🚀 Motivations
-
In generative modeling of 3D shapes, the shapes produced by SOTA methods still fall far short in terms of visual quality.
-
This is reflected by a combination of issues including low-resolution outputs, overly smoothed or discontinuous surfaces, as well as a variety of topological noise and irregularities.
⭐ Methods
- This paper introduces an implicit field decoder, called IM-NET, for shape generation, aimed at improving the visual quality of the generated shapes.

- It takes a point coordinate (x, y, z), along with a feature vector encoding a shape, and outputs a value which indicates whether the point is outside the shape or not.
- IM-NET follows an encoder which outputs the shape featue vectors and then return an implicit field to define an output shapes.
- Decoder output can be sampled at any resolution and is not limited by the resolution of the training shapes.
- Concatenate point coordinates with shape features, feeding both as input to implicit decoder, which learns the inside/outside status of any point realtive to a shape.
-
IM-NET learns shape boundaries (Fig 3)
-
IM-NET can input an arbitrary 3D point and learn a continuous implicit field without discretization.

-
This paper embed IM-NET into several contemporoary analysis and synthesis frameworks, including autoencoders(AEs) variational autoencoders(VAEs), and generative adversarial networks(GANs), by replacing the decoders employed by current approachis with IM-NET.
Implicit decoder and shape generation
- For a closed shape, this paper defines the inside/outside field F of the shape by taking the sign of its signed distance field.
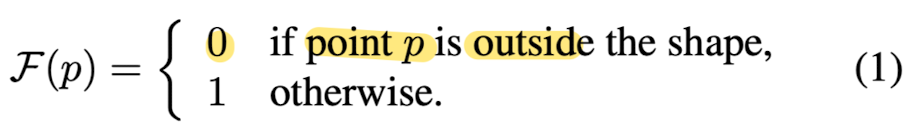

Network structure of IM-NET
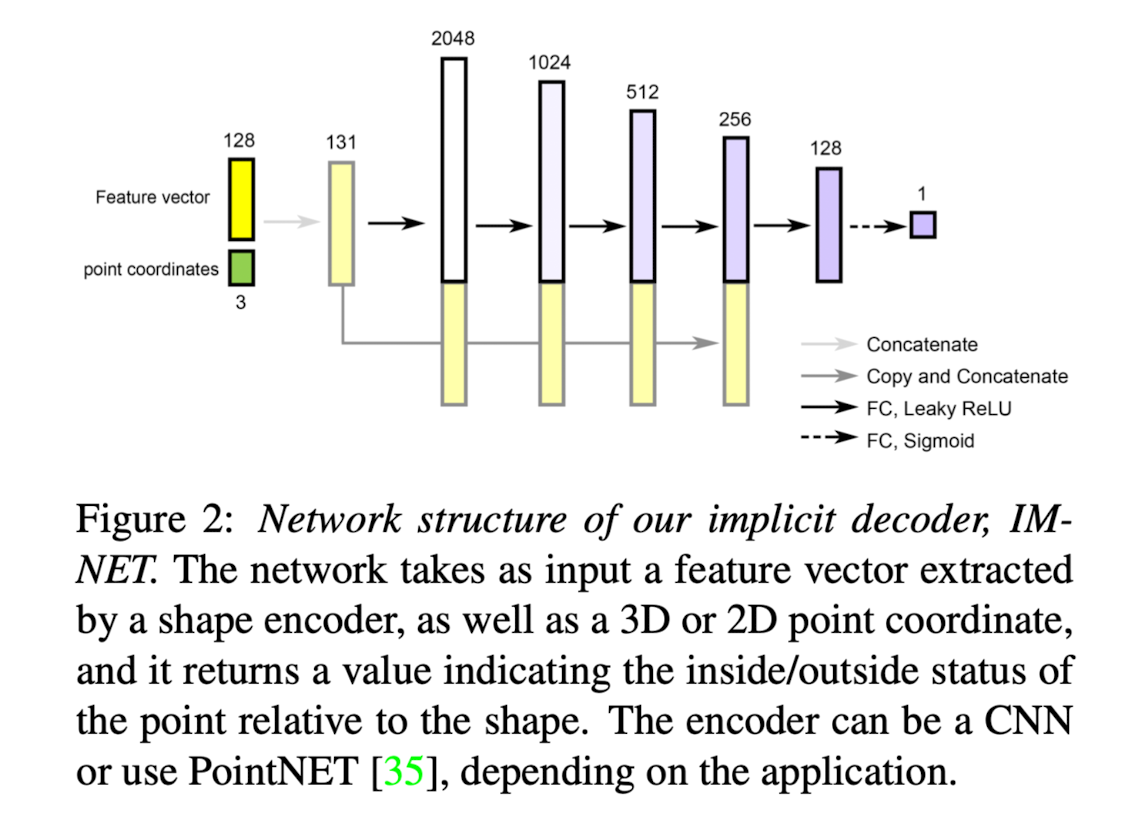
- skip connections make the learning progress faster in the experiments.
