🚀 Motivations
-
1️⃣ Few recent works have SOTA performance with just point clouds input (e.g. VOTENET)
-
VOTENET showed remarkable improvement for indoor object recognition compared with previous works that exploit all RGB-D channels.
➡️ This leads to an interesting research questions:
🤔 Is geometry data(point clouds) sufficient for 3D detection, or
🤔 Is ther any way RGB images can further boost current detectors?
-
2️⃣ Point cloud data's inherent limitations.
1) Sparsity, 2) Lack of color information, 3) Suffer from sensor noise
However, have advantage: Having absolute measures of object depth and scale, -
Images have advantage: high resolution and rich texture
However, have Limitations: Lack of absolute measures of object depth and scale,
✅ Thus Image and Point Clouds can provide complementary information.
-
IMVOTENET is a 3D detection architecure based on
fusing 2D votes in images and 3D votes in point clouds.
(which is build upon VOTENET arch.) -
Extract both geometric and semantic features from the 2D images.
Leverage camera parameters to lift these features to 3D. -
To improve the synergey of 2D-3D feature fusion,
paper also propose a multi-tower training scheme.
🔑 Key Contributions
-
Geometrically principled way
to fuse 2D object detection cues
into a point cloud based 3D detection pipeline. -
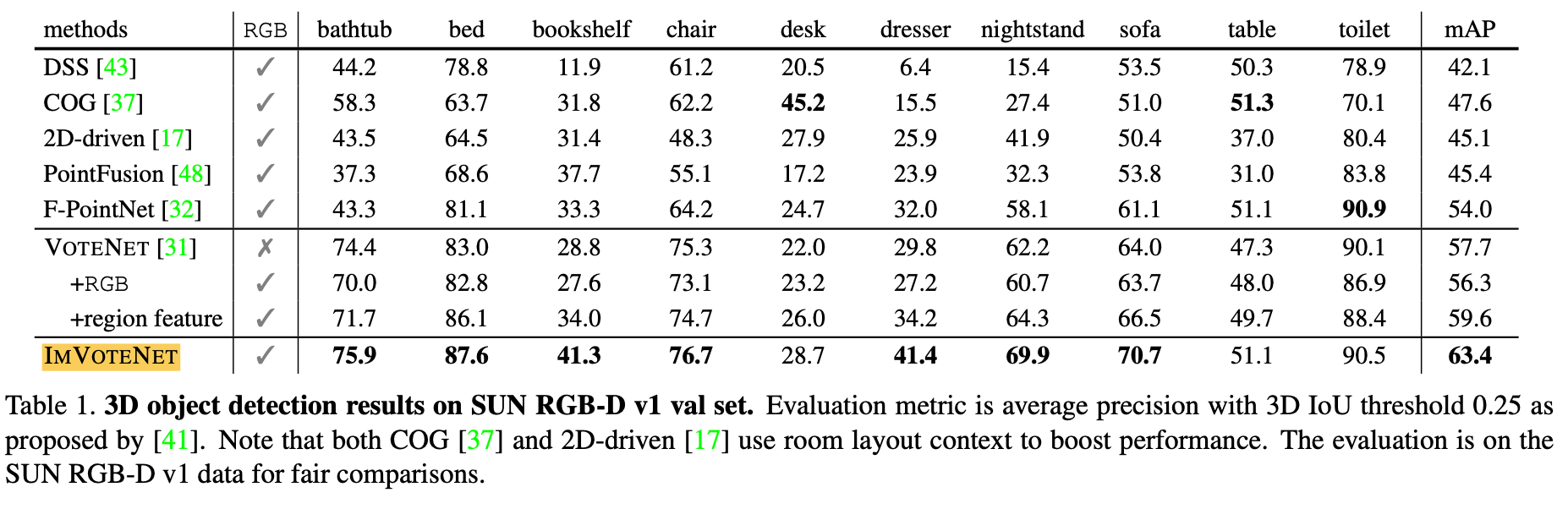
IMVOTENET achieves SOTA 3D object detection performance on SUN RGB-D
⭐ Methods
Abstract
-
Key is leveraging both geometric and semantic/texture cues in 2D images.
-
Geometric cues
Given a 2D box, paper generates 2D votes on the image space.
To pass the 2D votes to 3D,
lift them by applying geometric transformations
based on the camera intrinsic and pixel depth,
so as to generate "pseudo" 3D votes. -
Semantic/Texture cures
each pixel passes semantic and texture cues to the 3D points. -
After lifting and passing all the features
from th images to 3D,
concatenate them with 3D point features
from a point cloud backbone network. -
Next, following the VOTENET pipeline,
points with the fused 2D and 3D features
generate 3D Hough votes toward object centers
and aggregate the votes
to produce the final object detections in 3D. -
Paper introduces a multi-towered network structure
with gradient blending
to balance and ensure making the best use of both 2D and 3D features.
