🚀 Motivation
-
Lack of 3D understating of generative neural networks by introducing a persistent 3D feature embedding for view synthesis.
-
While Techniques based on explicit 3D representations in the form of occupancy grids, signed distance fields, point clouds, ormeshts handle the geometric reconstruction task well,
They are not directly applicable to the synthesis of realistic imagery, since it is unclear how to represent color information at a high resolution.
🔑 Key Contributions
-
This paper proposes DeepVoxels, a learned representation that encodes the view-dependent appearance of a 3D scene, without having to explicitly model its geometry.
-
This approach is based on a Cartesian 3D grid of persistent embedded features that learn to make use of the underlying 3D scene structure.
-
Explicit occlusion reasoning based on learned soft visibility ➡️ that leads to higher-quality results and better generalization to viewpoints.
-
Diferentialble image formation to enforce perspective and multi-view geometry during training.
-
Training without requiring 3D supervision.
⭐ Method
-
The goal of the DeepVoxels approach is to condense posed input images of a scene into a persistent latent representation, without explicitly having to model its geometry.
-
DeepVoxels is a viewpoint-invariant, persistent and uniform 3D voxel grid of features.
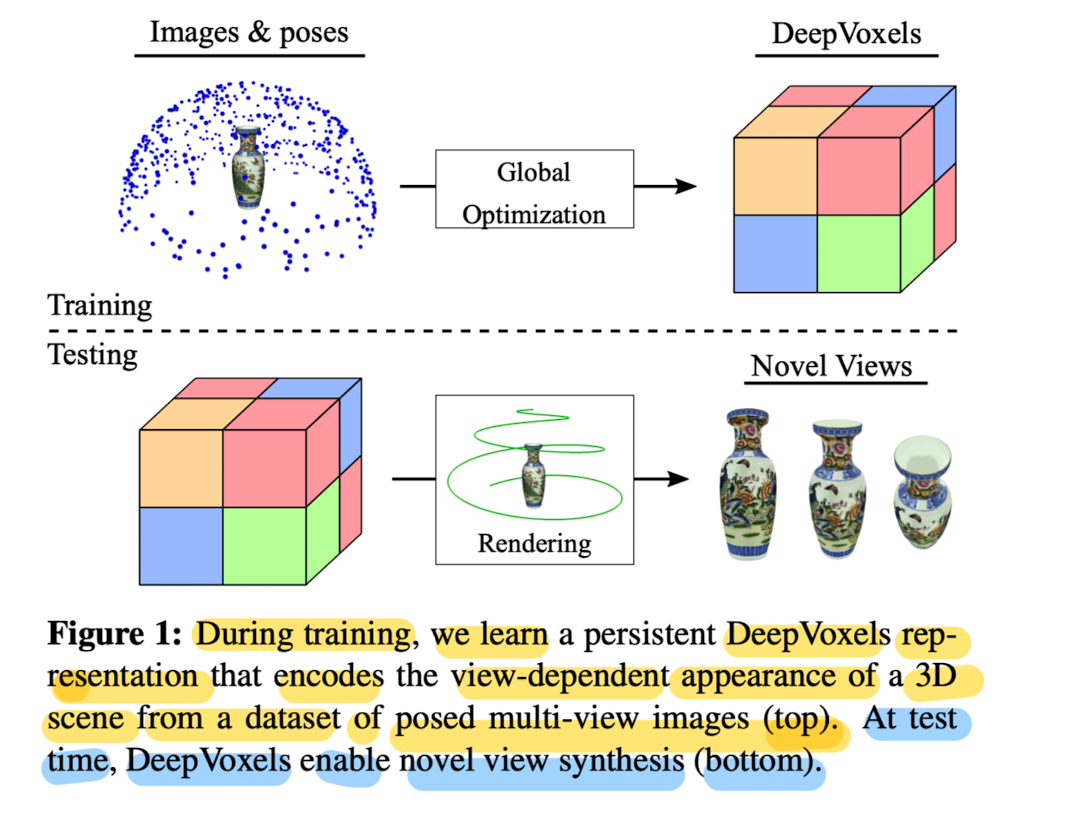
-
This paper's approach is a hybrid 2D/3D one,
in that it learns to represent a scene in a Cartesian 3D grid of persistent feature embedding that is projected to the target view's canonical view volume,
and processed by a 2D renering network. -
The underlying 3D grid enforces espatial structure on the learned per-voxel code vectors.
-
The final output image is formed based on a 2D network thath receives the perspective re-sampled version of this 3D volume,
i.e, the canonical view volume of the target view, as input. -
3D part: takes care of spatial reasoning,
2D part: enbales fine-scale feature synthesis.
