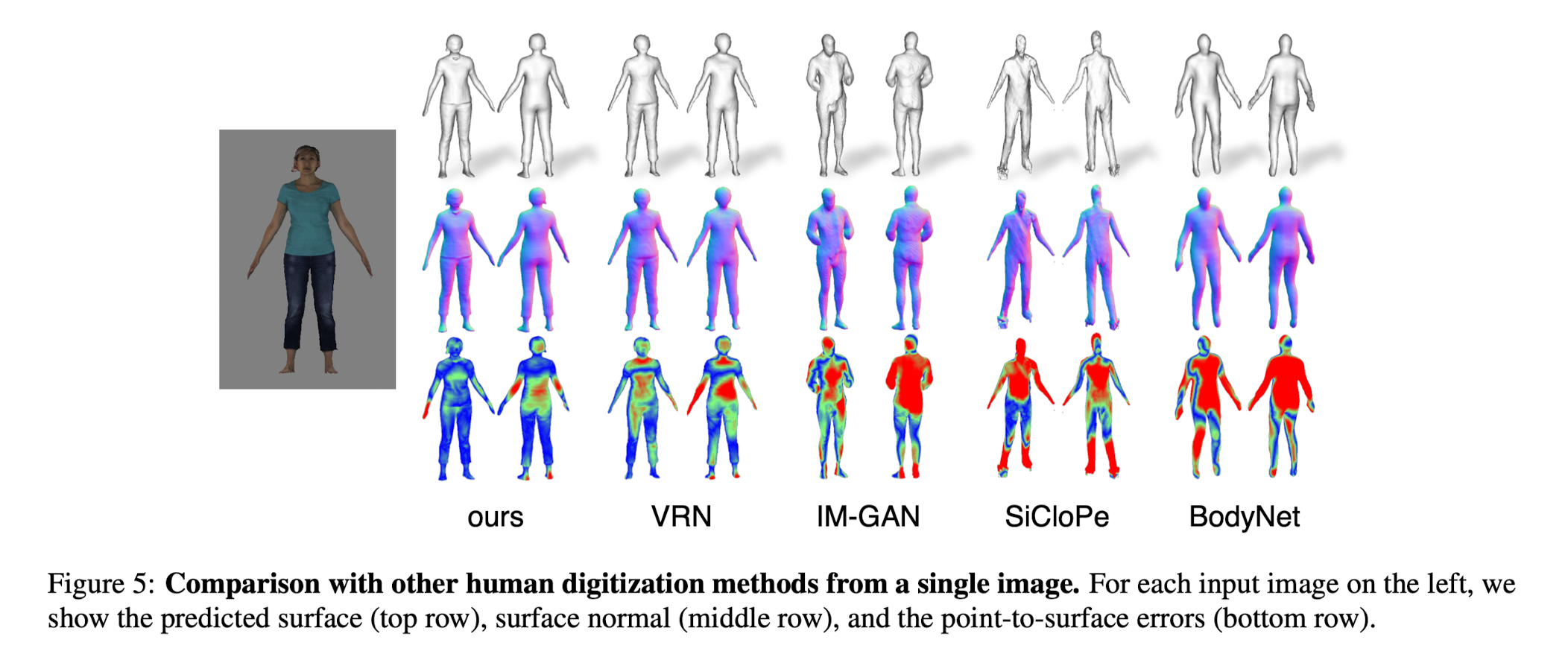
- This paper evaluatees the reconstruction erros for each method on both Buff and RenderPeople test set. (Table 1 and Figure 5)
- Paper's method outputs pixel-aligned high-resolution surface reconstruction that captures hair styles and wrinkles of the clothing,