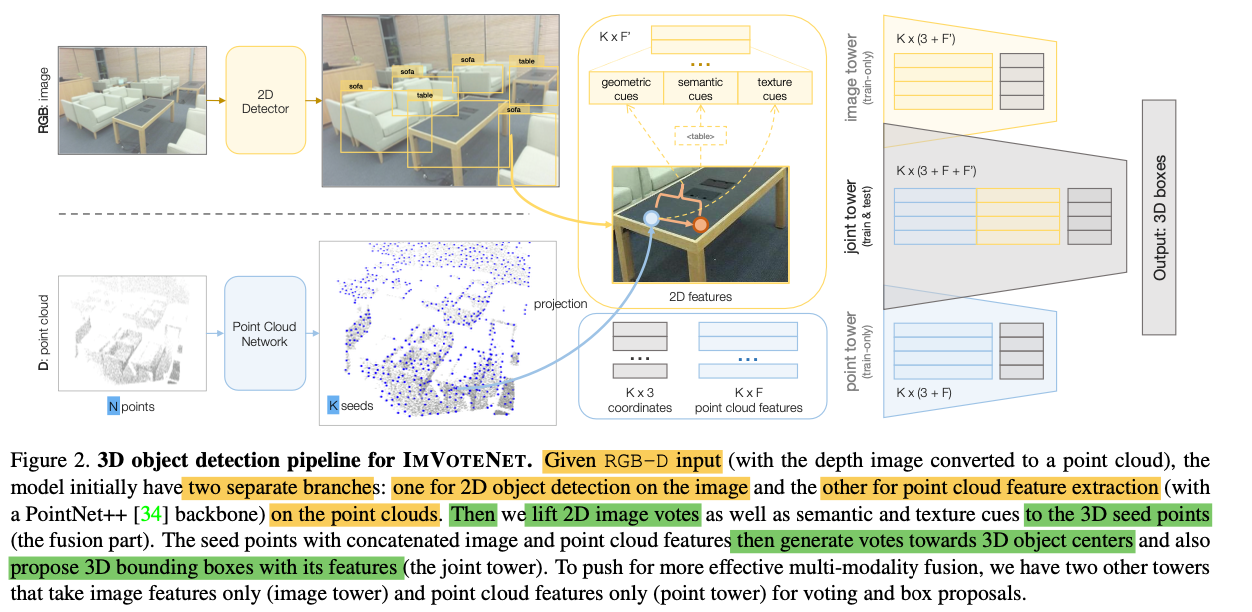
ImVoteNet Architecture

Deep Hough Voting
-
VOTENET consumes a 3D point cloud
and outputs object proposals for 3D object detection. -
VOTENET proposes an adaptation of the voting mechanism
for object detection to a deep learning framework
that is fully differentiable. -
VOTENET is comprised of a point cloud feature extraction module
that enriches a subsampled set of scene points (called seeds)
with high-dimensional features
(bottom of Fig2 from N x 3 input points to K x (3+F) seeds) -
These features are then pushed through a MLP
to generate votes. -
Every vote is both