Training Corpus


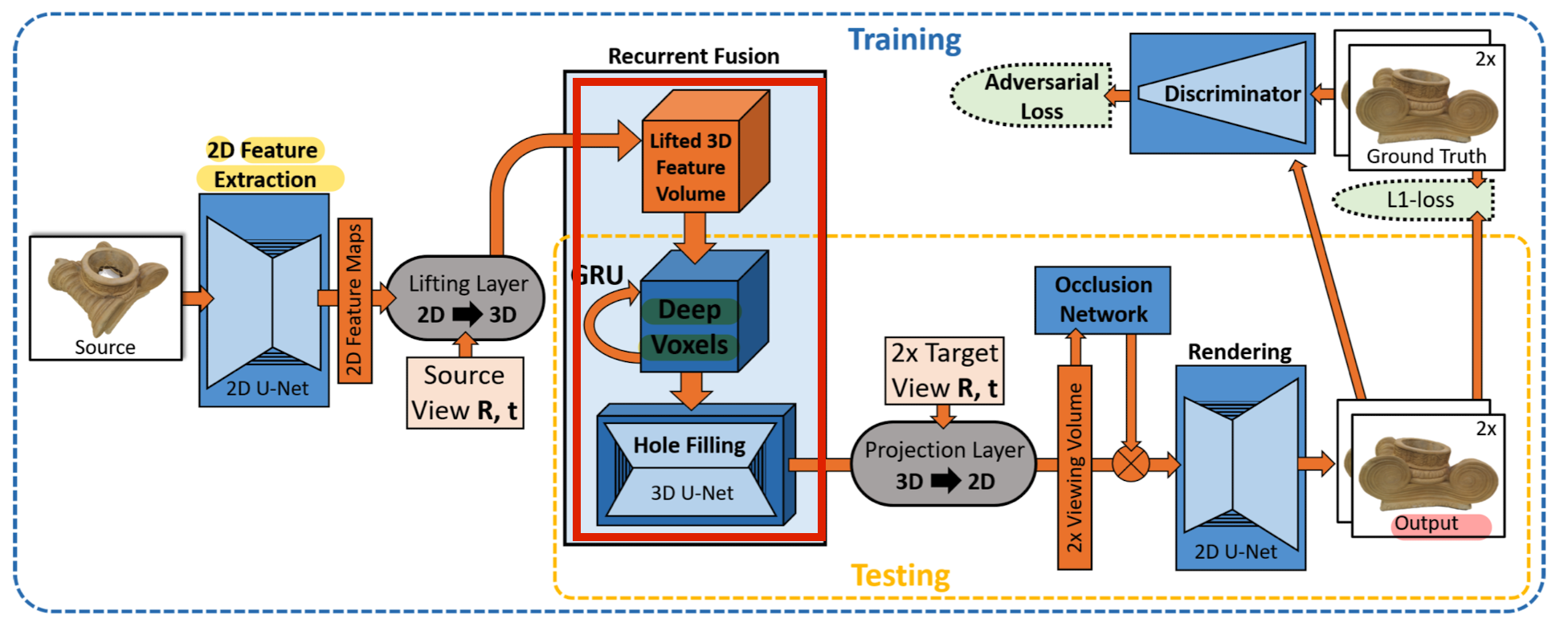
Architecture Overview
- On a high level, it can be ssen as an encoder-decoder based architecture with the persistent 3D DeepVoxels representation as its latent space.
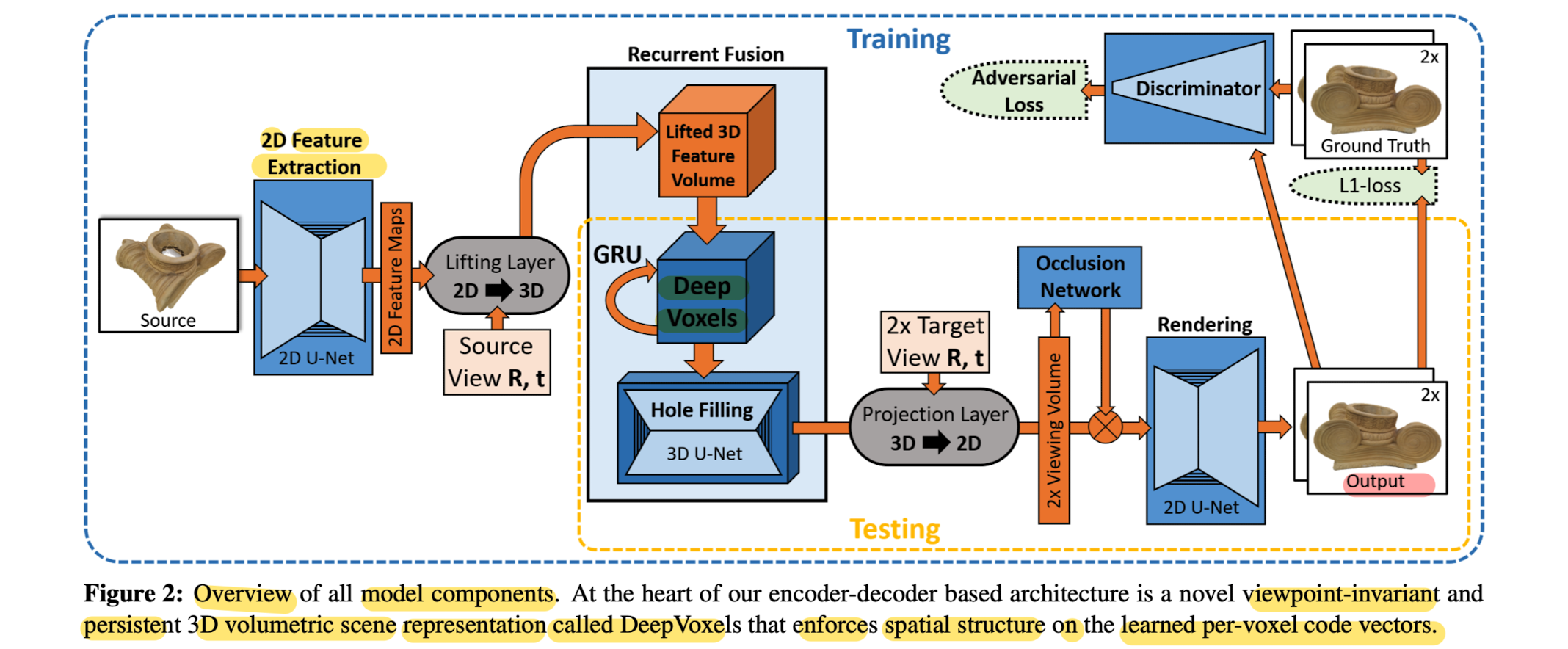