in contrast to the SOTA single-view reconstruction method using implicit function (IM-GAN) that reconsturct surface from one global feature per image 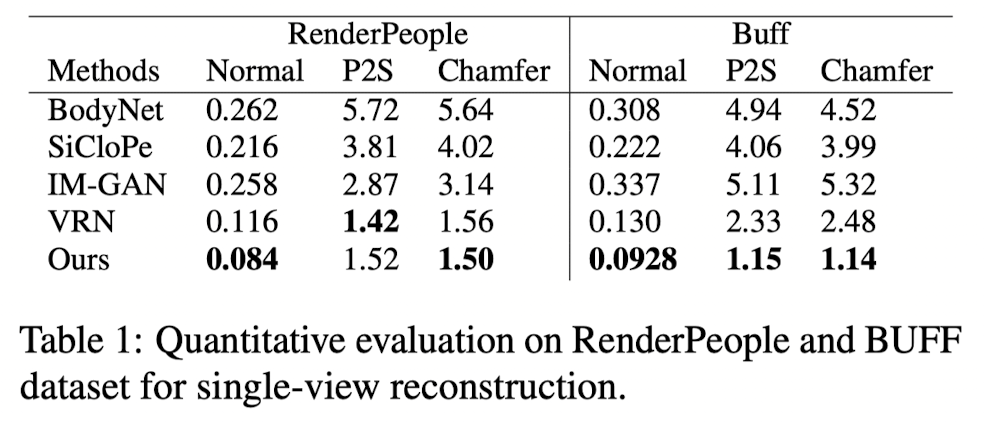
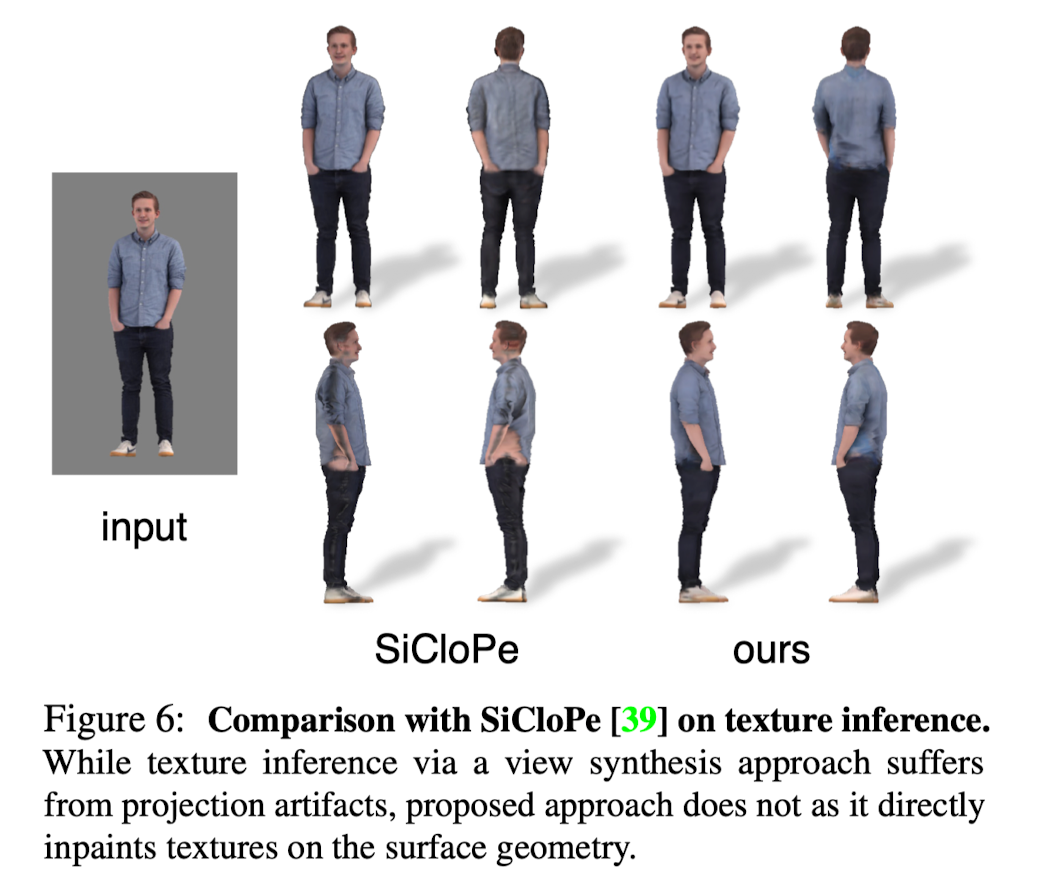
- Compare single-view texture inferences with SOTA inference method on clothed human.