a point in the 3D space with its Euclidean coordinates (3-dim)
supervised to be close to the object center,
and a feature vector learned for the final detection task (F-dim) -
Votes form a clustered point cloud near object centers
and then be processed by another point cloud network
to generate object proposals and classification socre. -
In IMVOTENET,
paper leverage the additional image information
and propose a lifting module from 2D votes to 3D
thet improves detection performance.
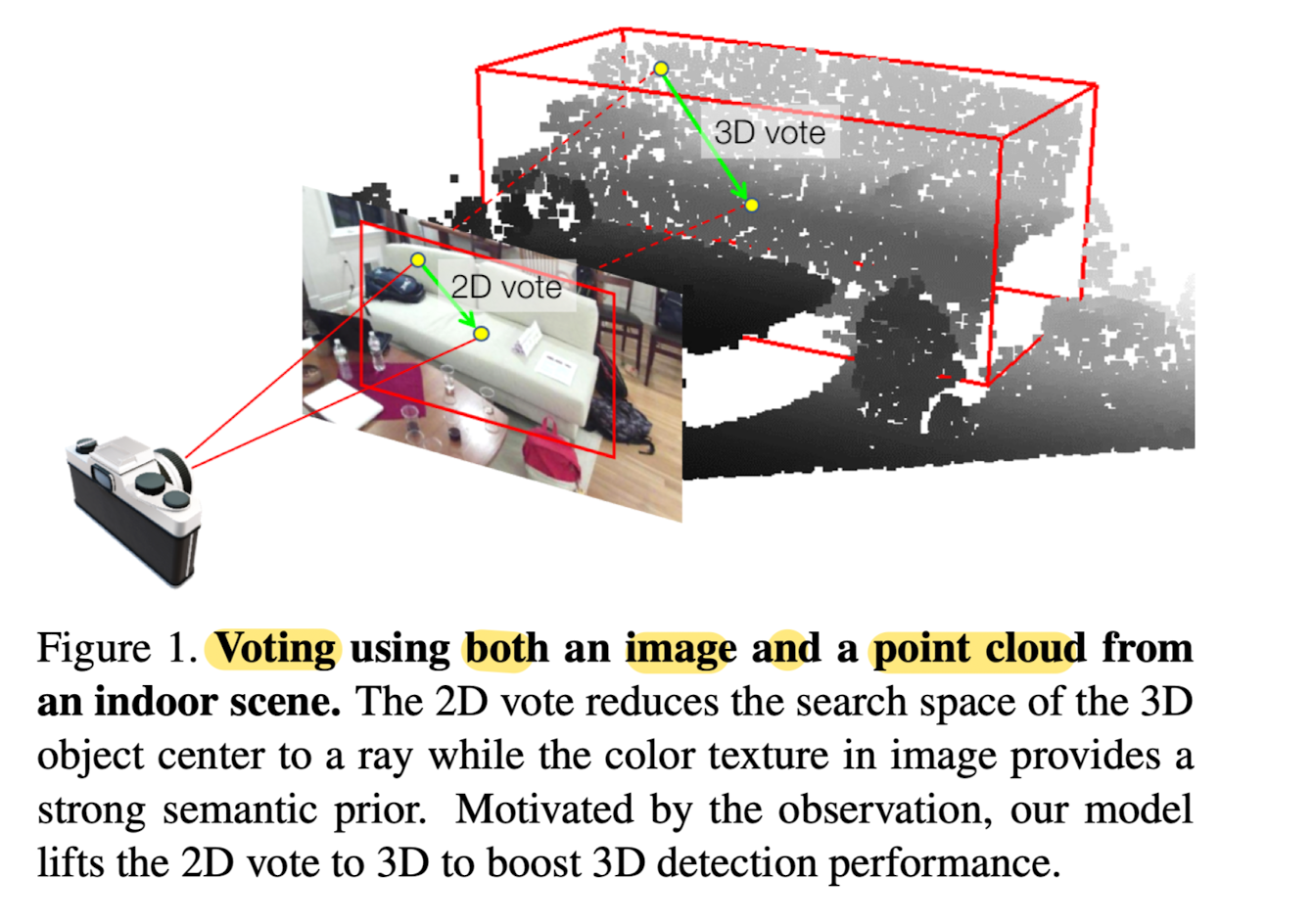
Image Votes from 2D Detection
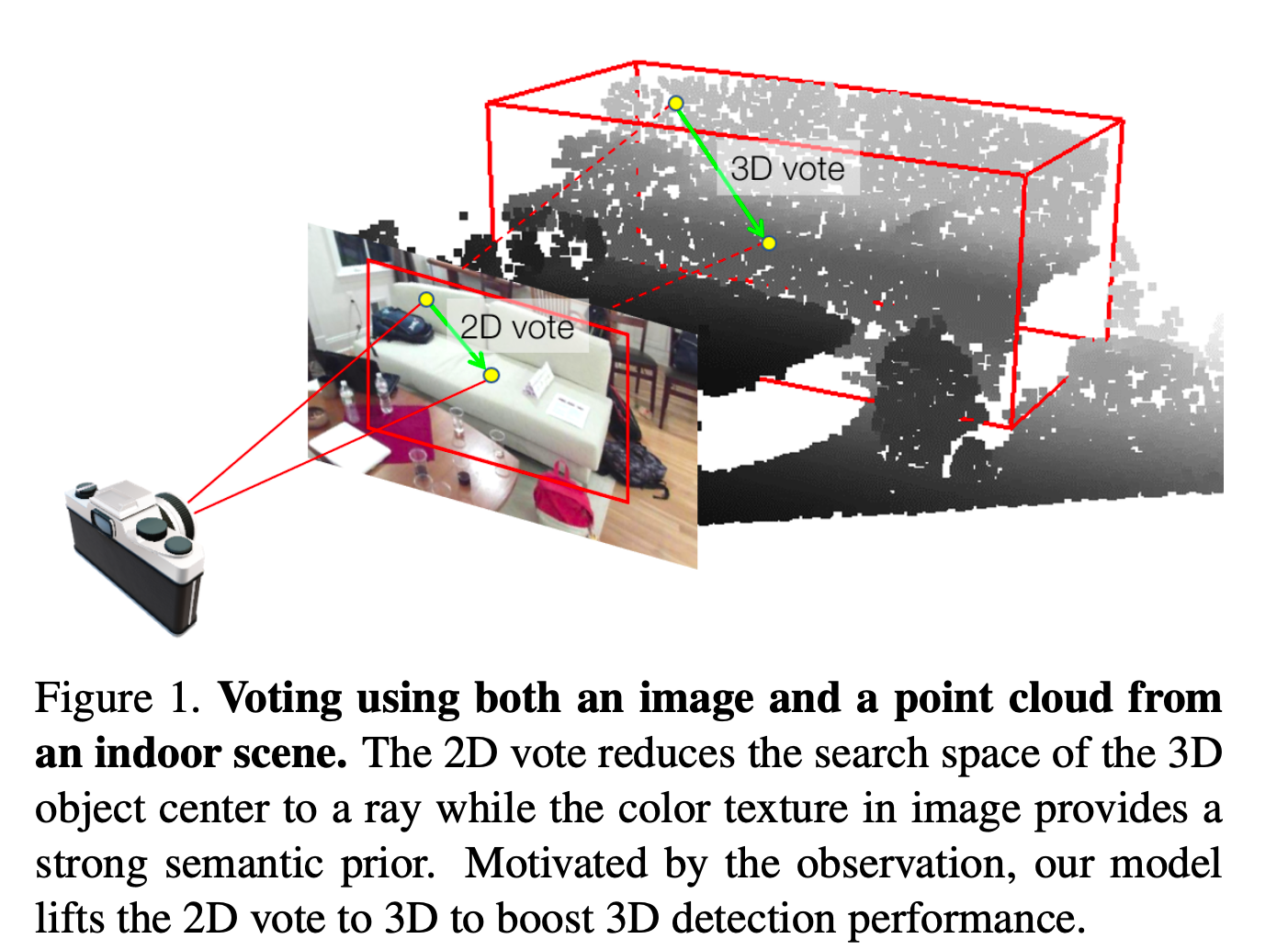
-
Generate image votes
based on a set of candidate boxes from 2D detectors. -