- During training, feed a source view Si to the encoder
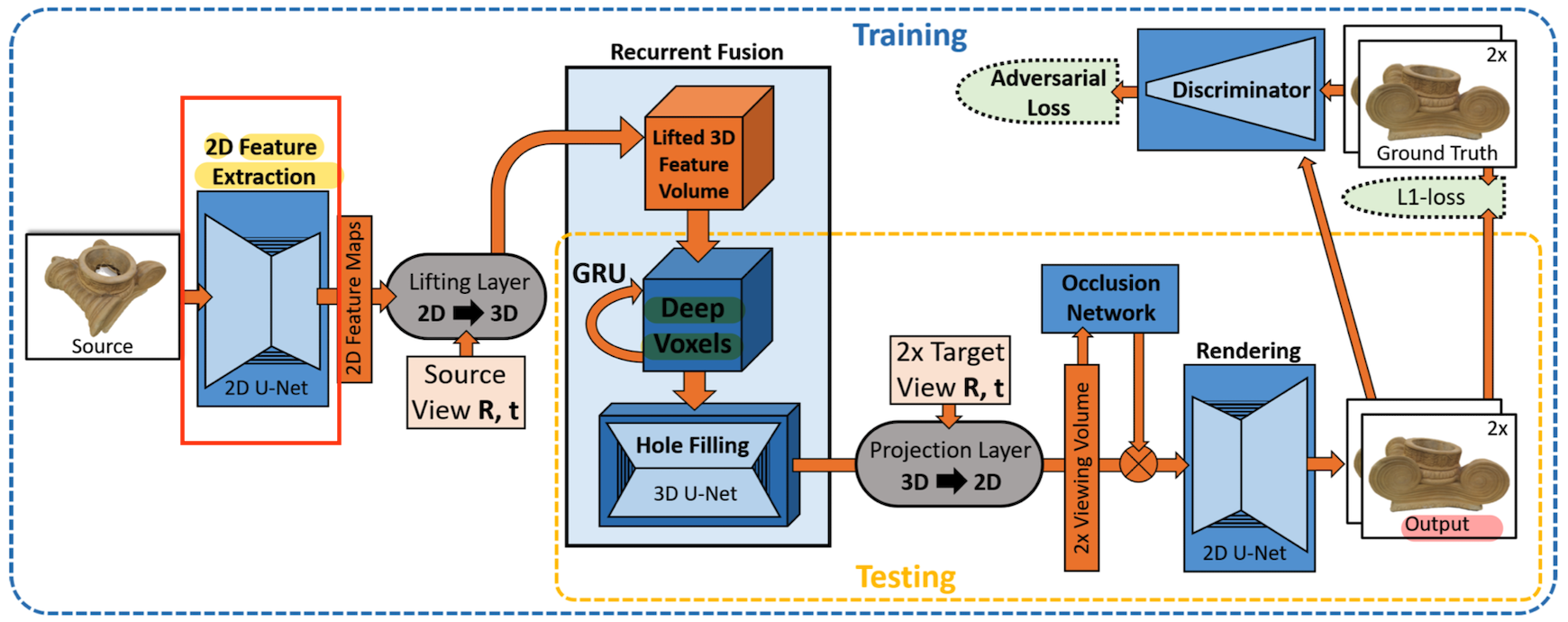
and try to predict the target view Ti . - 1) Feature Extraction
extract a set of 2D feature maps from the Si using a 2D fature Extraction network.
