머신 러닝이란?
간단히 말해서, 기계한테 데이터를 주고 학습을 시켜서 내가 원하는 문제에 대한 답을 찾아내도록 하는 것.
Iris Classification
머신 러닝계에서 가장 유명한 데이터셋 중 하나가 Iris라고 함.
Iris의 품종은 Versicolor, Virginica, Setosa가 있는데, 위 데이터셋을 통해 꽃잎(petal), 꽃받침(sepal), 길이/너비 정보를 이용해서 품종을 구분해보는 것..!
"이건 Setosa야." <- 이런식으로
일단 머신한테 learn 시키기 전에, 사람이 먼저 분석해보기로 한다.
데이터 불러오기
iris 데이터는 싸이킷런(sklearn)에서 불러올 수 있다.
from sklearn.datasets import load_iris
iris = load_iris()iris가 가진 key값을 확인해보면,
iris.keys()
요런 아이들이 있다.
DESCR(설명?)을 확인해보자.
print(iris.DESCR)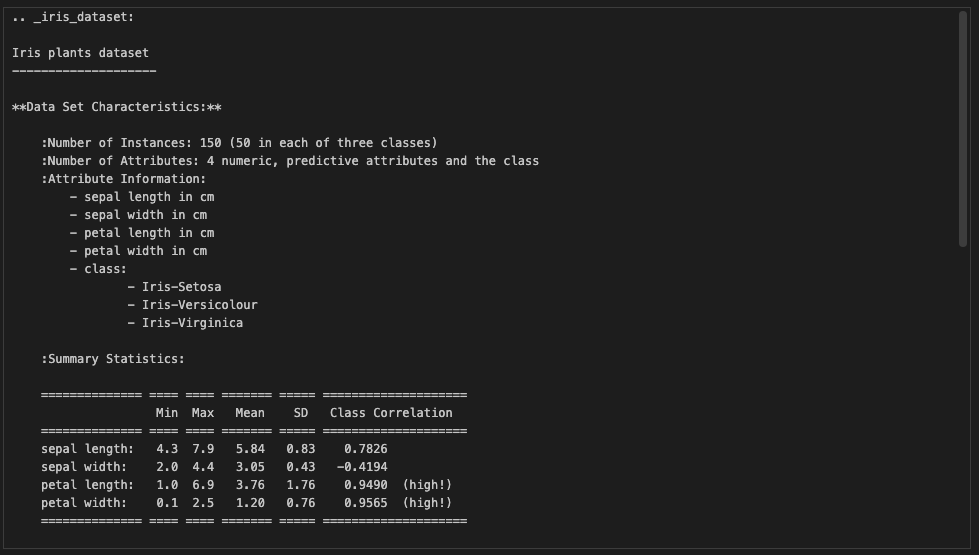
데이터셋의 특성에 대해 설명되어있다.
각 클래스에 50개씩 총 150개의 인스턴스가 있으며 (3개 클래스 - 품종)
sepal length/width, petal length/width 이렇게 4개의 숫자타입 속성이 있다고 한다.