- The loss function is a weighted mean squared error between ground truth labels and predicted labels for each point. Lset S be a set of points sampled from the targe shape,
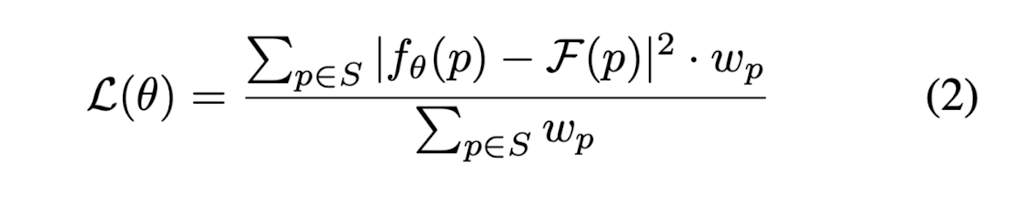
👨🏻🔬 Experimental Results
- Dataset: 256^3 vowlized and flood filled 3D models from ShapeNet Core dataset(v1)
- This paper first used Marching Cubes to obtain meshes from the 256^3 voxelized models, then use Poisson-disk Sampling to obtain 10000 points.
Auto-encoding 3D Sahpes
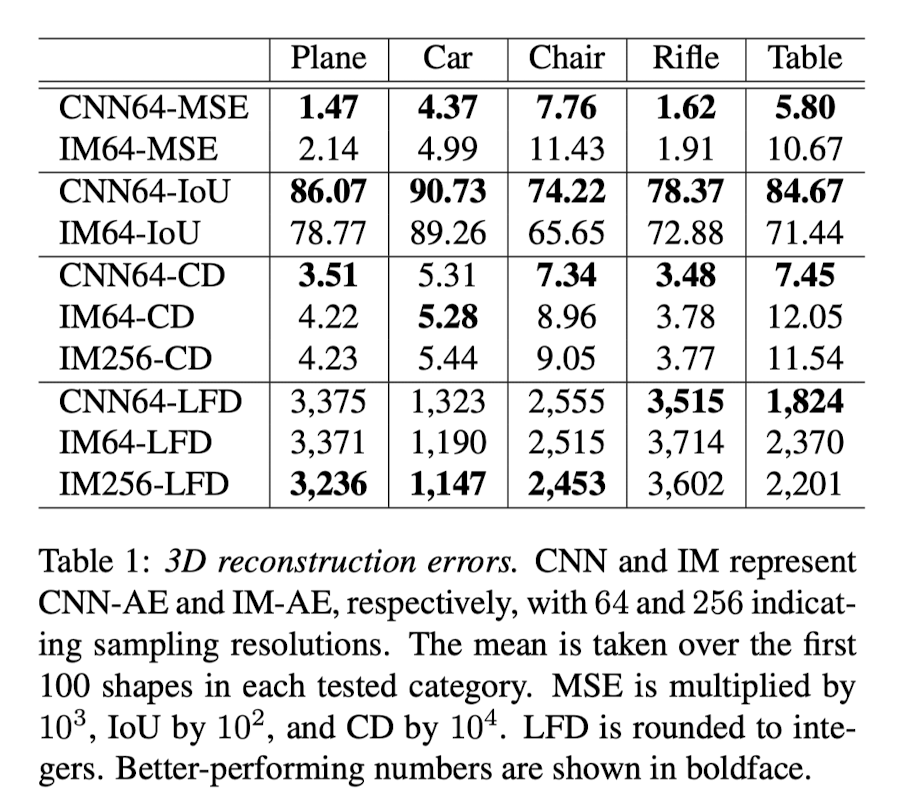
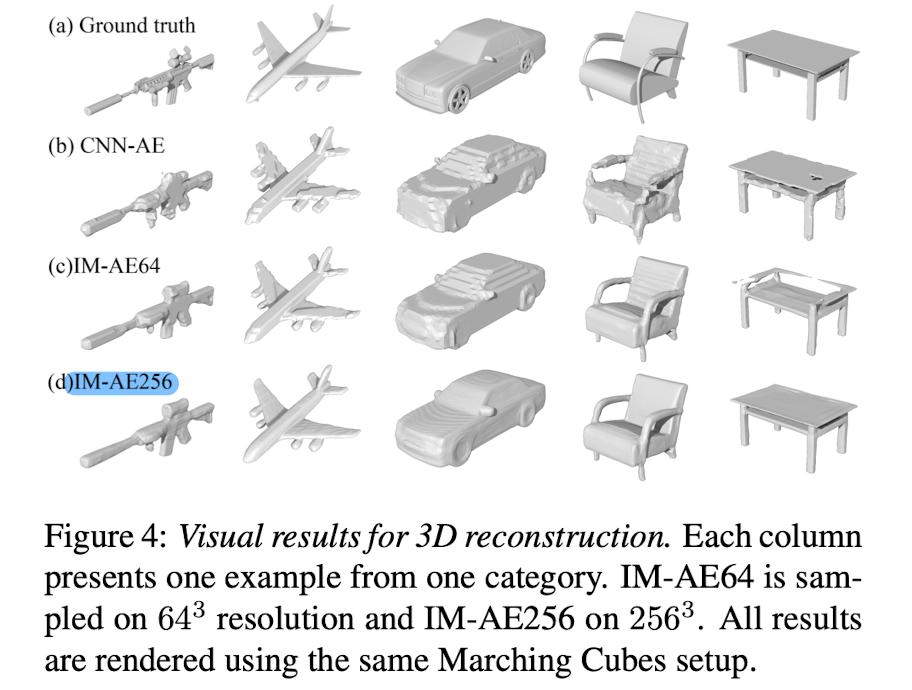