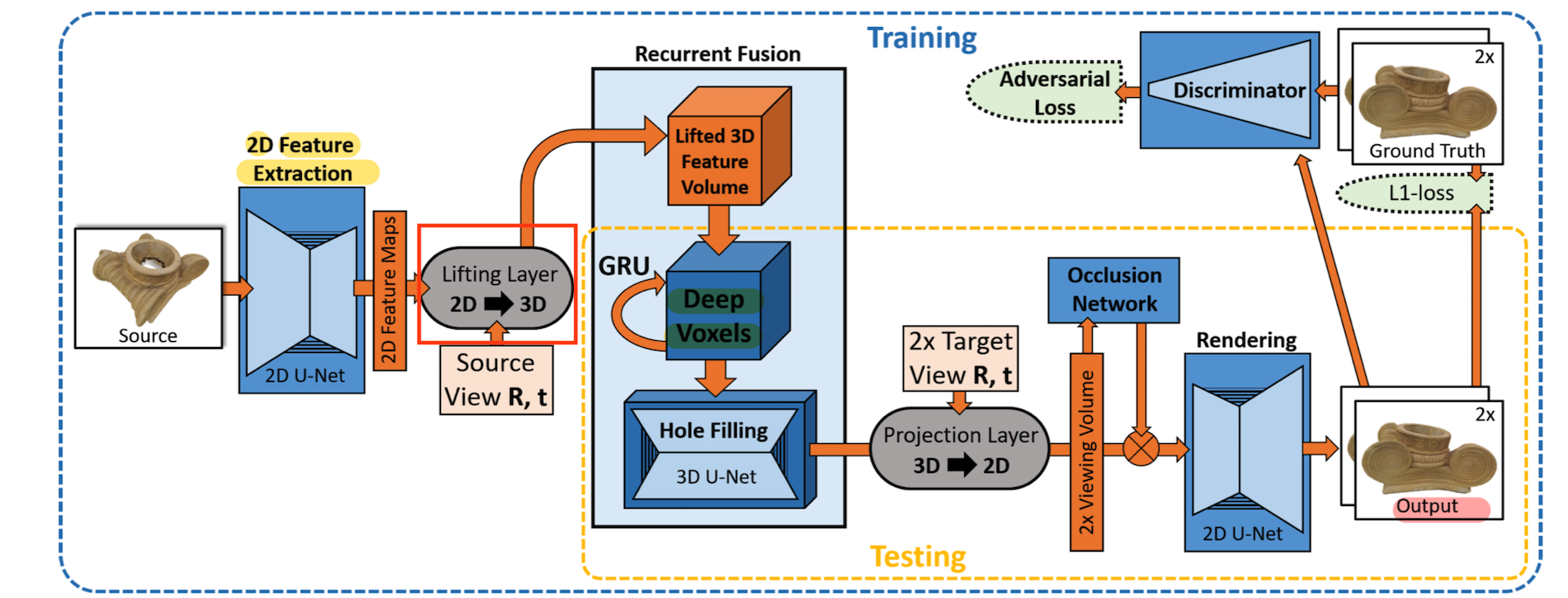
- 2) Lifting 2D Features to 3D Observations
To lean a view-independent 3D feature representation, lift image feature to 3D based on differentiable lifting layer.
- 3) Integrating Lifted Features into DeepVoxels
Lifted 3D feature volume is fused with persistent DeepVoxels scene representation using a GRU(gated recurrent unit).
Specifically, the persistent 3D feature volume is the hidden state of a GRU.
After Feature Fusion, the volume is processed by a 3D fully convolutional network.
Deatil about GRU
✅ The goal of GRU is to incrementally fuse the lifted features and the hidden state during training,
such that the bset persistent 3D volumetric feature representation is discovered.
✅ The GRU implement the mapping
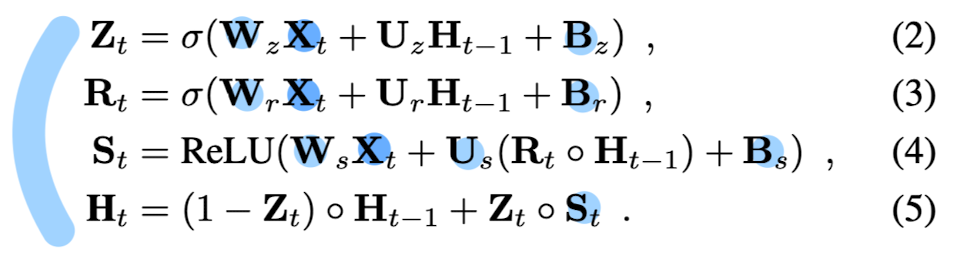
🔥 Zt = update gates
🔥 Rt = reset gates (per-voxel reset values)
H(t-1) = previous hidden state
Xt: lifted 3D feature volume of current timestep t
W and U: trainable 3D convolution weights
B: trainable tensores of biases.
🔥 St: tensor of new feature proposals
➡️ computed for the current time step t based on H(t-1), Rt, and Xt
Us and Ws: single 3D convolutional layers
🔥 Ht: new hidden state, the Deep Voxels representation for the current time step
➡️ computed by H(t-1) (per-voxel linear combination of old state) & St (new Deep Voxel proposal)
- 4) Projection Layer
Volume is then mapped to the camera coordinate systems of the 2 target views (T0i, T1i) via a differentiable projection layer,
resulting in canonical view volume.
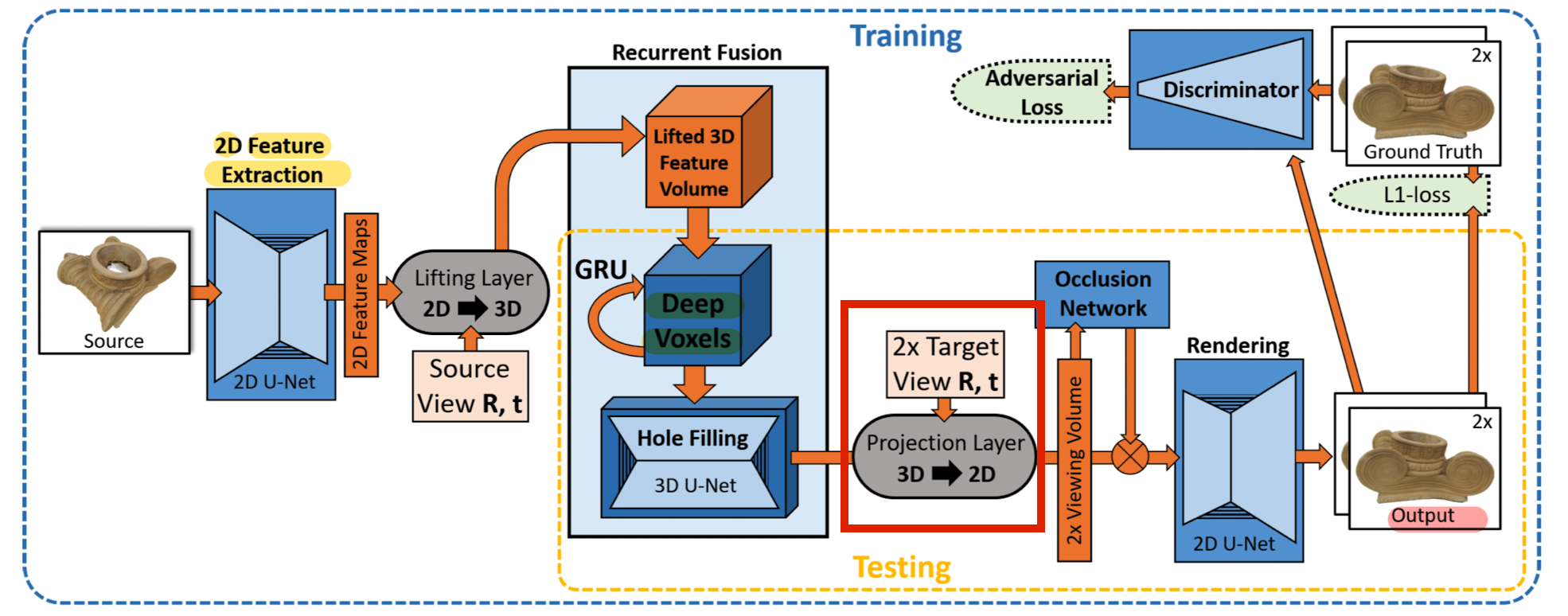
- It maps the 3D code vectors to the canonical coordinate system of the target view.