- While SiCloPe suffers from projection distortion and artifacts around the silhouette boundary, paper's approach predicts textures on the surface mesh directly, removing projection artifacts.
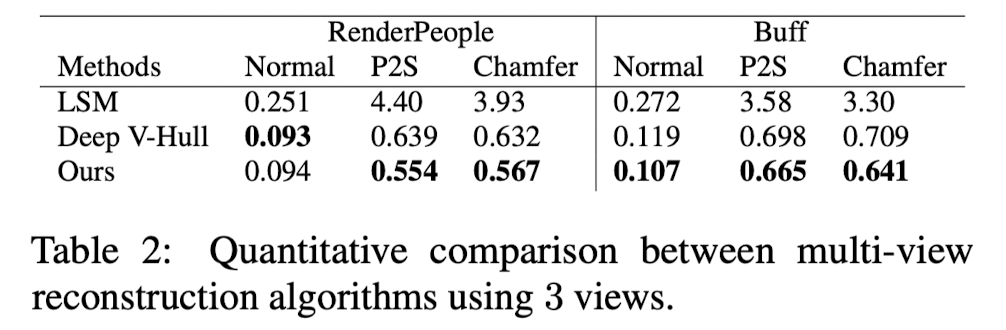
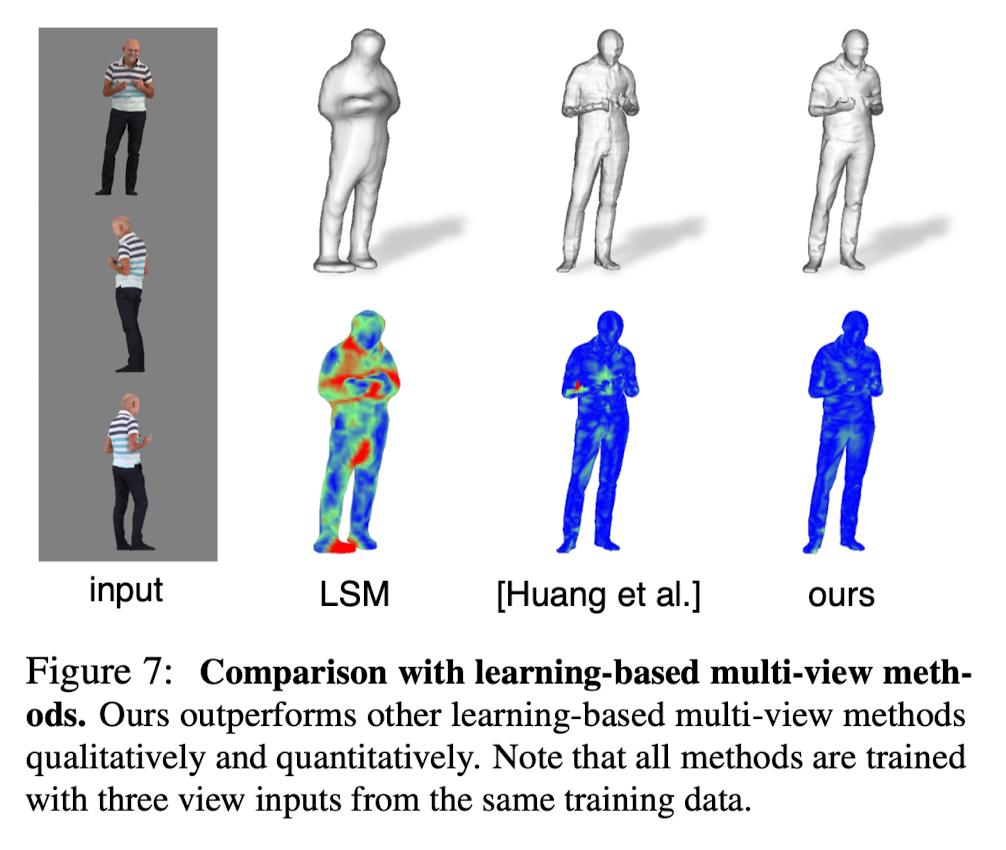
Multi-View Reconstruction
-
Comparison with other deep learning-based multi-view methods.
