iris data로 PCA를 실습해보자!
1. 필요한 라이브러리 불러오기
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA2. 데이터 불러오기
iris = load_iris()
iris_pd = pd.DataFrame(iris.data, columns=iris.feature_names)
iris_pd['species'] = iris.target
iris_pd.head()3. 표준화 (PCA 시 필수)
iris_ss = StandardScaler().fit_transform(iris.data) 4. PCA 반환해주는 함수 작성
def get_pca_data(ss_data, n_components=2):
pca = PCA(n_components=n_components)
pca.fit(ss_data)
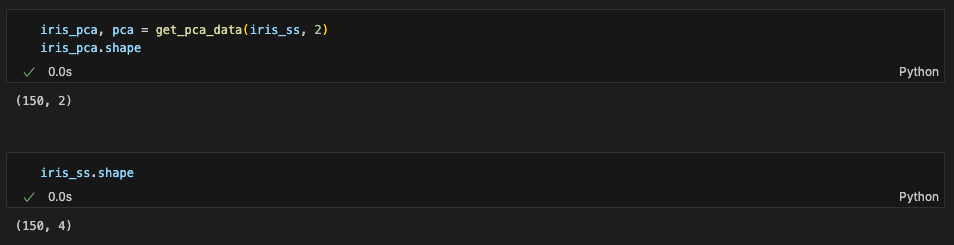
return pca.transform(ss_data), pcairis_pca와 iris_ss shape 비교:
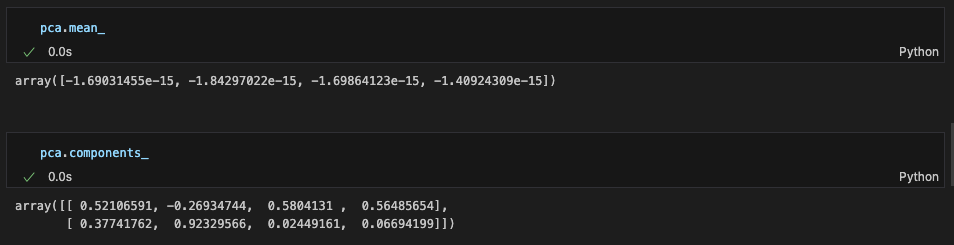
pca mean 속성과 components 속성 확인:
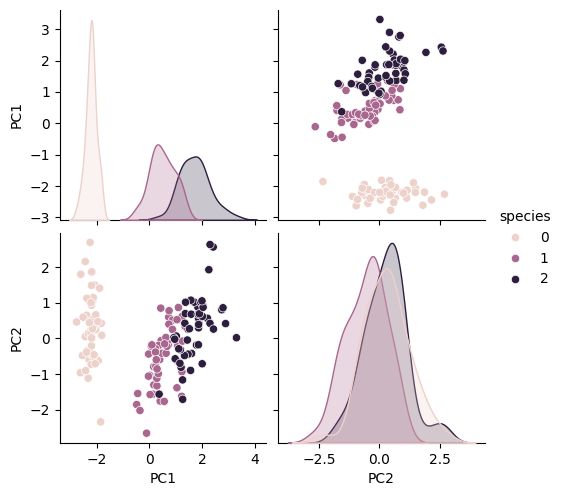
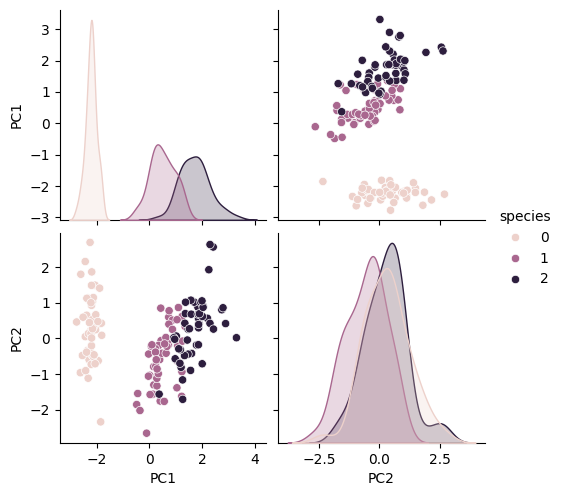
5. 시각화
pca 데이터로 데이터프레임 만들기:
def get_pd_from_pca(pca_data, cols=['PC1', 'PC2']):
return pd.DataFrame(pca_data, columns=cols)
iris_pd_pca = get_pd_from_pca(iris_pca)
iris_pd_pca['species'] = iris.target
iris_pd_pca.head()페어플롯:
6. Explained variance ratio
def print_variance_ratio(pca):
print('Explained variance ratio: {}'.format(pca.explained_variance_ratio_))
print('Cumulative explained variance ratio:{}'.format(np.cumsum(pca.explained_variance_ratio_)))
print_variance_ratio(pca)
PC1과 PC2가 데이터셋을 각각 73%, 23% 정도를 설명한다.
(이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다.)

데이터 엔지니어 도전기 / 스터디 노트