
Encoder와 Scaler는 머신러닝에서 데이터 전처리할 때 자주 쓰이는 도구들이다.
Encoder
- Encoder들은 문자(텍스트) 데이터를 숫자로 바꿔주는 역할을 함
- 주로 사용되는 Scikit-learn 도구에는
LabelEncoder와OneHotEncoder가 있다.
Label Encoder
Label Encoder는 문자(카테고리형 데이터)를 정수(0, 1, 2...)로 바꿔준다. 예를 들어:
['apple', 'banana', 'apple', 'orange']이걸 LabelEncoder로 변환하면:
[0, 1, 0, 2]각각의 고유한 카테고리에 숫자를 하나씩 할당함.
주로 타겟(y값)에 사용
코드 예시
from sklearn.preprocessing import LabelEncoder
encoder = LabelEncoder()
y = encoder.fit_transform(['cat', 'dog', 'cat', 'fish'])
print(y) # [0 1 0 2]
| 원본 | 숫자 |
|---|---|
| cat | 0 |
| dog | 1 |
| fish | 2 |
주의할 점
숫자 간에 크기나 순서 의미가 없음 → 숫자라고 해서 0 < 1 < 2 이런 식으로 해석하면 안됨
그래서 트리 계열 모델엔 괜찮지만, 선형 모델(로지스틱 회귀 등)에는 보통 One-Hot Encoding이 더 적합할 때가 많다고 함
그리고 숫자 간 '크기'가 있는 것처럼 보이게 될 수 있는 특징 때문에 타겟(Y)이 아닌 입력 데이터(X)에는 보통 OneHotEncoder를 쓴다.
OneHotEncoder
OneHotEncoder는 각 카테고리를 독립된 열로 바꿔주는 도구 (0/1 벡터)
from sklearn.preprocessing import OneHotEncoder
import numpy as np
encoder = OneHotEncoder(sparse=False)
X = encoder.fit_transform(np.array(['cat', 'dog', 'cat', 'fish']).reshape(-1, 1))
print(X)
| cat | dog | fish |
|---|---|---|
| 1 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 0 | 0 | 1 |
- 주로 입력 특성(X) 에 사용
- 모델이 카테고리들 사이의 순서나 거리감을 착각하지 않도록 도와줌
요약
| 도구 | 설명 | 보통 어디에 사용 |
|---|---|---|
| LabelEncoder | 문자 → 정수 | 타겟값(y) |
| OneHotEncoder | 문자 → 0/1 벡터 | 입력값(X) |
Scaler (정규화/표준화 도구)
데이터를 적절한 범위로 바꾸는데 사용
예를 들어:
| 키(cm) | 몸무게(kg) | 연봉(천만원) |
|---|---|---|
| 170 | 65 | 7,000 |
이런 데이터가 있으면,
연봉은 숫자가 너무 크고, 키/몸무게는 작다. 단위가 달라서
➡️ 이럴 경우 머신러닝 모델은 연봉에만 너무 집중하게 됨 😵
그래서,
🔧 Scaler는 이런 숫자 크기 차이를 ‘맞춰주는’ 역할을 함.
= 정규화 / 표준화 / 정렬
Scaler 종류
| Scaler 이름 | 설명 | 언제 쓰나 |
|---|---|---|
StandardScaler | 평균 0, 표준편차 1로 바꿔줌 (정규분포 느낌) | 대부분의 경우 기본 |
MinMaxScaler | 최소값 0, 최대값 1로 바꿈 | 값이 양수일 때, 이미지 등 |
RobustScaler | 중앙값 기준으로 스케일링 (이상치에 강함) | 이상치(outlier) 많은 데이터 |
Normalizer | 각 샘플의 벡터 크기를 1로 만듦 | 거리 기반 알고리즘 (KNN 등) |
사용 예시 (scikit-learn)
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)fit→ 데이터의 평균, 표준편차 계산transform→ 실제 스케일 조정fit_transform→ 한 번에 둘 다
📌 왜 중요하냐면?