간략한 통계도 제공
feature name 확인 (데이터가 가진 4가지 특성)
iris.feature_names
target name 확인 (품종 3개)
iris.target_names
target 확인 (각 데이터가 어떤 품종으로 분류되는지)
iris.target
이 target에 len을 감싸서 데이터 길이 확인
len(iris.target)
150개
data 출력해보기
iris.data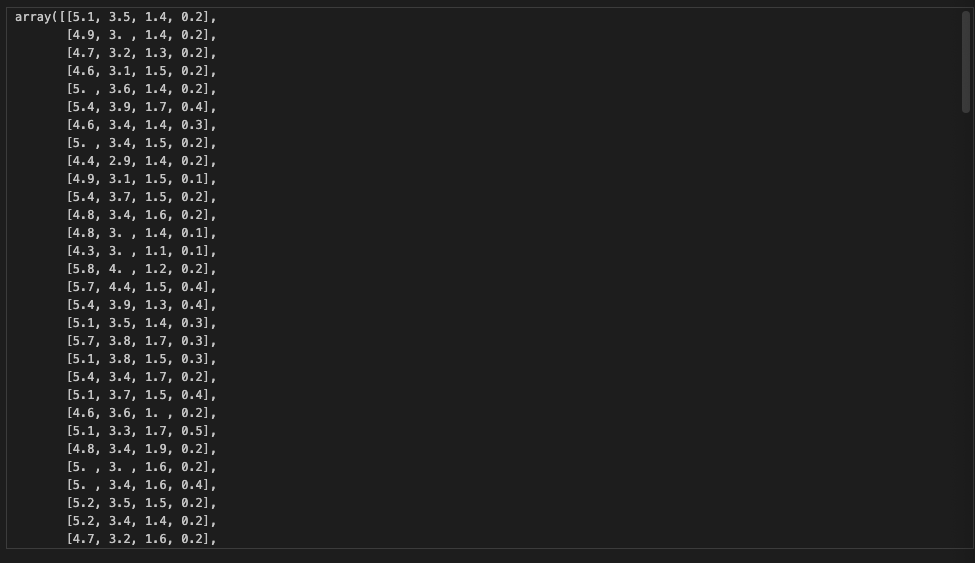
요렇게 값들이 잘 들어가있는 것을 확인할 수 있다.
분석 및 시각화
pandas dataframe으로 불러와보자.
import pandas as pd
iris_pd = pd.DataFrame(iris.data, columns=iris.feature_names)
iris_pd.head()
species 컬럼을 만들어서 target 데이터(품종)를 넣어줌
iris_pd['species'] = iris.target
head()로 확인해보면 잘 들어갔다.
데이터 분석 시각화를 위해서 seaborn과 matplotlib의 pyplot을 불러와주고, 박스플롯 그려보기
import seaborn as sns
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 4))
sns.boxplot(x='petal length (cm)', y='species', data=iris_pd, orient='h');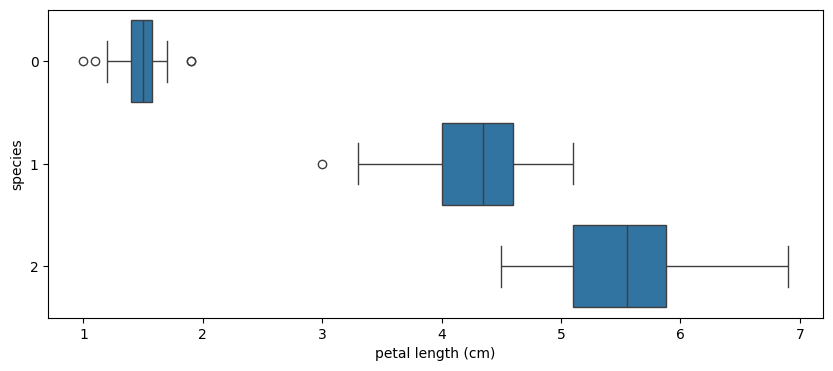
x축을 petal length로 확인해보면, 꽃잎 길이 정보가 주어졌을 때 확실히 0번 종은 다른 두 종과 구분이 가능할 것 같다.
여러 숫자형 변수들 간의 관계를 한눈에 볼 수 있는 pairplot을 그려보았다.