- 5)Occlusion Module
Occlusion network operates on the canonical view volume
to reason about voxel visibility and flattens the view volume to a 2D view feature map.
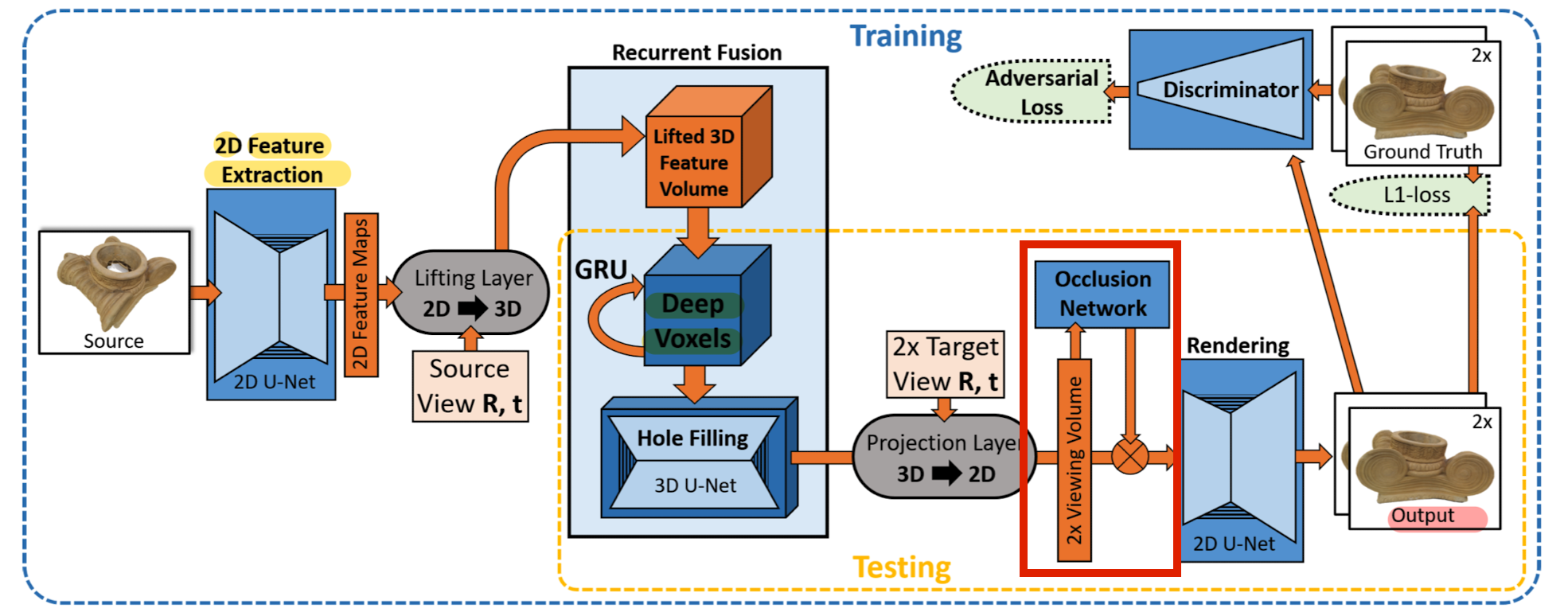
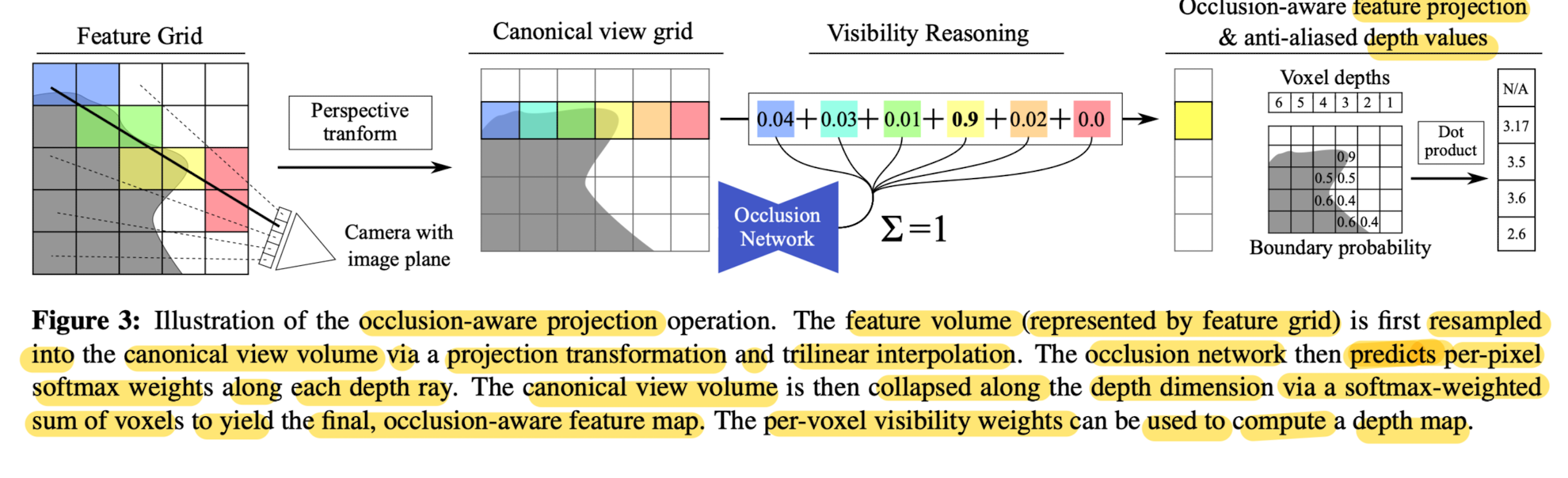
- 6) Rendering and Loss