- Although CNN-AE beats IM-AE in nearly all five catgories in terms of MSE, IOU, and CD,
- Visual examination clearly reveals that IM-AE produces better results, as shown in Fig 4.
- This validates that LFD is a better visual similarity metric for 3D shapes.
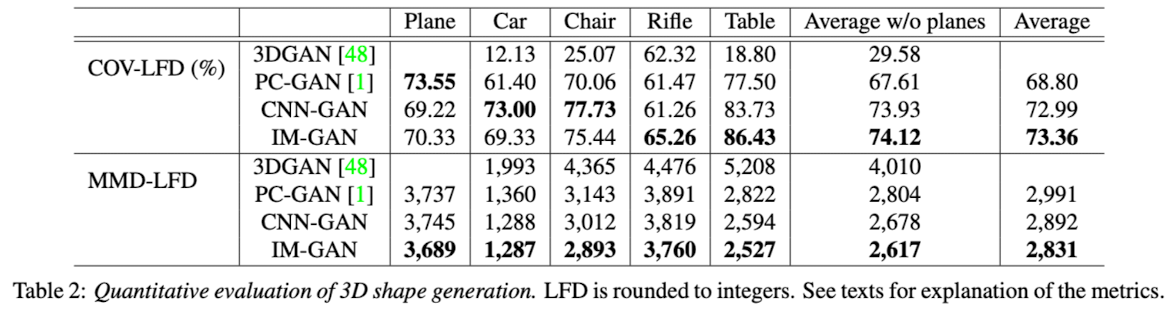
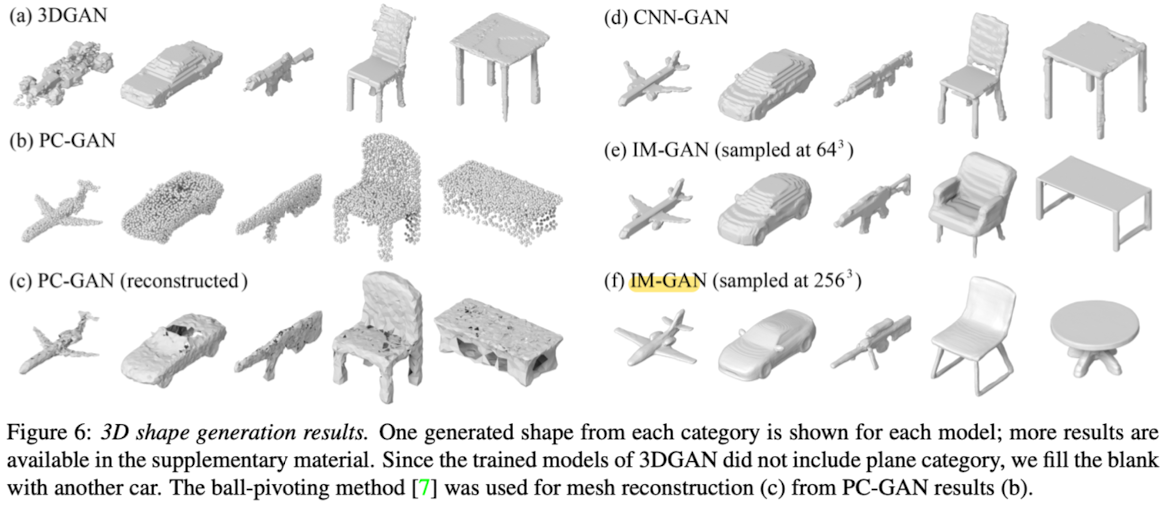
3D shape generation and interpolation
- For evaluating the implicit decoder for generative modeling of 3D shapes, This paper trained latent-GANs on both CNN-AE and IM-AE to obtain CNN-GAN and IM-GAN.