(pairplot은 수치형 변수들 간 관계를 산점도+히스토그램으로 시각화해 주는데, 머신러닝 전에 EDA 단계에서 자주 쓰임)
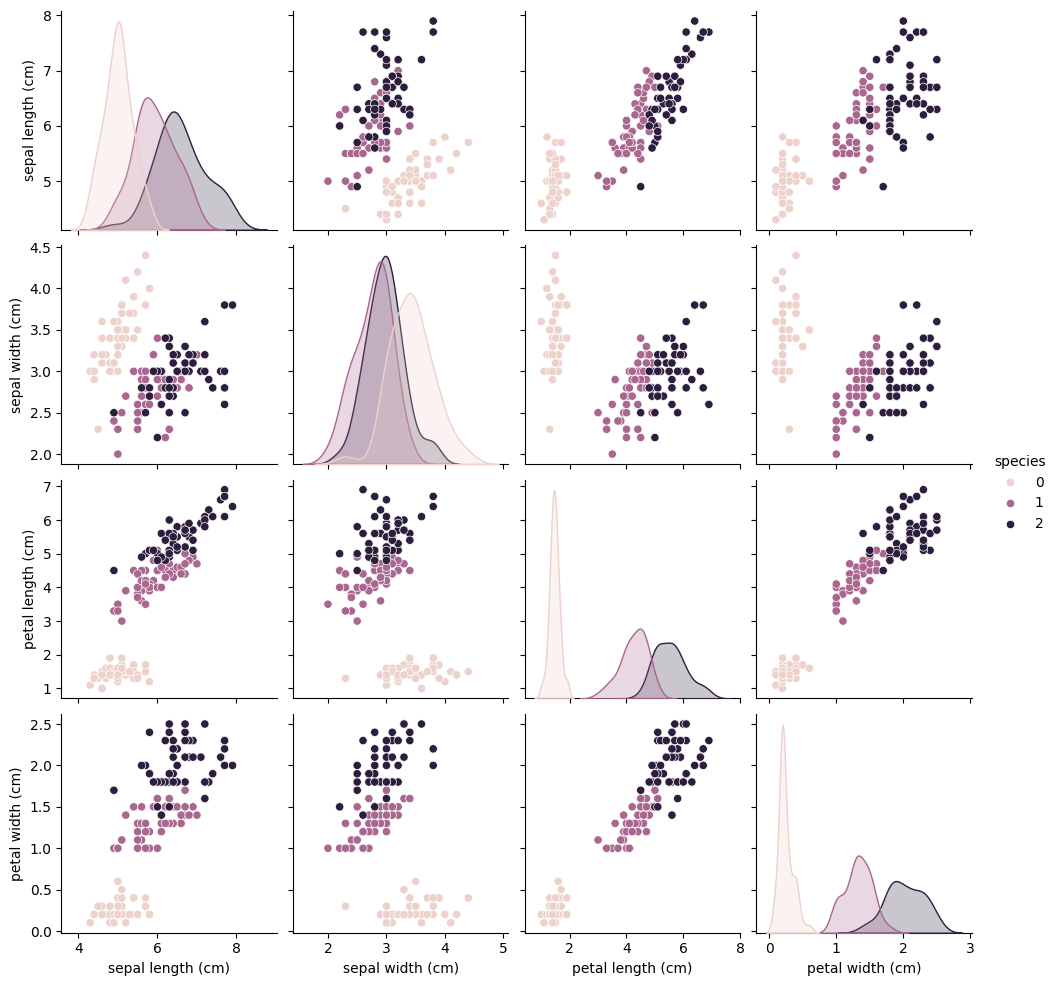
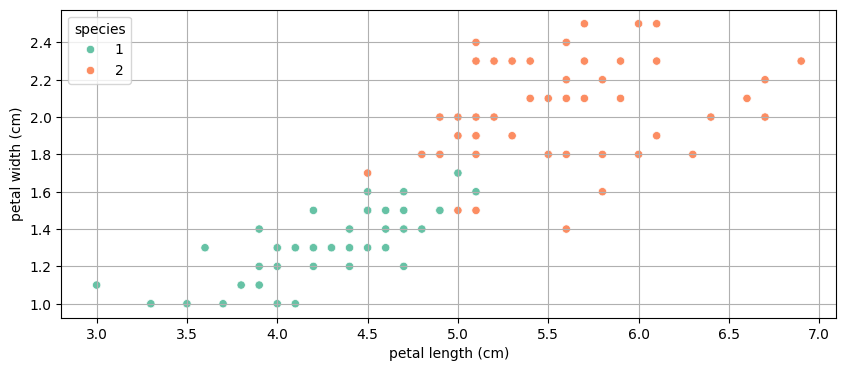
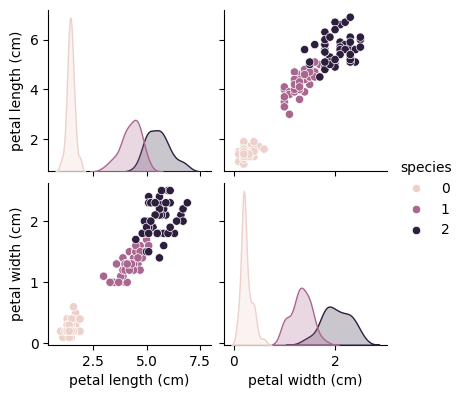
petal width, length를 집중적으로 보기로
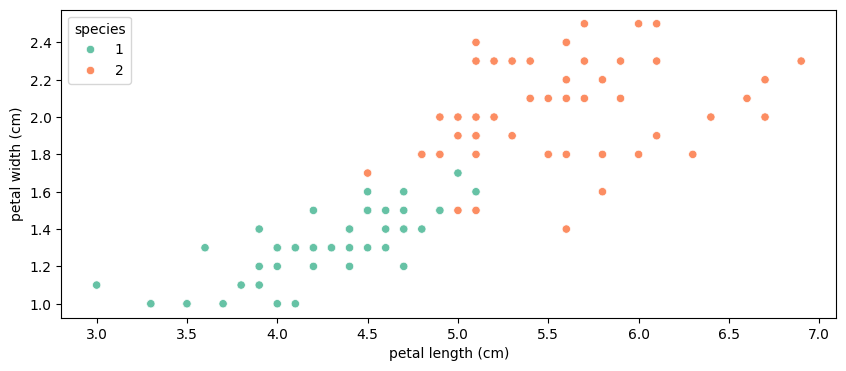
품종 1, 2는 어떻게 구분해야할까? 일단 1, 2만 넣은 데이터프레임을 만들었다.
iris_12 = iris_pd[iris_pd['species'] != 0]
iris_12.info()
scatterplot으로 그려보면, petal length와 width를 딱 어느 기준으로 나눌 수 없도록 애매하게 겹치는 데이터들이 있다.
petal width 약 1.6~1.7 정도
petal length 약 5.0~5.2 정도
데이터가 혼합돼있음. 이때 어떻게 두 품종을 분류할 것인가?
Decision Tree
이때, 모델이 등장한다. Decision Tree를 통해 데이터를 분류시켜보자.
사이킷런(Scikit Learn)은 현재 파이썬에서 가장 유명한 기계 학습 오픈 소스 라이브러리인데, 결정나무에 의한 분류(Decision Tree Classifier) 또한 제공하고 있다.
iris_tree로 DecisionTreeClassifier()을 불러오고, (학습하지 않은 상태의 모델)
fit()은 학습시키기.
이때 학습할 데이터를 인수로 넘겨준다.
iris.data[:, 2:] -> 특성 정보
iris.target -> 품종 (정답)
from sklearn.tree import DecisionTreeClassifier
iris_tree = DecisionTreeClassifier()
iris_tree.fit(iris.data[:, 2:], iris.target) 
그럼 이렇게 학습이 잘 됐다고 뜸
accuracy_score를 통해 정확도를 측정해보면,
from sklearn.metrics import accuracy_score
y_pred_tr = iris_tree.predict(iris.data[:, 2:])
accuracy_score(iris.target, y_pred_tr) 
학습시킨 decision tree가 0.99의 정확도를 갖는 것을 확인할 수 있다.
이건 알고리즘 중에서 쉬운 축에 속하는 decision tree라고 한다~
(이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다.)