스케일이 다른 특성들 때문에 학습이 꼬일 수 있음
특히 KNN, SVM, 선형회귀, 신경망 등은 스케일에 매우 민감함
스케일링 전후 비교 시각화
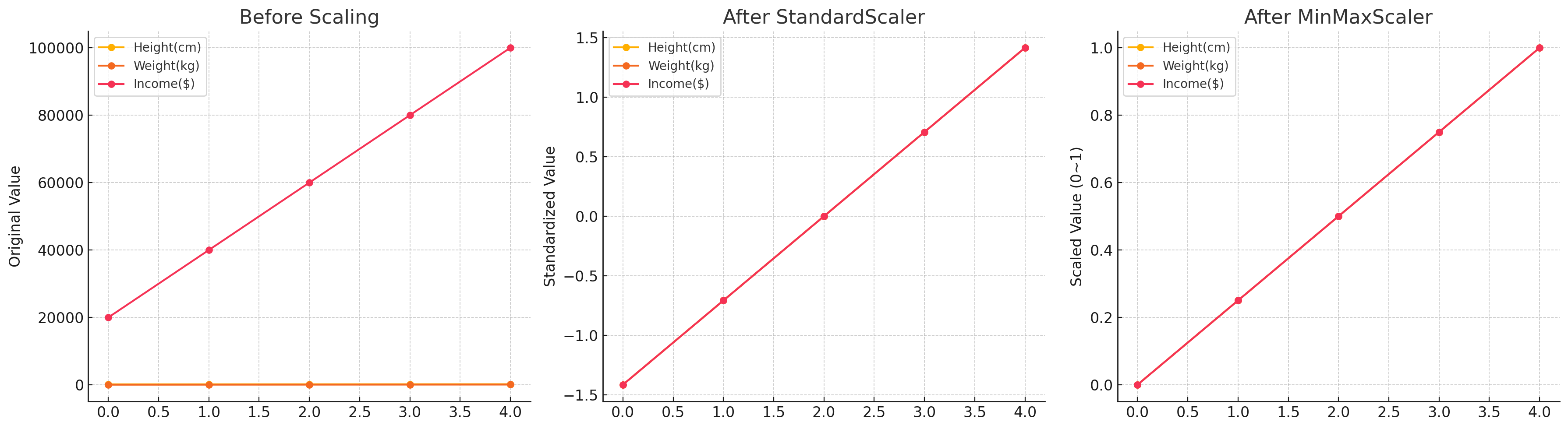
| 왼쪽: Before Scaling | 가운데: After StandardScaler | 오른쪽: After MinMaxScaler |
|---|---|---|
| Income(수입)은 숫자가 너무 커서 키랑 몸무게가 거의 눕다시피 보임 → 이 상태로 머신러닝 돌리면 수입에만 몰빵해서 학습해버릴 가능성 높음 | 모든 특성들이 평균 0, 표준편차 1로 정규화됨 중심은 같지만, 퍼짐 정도가 조절돼서 공평한 느낌 | 모든 특성이 0~1 사이로 딱 맞춰짐. 스케일 통일 = 머신러닝 알고리즘 입장에서 훨씬 처리하기 쉬워짐 |
Scaler는 키 작고 조용한 피처가 무시당하지 않게,
모든 피처들이 공평하게 말할 기회를 주는 느낌~
코드 예시
df = pd.DataFrame({
'A' : [10, 20, -10, 0, 25],
'B' : [1, 2, 3, 1, 0]
})
df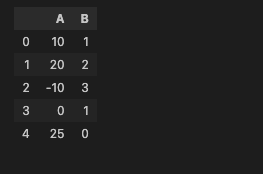
데이터프레임 만들고,
from sklearn.preprocessing import MinMaxScaler
mms = MinMaxScaler()
mms.fit(df)MinMaxScaler로 fit을 시키고 min, max 값을 확인해보면
mms.data_min_, mms.data_max_
이렇게 min, max 값을 반환해줌
mms.transform(df)transform시키면~
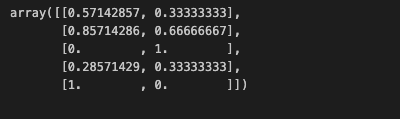
스케일링이 되었다.
시각화로 비교
데이터 생성
df = pd.DataFrame({
'A' : [-0.1, 0., 0.1, 0.2, 0.3, 0.4, 1.0, 1.1, 5.]
})
dfMinMaxScaler, StandardScaler, RobustScaler를 각각 생성해주고
from sklearn.preprocessing import MinMaxScaler, StandardScaler, RobustScaler
mm = MinMaxScaler()
ss = StandardScaler()
rs = RobustScaler()각각 스케일러로 fit transform한 데이터 붙여주기
df_scaler = df.copy()
df_scaler['mm'] = mm.fit_transform(df)
df_scaler['ss'] = ss.fit_transform(df)
df_scaler['rs'] = rs.fit_transform(df)
df_scaler
박스플롯으로 그려보자~
import seaborn as sns
import matplotlib.pyplot as plt
sns.set_theme(style='whitegrid')
plt.figure(figsize=(10, 5))
sns.boxplot(data=df_scaler, orient='h', palette='Set2')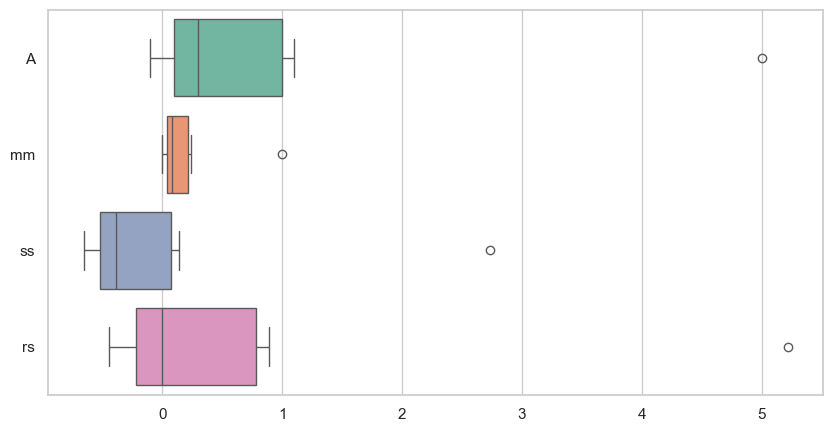
각 스케일러의 특징을 눈으로 확인할 수 있다!
(이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다.)