Image vote,
in its geometric part, is simply a vector
connecting an image pixel and the center of the 2D object bounding box
that pixel belongs to (Fig 1) -
To form the set of boxes given an RGB image,
apply 2D detector (e.g. Faster R-CNN) pretrained on
color channels of the RGB-D dataset.
Detector outputs the M most confident bounding boxes
and their corresponding classes. -
Assign each pixel within a detected box
a vote to the box center. -
Pixels inside multiple boxes are given multiple votes,
and those outsid on any box are padded with zeros.
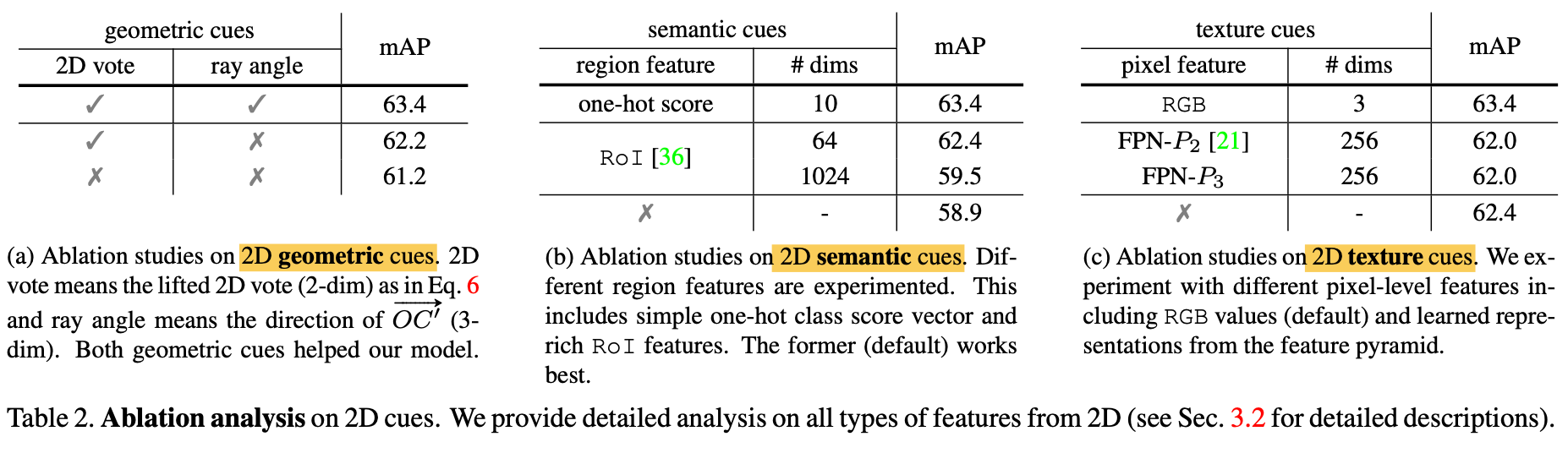
Geometric cues: lifting image votes to 3D