Finally, a learned 2D rendering network forms the two final output images.
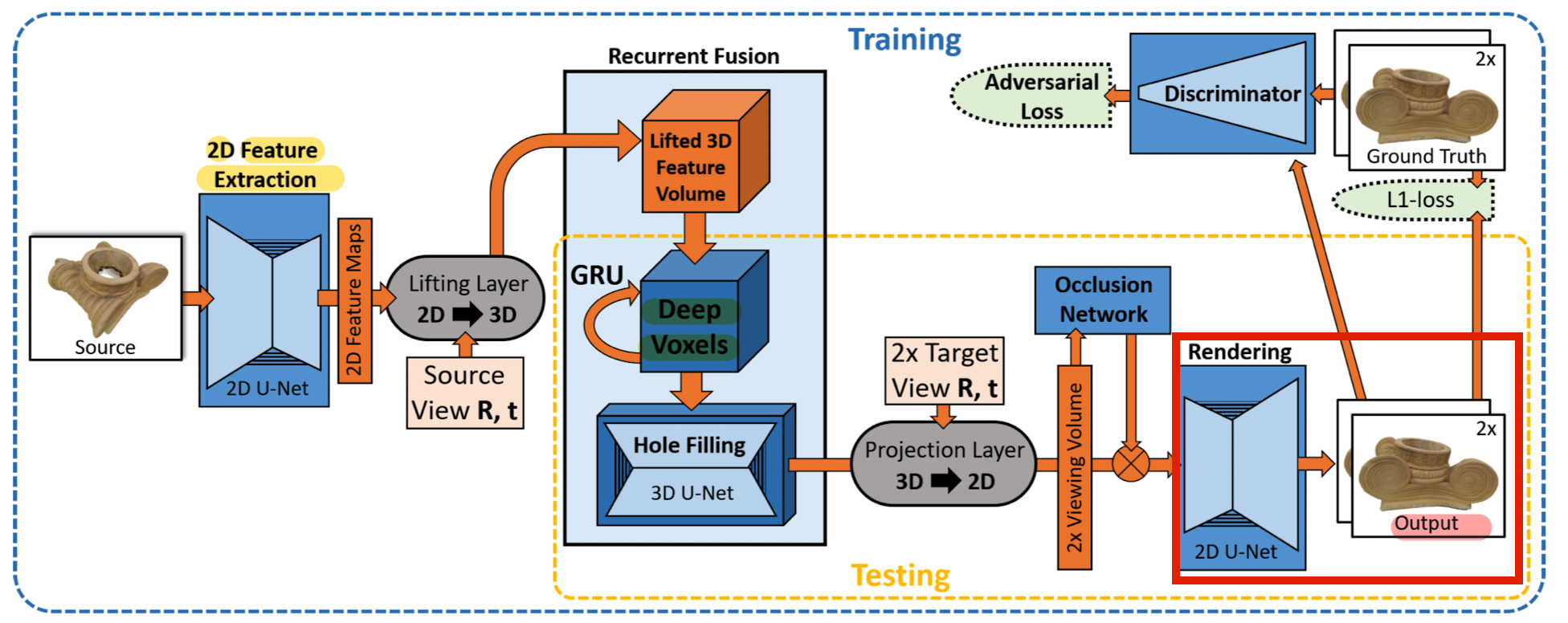
This network is trained end-to-end, without the need of super vision in th 3D domain,
by a 2D re-rendering loss that enforces that the predictions match the target views.