-
-
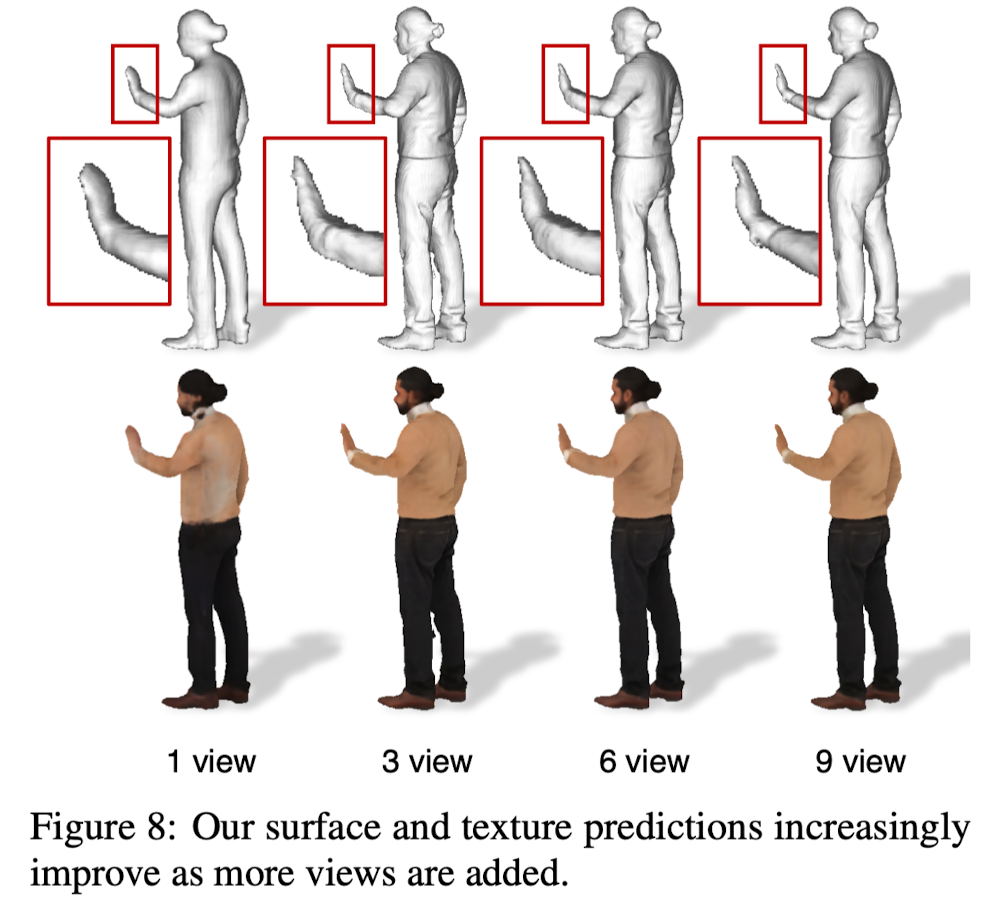
- Multi-view PIFu shows increasingly refined geometry and texture by incorporating arbitrary number of views in Fig 8.