-
Translational 2D votes provide
useful geometric cues for 3D object localization. -
Given camera matrix,
2D object center in the image plane
becomes a ray in 3D space
connecting the 3D object center and the camera optical center (Fig1)
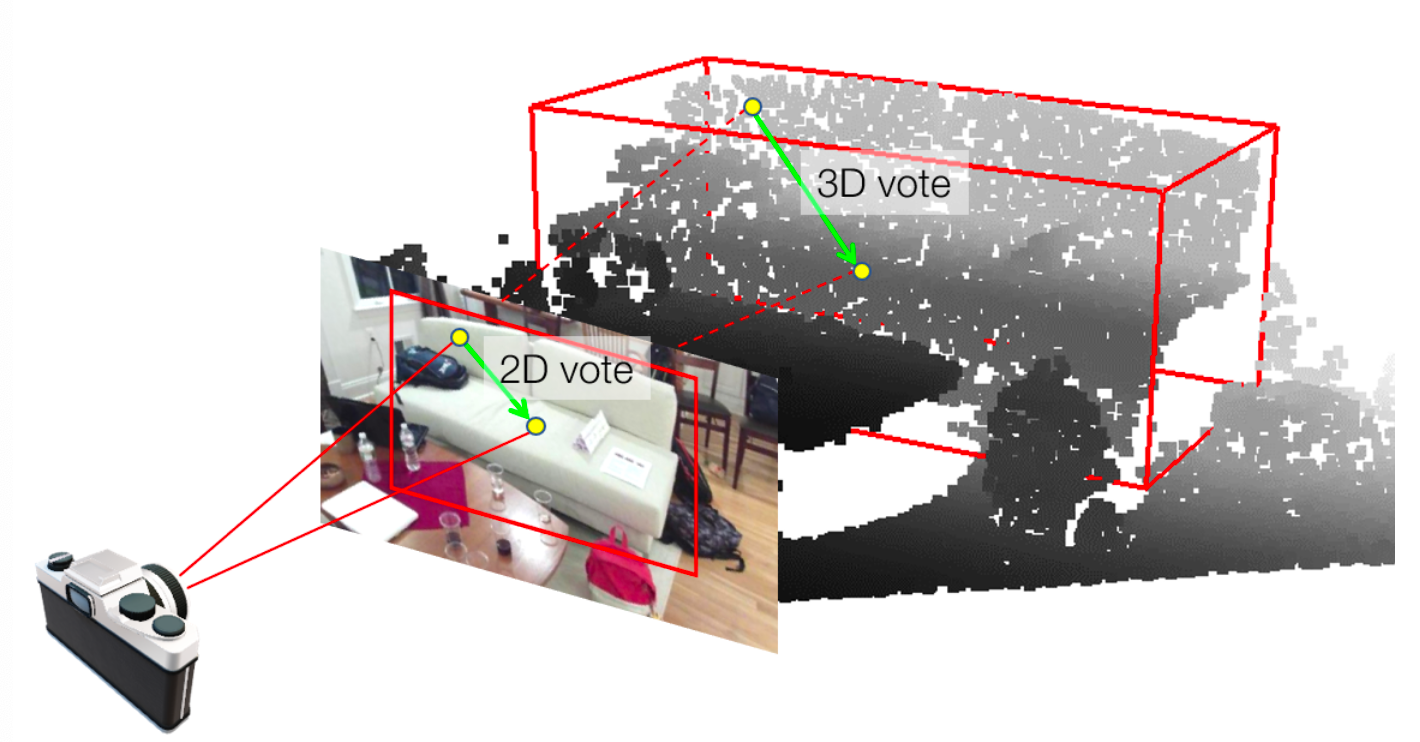
Adding this info to a seed point
can effectivle narrow down the 3D search space
of the object center to 1D
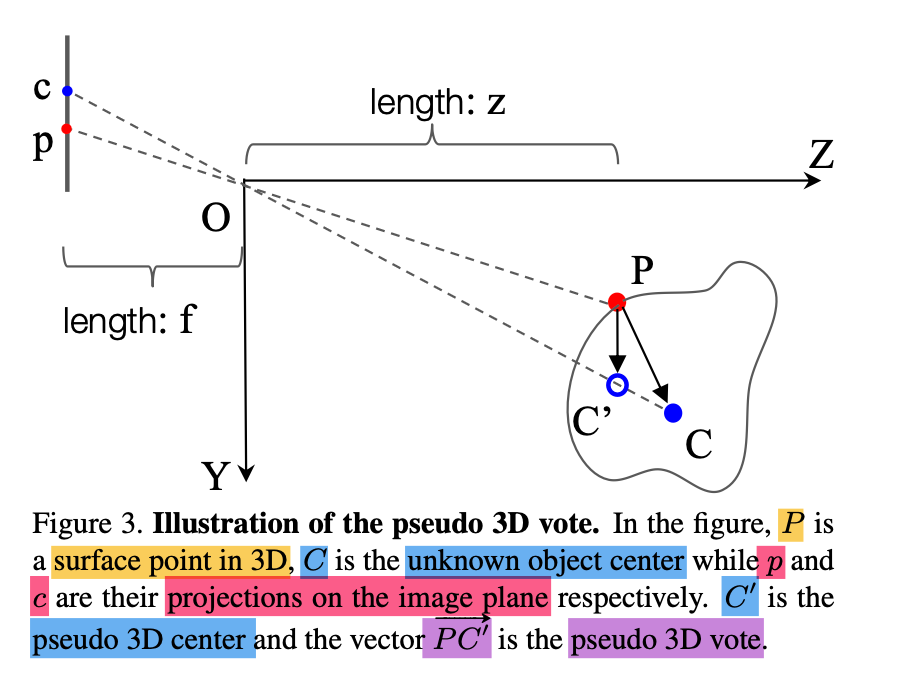
- As shown in Fig 3,
given an object in 3D
with its detected 2D bounding box
in the image plane,
A point P on the object surface
is associated with
its projected point p in the image place.