- COV-LFD: For each shape in sample set A, find its closest neighbor in testint set G using LFD, mark "matched". ➡️ calculate the percentage of G marked as "matched" to obtain the converage score(COV-LFD).
- MMD-LFD: This paper matchs every shape in testing set G to the one in smaple set A with the minimum distance and compute the mean distance in the matching as Minimum Matching Distance(MMD-LFD).
- Ideally, a good generative model would have higher COV-LFD and lower MMD-LFD values.
- Overall, IM-GAN performs better on both COV-LFD and MMD-LFD.
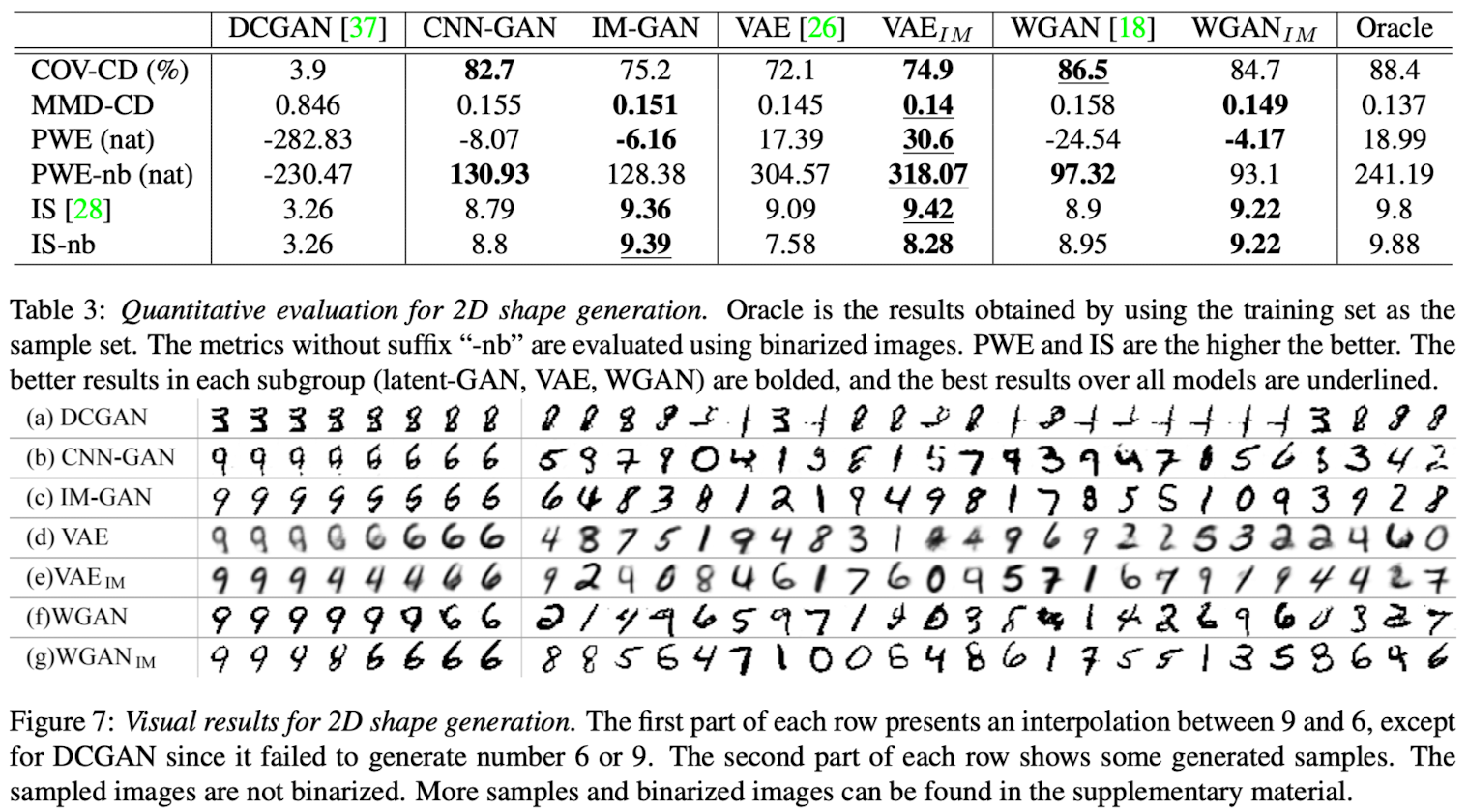
2D shape generation and interpolation.