👨🏻🔬 Experimental Analysis
Object-specific Novel View Synthesis
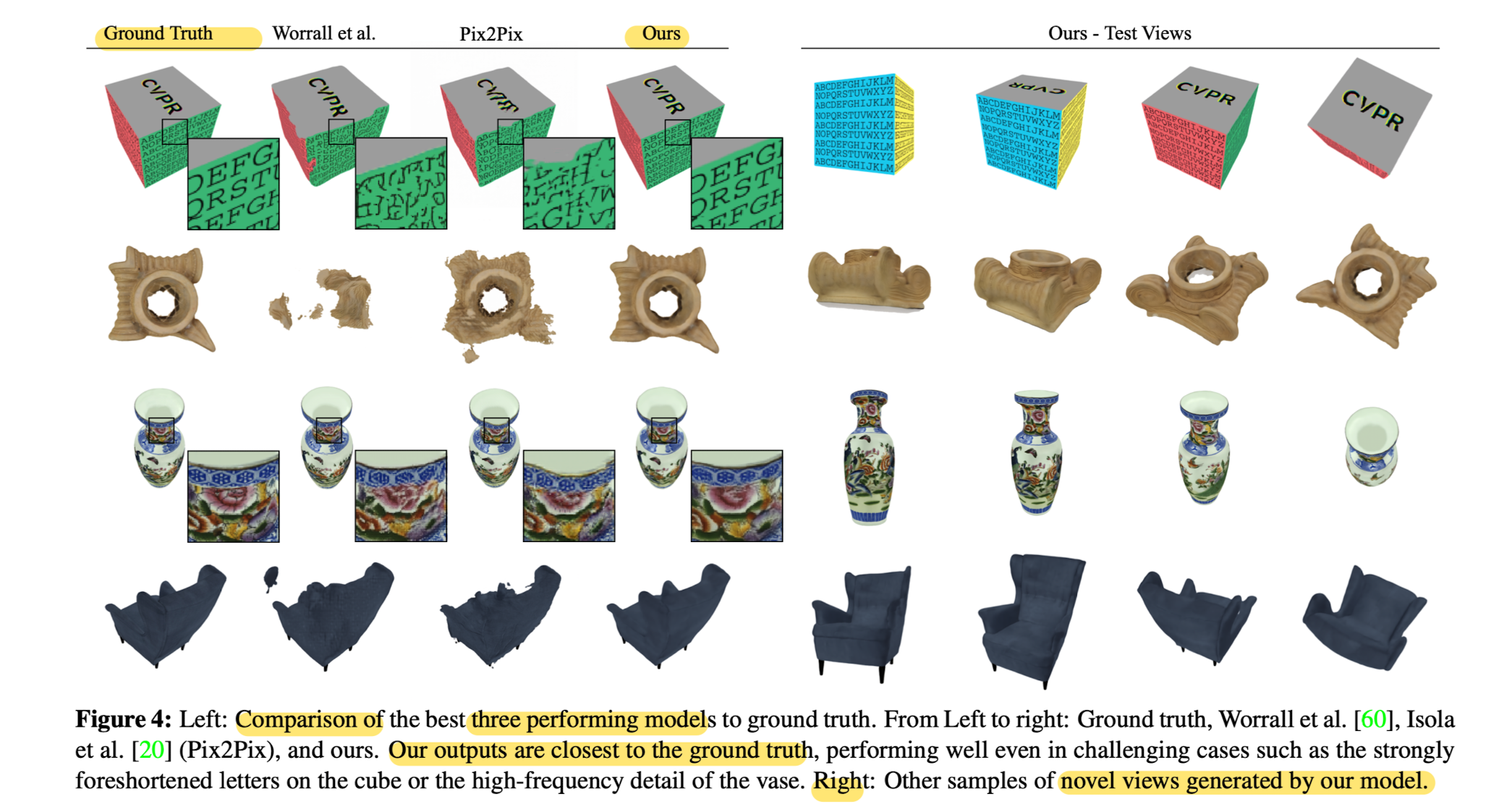
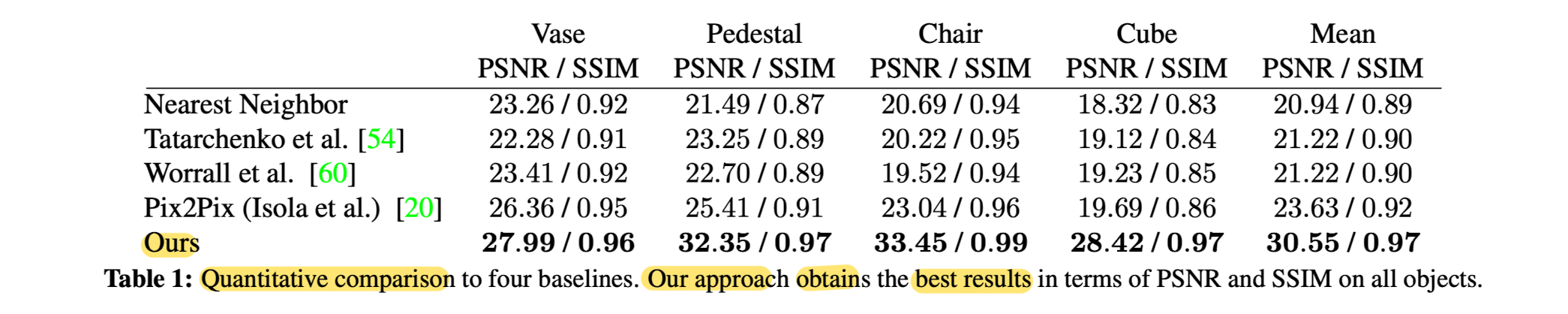
Qunantitavie Comparison to Baselines
- Lacking occlusion reasoning, depth maps are not made explicit.