hence knowing the 2D vote to the 2D object center c,
we can reduces the search space
for 3D center to a 1D position on the ray OC.
-
P = (x1, y1, z1) in the camera coordinate,
p = (u1, v1), c = (u2, v2) in the image plane coordinate,
we seek to recover the 3D object center C = (x2, y2, z2)
(voring target for the 3D point P). -
True 3D vote from P to C is:
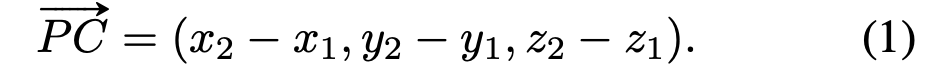
-
2D vote, (assuing a simple pin-hole camera with focal length f.
can be written as)
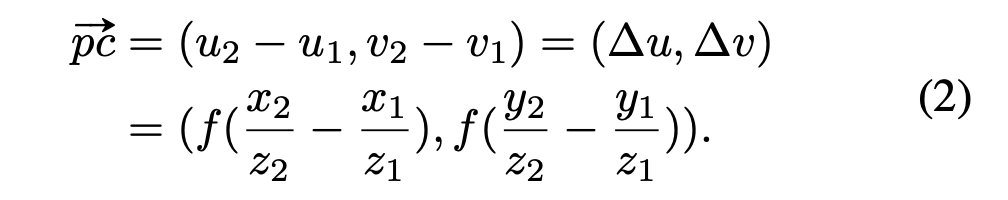
-
Further assume depth of the surface point P
is similar to the center point C.
Then, given z1 ~= z2, compute vector PC'
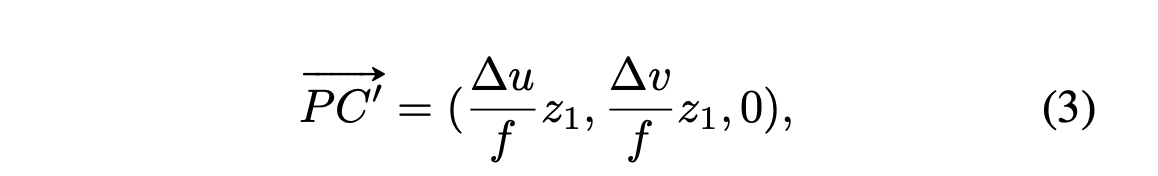
which paper refers to a pseudo 3D vote,
as C' lies on the ray OC
and is in the proximity of C.
This pseudo 3D vote provides info about
where the 3D center is relative to the point surface point P. -
To compensate for the error
caused by the depth approximation (z1 ~= z2),
paper passes ray direction as extra info to the 3D surface point. -
Error caused by the approximated depth, can be expressed by
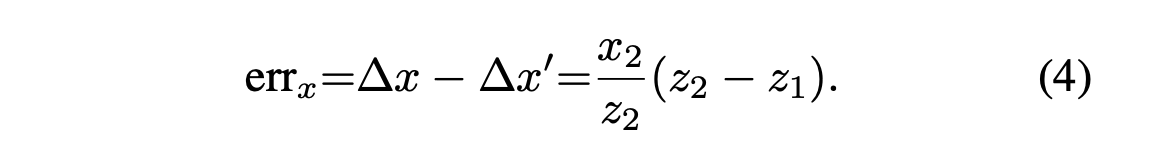
-
Hence, if input the direction of the ray OC: (x2/z2, y2/z2),
network should have more info
to estimate the true 3D vote
by estimate the depth difference
Δz = z2 - z1. -
As we don't know the true 3D object center C,
we can use the ray direction of OC'
which aligns with OC
after all, where
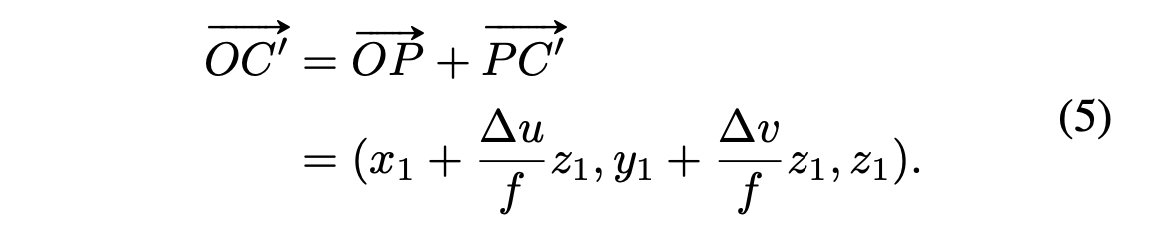
-
Normalizing and concatenating with pseudo vote,
image geometric features
we pass to the seed point P are:
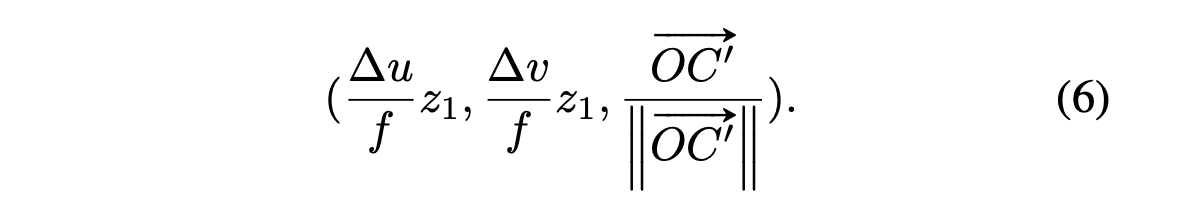
Semantic cues
-
Provide additional region-level features
extracted per bounding vox
as semantic cues for 3D points. -
For all 3D seed points