- This paper conducted experiments on the MNIST dataset to evaluate IM-GAN for 2D shape generation.
- Substitued the CNN decoders of VAE and WGAN with this paper's implicit decoders to obtain VAEIM and WGANIM.
- Inception socre for MNIST(IS) and the log-likelihood produced by PWE(Parzen-window estimate)
- Models equipped with paper's implicit decoder generally perform better.
Single-view 3D reconstruction (SVR)
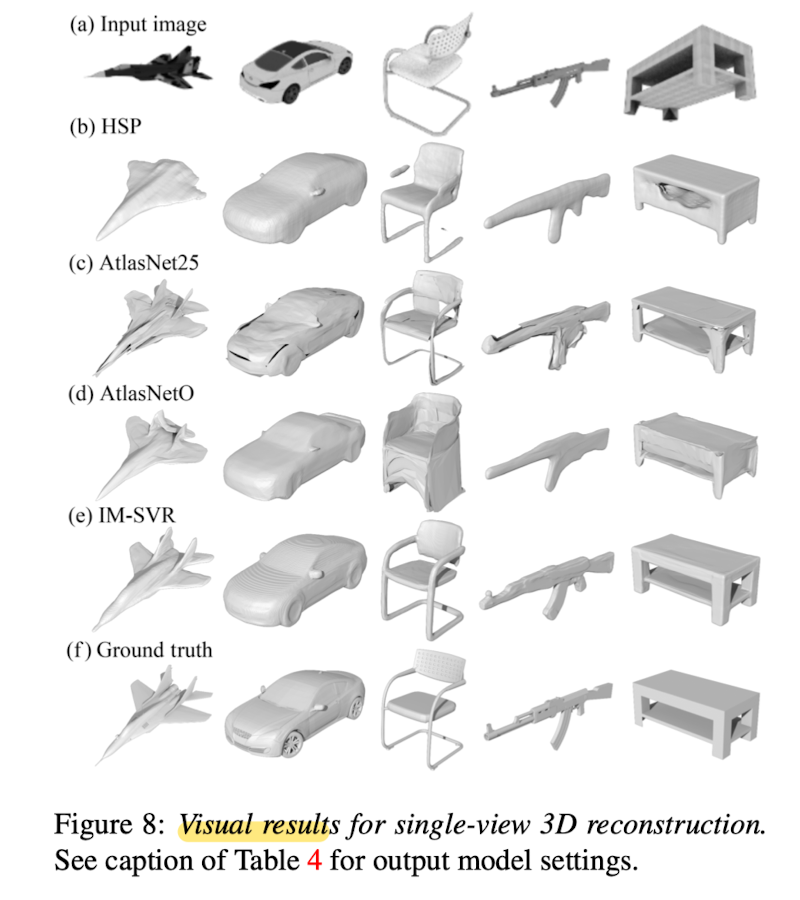
✅ Conclusion
- This paper introduced an implicit field decoder to learn shape boundaries.
- IM-NET can be easily plugged into contemporary deep neural networks for a variety of applications including shape auto-encoding, generation, interpolation, and single-view reconstruction.
- Paper's implicit decoder does lead to cleaner surface boundaires, allowing both part movement and topology changes during interpolation.