Qualitative Results
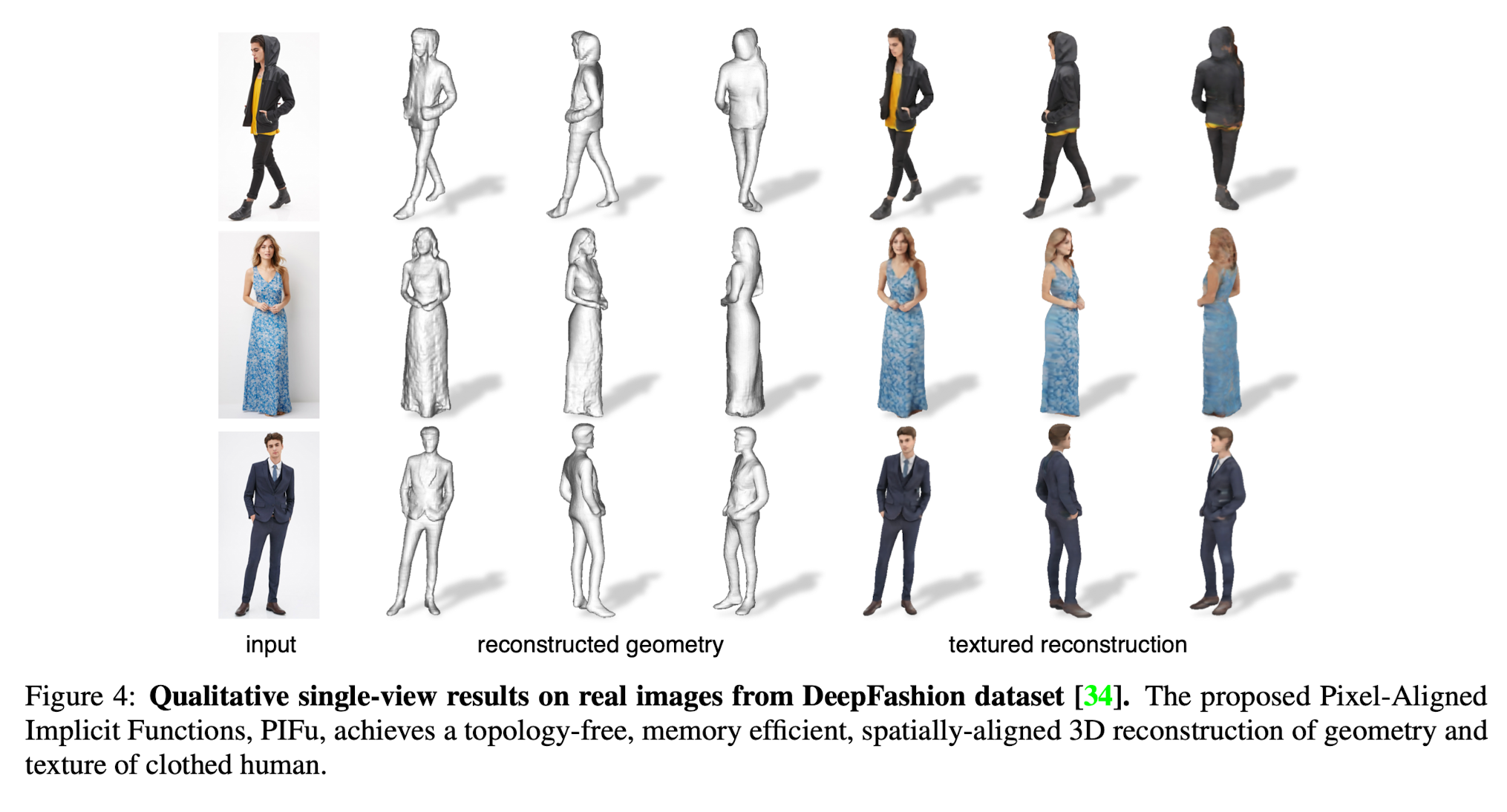
- Fig 4 show digitization results using real world input images from the DeepFashion dataset.
- PIFu can handle wide varieties of clothing
- Can produce high-resolution local detais, while inferring plausible 3D surfaces in unseen regions and complete textures.