that are projected within the 2D box,
paper passes a vector
representing that box th the point. -
If a 3D seed point
falls into more than one 2D boxes (i.e, when they overlap),
duplicate the seed point for
each of the overlapping 2D regions (up to max # of K). -
If a seed point is not projected to any 2D box,
simply pass an all-zero feature vector for padding. -
This semantic feature can help to distinguish between classes
that are geometrically simialr.
(such as table vs desk or nightstand vs dresser)
Texture cues
-
RGB images can capture
high-resolution signals
at a dense, per-pixel level in 2D. -
Low-level, texture-rich representations as cues
passed to the 3D seed points
via a simple mapping:
a seed point gets pixel features
from the corresponding pixel of its 2D projection
Feature Fusion and Multi-tower Training
-
With lifted image votes
and its corresponding semantic and texture cues
(K x F' in the fusion block in Fig.2)
as well as the point cloud features
with the seed points K X F, -
each seed point can generate 3D votes and aggregate them
to propose 3D bounding boxes -
Paper follows the gradient blending strategy
to weight the gradient for different modality towers
(by weihting the loss functions) -
In paper's multi-tower formulation, as shown in Fig 2,
Three towers taking seed points
with three sets of features:
point cloud feature only,
image features only
and joint features.
-
Each tower has same target task of detecting 3D objects
but they each have separate 3D voting and box proposal network params
as well as separate losses. -
Final training loss is the weighted sum of three detection losses:
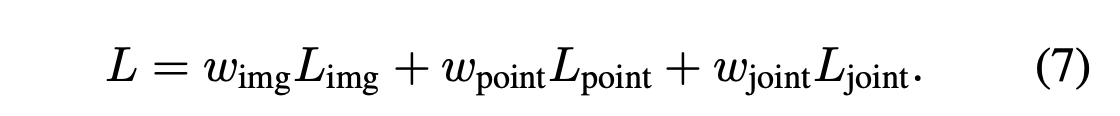
👨🏻🔬 Experimental Results
- Dataset
SUN RGB-D: single-view RGB-D dataset for 3D scene understanding.