Model may thus parameterize latent spaces that do not respect multi-view geometry.
This increases the risk overfitting, which is observed empirically. - While the proposed voxel embedding is very parater efficient.
Occlusion Reasoning and Interpretability
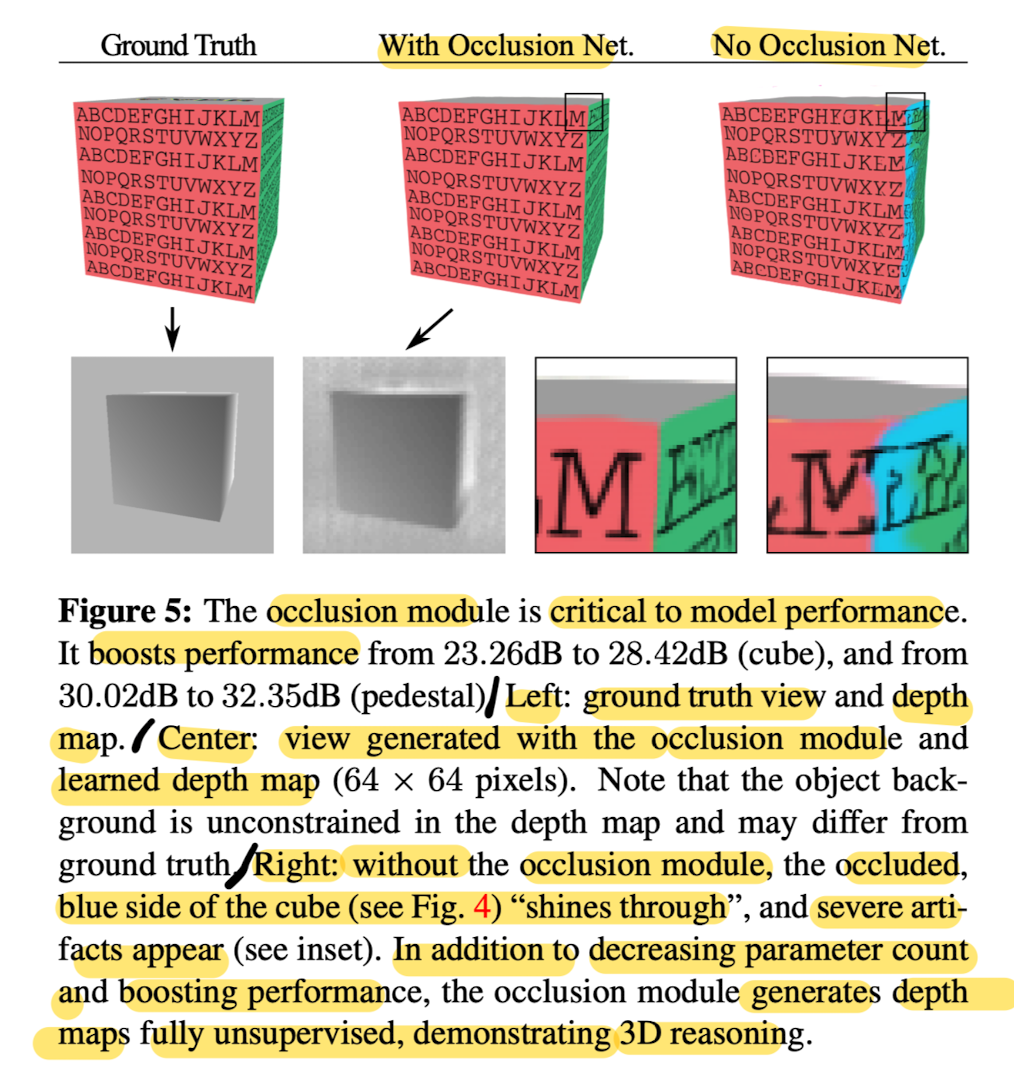
- Essential part of the rendering pipeline is the depth test.
Similarly, Rendering network ought to be able to reason about occlusions when regressing the output view. - A naive approach might Flatten the depth dimension of the canonical camera volume and subsequently reduce the number of features using a series of 2D convolutions.
- This leads to a drastic increas in the number of network parameters.
- At training time, this allows the network to combine features from several depths equally to regress on pixel colors in the target view.
- At inference time, this results in severe artifacts and occluded parts of the object "shining through" Fig5
- ✅ Paper's occlusion network forces learning to use a softmax-weighted sum of voxels along each ray,
which penalizes combining voexls from several depths. - As a result, novel views generated by the network with the occlusion module perform much more favorabley at test time Fig 5
- The depth map generated by the occlusion model demonstrates that the proposed model indeed learns the 3D structure of the scene.
- This paprer nots that the depth map is learned in a fully unsupervised manner
and arises out of the pure necessity of picking the most relevant voxel.
Novel View Synthesis for Real Captures
- Gnererally, results are of high qaulity, and only details that are significantly smaller than a single voxel.

🤔 Limitations
- Employed 3D volume is memory inefficient, thus this paper have to trade local resolution for spatial extend.
✅ Conclusion
- This paper proposes a 3D structured scene representation, called DeepVoxels,
that encodes the view-dependent appearance of a 3D scene using only 2D supervision. - First step towards 3D structured neural scene representations
and the goal of overcoming the fundamental limitations of existing 2D generative models
by introducing native 3D operations into the network.

잘 봤습니다. 좋은 글 감사합니다.