Comparing with SOTA Methods
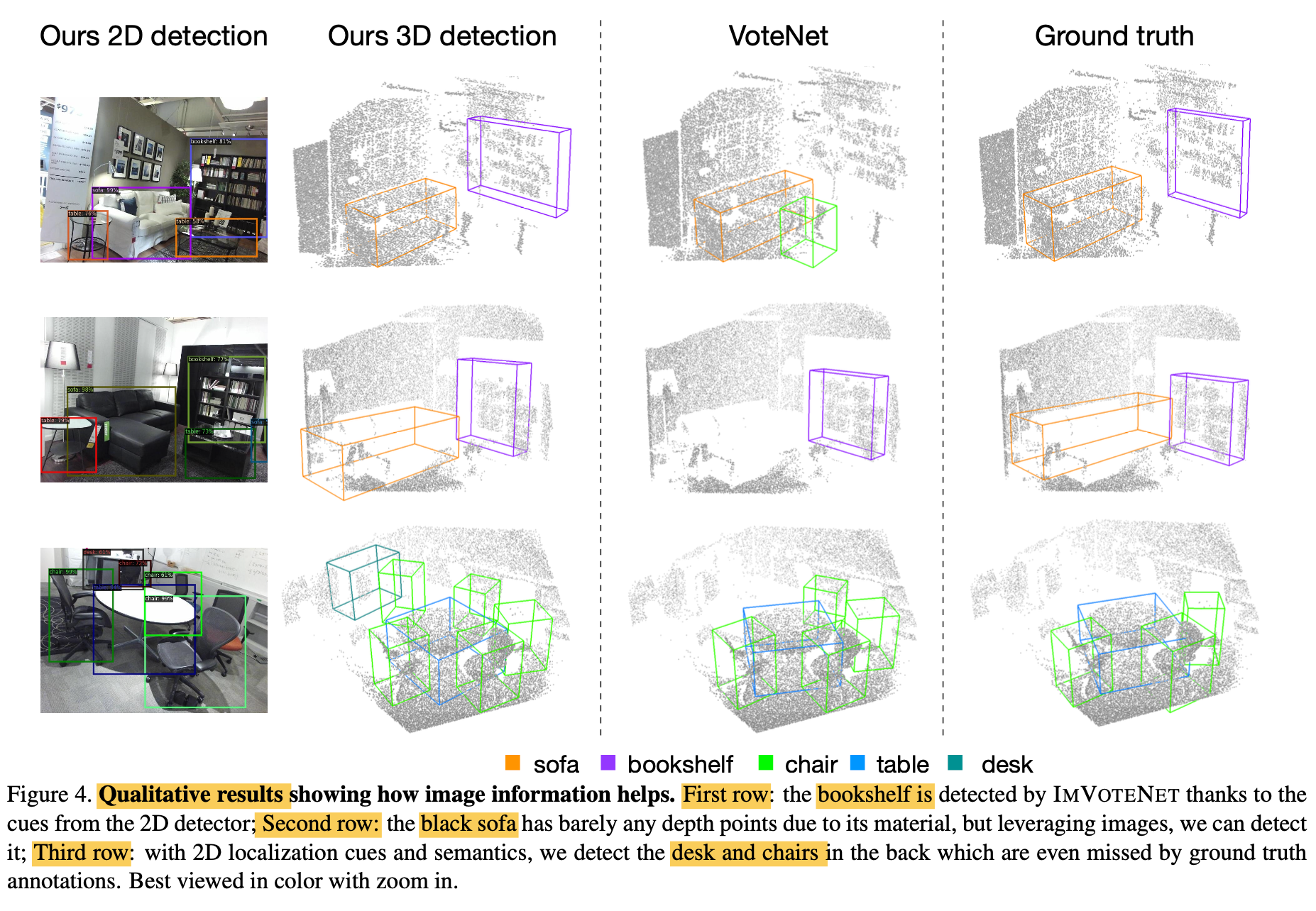
Qualitative Results
Ablation Analysis Experiments
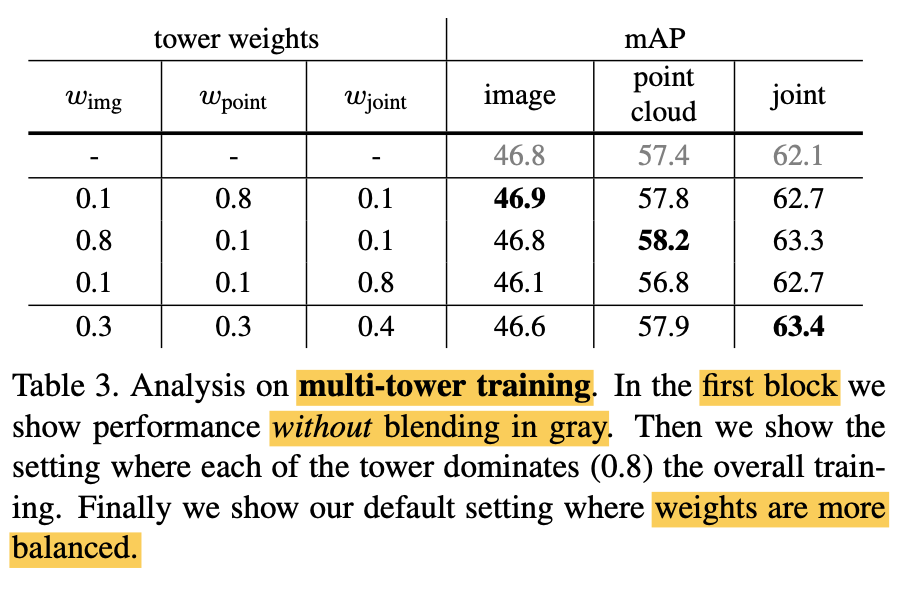
Gradient blending
- Table 3 studies how tower weights affect the gradient blending training.
- It is interesting to note that
even with just the image features (1st row, 4th column)
i.e. the pseudo votes and semantic/texture cues from the images,
already outperform several previous methods,
showing the power of fusion and voting design.